JoyVASA
1.0.0
Xuyang Cao 1* Guoxin Wang 12* Sheng Shi 1* Jun Zhao 1 Yang Yao 1
Jintao Fei 1 Minyu Gao 1
1 JD Health International Inc. 2 Universidad de Zhejiang
La animación de retratos basada en audio ha logrado avances significativos con modelos basados en difusión, mejorando la calidad del video y la precisión de la sincronización de labios. Sin embargo, la creciente complejidad de estos modelos ha provocado ineficiencias en el entrenamiento y la inferencia, así como limitaciones en la duración del vídeo y la continuidad entre cuadros. En este artículo, proponemos JoyVASA, un método basado en difusión para generar dinámica facial y movimiento de la cabeza en animación facial basada en audio. Específicamente, en la primera etapa, introducimos un marco de representación facial desacoplado que separa las expresiones faciales dinámicas de las representaciones faciales estáticas en 3D. Este desacoplamiento permite que el sistema genere videos más largos combinando cualquier representación facial estática en 3D con secuencias de movimiento dinámico. Luego, en la segunda etapa, se entrena un transformador de difusión para generar secuencias de movimiento directamente a partir de señales de audio, independientemente de la identidad del personaje. Finalmente, un generador entrenado en la primera etapa utiliza la representación facial 3D y las secuencias de movimiento generadas como entradas para generar animaciones de alta calidad. Con la representación facial desacoplada y el proceso de generación de movimiento independiente de la identidad, JoyVASA va más allá de los retratos humanos para animar rostros de animales sin problemas. El modelo se entrena en un conjunto de datos híbrido de datos privados en chino y públicos en inglés, lo que permite soporte multilingüe. Los resultados experimentales validan la eficacia de nuestro enfoque. El trabajo futuro se centrará en mejorar el rendimiento en tiempo real y perfeccionar el control de la expresión, ampliando aún más las aplicaciones del marco en la animación de retratos.
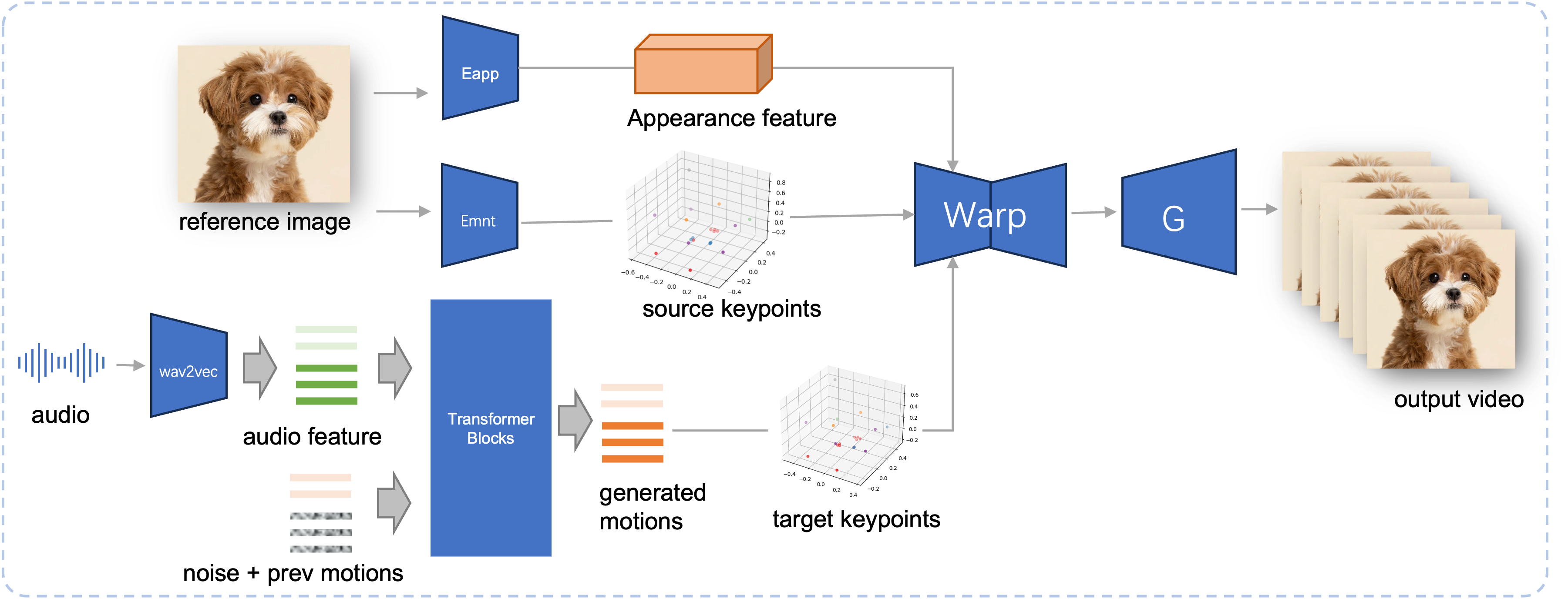
Canal de inferencia del JoyVASA propuesto. Dada una imagen de referencia, primero extraemos la característica de apariencia facial 3D usando el codificador de apariencia en LivePortrait, y también una serie de puntos clave 3D aprendidos usando el codificador de movimiento. Para la voz de entrada, las características de audio se extraen inicialmente utilizando el codificador wav2vec2. Luego, las secuencias de movimiento impulsadas por audio se muestrean utilizando un modelo de difusión entrenado en la segunda etapa en forma de ventana deslizante. Utilizando los puntos clave 3D de la imagen de referencia y las secuencias de movimiento del objetivo muestreadas, se calculan los puntos clave del objetivo. Finalmente, la característica de apariencia facial 3D se deforma según los puntos clave de origen y de destino y un generador la procesa para producir el vídeo de salida final.
Requisitos del sistema:
Ubuntu:
Probado en Ubuntu 20.04, Cuda 11.3
GPU probadas: A100
Ventanas:
Probado en Windows 11, CUDA 12.1
GPU probadas: GPU VRAM de 8 GB para computadora portátil RTX 4060
Crear ambiente:
# 1. Crear entorno baseconda create -n joyvasa python=3.10 -y conda activar joyvasa # 2. Instalar requisitospip install -r requisitos.txt# 3. Instalar ffmpegsudo apt-get update sudo apt-get install ffmpeg -y# 4. Instale MultiScaleDeformableAttentioncd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build installcd - # igual a cd ../../../../../../../
Asegúrate de tener instalado git-lfs y descarga todos los siguientes puntos de control en pretrained_weights :
instalación de git lfs clon de git https://huggingface.co/jdh-algo/JoyVASA
Admitimos dos tipos de codificadores de audio, incluidos wav2vec2-base y hubert-chinese.
Ejecute los siguientes comandos para descargar pesas previamente entrenadas en hubert-chinese:
instalación de git lfs clon de git https://huggingface.co/TencentGameMate/chinese-hubert-base
Para obtener los pesos previamente entrenados en wav2vec2-base, ejecute los siguientes comandos:
instalación de git lfs clon de git https://huggingface.co/facebook/wav2vec2-base-960h
Nota
El modelo de generación de movimiento con codificador wav2vec2 será compatible más adelante.
# !pip install -U "huggingface_hub[cli]"huggingface-cli descargar KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
Consulte Liveportrait para conocer más métodos de descarga.
pretrained_weights El directorio final pretrained_weights debería verse así:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.jsonNota
La carpeta TencentGameMate:chinese-hubert-base en Windows debería cambiarse de nombre a chinese-hubert-base .
Animal:
python inference.py -r activos/examples/imgs/joyvasa_001.png -a activos/examples/audios/joyvasa_001.wav --animation_mode animal --cfg_scale 2.0
Humano:
python inference.py -r activos/examples/imgs/joyvasa_003.png -a activos/examples/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
Puedes cambiar cfg_scale para obtener resultados con diferentes expresiones y poses.
Nota
Si el modo de animación y la imagen de referencia no coinciden, se pueden producir resultados incorrectos.
Utilice el siguiente comando para iniciar la demostración web:
aplicación python.py
La demostración se creará en http://127.0.0.1:7862.
Si encuentra útil nuestro trabajo, considere citarnos:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}Nos gustaría agradecer a los contribuyentes de los repositorios LivePortrait, Open Facevid2vid, InsightFace, X-Pose, DiffPoseTalk, Hallo, wav2vec 2.0, Chinese Speech Pretrain, Q-Align, Syncnet y VBench, por su investigación abierta y su extraordinario trabajo.


