REaLTabFormer
v0.2.1
REaLTabFormer (Datos tabulares y relacionales realistas mediante transformadores) ofrece un marco unificado para sintetizar datos tabulares de diferentes tipos. Se utiliza un modelo de secuencia a secuencia (Seq2Seq) para generar conjuntos de datos relacionales sintéticos. El modelo REaLTabFormer para datos tabulares no relacionales utiliza GPT-2 y se puede utilizar de forma inmediata para modelar cualquier dato tabular con observaciones independientes.
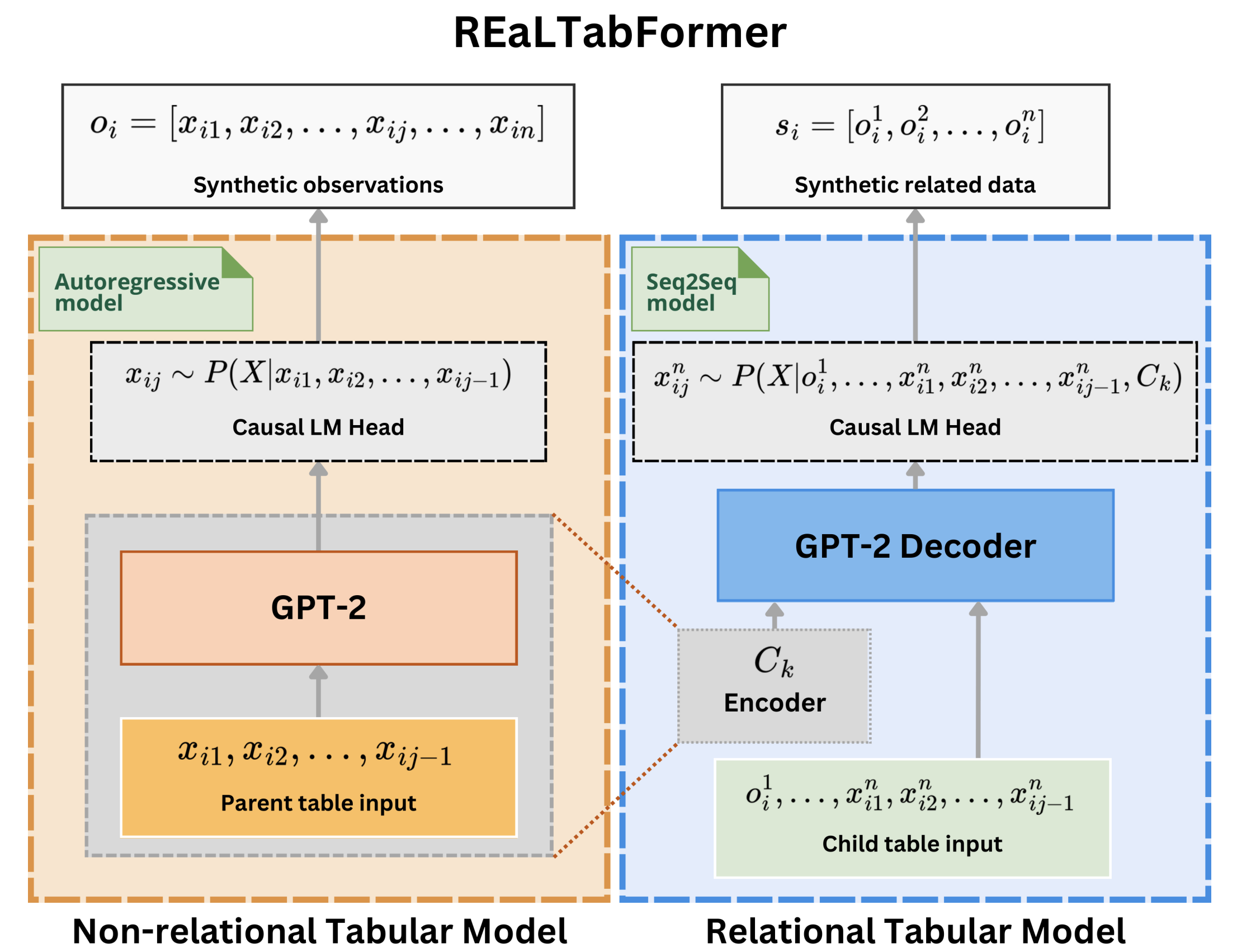
REaLTabFormer: Generación de datos tabulares y relacionales realistas mediante transformadores
Documento sobre ArXiv
REaLTabFormer está disponible en PyPi y se puede instalar fácilmente con pip (versión de Python >= 3.7):
pip instalar realtabformer
Mostramos ejemplos del uso de REaLTabFormer para modelar y generar datos sintéticos a partir de un modelo entrenado.
