Chatbot transformador con TensorFlow 2
Cree un chatbot de un extremo a otro con Transformer en TensorFlow 2. Consulte mi tutorial en blog.tensorflow.org.
Actualizaciones
- 16 de junio de 2022:
- Actualice el script
setup.sh para instalar la versión Apple Silicon de TensorFlow 2.9 (úselo solo si se siente aventurero). - Se actualizaron las dos capas personalizadas,
PositionalEncoding y MultiHeadAttentionLayer , para permitir guardar el modelo mediante model.save() o tf.keras.models.save_model() . -
train.py muestra cómo llamar model.save() y tf.keras.models.load_model() .
- 8 de diciembre de 2020: compatibilidad actualizada con TensorFlow 2.3.1 y TensorFlow Datasets 4.1.0
- 18 de enero de 2020: Se agregó una computadora portátil con soporte de TPU de Google Colab en TensorFlow 2.1.
Paquetes
- TensorFlow 2.9.1
- Conjuntos de datos de TensorFlow
Configuración
- crear un nuevo entorno anaconda e inicializar
chatbot del entorno conda create -n chatbot python=3.8
conda activate chatbot
- ejecutar script de instalación
- Nota: el script instalaría CUDA y cuDNN a través de conda si se instala en un sistema Linux, o
tensorflow-metal para dispositivos con Apple Silicon (tenga en cuenta que hay toneladas de errores con TensorFlow en la GPU de Apple Silicon, por ejemplo, el optimizador Adam no funciona).
Conjunto de datos
- Usaremos como nuestro conjunto de datos las conversaciones en películas y programas de televisión proporcionadas por Cornell Movie-Dialogs Corpus, que contiene más de 220.000 intercambios conversacionales entre más de 10.000 pares de personajes de películas.
- Preprocesamos nuestro conjunto de datos en el siguiente orden:
- Extraiga los pares de conversación
max_samples en una lista de questions y answers . - Preprocese cada oración eliminando caracteres especiales en cada oración.
- Cree un tokenizador (asigne texto a ID y ID a texto) utilizando TensorFlow Datasets SubwordTextEncoder.
- Tokenice cada oración y agregue
start_token y end_token para indicar el inicio y el final de cada oración. - Filtre la oración que tenga más de tokens
max_length . - Rellenar oraciones tokenizadas a
max_length
- Verifique la implementación de dataset.py.
Modelo
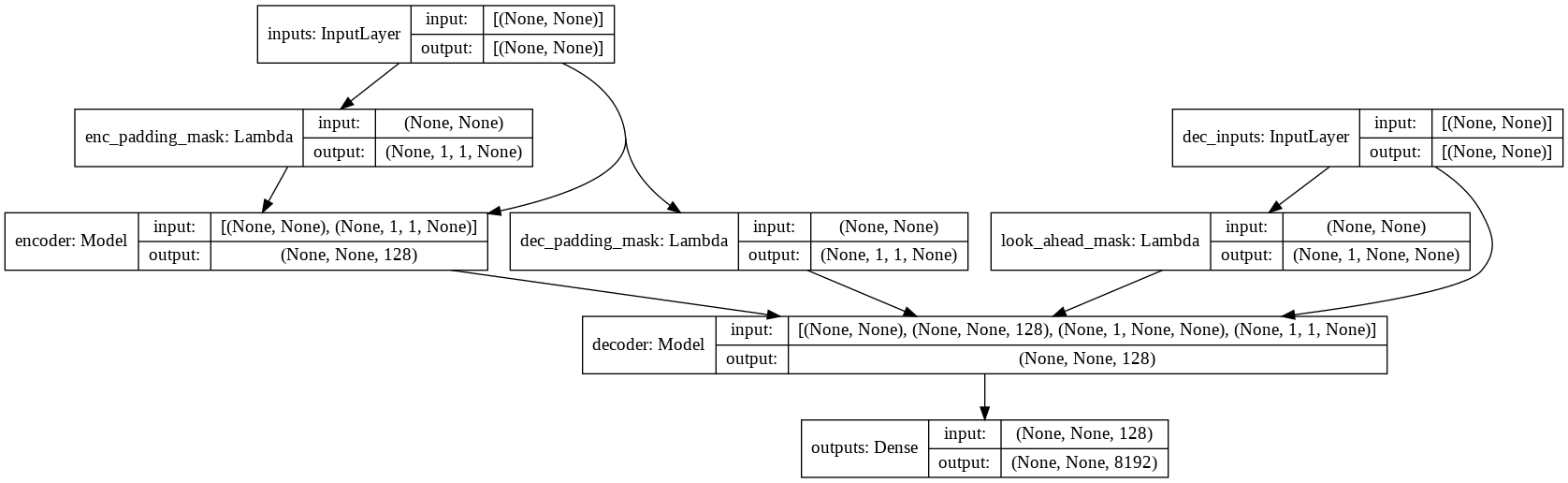
- consulte model.py para conocer la implementación de atención de múltiples cabezas, codificación posicional y transformador.
Correr
- verifique todos los indicadores e hiperparámetros disponibles
python main.py --help
python train.py --output_dir runs/save_model --batch_size 256 --epochs 50 --max_samples 50000
- El modelo entrenado final se guardará en
runs/save_model .
Muestras
input: where have you been?
output: i m not talking about that .
input: it's a trap!
output: no , it s not .


