learning kcp protocol
1.0.0
En determinadas aplicaciones, el simple uso de TCP no puede satisfacer las necesidades. El uso directo de datagramas UDP no puede garantizar la confiabilidad de los datos y, a menudo, es necesario implementar un protocolo de transmisión confiable basado en UDP en la capa de aplicación.
El uso directo del protocolo KCP es una opción, que implementa un protocolo de retransmisión automática robusto y además proporciona ajuste de parámetros gratuito. Adáptese a las necesidades de diferentes escenarios mediante parámetros de configuración y métodos de llamada adecuados.
Introducción a KCP:
KCP es un protocolo rápido y confiable que puede reducir el retraso promedio entre un 30% y un 40% y reducir el retraso máximo tres veces a un costo de entre un 10% y un 20% más de ancho de banda que TCP. La implementación pura del algoritmo no es responsable del envío y recepción de protocolos subyacentes (como UDP). Los usuarios deben definir el método de envío de paquetes de datos de capa inferior y proporcionárselo a KCP en forma de devolución de llamada. Incluso el reloj debe pasarse externamente y no habrá ninguna llamada al sistema internamente. Todo el protocolo solo tiene dos archivos fuente, ikcp.h e ikcp.c, que se pueden integrar fácilmente en la pila de protocolos del propio usuario. Tal vez haya implementado un protocolo basado en P2P o UDP pero le falta una implementación completa y confiable del protocolo ARQ. Luego simplemente copie estos dos archivos al proyecto existente, escriba algunas líneas de código y podrá usarlo.
Este artículo presenta brevemente el proceso básico de envío y recepción, la ventana de congestión y el algoritmo de tiempo de espera del protocolo KCP, y también proporciona un código de muestra de referencia.
La versión de KCP a la que se hace referencia es la última versión en el momento de escribir este artículo. Este artículo no pegará completamente todo el código fuente de KCP, pero agregará enlaces a las ubicaciones correspondientes del código fuente en puntos clave.
La estructura IKCPSEG se utiliza para almacenar el estado de los segmentos de datos enviados y recibidos.
Descripción de todos los campos IKCPSEG:
struct IKCPSEG
{
/* 队列节点,IKCPSEG 作为一个队列元素,此结构指向了队列后前后元素 */
struct IQUEUEHEAD node;
/* 会话编号 */
IUINT32 conv;
/* 指令类型 */
IUINT32 cmd;
/* 分片号 (fragment)
发送数据大于 MSS 时将被分片,0为最后一个分片.
意味着数据可以被recv,如果是流模式,所有分片号都为0
*/
IUINT32 frg;
/* 窗口大小 */
IUINT32 wnd;
/* 时间戳 */
IUINT32 ts;
/* 序号 (sequence number) */
IUINT32 sn;
/* 未确认的序号 (unacknowledged) */
IUINT32 una;
/* 数据长度 */
IUINT32 len;
/* 重传时间 (resend timestamp) */
IUINT32 resendts;
/* 重传的超时时间 (retransmission timeout) */
IUINT32 rto;
/* 快速确认计数 (fast acknowledge) */
IUINT32 fastack;
/* 发送次数 (transmit) */
IUINT32 xmit;
/* 数据内容 */
char data[1];
};
El campo data al final de la estructura se utiliza para indexar los datos al final de la estructura. La memoria asignada adicional extiende la longitud real de la matriz del campo de datos en tiempo de ejecución (ikcp.c:173).
La estructura IKCPSEG es solo estado de memoria y solo algunos campos están codificados en el protocolo de transporte.
La función ikcp_encode_seg codifica el encabezado del protocolo de transporte:
/* 协议头一共 24 字节 */
static char *ikcp_encode_seg(char *ptr, const IKCPSEG *seg)
{
/* 会话编号 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->conv);
/* 指令类型 (1 Bytes) */
ptr = ikcp_encode8u(ptr, (IUINT8)seg->cmd);
/* 分片号 (1 Bytes) */
ptr = ikcp_encode8u(ptr, (IUINT8)seg->frg);
/* 窗口大小 (2 Bytes) */
ptr = ikcp_encode16u(ptr, (IUINT16)seg->wnd);
/* 时间戳 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->ts);
/* 序号 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->sn);
/* 未确认的序号 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->una);
/* 数据长度 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->len);
return ptr;
}
La estructura IKCPCB almacena todo el contexto del protocolo KCP y la comunicación del protocolo se realiza creando dos objetos IKCPCB en el extremo opuesto.
struct IKCPCB
{
/* conv: 会话编号
mtu: 最大传输单元
mss: 最大报文长度
state: 此会话是否有效 (0: 有效 ~0:无效)
*/
IUINT32 conv, mtu, mss, state;
/* snd_una: 发送的未确认数据段序号
snd_nxt: 发送的下一个数据段序号
rcv_nxt: 期望接收到的下一个数据段的序号
*/
IUINT32 snd_una, snd_nxt, rcv_nxt;
/* ts_recent: (弃用字段?)
ts_lastack: (弃用字段?)
ssthresh: 慢启动阈值 (slow start threshold)
*/
IUINT32 ts_recent, ts_lastack, ssthresh;
/* rx_rttval: 平滑网络抖动时间
rx_srtt: 平滑往返时间
rx_rto: 重传超时时间
rx_minrto: 最小重传超时时间
*/
IINT32 rx_rttval, rx_srtt, rx_rto, rx_minrto;
/* snd_wnd: 发送窗口大小
rcv_wnd: 接收窗口大小
rmt_wnd: 远端窗口大小
cwnd: 拥塞窗口 (congestion window)
probe: 窗口探测标记位,在 flush 时发送特殊的探测包 (window probe)
*/
IUINT32 snd_wnd, rcv_wnd, rmt_wnd, cwnd, probe;
/* current: 当前时间 (ms)
interval: 内部时钟更新周期
ts_flush: 期望的下一次 update/flush 时间
xmit: 全局重传次数计数
*/
IUINT32 current, interval, ts_flush, xmit;
/* nrcv_buf: rcv_buf 接收缓冲区长度
nsnd_buf: snd_buf 发送缓冲区长度
nrcv_que: rcv_queue 接收队列长度
nsnd_que: snd_queue 发送队列长度
*/
IUINT32 nrcv_buf, nsnd_buf;
IUINT32 nrcv_que, nsnd_que;
/* nodelay: nodelay模式 (0:关闭 1:开启)
updated: 是否调用过 update 函数
*/
IUINT32 nodelay, updated;
/* ts_probe: 窗口探测标记位
probe_wait: 零窗口探测等待时间,默认 7000 (7秒)
*/
IUINT32 ts_probe, probe_wait;
/* dead_link: 死链接条件,默认为 20。
(单个数据段重传次数到达此值时 kcp->state 会被设置为 UINT_MAX)
incr: 拥塞窗口算法的一部分
*/
IUINT32 dead_link, incr;
/* 发送队列 */
struct IQUEUEHEAD snd_queue;
/* 接收队列 */
struct IQUEUEHEAD rcv_queue;
/* 发送缓冲区 */
struct IQUEUEHEAD snd_buf;
/* 接收缓冲区 */
struct IQUEUEHEAD rcv_buf;
/* 确认列表, 包含了序号和时间戳对(pair)的数组元素*/
IUINT32 *acklist;
/* 确认列表元素数量 */
IUINT32 ackcount;
/* 确认列表实际分配长度 */
IUINT32 ackblock;
/* 用户数据指针,传入到回调函数中 */
void *user;
/* 临时缓冲区 */
char *buffer;
/* 是否启用快速重传,0:不开启,1:开启 */
int fastresend;
/* 快速重传最大次数限制,默认为 5*/
int fastlimit;
/* nocwnd: 控流模式,0关闭,1不关闭
stream: 流模式, 0包模式 1流模式
*/
int nocwnd, stream;
/* 日志标记 */
int logmask;
/* 发送回调 */
int (*output)(const char *buf, int len, struct IKCPCB *kcp, void *user);
/* 日志回调 */
void (*writelog)(const char *log, struct IKCPCB *kcp, void *user);
};
typedef struct IKCPCB ikcpcb;
Solo hay 2 estructuras de cola en KCP:
IQUEUEHEAD es una lista simple doblemente enlazada que apunta al elemento inicial (anterior) y al último (siguiente) de la cola:
struct IQUEUEHEAD {
/*
next:
作为队列时: 队列的首元素 (head)
作为元素时: 当前元素所在队列的下一个节点
prev:
作为队列时: 队列的末元素 (last)
作为元素时: 当前元素所在队列的前一个节点
*/
struct IQUEUEHEAD *next, *prev;
};
typedef struct IQUEUEHEAD iqueue_head;
Cuando la cola está vacía, siguiente/anterior apuntará a la cola misma, no a NULL.
