3DDFA
1.0.0
Por Jianzhu Guo.

[Actualizaciones]
2022.5.14 : Se recomienda una implementación en Python de creación de perfiles faciales: face_pose_augmentation.2020.8.30 : El modelo y el código previamente entrenados de ECCV-20 se hacen públicos en 3DDFA_V2, los derechos de autor los explican Jianzhu Guo y el grupo CBSR.2020.8.2 : actualice una versión simple de C++ de este proyecto.2020.7.3 : ECCV 2020 acepta el trabajo ampliado Hacia una alineación facial densa 3D rápida, precisa y estable. Consulte mi página para obtener más detalles.2019.9.15 : Algunas actualizaciones; consulte las confirmaciones para obtener más detalles.2019.6.17 : Añadiendo una demostración en vídeo aportada por zjjMaiMai.2019.5.2 : Evaluación de la velocidad de inferencia en la CPU con PyTorch v1.1.0, consulte aquí y speed_cpu.py.2019.4.27 : Una canalización de renderizado simple que se ejecuta a ~25 ms/fotograma (720p); consulte renderizado.py para obtener más detalles.2019.4.24 : Para obtener la versión de demostración de Obama, consulte demo@obama/readme.md para obtener más detalles.2019.3.28 : Algunas actualizaciones.2018.12.23 : Agregue varias funciones: estimación de imágenes de profundidad, PNCC, función PAF y serialización de objetos. Consulte las opciones dump_depth , dump_pncc , dump_paf , dump_obj para obtener más detalles.2018.12.2 : Admite recorte de rostros sin puntos de referencia, consulte la opción dlib_landmark .2018.12.1 : refina el código y agrega la función de estimación de pose; consulta utils/estimate_pose.py para obtener más detalles.2018.11.17 : refina el código y asigna el vértice 3D al espacio de la imagen original.2018.11.11 : Actualización del proceso de inferencia de extremo a extremo: inferir/serializar la forma de la cara 3D y 68 puntos de referencia dada una imagen arbitraria; consulte readme.md a continuación para obtener más detalles.2018.10.4 : Agregue una demostración de representación de malla facial de Matlab en visualización.2018.9.9 : Agregue el proceso previo de recorte de rostros en el punto de referencia.[Hacer]
Este repositorio contiene la versión mejorada de pytorch del artículo: Alineación facial en rango completo de pose: una solución total en 3D. Se agregan varios trabajos más allá del artículo original, incluida la capacitación en tiempo real y las estrategias de capacitación. Por tanto, este repositorio es una versión mejorada del trabajo original. Hasta el momento, este repositorio publica los modelos pytorch de primera etapa previamente entrenados de la estructura MobileNet-V1, el conjunto de datos de entrenamiento y prueba preprocesados y la base de código. Tenga en cuenta que el tiempo de inferencia es de aproximadamente 0,27 ms por imagen (lote de entrada con 128 imágenes como lote de entrada) en GeForce GTX TITAN X.
Este repositorio seguirá actualizándose en mi tiempo libre y cualquier problema significativo y relaciones públicas son bienvenidos.
