ComfyUI N Nodes
1.0.0
Un conjunto de nodos personalizados para ComfyUI que incluye nodos de variables enteras, de cadena y flotantes, nodos GPT y nodos de vídeo.
Importante
Estos nodos se probaron principalmente en Windows en el entorno predeterminado proporcionado por ComfyUI y en el entorno creado por el cuaderno para paperspace específicamente con la imagen acoplable cyberes/gradient-base-py3.10:latest. No se ha probado ningún otro entorno.
Clona el repositorio: git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
a su directorio ComfyUI custom_nodes
IMPORTANTE: si desea los nodos GPT en la GPU, deberá ejecutar los archivos bat install_dependency . Hay 2 versiones: install_dependency_ggml_models.bat para los modelos ggmlv3 antiguos e install_dependency_gguf_models.bat para todos los modelos nuevos (GGUF). ¡SOLO PUEDES USAR UNO DE ELLOS A LA VEZ! Dado que llama-cpp-python debe compilarse a partir del código fuente para permitirle usar la GPU, primero deberá tener CUDA y Visual Studio 2019 o 2022 (en el caso de mi bat) instalados para compilarlo. Para más detalles y la guía completa puedes ir AQUÍ.
Si tiene la intención de utilizar GPTLoaderSimple con el modelo Moondream, deberá ejecutar el script 'install_extra.bat', que instalará la versión 4.36.2 de Transformers.
Reiniciar ComfyUI
En caso de que necesite revertir estos cambios (debido a incompatibilidad con otros nodos), puede utilizar el script 'remove_extra.bat'.
ComfyUI cargará automáticamente todos los scripts y nodos personalizados al inicio.
Nota
La instalación de llama-cpp-python se realizará automáticamente mediante el script. Si tiene una GPU NVIDIA, NO ES NECESARIO CONSTRUIR MÁS CUDA gracias al repositorio jllllll. También eliminé el soporte para los modelos GGMLv3 ya que todos los modelos notables ya deberían haber cambiado a la última versión de GGUF.
Nota
Desde el 14/02/2024, el nodo ha sufrido una reescritura masiva, lo que también llevó al cambio de todos los nombres de los nodos para evitar conflictos con otras extensiones en el futuro (o al menos eso espero). En consecuencia, los flujos de trabajo antiguos ya no son compatibles y requerirán el reemplazo manual de cada nodo. Para evitar esto, he creado una herramienta que permite el reemplazo automático. En Windows, simplemente arrastre cualquier flujo de trabajo *.json al archivo migrar.bat ubicado en (custom_nodes/ComfyUI-N-Nodes) y se creará otro flujo de trabajo con el sufijo _migrado en la misma carpeta que el flujo de trabajo actual. En Linux, puede utilizar el script de la siguiente manera: python libs/migrate.py ruta/to/original/workflow/. Por razones de seguridad, el flujo de trabajo original no se eliminará". Para instalar la última versión de este repositorio antes de que esto cambie desde Comfyui-N-Suite, ejecute git checkout 29b2e43baba81ee556b2930b0ca0a9c978c47083
ComfyUI-N-Nodes en custom_nodescomfyui-n-nodes en ComfyUIwebextensionsn-styles.csv y n-styles.csv.backup en ComfyUIstylesGPTcheckpoints en ComfyUImodelscustom_nodes/ComfyUI-N-Nodesgit pull
El nodo LoadVideoAdvanced permite cargar un archivo de vídeo y extraer fotogramas del mismo. El nombre se ha cambiado de LoadVideo a LoadVideoAdvanced para evitar conflictos con el nodo animado LoadVideo .
video : seleccione el archivo de video para cargar.framerate : elija si desea mantener la velocidad de fotogramas original o reducirla a la mitad o a un cuarto de la velocidad.resize_by : seleccione cómo cambiar el tamaño de los marcos: 'ninguno', 'alto' o 'ancho'.size : tamaño objetivo si se cambia el tamaño por alto o ancho.images_limit : limita el número de fotogramas a extraer.batch_size : tamaño de lote para codificar fotogramas.starting_frame : seleccione desde qué marco comenzar.autoplay : seleccione si desea reproducir automáticamente el vídeo.use_ram : utiliza RAM en lugar de disco para descomprimir fotogramas de vídeo. IMAGES : Imágenes de cuadros extraídas como tensores de PyTorch.LATENT : Vectores latentes vacíos.METADATA : Metadatos de vídeo: FPS y número de fotogramas.WIDTH: Ancho del marco.HEIGHT : Altura del marco.META_FPS : velocidad de fotogramas.META_N_FRAMES : Número de fotogramas.El nodo extrae fotogramas del vídeo de entrada a la velocidad de fotogramas especificada. Cambia el tamaño de los fotogramas si se elige y los devuelve como lotes de tensores de imágenes de PyTorch junto con vectores latentes, metadatos y dimensiones de fotogramas.