El encabezado de la estructura IKCPSEG como elemento de cola también reutiliza la estructura IQUEUEHEAD:
struct IKCPSEG
{
struct IQUEUEHEAD node;
/* ... */
}
Cuando se utiliza como elemento de cola, se registran el elemento anterior (anterior) y el elemento siguiente (siguiente) en la cola donde se encuentra el elemento actual.
Cuando prev apunta a la cola, significa que el elemento actual está al principio de la cola, y cuando next apunta a la cola, significa que el elemento actual está al final de la cola.
Todas las operaciones de la cola se proporcionan como macros.
Los métodos de configuración proporcionados por KCP son:
Opciones del modo de trabajo :
int ikcp_nodelay(ikcpcb *kcp, int nodelay, int interval, int resend, int nc)
Opciones máximas de ventana :
int ikcp_wndsize(ikcpcb *kcp, int sndwnd, int rcvwnd);
El tamaño de la ventana de envío sndwnd debe ser mayor que 0 y el tamaño de la ventana de recepción rcvwnd debe ser mayor que 128. La unidad son paquetes, no bytes.
Unidad de transmisión máxima :
KCP no es responsable de detectar MTU. El valor predeterminado es 1400 bytes. Puede utilizar ikcp_setmtu para establecer este valor. Este valor afectará a la unidad máxima de transmisión al combinar y fragmentar paquetes de datos. Una MTU más pequeña afectará la prioridad de enrutamiento.
Este artículo proporciona un código kcp_basic.c que básicamente puede ejecutar KCP. El código de muestra de menos de 100 líneas es una llamada puramente algorítmica a KCP y no incluye ninguna programación de red. ( Importante : sigue el artículo para depurarlo y pruébalo).
Puede usarlo para obtener una comprensión preliminar de los campos de la estructura básica en la estructura IKCPCB:
kcp.snd_queue : cola de envío (longitud del registro kcp.nsnd_que )kcp.snd_buf : búfer de envío (longitud del registro kcp.nsnd_buf )kcp.rcv_queue : cola de recepción (longitud del registro kcp.nrcv_que )kcp.rcv_buf : búfer de recepción (longitud del registro kcp.nrcv_buf )kcp.mtu : unidad de transmisión máximakcp.mss : longitud máxima del mensajeY en la estructura IKCPSEG:
seg.sn : número de serieseg.frg : número de segmentoCree la estructura de contexto KCP IKCPCB mediante la función ikcp_create.
IKCPCB crea internamente la estructura IKCPSEG correspondiente para almacenar datos y estado llamando externamente a ikcp_send (entrada del usuario al remitente) y datos de entrada ikcp_input (entrada del remitente al receptor).
Además, la estructura IKCPSEG se eliminará a través de ikcp_recv (eliminado por el usuario del extremo receptor) y datos de confirmación ikcp_input (recibidos por el extremo emisor del extremo receptor).
Para obtener información detallada sobre la dirección del flujo de datos, consulte la sección Cola y ventana .
La creación y destrucción de IKCPSEG ocurre principalmente en las cuatro situaciones anteriores, y otras son comunes en movimientos entre colas internas y otras optimizaciones.
En los siguientes artículos, todos los campos de estructura IKCPCB e IKCPSEG que aparecen se resaltarán mediante
标记(solo exploración de rebajas, es posible que otros no lo vean). Todos los campos de la estructura IKCPCB tendrán el prefijokcp.y todos los campos de la estructura IKCPSEG tendrán el prefijoseg.. Por lo general, el nombre de la variable correspondiente o el nombre del parámetro de función en el código fuente también eskcposeg.
Este código simplemente escribe la longitud de datos especificada en el objeto KCP llamado k1 y lee los datos del objeto k2. KCP está configurado en modo predeterminado.
El proceso básico se puede describir simplemente mediante pseudocódigo como:
/* 创建两个 KCP 对象 */
k1 = ikcp_create()
k2 = ikcp_create()
/* 向发送端 k1 写入数据 */
ikcp_send(k1, send_data)
/* 刷出数据,执行 kcp->output 回调 */
ikcp_flush(k1)
/* output 回调接收到带协议包头的分片数据,执行发送 */
k1->output(fragment_data)
/* 接收端 k2 收到输入数据 */
ikcp_input(k2, input_data)
/* 接收端刷出数据,会发送确认包到 k1 */
ikcp_flush(k2)
/* 发送端 k1 收到确认数据 */
recv_data = ikcp_recv(k1, ack_data)
/* 尝试读出数据 */
recv = ikcp_recv(k2)
/* 验证接收数据和发送数据一致 */
assert(recv_data == send_data)
En el código de muestra, el objeto KCP creado está vinculado a la función kcp_user_output además de kcp.output que se utiliza para definir el comportamiento de los datos de salida del objeto KCP. kcp.writelog también está vinculado a la función kcp_user_writelog para depurar la impresión.