Nota
El modelo implementa un criterio de parada óptimo basado en la distribución de datos sintéticos al entrenar un modelo tabular no relacional. El modelo dejará de entrenarse cuando la distribución de datos sintéticos se acerque a la distribución de datos reales.
Asegúrese de establecer el parámetro epochs en un número grande para permitir que el modelo se ajuste mejor a los datos. El modelo dejará de entrenar cuando se cumpla el criterio de parada óptimo.
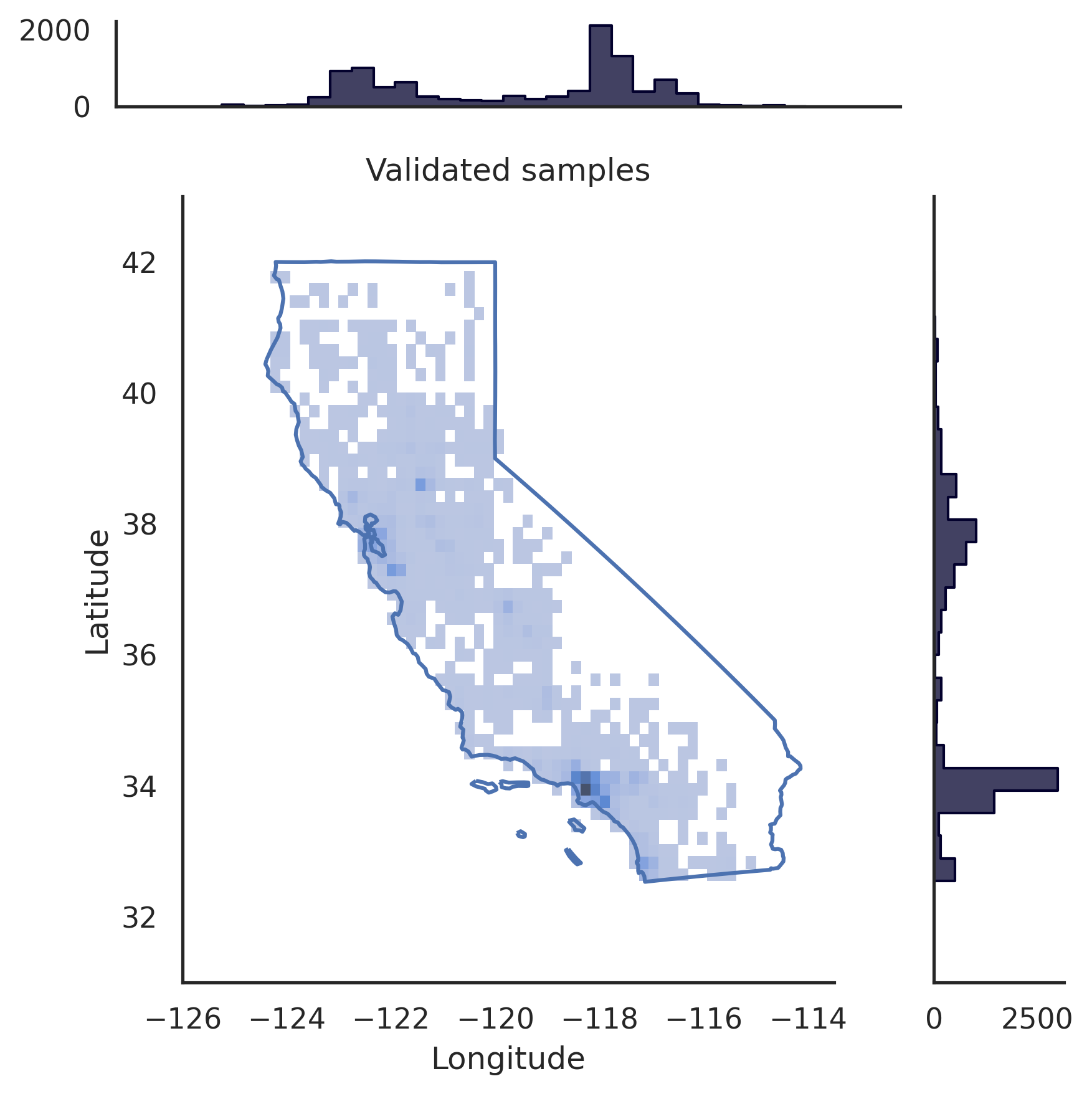
# pip install realtabformerimport pandas as pdffrom realtabformer import REaLTabFormerdf = pd.read_csv("foo.csv")# NOTA: Elimine cualquier identificador único en los# datos que no desee que se modelen.# Tabla principal o no relacional. modelo_rtf = REaLTabFormer(model_type="tabular",gradient_accumulation_steps=4,logging_steps=100)# Ajustar el modelo en el conjunto de datos.# Se pueden# pasar parámetros adicionales al método `.fit`.rtf_model.fit(df)# Guardar el modelo en el directorio actual.# Se creará un nuevo directorio `rtf_model/`.# En él, también se creará un directorio con el ID de experimento# del modelo `idXXXX`# donde se almacenarán los artefactos del modelo.rtf_model.save("rtf_model/")# Generar datos sintéticos con el mismo# número de observaciones que el conjunto de datos real.samples = rtf_model.sample(n_samples=len(df))# Cargar el modelo guardado. Se debe proporcionar el directorio del experimento#.rtf_model2 = REaLTabFormer.load_from_dir(path="rtf_model/idXXXX") # pip install realtabformerimport osimport pandas as pdffrom pathlib import Pathfrom realtabformer import REaLTabFormerparent_df = pd.read_csv("foo.csv")child_df = pd.read_csv("bar.csv")join_on = "unique_id"# Asegúrese de que las columnas clave en Tanto la tabla # principal como la secundaria