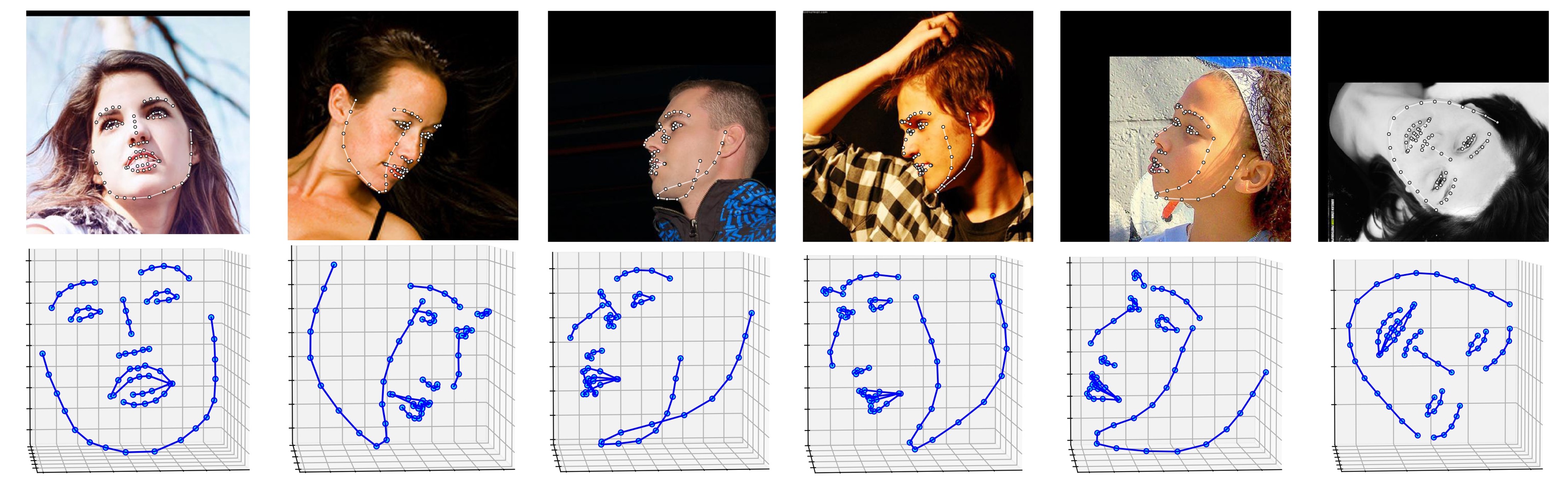
A continuación se muestran varios resultados del conjunto de datos ALFW-2000 (inferidos del modelo fase1_wpdc_vdc.pth.tar ).





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
Además, recomiendo encarecidamente utilizar Python3.6+ en lugar de la versión anterior para lograr un mejor diseño.
Clona este repositorio (esto puede llevar algún tiempo ya que es un poco grande)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
Luego, descargue el modelo previamente entrenado de dlib Landmark en Google Drive o Baidu Yun y colóquelo en el directorio models . (Para reducir el tamaño de este repositorio, eliminé algunos archivos binarios de gran tamaño, incluido este modelo, por lo que debes descargarlo :))
Construir módulo cython (solo una línea para construir)
cd utils/cython
python3 setup.py build_ext -i
Esto es para acelerar la estimación de profundidad y el renderizado PNCC, ya que Python es demasiado lento en el bucle for.
Ejecute main.py con una imagen arbitraria como entrada
python3 main.py -f samples/test1.jpg
Si puede ver estos registros de salida en la terminal, lo ejecutará correctamente.