Además, dado que kcp.output no puede llamar a otros ikcp_input de forma recursiva (porque eventualmente recurrirá a su propio kcp.output ), todos los datos de salida deben almacenarse en una ubicación intermedia y luego ingresarse en k2 después de salir de kcp.output función. Este es el propósito de la estructura OUTPUT_CONTEXT definida en el código de muestra.
Intente ejecutar el código de muestra y obtendrá el siguiente resultado (el contenido adjunto al signo # es una explicación):
# k1.output 被调用,输出 1400 字节
k1 [RO] 1400 bytes
# k2 被调用 ikcp_input 输入数据
k2 [RI] 1400 bytes
# psh 数据推送分支处理
k2 input psh: sn=0 ts=0
# k2.output 被调用,输出确认包,数据长度24字节
k2 [RO] 24 bytes
# k1 被调用 ikcp_input 输入数据
k1 [RI] 24 bytes
# 序号 sn=0 被确认
k1 input ack: sn=0 rtt=0 rto=100
k1 [RO] 1400 bytes
k1 [RO] 1368 bytes
k2 [RI] 1400 bytes
k2 input psh: sn=1 ts=0
k2 [RI] 1368 bytes
k2 input psh: sn=2 ts=0
k2 [RO] 48 bytes
k1 [RI] 48 bytes
k1 input ack: sn=1 rtt=0 rto=100
k1 input ack: sn=2 rtt=0 rto=100
# k2 被调用 kcp_recv 取出数据
k2 recv sn=0
k2 recv sn=1
k2 recv sn=2
El contenido de salida es la información de depuración impresa integrada en el código KCP. El prefijo de línea k1/k2 se agrega adicionalmente a través de kcp_user_writelog como distinción.
El diagrama esquemático completo del proceso de confirmación de envío de este código se describe como (el doble de tamaño):
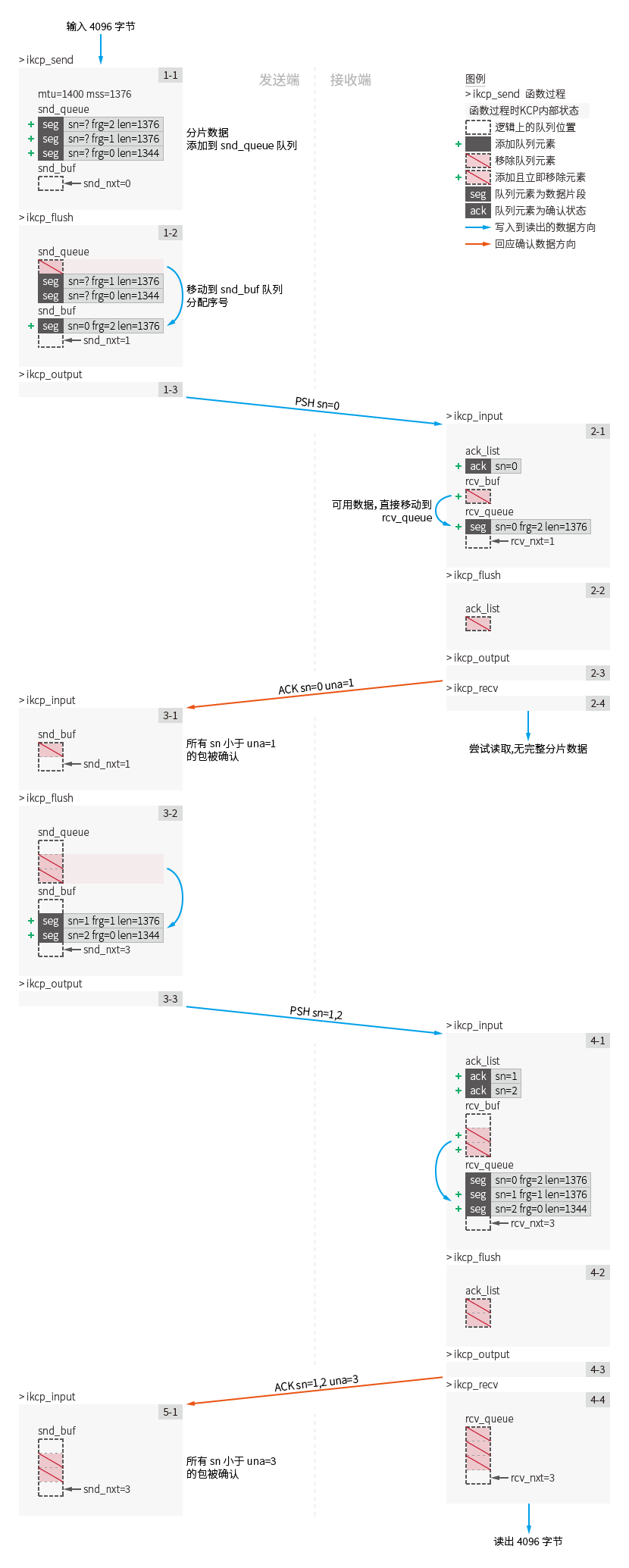
Llame a ikcp_send en k1: (Figura paso 1-1)
Los datos con una longitud de 4096 se escriben en el remitente. Según kcp.mss se corta en tres paquetes con una longitud de 1376/1376/1344, y seg.frg de cada paquete son 2/1/0 respectivamente.
La unidad de transmisión máxima kcp.mtu define la longitud máxima de datos que recibe ikcp.output cada vez. El valor predeterminado es 1400.
En el diagrama esquemático, el método ikcp_output eventualmente llamará al puntero de función
ikcp.output. (ikcp.c:212)
La longitud máxima del mensaje de kcp.mss se calcula restando la sobrecarga del protocolo (24 bytes) de kcp.mtu . El valor predeterminado es 1376.
No se ejecutará ninguna devolución de llamada kcp.output en este momento y todos los datos del fragmento se asignarán y registrarán en la estructura IKCPSEG y se agregarán a la cola kcp.snd_queue (ikcp.c:528).
En este momento, la longitud de la cola kcp.snd_queue de k1 es 3 y la longitud de la cola kcp.snd_buf es 0.
Llame a ikcp_flush en k1: (Figura paso 1-2)
Aquí se ignora el proceso de cálculo específico de la ventana. Solo necesita saber que el valor de la ventana de congestión
kcp.cwndes 1 cuando k1 llama a ikcp_flush por primera vez.
Debido al límite de la ventana de congestión, sólo se puede enviar un paquete por primera vez. El objeto IKCPSEG con la primera longitud de datos de la cola kcp.snd_queue se mueve a la cola kcp.snd_buf (ikcp.c:1028), y el valor del número de secuencia seg.sn asignado de acuerdo con kcp.snd_nxt es 0 (ikcp .c:1036), el campo seg.cmd es IKCP_CMD_PUSH, Representa un paquete de envío de datos.
En este momento, la longitud de la cola kcp.snd_queue de k1 es 2 y kcp.snd_buf es 1.
En el paso 1-3, ejecute la llamada ikcp_output (ikcp.c:1113) en los primeros datos enviados para enviar el paquete de datos [PSH sn=0 frg=2 len=1376] .