tienen el mismo nombre.assert ((join_on en parent_df.columns) y (join_on en child_df.columns))# Tabla principal o no relacional. No incluya el# Unique_id field.parent_model = REaLTabFormer(model_type="tabular")parent_model.fit(parent_df.drop(join_on, axis=1))pdir = Path("rtf_parent/")parent_model.save(pdir)# # Obtenga el modelo principal guardado más recientemente,# # o especifique algún otro modelo guardado.# parent_model_path = pdir / "idXXX"parent_model_path = ordenado([p para p en pdir.glob("id*") if p.is_dir()],key=os.path.getmtime)[-1]child_model = REaLTabFormer(model_type="relational",parent_realtabformer_path=parent_model_path,output_max_length=None,train_size=0.8)child_model.fit(df=child_df,in_df=parent_df,join_on=join_on)# Generar muestras principales.parent_samples = parent_model.sample(len(parend_df ))# Cree los identificadores únicos basados en el index.parent_samples.index.name = join_onparent_samples = parent_samples.reset_index()# Generar las observaciones relacionales.child_samples = child_model.sample(input_unique_ids=parent_samples[join_on],input_df=parent_samples.drop(join_on, axis=1),gen_batch=64 ) El marco REaLTabFormer proporciona una interfaz para crear fácilmente validadores de observación para filtrar muestras sintéticas no válidas. A continuación mostramos un ejemplo del uso del GeoValidator . El gráfico de la izquierda muestra la distribución de la latitud y longitud generada sin validación. El gráfico de la derecha muestra las muestras sintéticas con observaciones que han sido validadas utilizando el GeoValidator con el límite de California. Aún así, incluso cuando no entrenamos de manera óptima el modelo para generar esto, las muestras no válidas (que quedan fuera del límite) son escasas en los datos generados sin un validador.
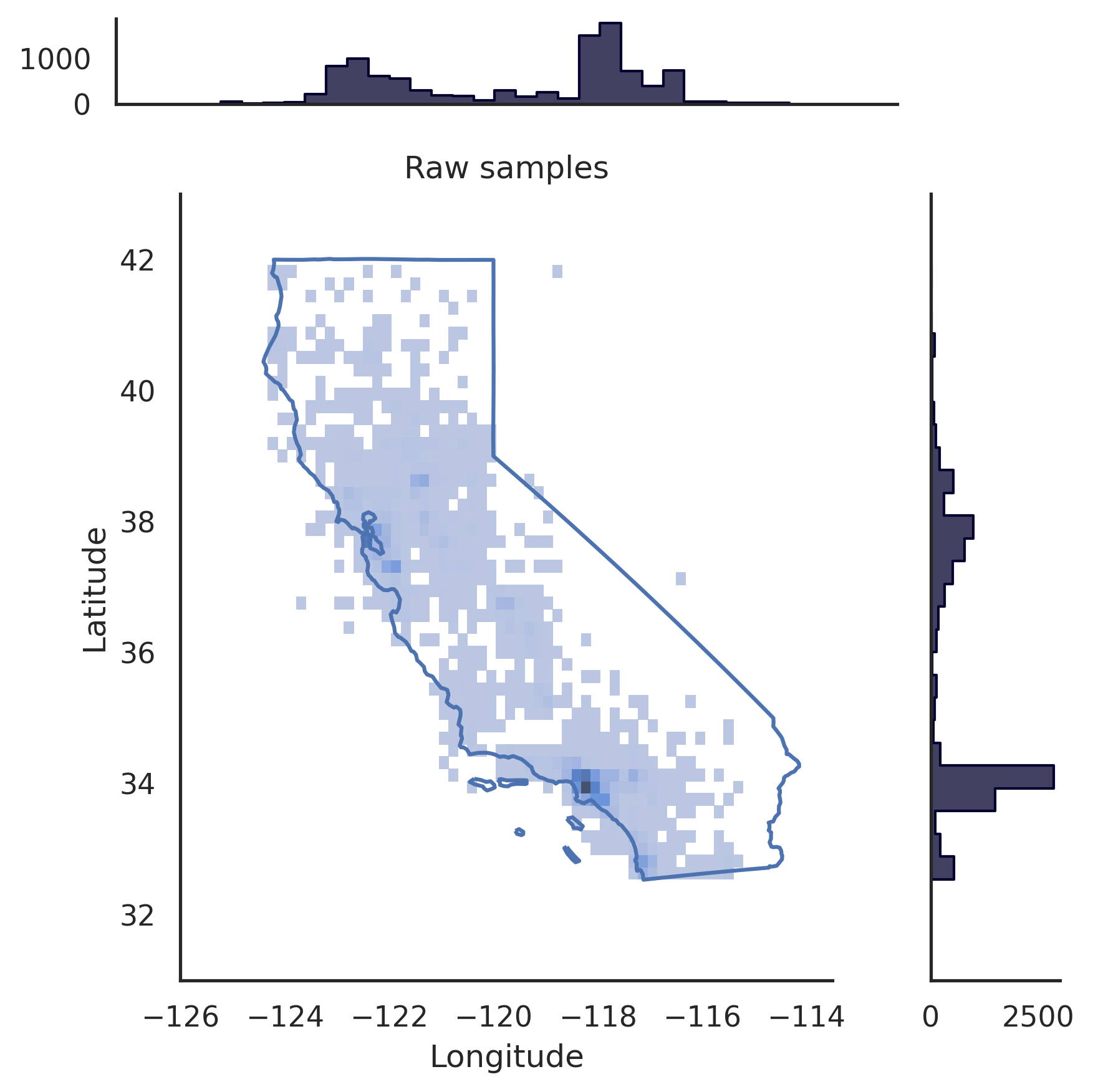
# !pip install geopandas &> /dev/null# !pip install realtabformer &> /dev/null# !git clone https://github.com/joncutrer/geopandas-tutorial.git &> /dev/nullimport geopandasimport seaborn as snsimport matplotlib.pyplot como pltdesde realtabformer importar REaLTabFormerdesde realtabformer importar rtf_validators as rtf_valfrom shapely.geometry import Polygon, LineString, Point, MultiPolygonfrom sklearn.datasets import fetch_california_housingdef plot_sf(data, samples, title=Ninguno):xlims = (-126, -113.5)ylims = (31, 43)bins = (50) , 50)dd = muestras.copia()pp = dd.loc[dd["Longitud"].entre(datos["Longitud"].min(), datos["Longitud"].max()) &dd["Latitud"].between(datos["Latitud"] .min(), datos["Latitud"].max())
]g = sns.JointGrid(data=pp, x="Longitud", y="Latitud", marginal_ticks=True)g.plot_joint(sns.histplot,bins=bins,
)estados[estados['NOMBRE'] == 'California'].boundary.plot(ax=g.ax_joint)g.ax_joint.set_xlim(*xlims)g.ax_joint.set_ylim(*ylims)g.plot_marginals(sns. histplot, elemento="paso", color="#03012d")si title:g.ax_joint.set_title(title)plt.tight_layout()# Obtener archivos geográficosstates = geopandas.read_file('geopandas-tutorial/data/usa-states-census-2014.shp')states = States.to_crs("EPSG :4326") # Proyección GPS# Obtener el conjunto de datos de vivienda de Californiadata = fetch_california_housing(as_frame=True).frame# Creamos un modelo con épocas pequeñas para la demostración, el valor predeterminado es 200.rtf_model = REaLTabFormer(model_type="tabular",batch_size=64,epochs=10,gradient_accumulation_steps=4,logging_steps=100)# Ajustar el modelo especificado. También reducimos num_bootstrap, el valor predeterminado es 500.rtf_model.fit(data, num_bootstrap=10)# Guarde el modelo entrenadortf_model.save("rtf_model/")# Muestra de datos sin procesar sin validadoressamples_raw = rtf_model.sample(n_samples=10240, gen_batch= 512)# Datos de muestra con el validador geográficoobs_validator = rtf_val.ObservationValidator()obs_validator.add_validator("geo_validator",rtf_val.GeoValidator(MultiPolygon(estados[estados['NOMBRE'] == 'California'].geometría[0])),
("Longitud", "Latitud")
)muestras_validadas = rtf_model.sample(n_muestras=10240, gen_batch=512,validator=obs_validator,
)# Visualice samplesplot_sf(data, samples_raw, title="Muestras sin procesar")plot_sf(data, samples_validated, title="Muestras validadas")Cite nuestro trabajo si utiliza REaLTabFormer en sus proyectos o investigaciones.
@article{solatorio2023realtabformer, title={REaLTabFormer: Generación de datos tabulares y relacionales realistas usando Transformers}, autor={Solatorio, Aivin V. y Dupriez, Olivier}, diario={arXiv preprint arXiv:2302.02041}, año={2023}}Agradecemos al Centro Conjunto de Datos sobre Desplazamiento Forzado (JDC) del Banco Mundial y ACNUR por financiar el proyecto "Mejora del acceso responsable a microdatos para mejorar las políticas y la respuesta en situaciones de desplazamiento forzado" (KP-P174174-GINP-TF0B5124). Una parte del fondo se destinó a apoyar el desarrollo del marco REaLTabFormer que se utilizó para generar la población sintética para la investigación sobre el riesgo de divulgación y el efecto mosaico.
¿También enviamos? a la cara de abrazo? por todo el software de código abierto que lanzan. Y a todos los proyectos de código abierto, ¡gracias!


