wikisearch
1.0.0
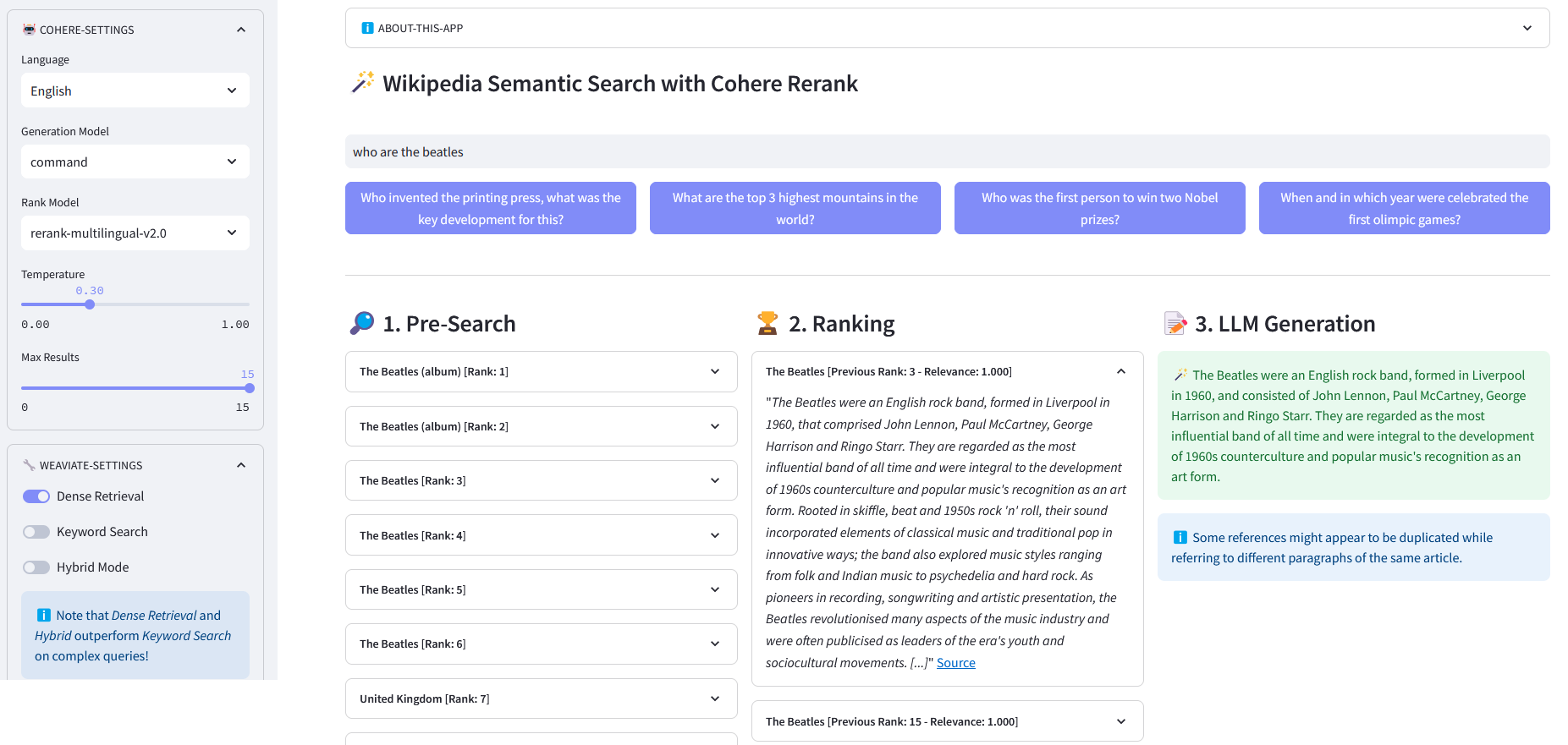
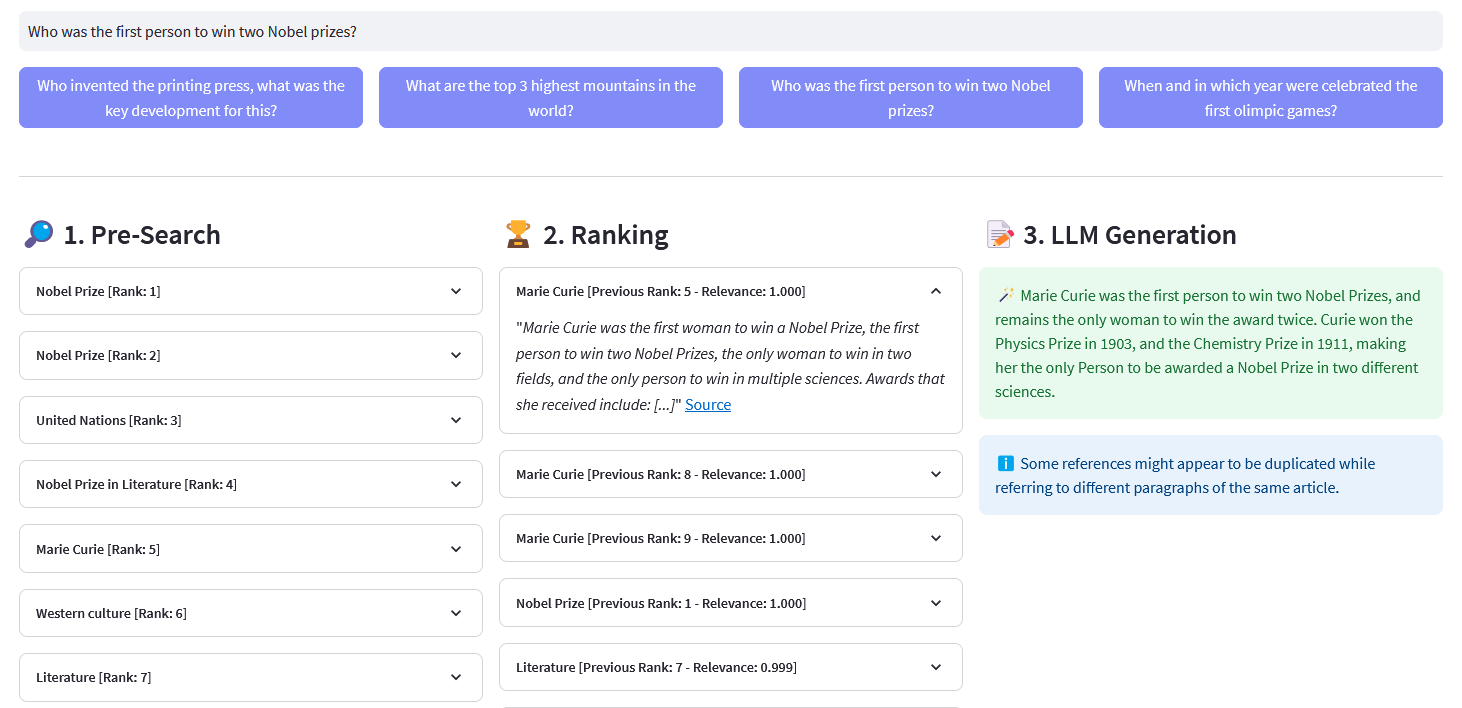
Aplicación Streamlit para búsqueda semántica multilingüe en más de 10 millones de documentos de Wikipedia vectorizados en incrustaciones por Weaviate. Esta implementación se basa en el blog de Cohere ´Using LLMs for Search´ y su cuaderno correspondiente. Permite comparar el rendimiento de la búsqueda de palabras clave , la recuperación densa y la búsqueda híbrida para consultar el conjunto de datos de Wikipedia. Además, demuestra el uso de Cohere Rerank para mejorar la precisión de los resultados y Cohere Generate para proporcionar una respuesta basada en dichos resultados clasificados.
La búsqueda semántica se refiere a algoritmos de búsqueda que consideran la intención y el significado contextual de las frases de búsqueda al generar resultados, en lugar de centrarse únicamente en la concordancia de palabras clave. Proporciona resultados más precisos y relevantes al comprender la semántica o significado detrás de la consulta.
Una incrustación es un vector (lista) de números de punto flotante que representan datos como palabras, oraciones, documentos, imágenes o audio. Dicha representación numérica captura el contexto, jerarquía y similitud de los datos. Se pueden utilizar para tareas posteriores como clasificación, agrupación, detección de valores atípicos y búsqueda semántica.
Las bases de datos vectoriales, como Weaviate, están diseñadas específicamente para optimizar las capacidades de almacenamiento y consulta para incrustaciones. En la práctica, una base de datos vectorial utiliza una combinación de diferentes algoritmos que participan en la búsqueda del vecino más cercano aproximado (ANN). Estos algoritmos optimizan la búsqueda mediante hash, cuantificación o búsqueda basada en gráficos.
Búsqueda previa : Búsqueda previa en incrustaciones de Wikipedia con concordancia de palabras clave , recuperación densa o búsqueda híbrida :
Keyword Matching: busca objetos que contengan los términos de búsqueda en sus propiedades. Los resultados se puntúan según la función BM25F:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" Realiza una palabra clave búsqueda (recuperación escasa) en artículos de Wikipedia que utilizan incrustaciones almacenadas en Weaviate Parámetros: - consulta (cadena): la consulta de búsqueda. lang (cadena, opcional): el idioma de los artículos. El valor predeterminado es 'en' - top_n (int, opcional): el número de resultados principales a devolver es 10. Devuelve: - lista: lista de los artículos principales basados en. Puntuación BM25F """logging.info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response =. (self.weaviate.query.get("Artículos", self.WIKIPEDIA_PROPERTIES)
.with_bm25(consulta=consulta)
.with_where(dónde_filtro)
.with_limit(top_n)
.hacer()
)devolver respuesta["datos"]["Obtener"]["Artículos"]Recuperación densa: busque objetos más similares a un texto sin formato (no vectorizado):
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" Realiza una semántica búsqueda (recuperación densa) en artículos de Wikipedia que utilizan incrustaciones almacenadas en Weaviate Parámetros: - consulta (cadena): la consulta de búsqueda. lang (cadena, opcional): el idioma de los artículos. El valor predeterminado es 'en' - top_n (int, opcional): el número de resultados principales a devolver es 10. Devuelve: - lista: lista de los artículos principales basados en. similitud semántica """logging.info("with_neartext()")nearText = {"conceptos": [consulta]
}where_filter = {"ruta": ["idioma"],"operador": "Equal","valueString": lang}respuesta = (self.weaviate.query.get("Artículos", self.WIKIPEDIA_PROPERTIES)
.with_near_text(cerca deTexto)
.with_where(dónde_filtro)
.with_limit(top_n)
.hacer()
)devolver respuesta['datos']['Obtener']['Artículos']Búsqueda híbrida: produce resultados basados en una combinación ponderada de resultados de una búsqueda de palabra clave (bm25) y una búsqueda de vector.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" Realiza un híbrido buscar en artículos de Wikipedia utilizando incrustaciones almacenadas en Weaviate Parámetros: - consulta (cadena): la consulta de búsqueda - idioma (cadena, opcional): el idioma. de los artículos. El valor predeterminado es 'en'. - top_n (int, opcional): el número de resultados principales que se devolverán. El valor predeterminado es 10. Devuelve: - lista: lista de los artículos principales según la puntuación híbrida """logging.info. ("with_hybrid()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_hybrid(consulta=consulta)
.with_where(dónde_filtro)
.with_limit(top_n)
.hacer()
)devolver respuesta["datos"]["Obtener"]["Artículos"]ReRank : Cohere Rerank reorganiza la búsqueda previa asignando una puntuación de relevancia a cada resultado de la búsqueda previa dada la consulta de un usuario. En comparación con la búsqueda semántica basada en incrustaciones, produce mejores resultados de búsqueda, especialmente para consultas complejas y específicas de un dominio.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(self, consulta, documentos, top_n=10, model='rerank-english-v2.0') -> dict:""" Reclasifica una lista de respuestas utilizando la API de reclasificación de Cohere. Parámetros: - consulta (cadena): la consulta de búsqueda. - documentos (lista): Lista de documentos que se reclasificarán. - top_n (int, opcional): el número de resultados reclasificados principales que se devolverán. El valor predeterminado es 10. - modelo: el modelo que se utilizará para la reclasificación es 'rerank-english-v2. .0'. Devuelve: - dict: Documentos reclasificados de la API de Cohere """return self.cohere.rerank(query=query, documents=documents, top_n=top_n, modelo = modelo)
Fuente: Coherir
Generación de respuestas : Cohere Generate redacta una respuesta basada en los resultados clasificados.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, contexto, consulta, temperatura=0.2, model="command", lang="english") -> list:prompt = f""" Utiliza la información proporcionada a continuación para responder las preguntas al final. / Incluye algunos datos curiosos o relevantes extraídos del contexto. / Genera la respuesta en el idioma del consulta. Si no puede determinar el idioma de la consulta, utilice {lang}. / Si la respuesta a la pregunta no está contenida en la información proporcionada, genere "La respuesta no está en el contexto". } --- Pregunta: {consulta} """return self.cohere.generate(prompt=prompt,num_generaciones=1,max_tokens=1000,temperatura=temperatura,model=modelo,
)Clonar el repositorio:
[email protected]:dcarpintero/wikisearch.git
Cree y active un entorno virtual:
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
Instalar dependencias:
pip install -r requirements.txt
Iniciar aplicación web
streamlit run ./app.py
Aplicación web de demostración implementada en Streamlit Cloud y disponible en https://wikisearch.streamlit.app/
Reordenar Cohere
Nube iluminada
Los archivos de incrustación: millones de incrustaciones de artículos de Wikipedia en muchos idiomas
Uso de LLM para búsquedas con recuperación densa y reclasificación
Bases de datos vectoriales
Búsqueda de vectores Weaviate
Búsqueda Weaviate BM25
Búsqueda híbrida de Weaviate


