distribuidor
v0.0.1beta0
[29 de julio de 2024] ¡DistriFusion es compatible con ColossalAI!
[4 de abril de 2024] ¡ DistriFusion es seleccionado como cartel destacado en CVPR 2024!
[29 de febrero de 2024] ¡DistriFusion es aceptado por CVPR 2024! ¡Nuestro código está disponible públicamente!
 Presentamos DistriFusion, un algoritmo sin entrenamiento para aprovechar múltiples GPU para acelerar la inferencia del modelo de difusión sin sacrificar la calidad de la imagen. Naïve Patch (Descripción general (b)) sufre el problema de fragmentación debido a la falta de interacción del parche. Los ejemplos presentados se generan con SDXL utilizando un muestreador Euler de 50 pasos con una resolución de 1280×1920 y la latencia se mide en GPU A100.
Presentamos DistriFusion, un algoritmo sin entrenamiento para aprovechar múltiples GPU para acelerar la inferencia del modelo de difusión sin sacrificar la calidad de la imagen. Naïve Patch (Descripción general (b)) sufre el problema de fragmentación debido a la falta de interacción del parche. Los ejemplos presentados se generan con SDXL utilizando un muestreador Euler de 50 pasos con una resolución de 1280×1920 y la latencia se mide en GPU A100.
DistriFusion: inferencia paralela distribuida para modelos de difusión de alta resolución
Muyang Li*, Tianle Cai*, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li y Song Han
MIT, Princeton, Lepton AI y NVIDIA
En CVPR 2024.
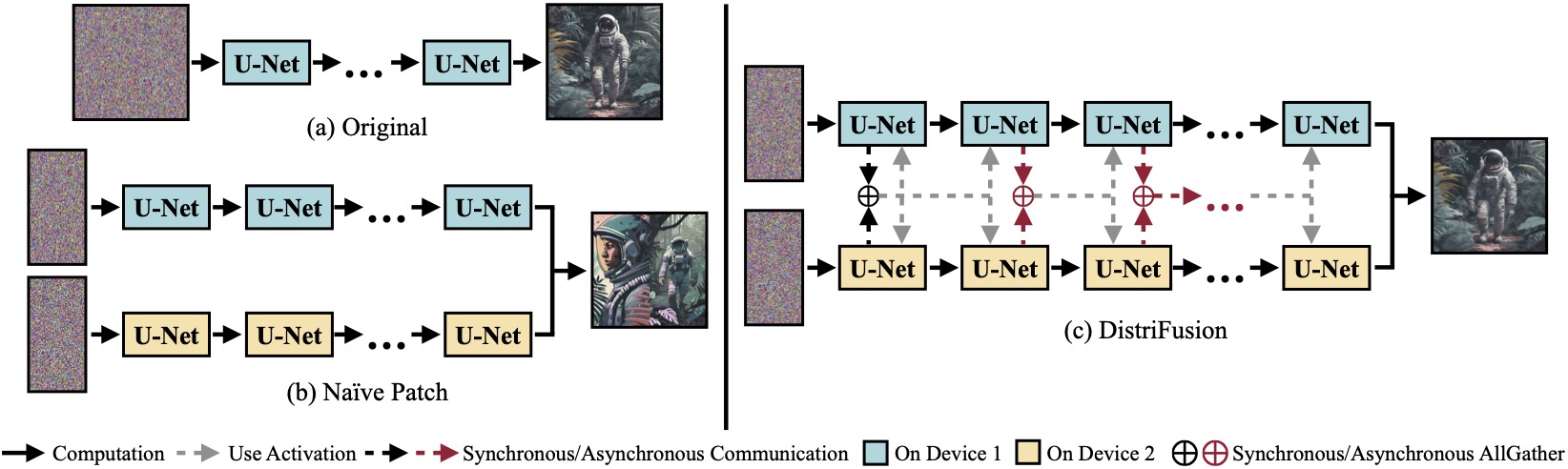 (a) Modelo de difusión original ejecutándose en un solo dispositivo. (b) Dividir ingenuamente la imagen en 2 parches en 2 GPU tiene una costura evidente en el límite debido a la ausencia de interacción entre parches. (c) Nuestra DistriFusion emplea comunicación sincrónica para la interacción de parches en el primer paso. Después de eso, reutilizamos las activaciones del paso anterior mediante comunicación asincrónica. De esta manera, la sobrecarga de comunicación se puede ocultar en el proceso de cálculo.
(a) Modelo de difusión original ejecutándose en un solo dispositivo. (b) Dividir ingenuamente la imagen en 2 parches en 2 GPU tiene una costura evidente en el límite debido a la ausencia de interacción entre parches. (c) Nuestra DistriFusion emplea comunicación sincrónica para la interacción de parches en el primer paso. Después de eso, reutilizamos las activaciones del paso anterior mediante comunicación asincrónica. De esta manera, la sobrecarga de comunicación se puede ocultar en el proceso de cálculo.
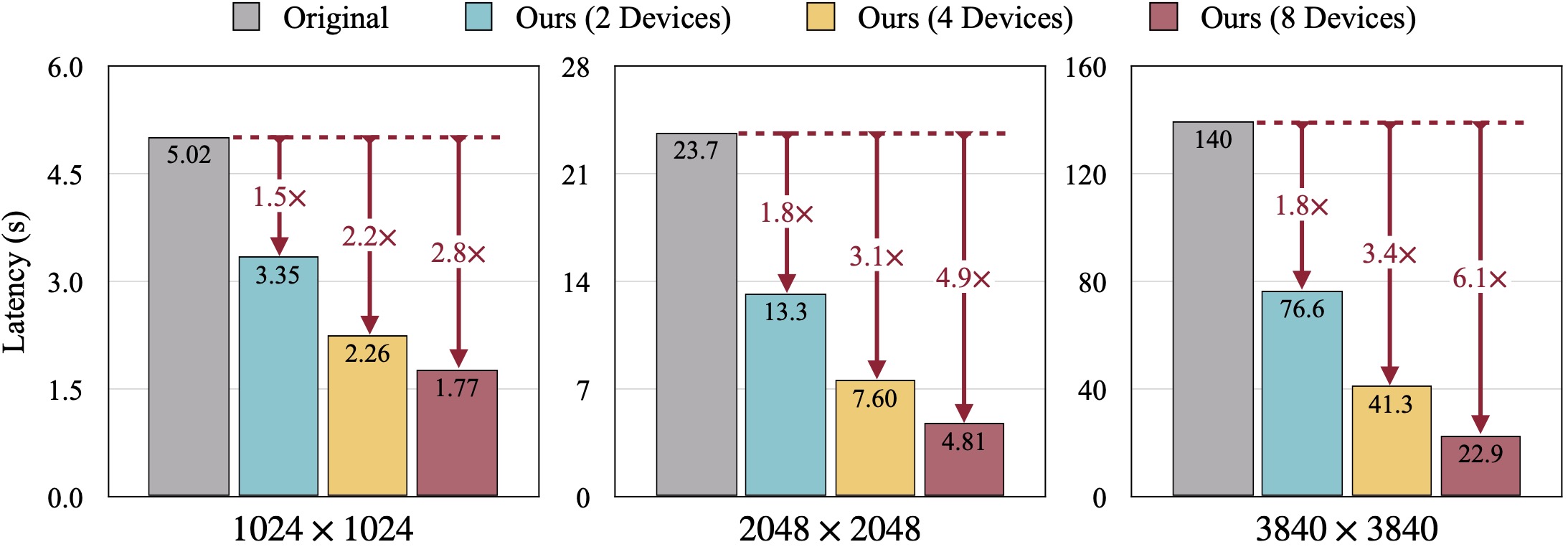
 Resultados cualitativos de SDXL. La FID se calcula con respecto a las imágenes reales. Nuestro DistriFusion puede reducir la latencia según la cantidad de dispositivos utilizados preservando la fidelidad visual.
Resultados cualitativos de SDXL. La FID se calcula con respecto a las imágenes reales. Nuestro DistriFusion puede reducir la latencia según la cantidad de dispositivos utilizados preservando la fidelidad visual.
Referencias:
Después de instalar PyTorch, debería poder instalar distrifuser con PyPI
pip install distrifusero vía GitHub:
pip install git+https://github.com/mit-han-lab/distrifuser.gito localmente para el desarrollo
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e . En scripts/sdxl_example.py , proporcionamos un script mínimo para ejecutar SDXL con DistriFusion.
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" ) Específicamente, nuestro distrifuser comparte las mismas API que los difusores y puede usarse de manera similar. Solo necesita definir un DistriConfig y usar nuestro DistriSDXLPipeline empaquetado para cargar el modelo SDXL previamente entrenado. Luego, podemos generar la imagen como StableDiffusionXLPipeline en difusores. El comando en ejecución es
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py donde $N_GPUS es el número de GPU que desea utilizar.
También proporcionamos un script mínimo para ejecutar SD1.4/2 con DistriFusion en scripts/sd_example.py . El uso es el mismo.
Nuestros resultados de referencia utilizan PyTorch 2.2 y difusores 0.24.0. Primero, es posible que necesites instalar algunas dependencias adicionales:
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid Puede utilizar scripts/generate_coco.py para generar imágenes con subtítulos de COCO. El comando es
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
donde $N_GPUS es el número de GPU que desea utilizar. De forma predeterminada, los resultados generados se almacenarán en results/coco . También puedes personalizarlo con --output_root . Algunos argumentos adicionales que quizás quieras ajustar:
--num_inference_steps : el número de pasos de inferencia. Usamos 50 por defecto.--guidance_scale : la escala de orientación sin clasificador. Usamos 5 por defecto.--scheduler : El muestreador de difusión. Usamos el muestreador DDIM por defecto. También puede utilizar euler para el muestreador Euler y dpm-solver para el solucionador DPM.--warmup_steps : el número de pasos de calentamiento adicionales (4 de forma predeterminada).--sync_mode : diferentes modos de sincronización GroupNorm. De forma predeterminada, utiliza nuestra GroupNorm asincrónica corregida.--parallelism : El paradigma de paralelismo que utilizas. De forma predeterminada, es paralelismo de parches. Puedes usar tensor para paralelismo tensorial y naive_patch para parche ingenuo. Después de generar todas las imágenes, puede utilizar nuestro script scripts/compute_metrics.py para calcular PSNR, LPIPS y FID. El uso es
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1 donde $IMAGE_ROOT0 y $IMAGE_ROOT1 son rutas a las carpetas de imágenes que estás intentando comparar. Si IMAGE_ROOT0 es la carpeta de verdad sobre el terreno, agregue una marca --is_gt para cambiar el tamaño. También proporcionamos un script scripts/dump_coco.py para volcar las imágenes reales.
Puede utilizar scripts/run_sdxl.py para comparar la latencia de nuestros diferentes métodos. El comando es
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent donde $N_GPUS es el número de GPU que desea utilizar. De manera similar a scripts/generate_coco.py , también puedes cambiar algunos argumentos:
--num_inference_steps : el número de pasos de inferencia. Usamos 50 por defecto.--image_size : el tamaño de la imagen generada. Por defecto, es 1024×1024.--no_split_batch : deshabilite la división de lotes para obtener orientación sin clasificadores.--warmup_steps : el número de pasos de calentamiento adicionales (4 de forma predeterminada).--sync_mode : diferentes modos de sincronización GroupNorm. De forma predeterminada, utiliza nuestra GroupNorm asincrónica corregida.--parallelism : El paradigma de paralelismo que utilizas. De forma predeterminada, es paralelismo de parches. Puedes usar tensor para paralelismo tensorial y naive_patch para parche ingenuo.--warmup_times / --test_times : el número de ejecuciones de calentamiento/prueba. Por defecto, son 5 y 20, respectivamente. Si utiliza este código para su investigación, cite nuestro artículo.
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}Nuestro código está desarrollado en base a huggingface/diffusers y lmxyy/sige. Agradecemos a torchprofile por la medición de MAC, clean-fid por el cálculo FID y Lightning-AI/torchmetrics por PSNR y LPIPS.
Agradecemos a Jun-Yan Zhu y Ligeng Zhu por su útil discusión y valiosos comentarios. El proyecto cuenta con el apoyo de MIT-IBM Watson AI Lab, Amazon, MIT Science Hub y National Science Foundation.
