alfresco ai framework
1.0.0
Alfresco AI Framework es un marco robusto diseñado para integrar capacidades de IA en Alfresco, aprovechando Java y Spring AI. Proporciona un conjunto de herramientas y servicios para procesar, analizar y mejorar el contenido de los documentos en Alfresco utilizando modelos de inteligencia artificial y aprendizaje automático.
Nota : Este proyecto utiliza la versión Spring AI SNAPSHOT, ya que una VERSIÓN final aún no está disponible.
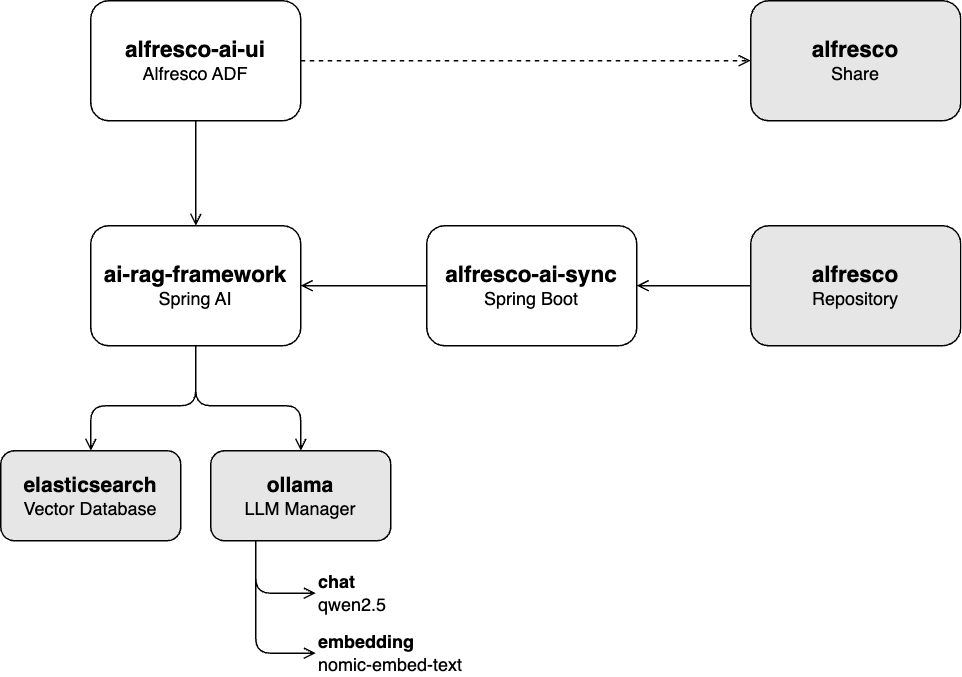
ai-rag-framework :
Una API REST construida sobre Spring AI para ingerir documentos en un modelo de IA generativa (GenAI) y proporcionar un servicio de chat de recuperación-generación aumentada (RAG).
sincronización-ai-al aire libre :
Un servicio creado sobre el SDK de Java de Alfresco que recupera documentos del repositorio de Alfresco y los ingiere en la base de datos vectorial a través de la API ai-rag-framework .
ai-rag-framework al aire libre-ai-ui :
Una interfaz de usuario construida sobre Alfresco ADF para interactuar con el servicio de chat RAG proporcionado por ai-rag-framework .
ai-rag-framework debe estar ejecutándosealfresco-docker : Implementación de Alfresco Community 23.3 orientada a contenedores
Esta serie de tutoriales lo guiará a través de las características clave del proyecto, incluida la ingesta de datos, la integración del chat y el funcionamiento general del sistema.
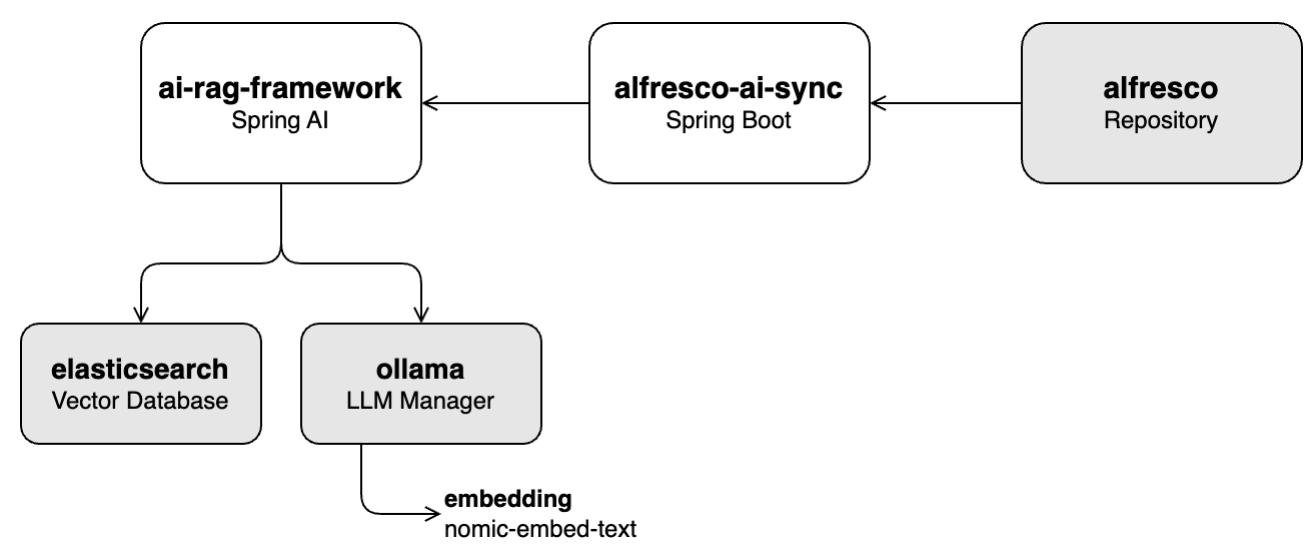
En esta práctica de laboratorio, aprenderá cómo completar la base de datos de vectores (Elasticsearch) con contenido seleccionado de la base de conocimientos almacenada en Alfresco. Esto implica extraer vectores del contenido utilizando el módulo de incrustación nomic-embed-text a través de Ollama.
Comience la práctica de laboratorio siguiendo el Laboratorio 1: Tubería de ingestión.
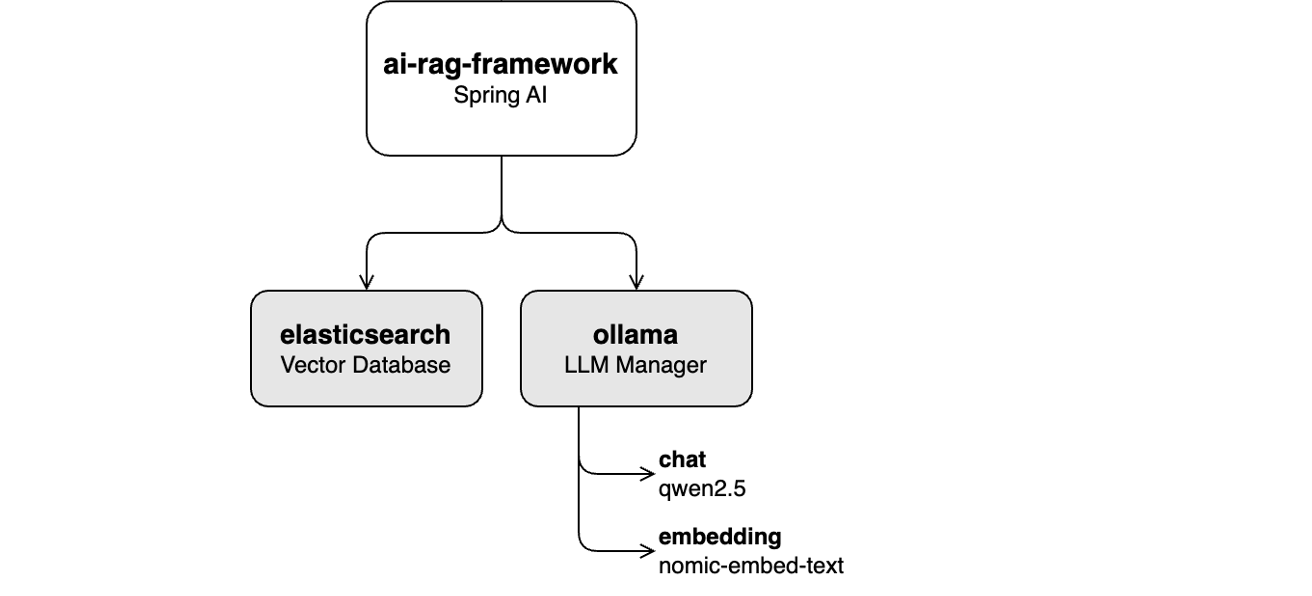
Esta práctica de laboratorio se centra en habilitar la funcionalidad de chat con LLM qwen2.5 a través de Ollama, utilizando aplicaciones de interfaz de usuario de Alfresco como Share y ADF. El proceso incluye transformar el mensaje del usuario en vectores utilizando el módulo de incrustación nomic-embed-text a través de Ollama, y luego buscar contenido relevante en la base de datos de vectores (Elasticsearch). El texto recuperado se utiliza para proporcionar contexto al LLM , lo que ayuda a generar respuestas más precisas.
Comience esta práctica de laboratorio siguiendo la Práctica 2: Funcionalidad del chat.
En esta práctica de laboratorio, integrará todos los componentes (funcionalidad de ingesta y chat) con un repositorio de Alfresco en vivo. El sistema actualizará automáticamente la base de datos de vectores cada vez que haya cambios en el repositorio, eliminando la necesidad de intervención manual.
Puede comenzar esta práctica de laboratorio siguiendo la Práctica 3: Ejecución de todos los componentes juntos.
Este proyecto tiene la licencia Apache 2.0. Consulte el archivo de LICENCIA para obtener más detalles.
Un agradecimiento especial a los equipos de Alfresco y Hyland por su continuo apoyo y contribuciones a iniciativas de código abierto en los dominios de gestión de contenidos e inteligencia artificial.