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
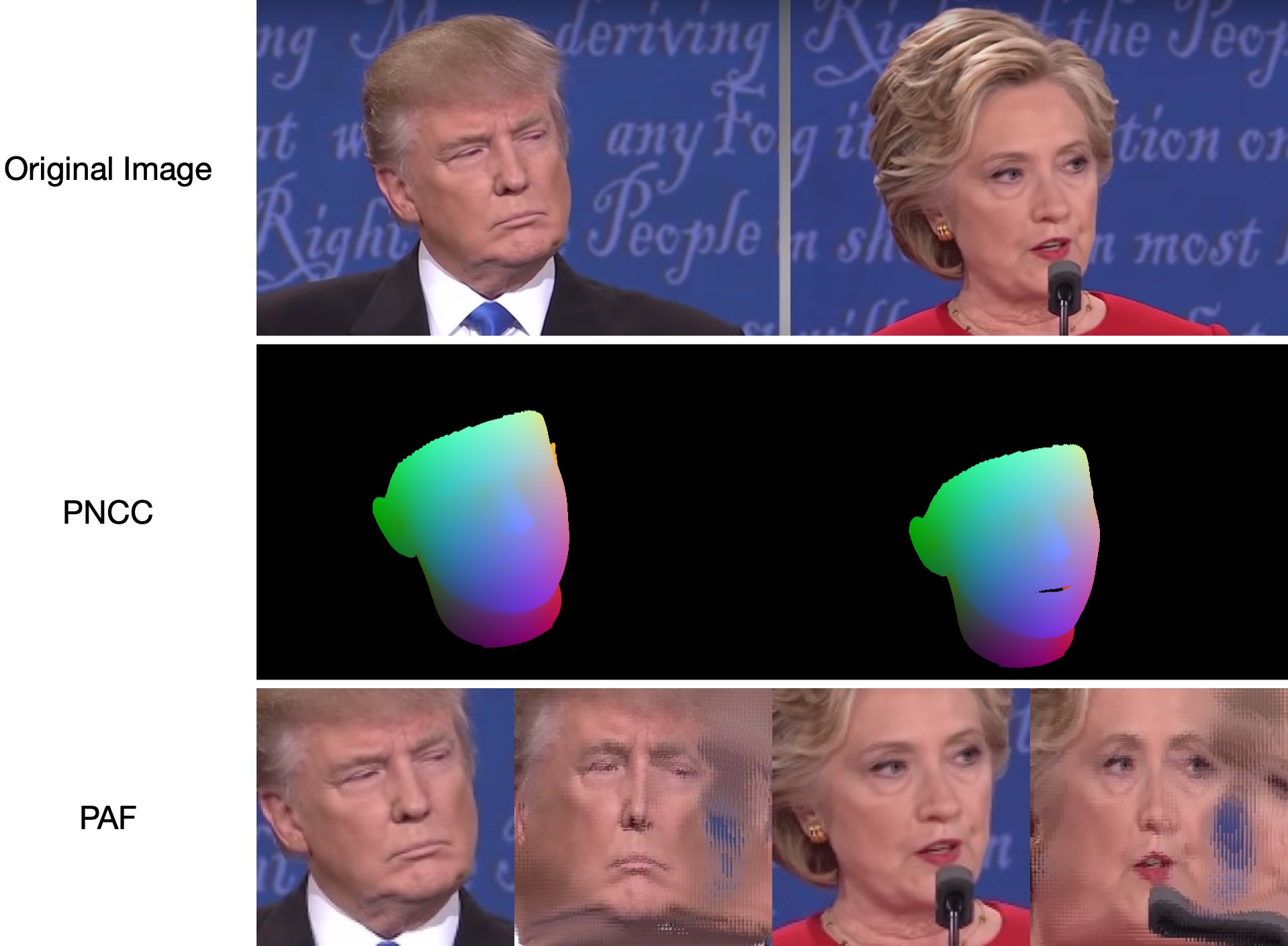
Debido a que test1.jpg tiene dos caras, se predicen dos archivos .ply y .obj (que pueden ser renderizados por Meshlab o Microsoft 3D Builder). La estimación de profundidad, PNCC, PAF y pose están configuradas como verdaderas de forma predeterminada. Ejecute python3 main.py -h o revise el código para obtener más detalles.
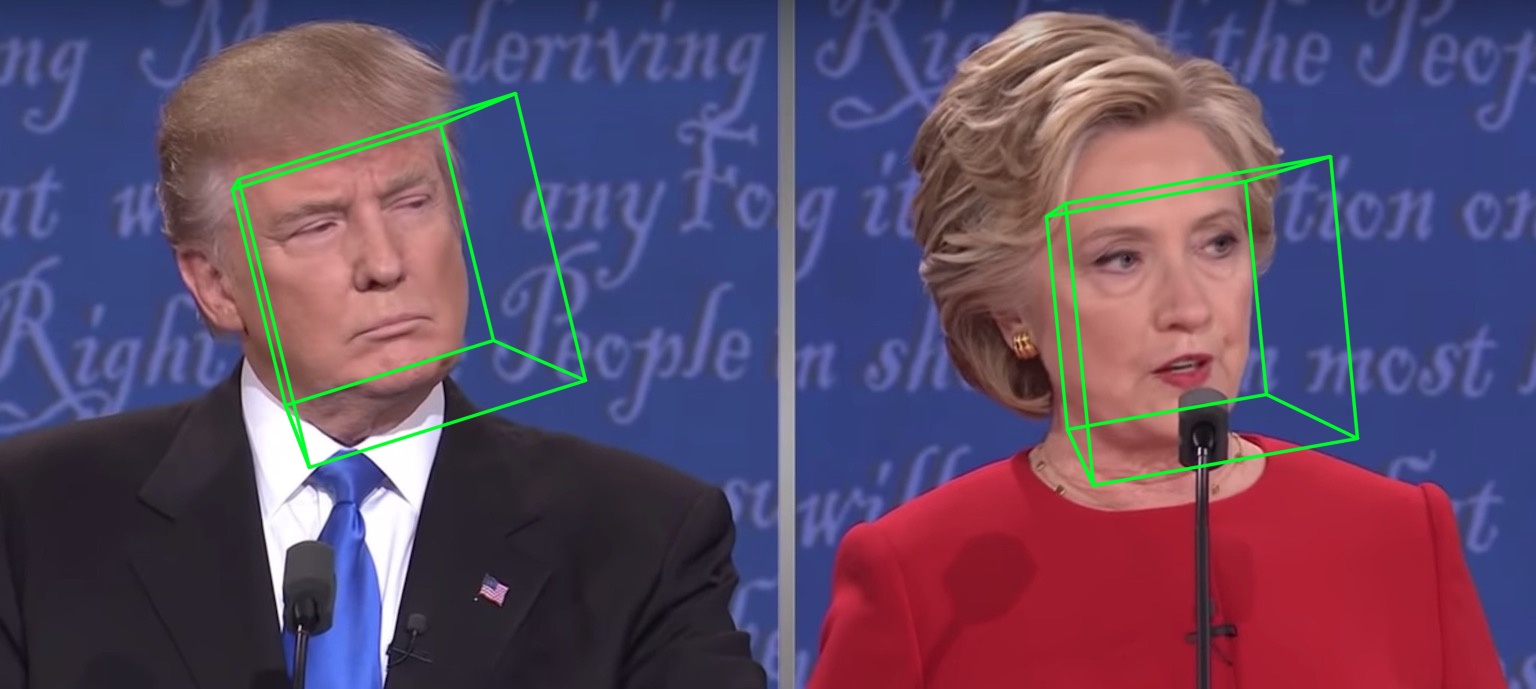
Las samples/test1_3DDFA.jpg y samples/test1_pose.jpg se muestran a continuación:

Ejemplo adicional
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
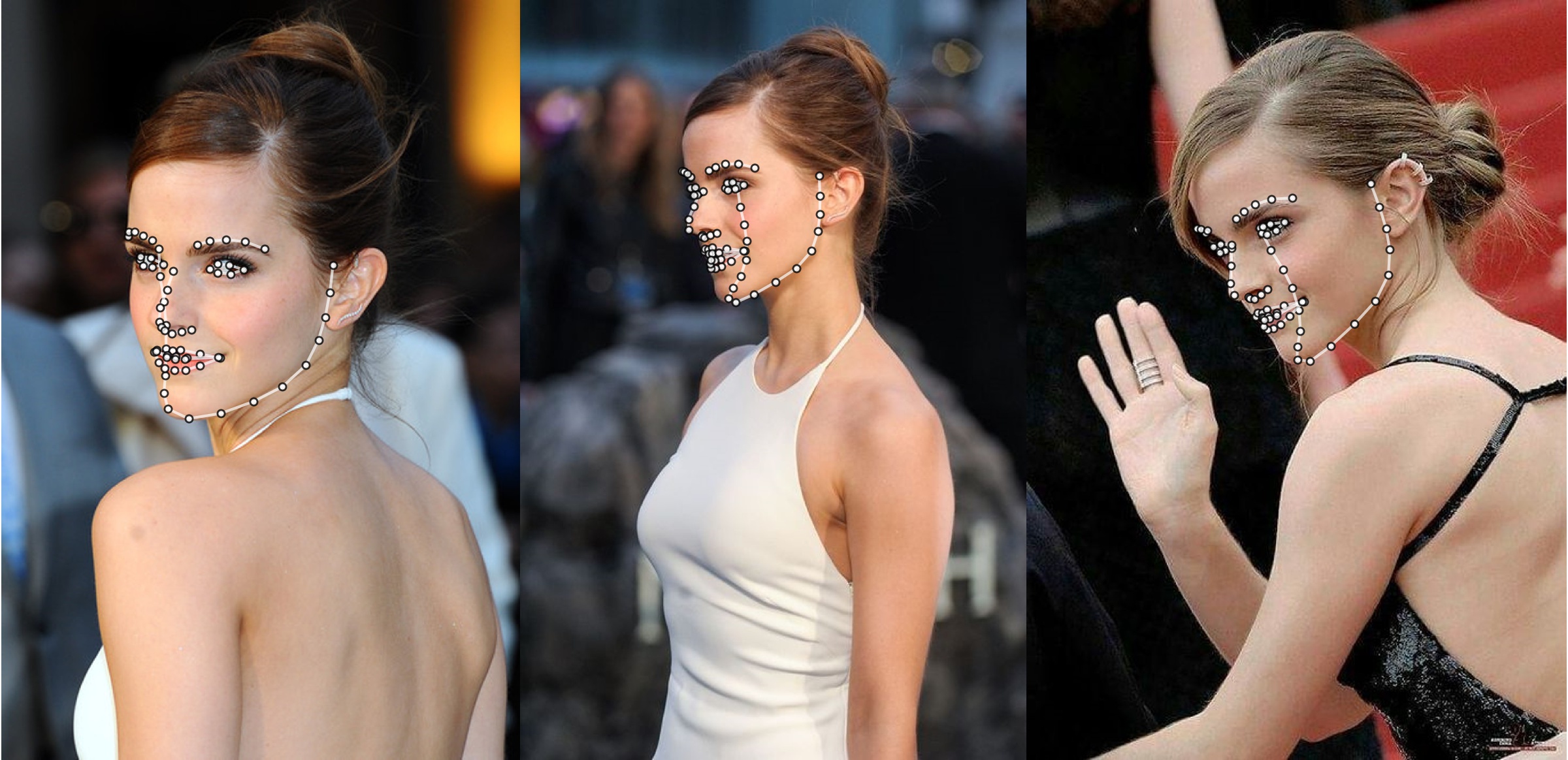