Solo hay cuatro tipos de comandos de datos: IKCP_CMD_PUSH (envío de datos) IKCP_CMD_ACK (confirmación) IKCP_CMD_WASK (detección de ventana) IKCP_CMD_WINS (respuesta de ventana), definido en ikcp.c:29
Llame a ikcp_input en k2: (Figura paso 2-1)
Ingrese el paquete de datos [PSH sn=0 frg=2 len=1376] , analice el encabezado del paquete y verifique la validez. (ikcp.c:769)
Analice el tipo de paquete de datos e ingrese al procesamiento de la rama de envío de datos. (ikcp.c:822)
Registre el valor seq.sn y el valor seq.ts del paquete de datos en la lista de confirmación kcp.acklist (ikcp.c:828). Tenga en cuenta : el valor de seq.ts en este ejemplo es siempre 0.
Agregue los paquetes recibidos a la cola kcp.rcv_buf . (ikcp:709)
Compruebe si el primer paquete de datos en kcp.rcv_buf está disponible. Si es un paquete de datos disponible, se mueve a kcp.rcv_queue . (ikcp.c:726)
Los paquetes de datos disponibles en kcp.rcv_buf se definen como: el siguiente número de secuencia de datos que se espera recibir (tomado de kcp.rcv_nxt , donde el siguiente número de secuencia de datos debe ser seg.sn == 0) y la longitud del kcp.rcv_queue La cola kcp.rcv_queue es menor que el tamaño de la ventana recibida.
En este paso, el único paquete de datos en la cola kcp.rcv_buf se mueve directamente a la cola kcp.rcv_queue .
En este momento, kcp.>rcv_queue de k2 es 1 y la longitud de la cola kcp.snd_buf es 0. El valor del siguiente número de secuencia de datos recibido kcp.rcv_nxt se actualiza de 0 a 1.
Llame a ikcp_flush en k2: (Fig. Paso 2-2)
En la primera llamada a ikcp_flush de k2. Debido a que hay datos en la lista de confirmación kcp.acklist , el paquete de confirmación se codificará y enviará (ikcp.c:958).
Al valor seg.una en el paquete de confirmación se le asigna kcp.rcv_nxt =1.
Este paquete se registra como [ACK sn=0 una=1] : Significa que en la confirmación del acuse de recibo se confirma el paquete número de secuencia 0. En una confirmación, se confirman todos los paquetes anteriores al paquete número 1.
En los pasos 2-3, se llama kcp.output para enviar el paquete de datos.
Llame a ikcp_recv en k2: (Figura Paso 2-4)
Compruebe si la cola kcp.rcv_queue contiene un paquete con seg.frp de 0 (ikcp.c:459). Si contiene este paquete, registre el primer paquete seg.frp == 0 y los datos del paquete anterior. este paquete. La longitud total se devuelve como valor de retorno. De lo contrario, esta función devuelve un valor de error de -1.
Debido a que kcp.rcv_queue solo tiene el paquete [PSH sn=0 frg=2 len=1376] en este momento, el intento de lectura falló.
Si está en modo de transmisión (kcp.stream! = 0), todos los paquetes se marcarán como
seg.frg=0. En este momento, todos los paquetes en la colakcp.rcv_queuese leerán correctamente.
Llame a ikcp_input: en k1 (Figura paso 3-1)
Paquete de entrada [ACK sn=0 una=1] .
La UNA confirma :
Cualquier paquete recibido intentará primero la confirmación UNA (ikcp.c:789)
Confirmó y eliminó todos los paquetes en la cola kcp.snd_buf seg.sn es menor que el valor una (ikcp:599) confirmando el valor seg.una del paquete.
[PSH sn=0 frg=2 len=1376] se confirma y se elimina de la cola kcp.snd_buf de k1.
Confirmación de confirmación :
Analice el tipo de paquete de datos e ingrese al procesamiento de la rama de confirmación. (ikcp.c:792)
Haga coincidir los números de secuencia de los paquetes de confirmación y elimine los paquetes correspondientes. (ikcp.c:581)
Al realizar la confirmación ACK en el paso 3-1, la cola kcp.snd_buf ya está vacía porque UNA ha confirmado de antemano el único paquete [PSH sn=0 frg=2 len=1376] .
Si se confirman kcp.snd_buf ( kcp.snd_una cambia), el valor cwnd del tamaño de la ventana de congestión se recalcula y se actualiza a 2 (ikcp.c:876).
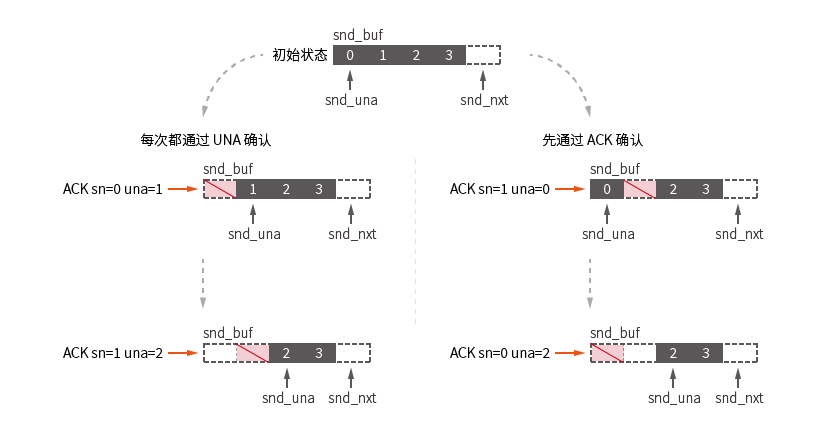
Diagrama de confirmación UNA / ACK. Este diagrama registra adicionalmente el estado de kcp.snd_una sin marcar en el diagrama de proceso:
El reconocimiento ACK no funcionará para los paquetes de reconocimiento que llegan secuencialmente. Para los paquetes que llegan fuera de orden, el paquete se elimina individualmente después de la confirmación vía ACK:
Llame a ikcp_flush en k1: (Figura paso 3-2)
Al igual que en los pasos 1-2, el valor de la nueva ventana de congestión kcp.cwnd se actualizó a 2 y los dos paquetes restantes se enviarán esta vez: [PSH sn=1 frg=1 len=1376] [PSH sn=2 frg=0 len=1344] .
En el paso 3-3, se llamará kcp.output dos veces para enviar paquetes de datos respectivamente.
Llame a ikcp_input: en k2 (Figura paso 4-1)
Paquetes de entrada [PSH sn=1 frg=1 len=1376] y [PSH sn=2 frg=0 len=1344] .
Cada paquete se agrega a la cola kcp.rcv_buf , está disponible y, finalmente, todo se mueve a la cola kcp.rcv_queue .
En este momento, la longitud de la cola kcp.rcv_queue de k2 es 3 y kcp.snd_buf es 0. El valor de kcp.rcv_nxt para el siguiente paquete que se espera recibir se actualiza de 1 a 3.
Llame a ikcp_flush en k2: (Figura paso 4-2)
La información de confirmación en kcp.acklist se codificará en paquetes [ACK sn=1 una=3] y [ACK sn=2 una=3] y se enviará en el paso 4-3.
De hecho, estos dos paquetes se escribirán en un búfer y se realizará una llamada kcp.output .
Llame a ikcp_recv en k2: (Figura paso 4-4)
Ahora hay tres paquetes no leídos en kcp.rcv_queue : [PSH sn=0 frg=2 len=1376] [PSH sn=1 frg=1 len=1376] y [PSH sn=2 frg=0 len=1344]
En este momento, se lee un paquete con seg.frg de 0 y se calcula que la longitud total legible es 4096. Luego, todos los datos de los tres paquetes se leerán y escribirán en el búfer de lectura y se devolverá el éxito.
Es necesario prestar atención a otra situación : si la cola kcp.rcv_queue contiene 2 paquetes enviados por el usuario con seg.frg de 2/1/0/2/1/0 y está fragmentada en 6 paquetes de datos, el correspondiente es También es necesario llamar a ikcp_recv dos veces para leer todos los datos completos recibidos.
Llame a ikcp_input: en k1 (Figura paso 5-1)
Ingrese los paquetes de confirmación [ACK sn=1 una=3] y [ACK sn=2 una=3] y analícelos en seg.una =3. El paquete [PSH sn=1 frg=1 len=1376] [PSH sn=2 frg=0 len=1344] se confirma y se elimina de la cola kcp.snd_buf a través de una.
Todos los datos enviados han sido acusados.
La ventana se utiliza para el control de flujo. Marca un rango lógico de la cola. Debido al procesamiento de datos reales, la posición de la cola continúa moviéndose a la posición alta del número de secuencia. Lógicamente, esta ventana seguirá moviéndose, expandiéndose y contrayéndose al mismo tiempo, por eso también se le llama ventana corredera .
Este diagrama esquemático es otra representación de los pasos 3-1 a 4-1 del diagrama de flujo en la sección "Proceso básico de envío y recepción de datos". Como operaciones fuera del alcance de los pasos, las direcciones de los datos se indican mediante flechas semitransparentes.
Todos los datos se procesan a través de la función señalada por la flecha y se mueven a una nueva ubicación (el doble del tamaño de la imagen):
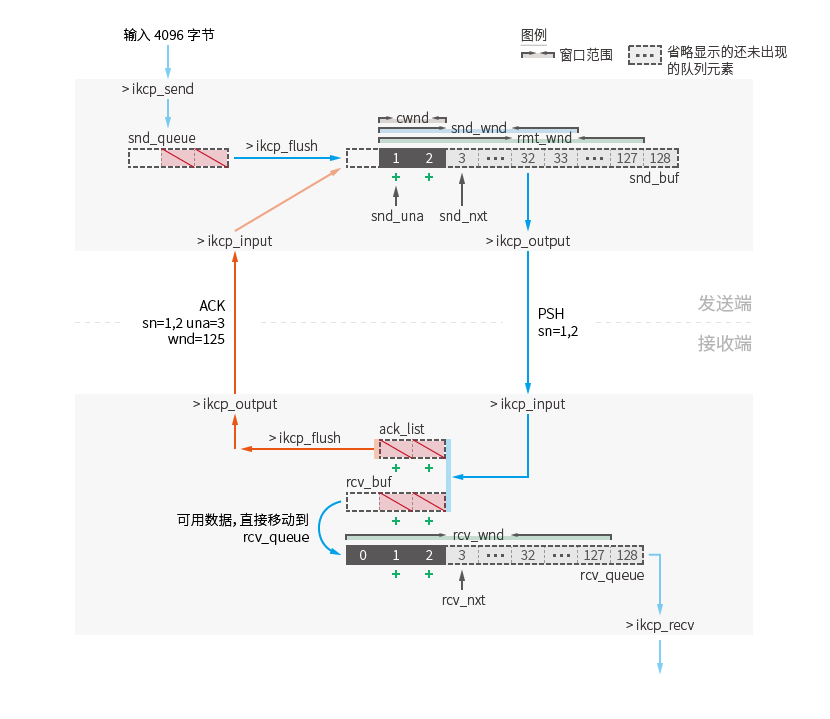
Los datos pasados por la función ikcp_send en el extremo emisor se almacenarán directamente en la cola de envío kcp.snd_queue después del procesamiento de la división de datos.
cada vez que se llama a ikcp_flush . El tamaño de la ventana para esta transmisión se calculará en función del tamaño de la ventana de envío kcp.snd_wnd , el tamaño de la ventana remota kcp.rmt_wnd y el tamaño de la ventana de congestión kcp.cwnd El valor es el mínimo de los tres: min( kcp.snd_wnd . kcp.rmt_wnd , kcp.cwd ) (ikcp.c:1017).
Si el parámetro nc se establece en 1 a través de la función ikcp_nodelay y el modo de control de flujo está desactivado, se ignora el cálculo del valor de la ventana de congestión. El resultado del cálculo de la ventana de envío es min( kcp.snd_wnd , kcp.rmt_wnd ) (ikcp.c:1018).
En la configuración predeterminada de desactivar solo el modo de control de flujo, la cantidad de paquetes de datos que se pueden enviar por primera vez es el valor de tamaño predeterminado de kcp.snd_wnd 32. Esto es diferente del ejemplo del proceso básico de envío y recepción, en el que solo se puede enviar un paquete por primera vez porque el control de flujo está habilitado de forma predeterminada.
Los paquetes de datos recién enviados se moverán a la cola kcp.snd_buf .
Para los datos de ikcp_send, solo hay un límite de segmento de 127 (es decir, 127*
kcp.mss= 174752 bytes). No hay límite en la cantidad total de paquetes en la cola de envío. Ver: Cómo evitar retrasos en la acumulación de caché
kcp.snd_buf almacena datos que se enviarán o se han enviado.
Cada vez que se llama ikcp_flush , se calcula la ventana de envío y el paquete de datos se mueve de kcp.snd_queue a la cola actual. Todos los paquetes de datos en la cola actual se procesarán en tres situaciones:
1. Primer envío de datos (ikcp.c:1053)
La cantidad de veces que se envía un paquete se registrará en seg.xmit . El procesamiento del primer envío es relativamente simple y se inicializarán algunos parámetros seg.rto / seg.resendts para el tiempo de espera de retransmisión.
2. Tiempo de espera de datos (ikcp.c:1058)
Cuando el tiempo kcp.current registrado internamente excede los seg.resendts del período de tiempo de espera del paquete en sí, se produce una retransmisión de tiempo de espera.
3. Confirmación de cruce de datos (ikcp.c:1072)
Cuando el extremo de los datos se expande y el número de intervalos seg.fastack excede la configuración de retransmisión de intervalos kcp.fastresend , se produce la retransmisión de intervalos. ( kcp.fastresend tiene el valor predeterminado 0, y cuando es 0, se calcula como UINT32_MAX y la retransmisión de intervalo nunca ocurrirá). Después de un tiempo de espera de retransmisión, el paquete actual seg.fastack se restablecerá a 0.
La lista de reconocimiento es una lista de registros simple que originalmente registra números de secuencia y marcas de seg.ts ( seg.sn ) en el orden en que se reciben los paquetes.
Por lo tanto, en el diagrama esquemático de este artículo,
kcp.ack_listno tendrá posiciones de elementos en blanco dibujadas. Porque no es una cola ordenada lógicamente (de manera similar, aunque al paquete en la colasnd_queueaún no se le ha asignado un número de secuencia, se ha determinado su número de secuencia lógico).
El extremo receptor almacena en buffer los paquetes de datos que no se pueden procesar temporalmente.
Todos los paquetes de datos entrantes de ikcp_input llegarán primero a esta cola y la información se registrará en kcp.ack_list en el orden de llegada original.
Sólo hay dos situaciones en las que los datos permanecerán en esta cola:
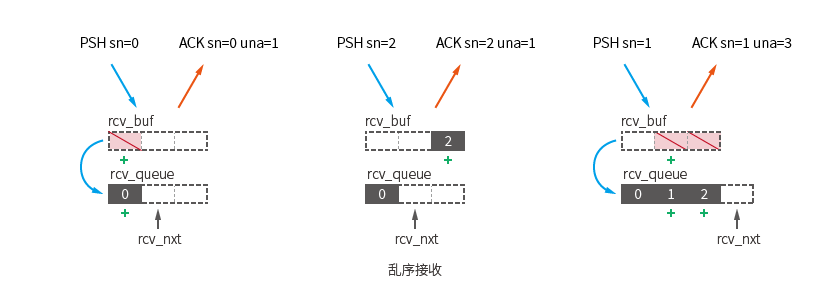
Aquí, primero se recibe el paquete [PSH sn=0] , que cumple con las condiciones de los paquetes disponibles y se mueve a kcp.rev_queue .
Luego se recibió el paquete [PSH sn=2] , que no era el siguiente paquete que se esperaba recibir ( seg.sn == kcp.rcv_nxt ), lo que provocó que este paquete permaneciera en kcp.rcv_buf .
Después de recibir el paquete [PSH sn=1] , mueva los dos paquetes atascados [sn=1] [sn=2] a kcp.rcv_queue .
kcp.rcv_queue alcanza el tamaño de la ventana de recepción kcp.rcv_wnd (no se llamó a ikcp_recv a tiempo).El extremo receptor almacena datos que pueden ser leídos por la capa superior.
En el modo de transmisión se leen todos los paquetes disponibles, en el modo sin transmisión se leen segmentos de datos fragmentados y se ensamblan en los datos sin procesar completos.
Una vez completada la lectura, se intentará mover datos de kcp.rcv_buf a esta cola (posiblemente para recuperarse de un estado de ventana de recepción completa).
El valor kcp.snd_wnd de la ventana de envío es un valor configurado y el valor predeterminado es 32.
La ventana remota kcp.rmt_wnd es un valor que se actualizará cuando el remitente reciba un paquete del receptor (no solo un paquete de confirmación). Registra la longitud disponible (ikcp.c:1086) de la cola de recepción del extremo receptor kcp.rcv_queue cuando el extremo receptor envía el paquete de datos actual. El valor inicial es 128.
La ventana de congestión es un valor calculado que crece algorítmicamente cada vez que se reciben datos a través de ikcp_input.
Si se detecta pérdida de paquetes y retransmisión rápida al vaciar datos ikcp_flush, se recalculará de acuerdo con el algoritmo.
La posición donde
kcp.cwndse inicializa en 1 es en la primera llamada de ikcp_update a ikcp_flush.
El valor kcp.rcv_wnd de la ventana de recepción es un valor configurado y el valor predeterminado es 128. Limita la longitud máxima de la cola de recepción kcp.rcv_queue .
En esta sección, se proporciona una versión mejorada de kcp_optional.c basada en el código de muestra de la sección "Envío y recepción de datos básicos". Puede observar más a fondo el comportamiento del protocolo modificando la definición de macro.
El código de muestra finaliza el proceso especificando escribir una cantidad específica de datos de longitud fija en k1 y leerlos completamente en k2.
Se proporcionan macros para controlar funciones específicas:
La ventana de congestión se registra mediante los valores de kcp.cwnd y kcp.incr . Dado que la unidad registrada por kcp.cwnd es paquete, se requiere kcp.incr adicional para registrar la ventana de congestión expresada en unidades de longitud de bytes.
Al igual que TCP, el control de congestión de KCP también se divide en dos etapas: inicio lento y evitación de congestión:
La ventana de congestión crece ; en el proceso de confirmación del paquete de datos, cada vez que se confirman kcp.snd_buf (confirmación efectiva de UNA, kcp.snd_una cambia). Y cuando la ventana de congestión es más pequeña que la ventana remota registrada kcp.rmt_wnd , la ventana de congestión aumenta. (ikcp:875)
1. Si la ventana de congestión es menor que el umbral de inicio lento kcp.ssthresh , está en la etapa de inicio lento y el crecimiento de la ventana de congestión es relativamente agresivo en este momento. La ventana de congestión crece en una unidad.
2. Si la ventana de congestión es mayor o igual que el umbral de inicio lento, está en la etapa de evitación de congestión y el crecimiento de la ventana de congestión es relativamente conservador. Si kcp.incr aumenta mss/16 cada vez, se requieren 16 confirmaciones UNA válidas antes de que aumente la ventana de congestión de la unidad. El crecimiento real de la ventana de la fase de evitación de la congestión es:
(mss * mss) / incr + (mss / 16)
Dado que incr=cwnd*mss es:
((mss * mss) / (cwnd * mss)) + (mss / 16)
Equivalente a:
(mss / cwnd) + (mss / 16)
La ventana de congestión crece incrementalmente por cada cwnd y cada 16 reconocimientos UNA válidos.
Reducción de la ventana de congestión : cuando la función ikcp_flush detecta la pérdida de paquetes entre retransmisiones o tiempos de espera, se reduce la ventana de congestión.
1. Cuando se produce la retransmisión del intervalo, el umbral de inicio lento kcp.ssthresh se establece en la mitad del intervalo del número de secuencia no reconocido. El tamaño de la ventana de congestión es el umbral de inicio lento más el valor de configuración de retransmisión rápida kcp.resend (ikcp:1117):
ssthresh = (snd_nxt - snd_una) / 2
cwnd = ssthresh + resend
2. Cuando se detecta un tiempo de espera de pérdida de paquetes, el umbral de inicio lento se establece en la mitad de la ventana de congestión actual. Ventana de congestión establecida en 1 (ikcp:1126):
ssthresh = cwnd / 2
cwnd = 1
Observe el inicio lento 1 : ejecute el código de muestra con la configuración predeterminada y observará que el proceso de inicio lento se omite rápidamente. Esto se debe a que el umbral de inicio lento predeterminado es 2:
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
# 收到一个确认包且拥塞窗口小于慢启动阈值,incr 增加一个 mss
t=100 n=1 una=1 nxt=2 cwnd=2|2 ssthresh=2 incr=2752
# 开始拥塞避免
t=200 n=1 una=2 nxt=3 cwnd=2|2 ssthresh=2 incr=3526
t=300 n=1 una=3 nxt=4 cwnd=4|4 ssthresh=2 incr=4148
t=400 n=1 una=4 nxt=5 cwnd=4|4 ssthresh=2 incr=4690
...
t en el contenido de salida es el tiempo lógico, n es el número de veces que k1 envía datos en el ciclo, el valor de cwnd=1|1 indica que el 1 delante del símbolo de la barra vertical es la ventana calculada cuando ikcp_flush, eso es, min(kcp. en modo de control de flujo. snd_wnd, kcp.rmt_wnd, kcp.cwnd), el valor del siguiente 1 es kcp.cwnd .
Observe gráficamente el crecimiento de la ventana de congestión bajo la configuración predeterminada: cuando se encuentra en la fase de evitación de la congestión, cuanto mayor es la ventana de congestión, más suave es el crecimiento de la ventana de congestión.
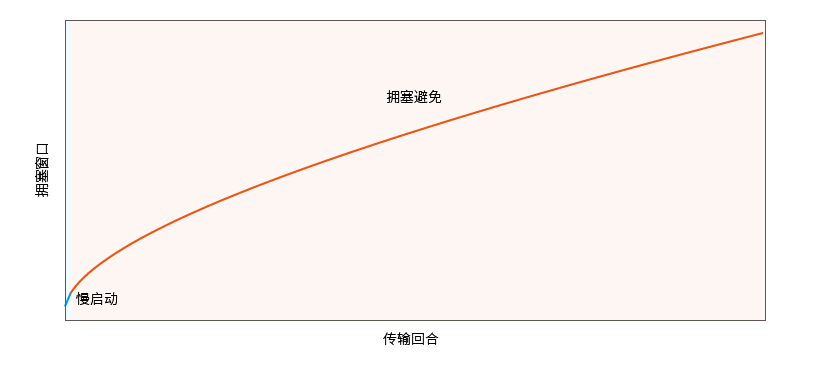
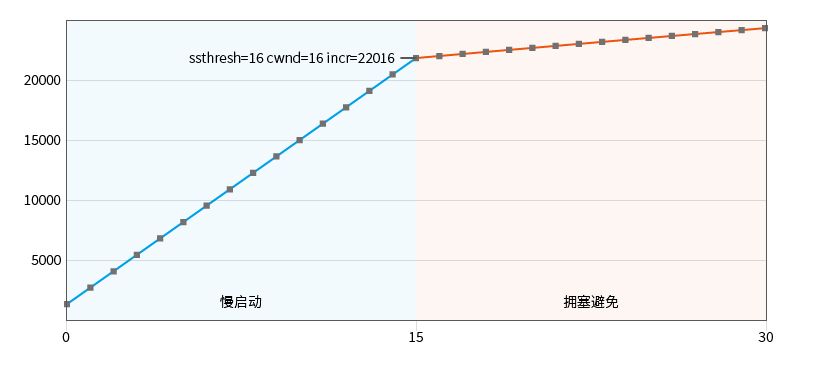
Observe el inicio lento 2 : ajuste el valor inicial del umbral de inicio lento de la configuración de muestra KCP_THRESH_INIT a 16:
#define KCP_THRESH_INIT 16
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=16 incr=1376
t=100 n=1 una=1 nxt=2 cwnd=2|2 ssthresh=16 incr=2752
t=200 n=1 una=2 nxt=3 cwnd=3|3 ssthresh=16 incr=4128
t=300 n=1 una=3 nxt=4 cwnd=4|4 ssthresh=16 incr=5504
...
t=1300 n=1 una=13 nxt=14 cwnd=14|14 ssthresh=16 incr=19264
t=1400 n=1 una=14 nxt=15 cwnd=15|15 ssthresh=16 incr=20640
t=1500 n=1 una=15 nxt=16 cwnd=16|16 ssthresh=16 incr=22016
# 开始拥塞避免
t=1600 n=1 una=16 nxt=17 cwnd=16|16 ssthresh=16 incr=22188
t=1700 n=1 una=17 nxt=18 cwnd=16|16 ssthresh=16 incr=22359
...
Al interceptar solo un corto período antes de la ronda de transmisión, se puede observar que el inicio lento también aumenta de manera lineal por defecto.
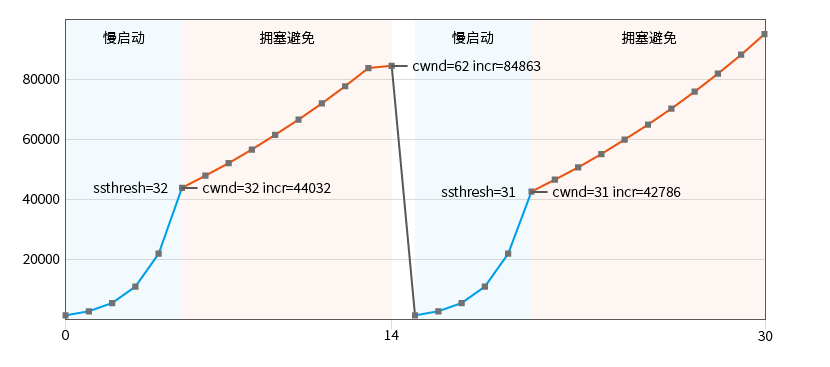
Observe cómo desactivar el acuse de recibo retrasado : envíe tantos datos como sea posible y desactive la opción de envío retrasado ACK_DELAY_FLUSH y simule una pérdida de paquetes:
#define KCP_WND 256, 256
#define KCP_THRESH_INIT 32
#define SEND_DATA_SIZE (KCP_MSS*64)
#define SEND_STEP 16
#define K1_DROP_SN 384
//#define ACK_DELAY_FLUSH
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=32 incr=1376
t=100 n=2 una=1 nxt=3 cwnd=2|2 ssthresh=32 incr=2752
t=200 n=4 una=3 nxt=7 cwnd=4|4 ssthresh=32 incr=5504
t=300 n=8 una=7 nxt=15 cwnd=8|8 ssthresh=32 incr=11008
t=400 n=16 una=15 nxt=31 cwnd=16|16 ssthresh=32 incr=22016
...
t=1100 n=52 una=269 nxt=321 cwnd=52|52 ssthresh=32 incr=72252
t=1200 n=56 una=321 nxt=377 cwnd=56|56 ssthresh=32 incr=78010
t=1300 n=62 una=377 nxt=439 cwnd=62|62 ssthresh=32 incr=84107
t=1400 n=7 una=384 nxt=446 cwnd=62|62 ssthresh=32 incr=84863
t=1500 n=1 una=384 nxt=446 cwnd=1|1 ssthresh=31 incr=1376
t=1600 n=2 una=446 nxt=448 cwnd=2|2 ssthresh=31 incr=2752
t=1700 n=4 una=448 nxt=452 cwnd=4|4 ssthresh=31 incr=5504
t=1800 n=8 una=452 nxt=460 cwnd=8|8 ssthresh=31 incr=11008
t=1900 n=16 una=460 nxt=476 cwnd=16|16 ssthresh=31 incr=22016
...
En este caso, se obtiene un gráfico clásico de inicio lento y evitación de congestión. Se detectó pérdida de paquetes en la decimoquinta ronda de transmisión (t=1500):
Desactivar la opción de envío retrasado significa que la parte receptora de datos llamará a ikcp_flush inmediatamente después de cada ejecución de ikcp_input para enviar un paquete de confirmación.
El proceso de inicio lento en este momento aumenta exponencialmente con cada RTT (tiempo de ida y vuelta), porque cada paquete de confirmación se enviará de forma independiente, lo que hará que la ventana de congestión del remitente crezca y, debido a que la ventana de congestión crece, la cantidad de paquetes Los envíos dentro de cada paquete RTT se duplicarán.
Si la confirmación se retrasa, se enviará un paquete de confirmación junto. El proceso de aumentar la ventana de congestión solo se ejecutará una vez cada vez que se llame a la función ikcp_input, por lo que fusionar varios paquetes de confirmación recibidos no tendrá el efecto de aumentar la ventana de congestión varias veces.
Si el intervalo del ciclo de reloj es mayor que RTT, aumentará exponencialmente en cada intervalo. El diagrama esquemático muestra una situación posible:
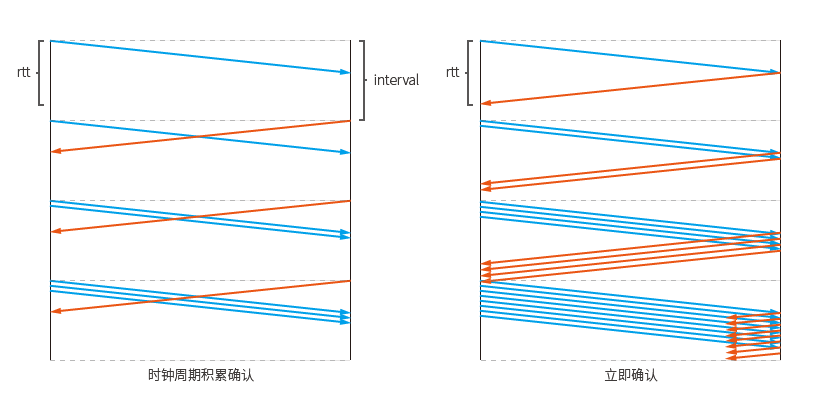
La premisa del crecimiento exponencial es que los datos enviados la próxima vez pueden satisfacer el doble de paquetes de datos la última vez. Si los datos escritos en el extremo emisor son insuficientes, no se logrará el crecimiento exponencial.
Cabe señalar que incluso si el código de muestra envía una confirmación inmediata, solo afecta la forma en que el receptor envía una confirmación. El remitente también debe esperar el siguiente ciclo antes de procesar estos paquetes de confirmación. Por lo tanto, el tiempo aquí es solo de referencia, a menos que el paquete recibido no se procese y almacene inmediatamente en el código del transceptor de red real, debe esperar hasta el ciclo de actualización antes de responder.
Según las características de KCP, debe haber una forma más directa de ampliar la ventana de congestión y desactivar directamente el control de flujo para obtener un envío más agresivo:
#define KCP_NODELAY 0, 100, 0, 1
#define SEND_DATA_SIZE (KCP_MSS*127)
#define SEND_STEP 1
t=0 n=32 una=0 nxt=32 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=32 una=32 nxt=64 cwnd=32|2 ssthresh=2 incr=2752
t=200 n=32 una=64 nxt=96 cwnd=32|2 ssthresh=2 incr=3526
t=300 n=31 una=96 nxt=127 cwnd=32|4 ssthresh=2 incr=4148
También puede modificar directamente el valor de la ventana de congestión según sea necesario.
Observe que la ventana remota está llena : si la longitud de los datos enviados está cerca del tamaño de la ventana remota predeterminada y el extremo receptor no los lee a tiempo, encontrará un período en el que no se pueden enviar datos (tenga en cuenta que En el código de muestra, el extremo receptor primero envía el paquete de confirmación y luego lee el contenido nuevamente):
#define KCP_NODELAY 0, 100, 0, 1
#define SEND_DATA_SIZE (KCP_MSS*127)
#define SEND_STEP 2
t=0 n=32 una=0 nxt=32 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=32 una=32 nxt=64 cwnd=32|2 ssthresh=2 incr=2752
t=200 n=32 una=64 nxt=96 cwnd=32|2 ssthresh=2 incr=3526
t=300 n=32 una=96 nxt=128 cwnd=32|4 ssthresh=2 incr=4148
t=400 n=0 una=128 nxt=128 cwnd=0|4 ssthresh=2 incr=4148
t=500 n=32 una=128 nxt=160 cwnd=32|4 ssthresh=2 incr=4148
t=600 n=32 una=160 nxt=192 cwnd=32|4 ssthresh=2 incr=4690
t=700 n=32 una=192 nxt=224 cwnd=32|4 ssthresh=2 incr=5179
t=800 n=30 una=224 nxt=254 cwnd=31|4 ssthresh=2 incr=5630
Cuando el tamaño de la ventana remota kcp.rmt_wnd registrado en el receptor es 0, la fase de espera de la sonda (espera de la sonda, ikcp.c:973) se iniciará en ikcp_flush. kcp.ts_probe registrará un tiempo inicialmente de 7000 milisegundos (registrado en kcp->probe_wait ).
Cuando llegue el momento, codifique adicionalmente un paquete de tipo IKCP_CMD_WASK y envíelo al extremo receptor (ikcp.c:994) para solicitar al extremo remoto que envíe de vuelta un paquete de tipo IKCP_CMD_WINS para actualizar kcp.rmt_wnd
Si el tamaño de la ventana remota es siempre 0, kcp->probe_wait aumenta a la mitad del valor actual cada vez y luego actualiza el tiempo de espera. El tiempo de espera máximo es 120000 milisegundos (120 segundos).
Cuando el tamaño de la ventana remota no es 0, se borra el estado de detección anterior.
En este ejemplo, no esperamos los 7 segundos iniciales antes de restaurar el tamaño de la ventana remota registrada. