splicing
1.0.0

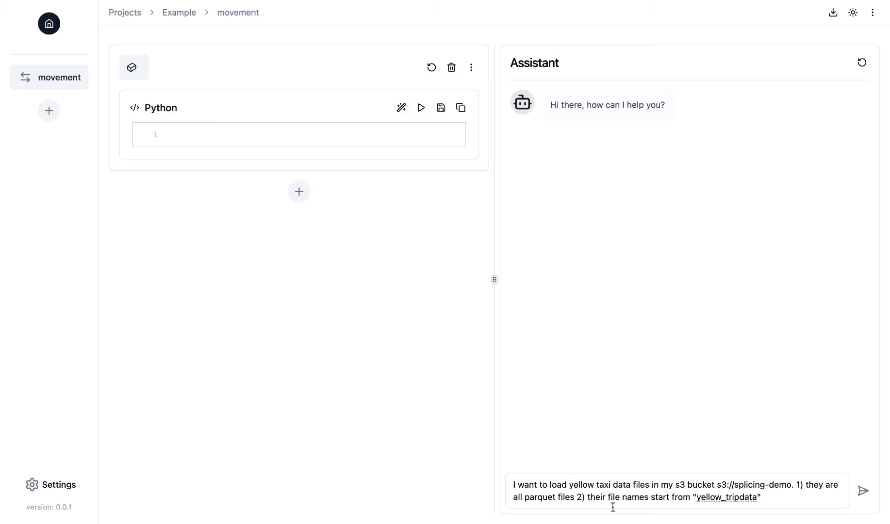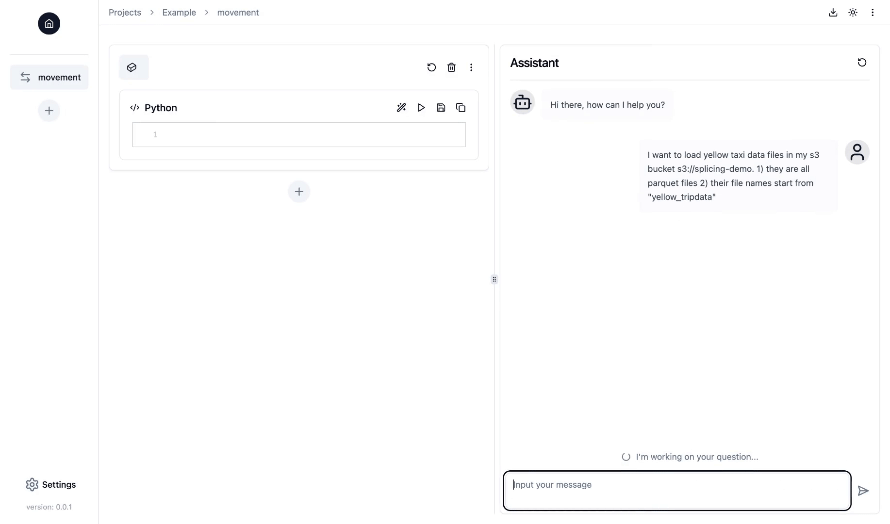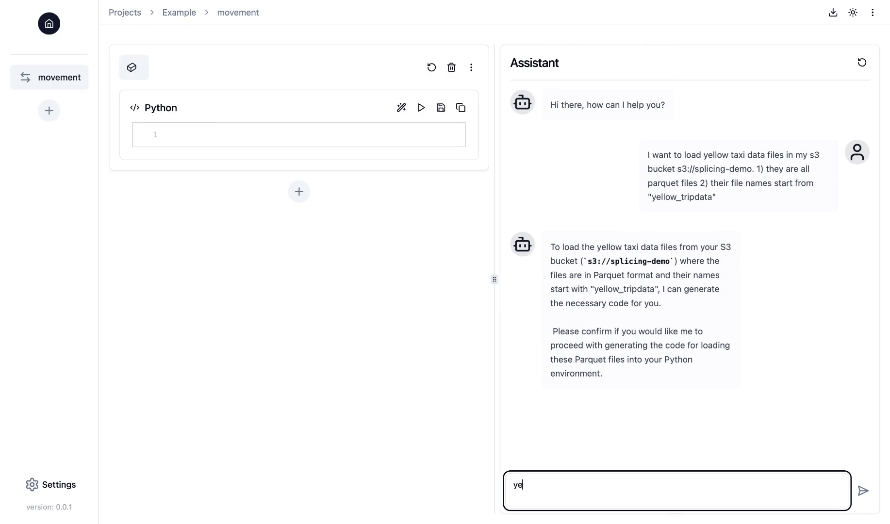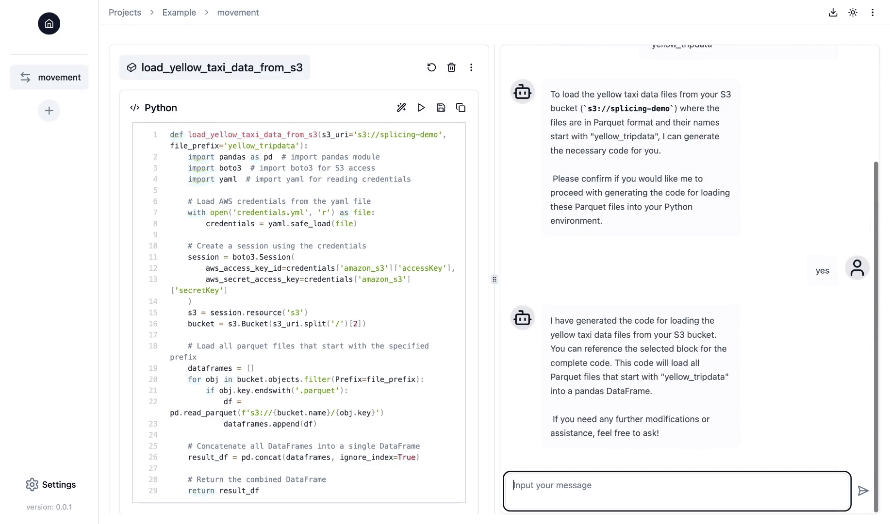
La forma más sencilla de ejecutar Splicing es en Docker:
Instale Docker.
Ejecute el siguiente comando para ejecutar Empalme:
docker run -v $( pwd ) /.splicing:/app/.splicing
-p 3000:3000
-p 8000:8000
-it --rm splicingai/splicing:latest De forma predeterminada, todos los datos de la aplicación se almacenan en la carpeta ./.splicing dentro del directorio actual donde ejecuta el comando anterior. Si desea conservar los datos, asegúrese de hacer una copia de seguridad de esta carpeta.
También puede instalar Splicing sin Docker para desarrollo siguiendo las instrucciones de la guía CONTRIBUCIÓN.
Consulte CONTRIBUTING.md para obtener más detalles.
El empalme ayuda a crear canales de datos, incluidas tareas como la ingesta, transformación y orquestación de datos, para preparar sus datos para procesos posteriores, como el análisis de datos y el aprendizaje automático.
Splicing está diseñado para ingenieros de datos, científicos de datos y cualquier persona que necesite crear canales de datos. Incluso si tiene experiencia limitada en ingeniería de datos, AI Copilot de Splicing lo guiará paso a paso y podrá pedir ayuda en cualquier momento utilizando lenguaje natural.
El empalme está diseñado específicamente para la ingeniería de datos, un campo con muchas opciones complejas que no ha adoptado completamente la IA generativa para la productividad. A diferencia de las herramientas genéricas, Splicing se centra en optimizar los modelos de lenguaje para los pasos fijos comunes en las canalizaciones de datos. También está profundamente integrado con fuentes de datos y herramientas, lo que permite al copiloto comprender el contexto de su proyecto (sus configuraciones, datos y más), lo que lleva a una generación de código más precisa y útil en comparación con los copilotos de propósito general.
Splicing es de código abierto y puede alojarse en su propia infraestructura. Sus datos y claves secretas nunca se comparten con nosotros ni con ningún proveedor de LLM por diseño. Además, Splicing Copilot no ejecuta automáticamente el código generado: usted controla cuándo y cómo se ejecuta.
¡Sí! Splicing genera código utilizando sus integraciones y herramientas de datos preferidas. Puede exportar el código con un solo clic y ejecutarlo o implementarlo en cualquier lugar que desee. No hay ningún tipo de dependencia del proveedor.