El nodo SaveVideo toma fotogramas extraídos y los guarda como un archivo de vídeo. 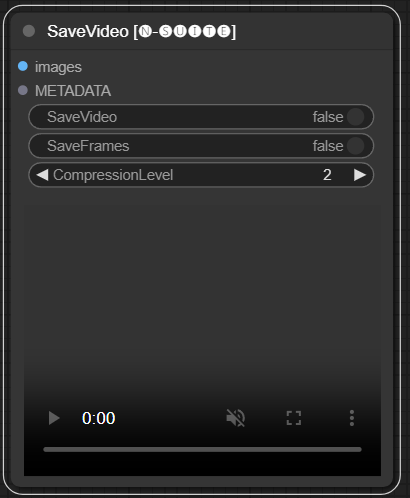
images : enmarca imágenes como tensores.METADATA : Metadatos del nodo LoadVideo.SaveVideo : alterna guardar el archivo de vídeo de salida.SaveFrames : alterna guardar marcos en una carpeta.CompressionLevel : nivel de compresión PNG para guardar fotogramas. Guarda el archivo de vídeo de salida y/o los fotogramas extraídos.
El nodo toma fotogramas y metadatos extraídos y puede guardarlos como un nuevo archivo de vídeo y/o imágenes de fotogramas individuales. Se puede configurar la compresión de vídeo y la compresión de cuadros PNG. NOTA: Si está utilizando LoadVideo como fuente de los fotogramas, el audio del archivo original se mantendrá, pero sólo en caso de que el límite de imágenes y el fotograma inicial sean iguales a cero.
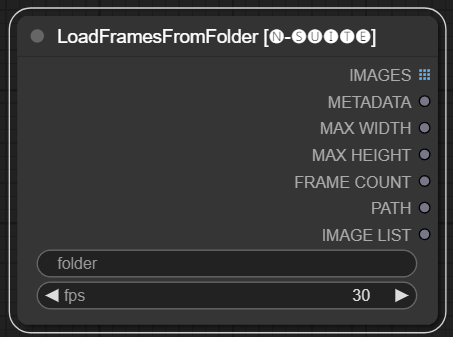
El nodo LoadFramesFromFolder permite cargar marcos de imágenes desde una carpeta y devolverlos como un lote.
folder : Ruta a la carpeta que contiene las imágenes del marco. Debe tener formato png, nombrado con un número (por ejemplo, 1.png o incluso 0001.png). Las imágenes se cargarán secuencialmente.fps : fotogramas por segundo para asignar a los fotogramas cargados. IMAGES : Lote de imágenes de cuadros cargados como tensores de PyTorch.METADATA : Metadatos que contienen el valor de FPS establecido.MAX_WIDTH : ancho máximo del marco.MAX_HEIGHT : Altura máxima del marco.FRAME COUNT : Número de cuadros en la carpeta.PATH : Ruta a la carpeta que contiene las imágenes del marco.IMAGE LIST : Lista de imágenes de fotogramas en la carpeta (no es una lista real, solo una cadena dividida por n).El nodo carga todos los archivos de imagen de la carpeta especificada, los convierte a tensores de PyTorch y los devuelve como un tensor por lotes junto con metadatos simples que contienen el valor de FPS establecido.
Esto permite cargar fácilmente un conjunto de fotogramas que fueron extraídos y guardados previamente, por ejemplo, para recargarlos y procesarlos nuevamente. Al establecer el valor de FPS, los fotogramas se pueden interpretar correctamente como una secuencia de vídeo.
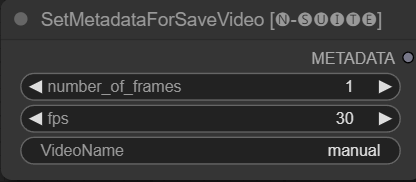
El nodo SetMetadataForSaveVideo permite configurar metadatos para el nodo SaveVideo.