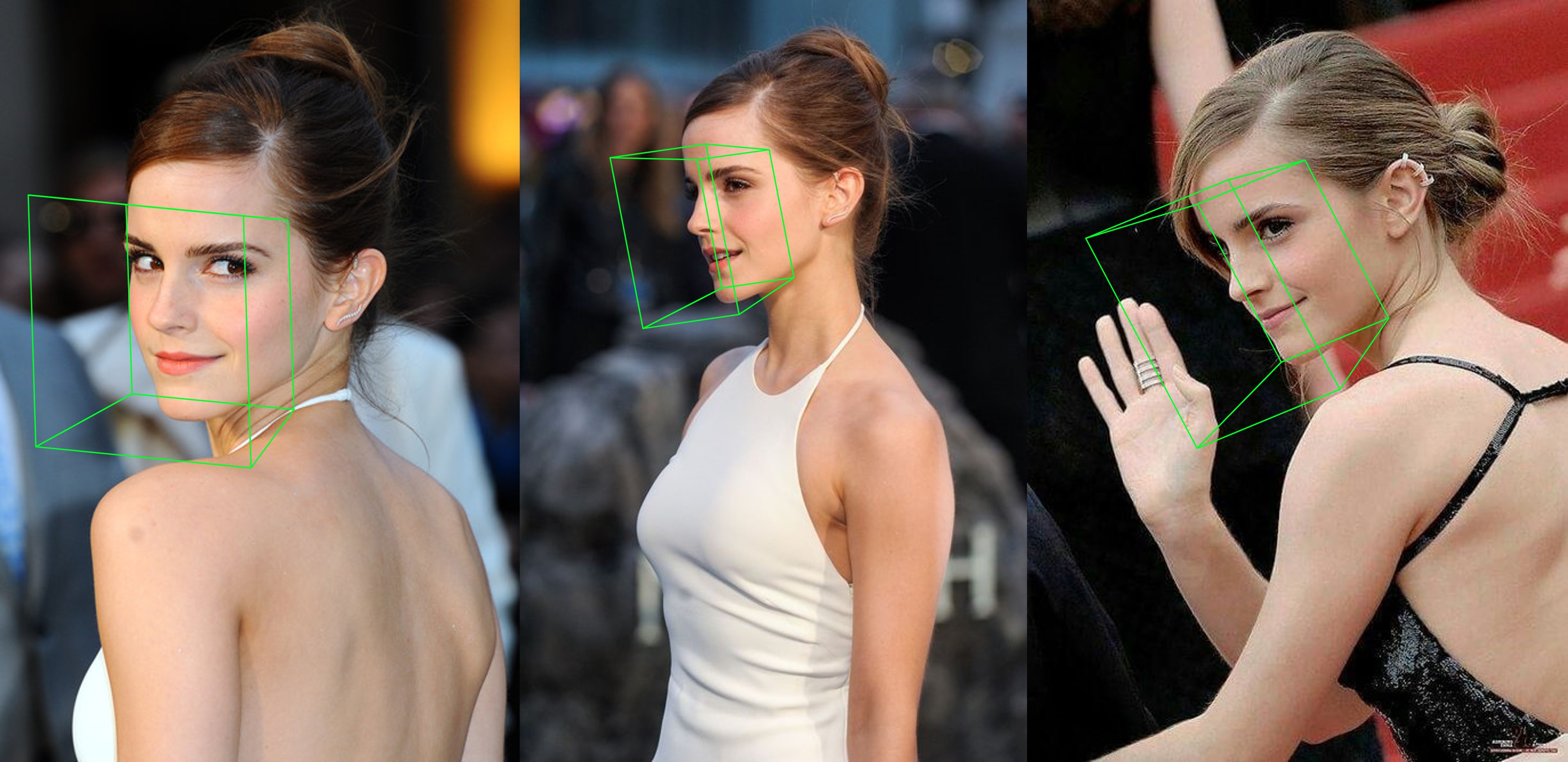
solo corre
python3 speed_cpu.py
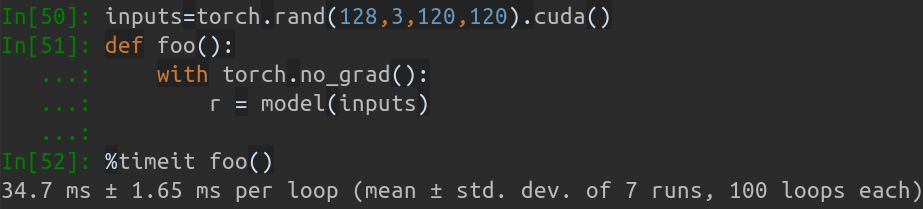
En mi MBP (CPU i5-8259U a 2,30 GHz en MacBook Pro de 13 pulgadas), basado en PyTorch v1.1.0 , con una sola entrada, la salida en ejecución es:
Inference speed: 14.50±0.11 ms
Cuando el tamaño del lote de entrada es 128, el tiempo total de inferencia de MobileNet-V1 es de aproximadamente 34,7 ms. La velocidad promedio es de aproximadamente 0,27 ms/imagen .
Los guiones de formación se encuentran en el directorio training . Los recursos relacionados se encuentran en la siguiente tabla.
| Datos | Enlace de descarga | Descripción |
|---|---|---|
| tren.configs | BaiduYun o Google Drive, 217M | El directorio que contiene los parámetros 3DMM y las listas de archivos del conjunto de datos de entrenamiento. |
| tren_ago_120x120.zip | BaiduYun o Google Drive, 2,15G | Las imágenes recortadas del conjunto de datos de entrenamiento de aumento. |
| prueba.datos.zip | BaiduYun o Google Drive, 151M | Las imágenes recortadas del conjunto de pruebas AFLW y ALFW-2000-3D |
Después de preparar el conjunto de datos de entrenamiento y los archivos de configuración, vaya al directorio training y ejecute los scripts de bash para entrenar. train_wpdc.sh , train_vdc.sh y train_pdc.sh son ejemplos de guiones de entrenamiento. Después de configurar los conjuntos de entrenamiento y prueba, simplemente ejecútelos para el entrenamiento. Tome train_wpdc.sh , por ejemplo, como se muestra a continuación:
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
Todos los parámetros de entrenamiento específicos se presentan en scripts bash, incluida la tasa de aprendizaje, el tamaño del mini lote, las épocas, etc.
Primero, debe descargar el conjunto de pruebas recortado ALFW y ALFW-2000-3D en test.data.zip, luego descomprimirlo y colocarlo en el directorio raíz. A continuación, ejecute el código de referencia proporcionando la ruta del modelo entrenado. Ya he proporcionado cinco modelos previamente entrenados en el directorio models (que se ven en la tabla a continuación). Estos modelos se entrenan utilizando diferentes pérdidas en la primera etapa. El tamaño del modelo es de aproximadamente 13M debido a la alta eficiencia de la estructura MobileNet-V1.
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
El rendimiento de los modelos previamente entrenados se muestra a continuación. En la primera etapa, la efectividad de diferentes pérdidas está en orden: WPDC > VDC > PDC. Mientras que la estrategia que utiliza VDC para ajustar WPDC logra el mejor resultado.
| Modelo | AFLW (21 puntos) | AFLW 2000-3D (68 puntos) | Enlace de descarga |
|---|---|---|---|
| fase1_pdc.pth.tar | 6,956±0,981 | 5,644±1,323 | Baidu Yun o Google Drive |
| fase1_vdc.pth.tar | 6,717±0,924 | 5.030±1.044 | Baidu Yun o Google Drive |
| fase1_wpdc.pth.tar | 6,348±0,929 | 4,759±0,996 | Baidu Yun o Google Drive |
| fase1_wpdc_vdc.pth.tar | 5,401±0,754 | 4,252±0,976 | En este repositorio. |
Créame, el marco de este repositorio puede lograr un mejor rendimiento que PRNet sin aumentar ningún presupuesto de cálculo. El trabajo relacionado está bajo revisión y el código se publicará una vez aceptado.
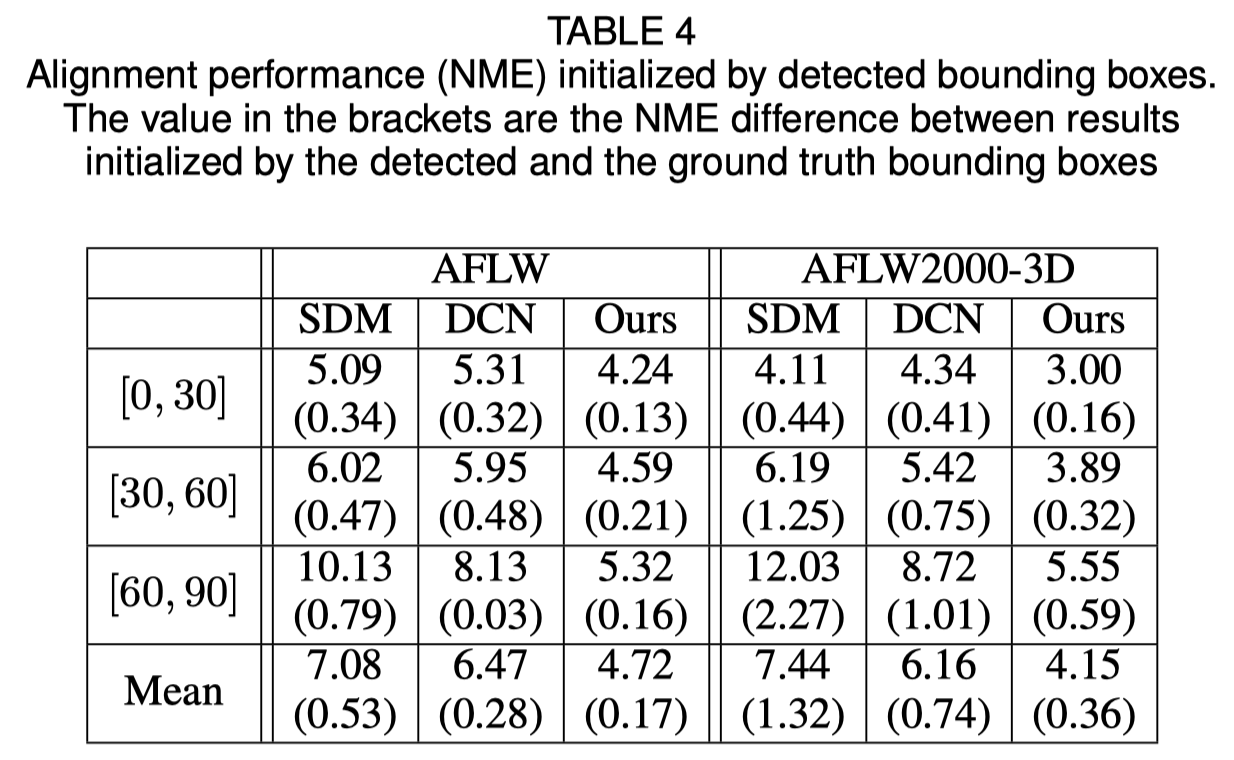
Inicialización del cuadro delimitador de caras
El documento original muestra que el uso de un cuadro delimitador detectado en lugar de un cuadro de verdad fundamental provocará una pequeña caída en el rendimiento. Por tanto, el método actual de recorte de rostros es el más sólido. Los resultados cuantitativos se muestran en la siguiente tabla.
Reconstrucción facial
La textura del área no visible está distorsionada debido a la autooclusión, por lo que la región de la cara no visible puede parecer extraña (un poco horrible).
Acerca del recorte de parámetros de forma y expresión
El recorte de parámetros acelera el entrenamiento y la reconstrucción, pero degrada la precisión, especialmente en detalles como cerrar los ojos. A continuación se muestra una imagen, con parámetros de dimensión 40+10, 60+29 y 199+29 (el original). En comparación con la forma, el recorte de expresiones tiene más efecto en la precisión de la reconstrucción cuando se trata de emociones. Por lo tanto, puede elegir un equilibrio entre velocidad/tamaño de parámetro y precisión. Una recomendación de compensación de recorte es 60+29.

Gracias por su interés en este repositorio. Si su trabajo o investigación se beneficia de este repositorio, ¿destacarlo?
Bienvenido a centrarme en mis trabajos relacionados con la cara en 3D: MeGlass y Face Anti-Spoofing.
Si su trabajo se beneficia de este repositorio, cite tres baberos a continuación.
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Jianzhu Guo (郭建珠) [Página de inicio, Google Scholar]: [email protected] o [email protected] .


