En esta práctica de laboratorio, pondremos en práctica las fórmulas matemáticas que vimos en la lección anterior para ver cómo funciona MLE con distribuciones normales.
Podrás:
Nota: *En este sitio web se puede ver una derivación detallada de todas las ecuaciones MLE con pruebas. *
Veamos a continuación un ejemplo de MLE y ajustes de distribución con Python. Aquí scipy.stats.norm.fit calcula los parámetros de distribución utilizando la estimación de máxima verosimilitud.
from scipy . stats import norm # for generating sample data and fitting distributions
import matplotlib . pyplot as plt
plt . style . use ( 'seaborn' )
import numpy as np sample = Nonestats.norm.fit(data) para ajustar una distribución a los datos anteriores. param = None
#param[0], param[1]
# (0.08241224761452863, 1.002987490235812)x = np.linspace(-5,5,100) x = np . linspace ( - 5 , 5 , 100 )
# Generate the pdf from fitted parameters (fitted distribution)
fitted_pdf = None
# Generate the pdf without fitting (normal distribution non fitted)
normal_pdf = None # Your code here 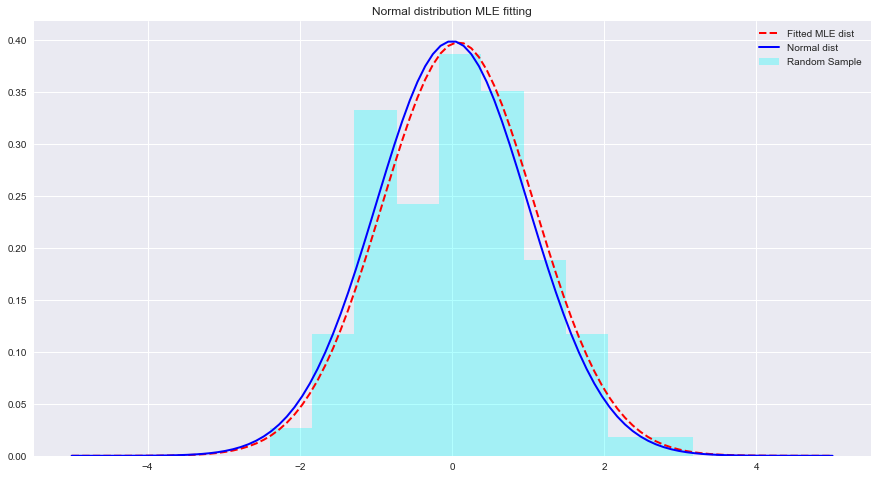
# Your comments/observations En esta breve práctica de laboratorio, analizamos la configuración bayesiana en un contexto gaussiano, es decir, cuando las variables aleatorias subyacentes se distribuyen normalmente. Aprendimos que MLE puede estimar los parámetros desconocidos de una distribución normal maximizando la probabilidad de la media esperada. La media esperada se acerca mucho a la media de una distribución normal no ajustada dentro de ese espacio de parámetros. Avanzaremos con esta comprensión para aprender cómo se realizan dichas estimaciones al estimar medias de varias clases presentes en la distribución de datos utilizando el clasificador Naive Bayes.