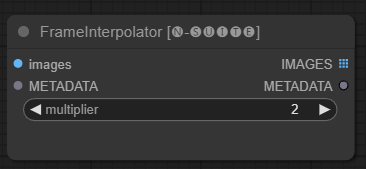
El nodo FrameInterpolator permite interpolar entre fotogramas de vídeo extraídos para aumentar la velocidad de fotogramas y suavizar el movimiento.
images : Imágenes de fotogramas extraídas como tensores.METADATA : Metadatos del vídeo: FPS y número de fotogramas.multiplier : Factor por el cual aumentar la velocidad de fotogramas. IMAGES : Cuadros interpolados como tensores de imágenes.METADATA : Metadatos actualizados con nueva velocidad de fotogramas.El nodo toma fotogramas y metadatos extraídos como entrada. Utiliza un modelo de interpolación (RIFE) para generar fotogramas intermedios adicionales a una velocidad de fotogramas más alta.
La velocidad de fotogramas original en los metadatos se multiplica por el valor multiplier para obtener la nueva velocidad de fotogramas interpolada.
Los fotogramas interpolados se devuelven como un lote de tensores de imagen, junto con metadatos actualizados que contienen la nueva velocidad de fotogramas.
Esto permite aumentar la velocidad de fotogramas de un vídeo existente para lograr un movimiento más fluido y una reproducción más lenta. El modelo de interpolación crea nuevos fotogramas realistas para llenar los huecos en lugar de simplemente duplicar los fotogramas existentes.
El código original ha sido tomado de AQUÍ.
Dado que el nodo primitivo tiene limitaciones en los enlaces (por ejemplo, en el momento en que escribo no se puede vincular "start_at_step" y "steps" de otro ksampler juntos), decidí crear estas variables de nodo simples para evitar esta limitación. variables son:
Estos nodos personalizados están diseñados para mejorar las capacidades del marco ConfyUI al permitir la generación de texto utilizando modelos GGUF GPT. Este README proporciona una descripción general de los dos nodos personalizados y su uso dentro de ConfyUI.
Puedes agregar en extra_model_paths.yaml la ruta donde está tu modelo GGUF de esta manera (ejemplo):
other_ui: base_path: I:\text-generation-webui GPTcheckpoints: models/
De lo contrario, creará una carpeta GPTcheckpoints en la carpeta de modelos de ComfyUI donde podrá colocar sus modelos .gguf.
También se han creado dos carpetas dentro del directorio 'Llava' en la carpeta 'GPTcheckpoints' del modelo LLava:
clips : esta carpeta está designada para almacenar los clips de sus modelos LLava (generalmente, archivos que comienzan con mm en el repositorio). models : esta carpeta está diseñada para almacenar los modelos LLava.
Estos nodos en realidad admiten 4 modelos diferentes:
Los modelos GGUF se pueden descargar desde Huggingface Hub
AQUÍ un vídeo de un ejemplo de cómo utilizar los modelos GGUF de boricuapab
Aquí una pequeña lista de los modelos soportados por estos nodos:
LlaVa 1.5 7B LlaVa 1.5 13B LlaVa 1.6 Mistral 7B BakLLaVa Nous Hermes 2 Visión
####Ejemplo con modelo Llama: 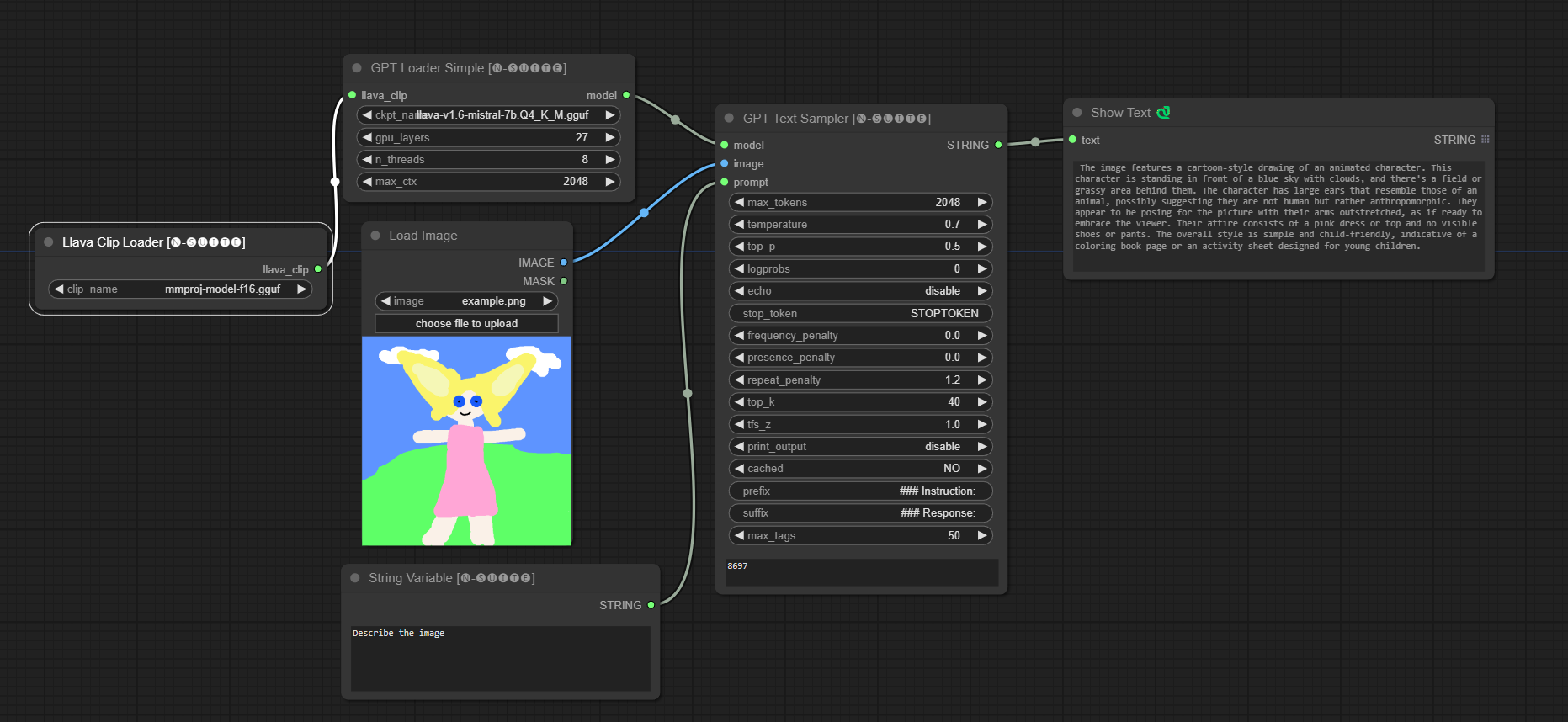
El modelo se descargará automáticamente cuando lo ejecute por primera vez. De todos modos, está disponible AQUÍ El código extraído de este repositorio
####Ejemplo con el modelo Moondream: 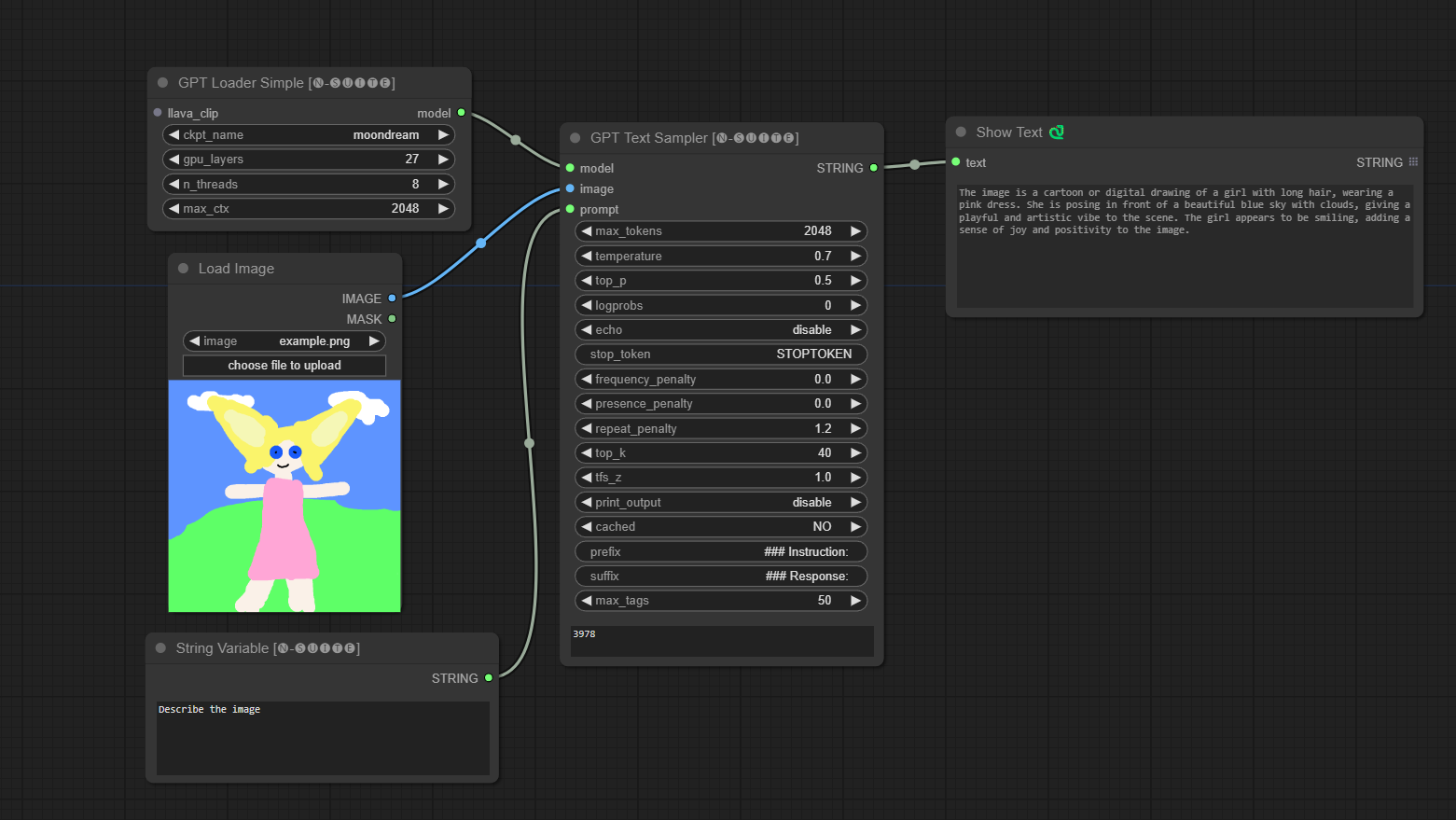
El modelo se descargará automáticamente cuando lo ejecute por primera vez. De todos modos, está disponible AQUÍ El código extraído de este repositorio
####Ejemplo con el modelo Joytag: 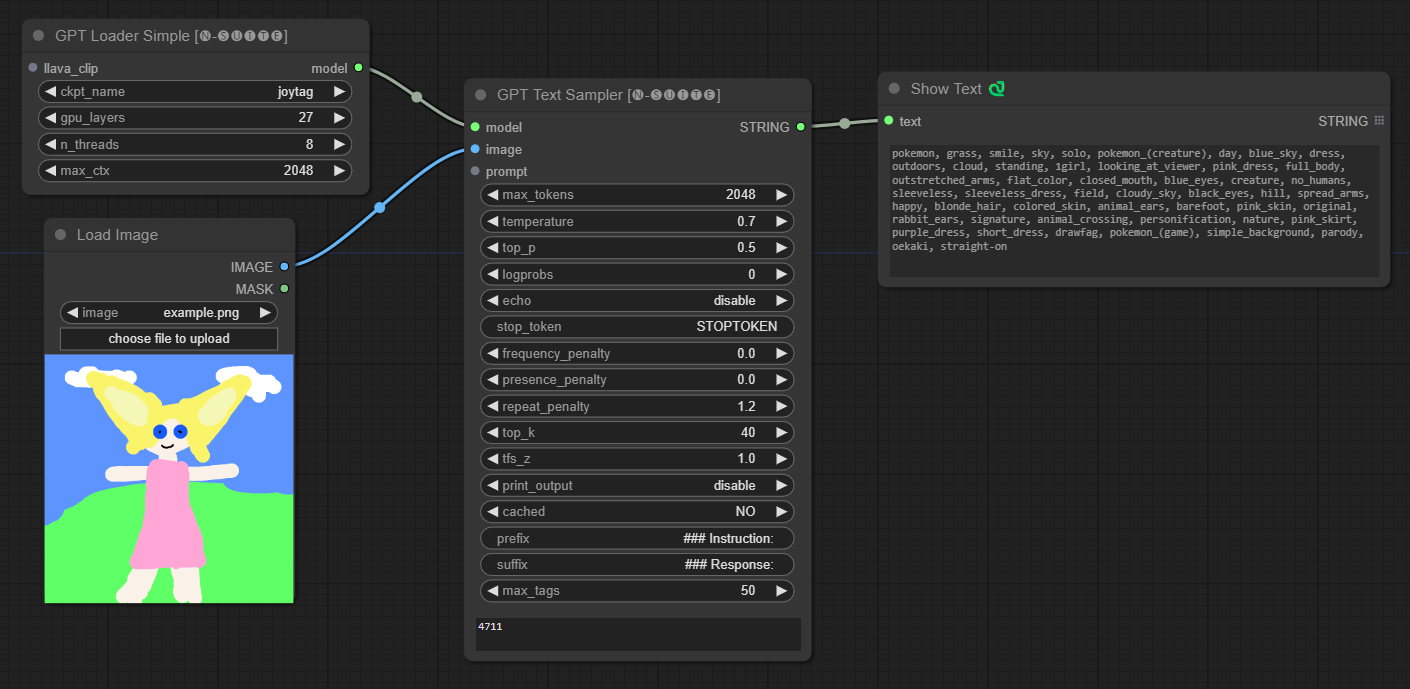
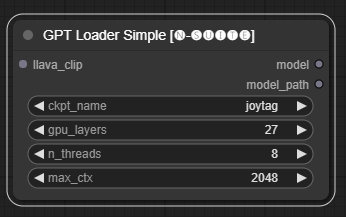
El nodo GPTLoaderSimple es responsable de cargar los puntos de control del modelo GPT y crear una instancia de la biblioteca Llama para la generación de texto. Proporciona una interfaz para configurar capas de GPU, la cantidad de subprocesos y el contexto máximo para la generación de texto.
ckpt_name : seleccione el nombre del punto de control GPT entre las opciones disponibles (joytag y moondream se descargarán automáticamente la primera vez).gpu_layers : especifique la cantidad de capas de GPU que se usarán (predeterminado: 27).n_threads : especifica el número de subprocesos para la generación de texto (predeterminado: 8).max_ctx : especifica la longitud máxima del contexto para la generación de texto (predeterminado: 2048). El nodo devuelve una instancia de la biblioteca Llama (MODEL) y la ruta al punto de control cargado (STRING).
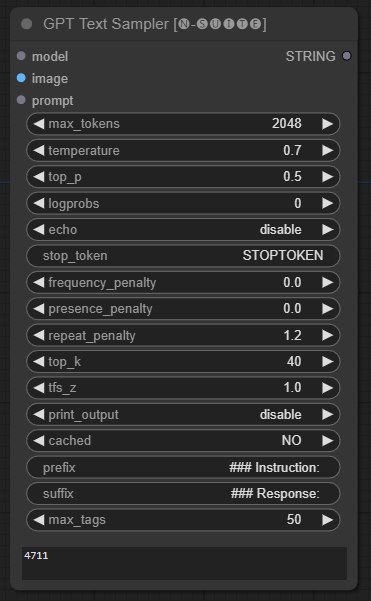
El nodo GPTSampler facilita la generación de texto utilizando modelos GPT basados en el mensaje de entrada y varios parámetros de generación. Le permite controlar aspectos como la temperatura, el muestreo superior, las penalizaciones y más.
prompt : ingrese el mensaje de entrada para la generación de texto.image : Entrada de imagen para los modelos Joytag, moondream y llama.model : elija el modelo GPT que se utilizará para la generación de texto.max_tokens : establece el número máximo de tokens en el texto generado (predeterminado: 128).temperature : establece el parámetro de temperatura para aleatoriedad (predeterminado: 0,7).top_p : establece la probabilidad top-p para el muestreo de núcleos (predeterminado: 0,5).logprobs : especifique el número de probabilidades de registro que se generarán (predeterminado: 0).echo : habilita o deshabilita la impresión del mensaje de entrada junto con el texto generado.stop_token : especifique el token en el que se detiene la generación de texto.frequency_penalty , presence_penalty , repeat_penalty : controla las penalizaciones por generación de palabras.top_k : establece los tokens top-k a considerar durante la generación (predeterminado: 40).tfs_z : establece el factor de escala de temperatura para las muestras más frecuentes (predeterminado: 1,0).print_output : habilita o deshabilita la impresión del texto generado en la consola.cached : elija si desea utilizar la generación en caché (predeterminado: NO).prefix , suffix : especifique el texto que se antepondrá y agregará al mensaje.max_tags : esto solo afecta la cantidad máxima de etiquetas generadas por joydag. El nodo devuelve el texto generado junto con una representación compatible con la interfaz de usuario.
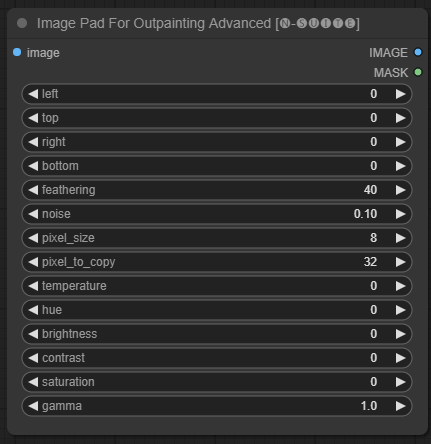
El nodo ImagePadForOutpaintingAdvanced es una alternativa al nodo ImagePadForOutpainting que aplica la técnica que se ve en este vídeo bajo la máscara de pintura exterior. La parte de corrección de color se tomó de este nodo personalizado de Sipherxyz.
image : Entrada de imagen.left : píxel para extender desde la izquierda,top : píxel que se extenderá desde arriba,right : píxel que se extenderá desde la derecha,bottom : píxel que se extenderá desde abajo.feathering : fuerza de desvanecimientonoise : mezcla la fuerza del ruido y el borde copiadopixel_size : qué tan grande será el píxel en el efecto pixeladopixel_to_copy : cuántos píxeles copiar (de cada lado)temperature : configuración de corrección de color que solo se aplica a la parte de la máscara.hue : configuración de corrección de color que solo se aplica a la parte de la máscara.brightness : configuración de corrección de color que solo se aplica a la parte de la máscara.contrast : configuración de corrección de color que solo se aplica a la parte de la máscara.saturation : configuración de corrección de color que solo se aplica a la parte de la máscara.gamma : configuración de corrección de color que solo se aplica a la parte de la máscara. El nodo devuelve la imagen procesada y la máscara.

El nodo DynamicPrompt genera mensajes combinando un mensaje fijo con una selección aleatoria de etiquetas de un mensaje variable. Esto permite la generación de mensajes flexibles y dinámicos para diversos casos de uso.
variable_prompt : ingrese la solicitud de variable para la selección de etiquetas.cached : elija si desea almacenar en caché el mensaje generado (predeterminado: NO).number_of_random_tag : elija entre "Fijo" y "Aleatorio" para la cantidad de etiquetas aleatorias que se incluirán.fixed_number_of_random_tag : Si number_of_random_tag si es "Fijo" Especifique el número de etiquetas aleatorias que se incluirán (predeterminado: 1).fixed_prompt (opcional): ingrese el mensaje fijo para generar el mensaje final. El nodo devuelve el mensaje generado, que es una combinación del mensaje fijo y etiquetas aleatorias seleccionadas.
variable_prompt con la etiqueta separada por comas, el fixed_prompt es opcional 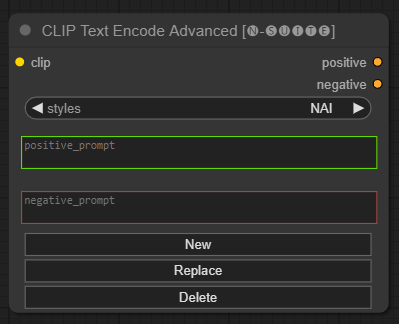
El nodo CLIP Text Encode Advanced es una alternativa al nodo CLIP Text Encode estándar. Ofrece soporte para Agregar/Reemplazar/Eliminar estilos, lo que permite la inclusión de mensajes positivos y negativos dentro de un solo nodo.
El archivo de estilo base se llama n-styles.csv y se encuentra en la carpeta ComfyUIstyles . El archivo de estilos sigue el mismo formato que el archivo styles.csv actual utilizado en A1111 (al momento de escribir este artículo).
NOTA: esta nota es experimental y todavía tiene muchos errores.
clip : entrada de clipstyle : completará automáticamente las indicaciones positivas y negativas según el estilo elegido positive : condiciones positivasnegative : condiciones negativas No dude en contribuir a este proyecto informando problemas o sugiriendo mejoras. Abra una incidencia o envíe una solicitud de extracción en el repositorio de GitHub.
Este proyecto está bajo la licencia MIT. Consulte el archivo de LICENCIA para obtener más detalles.


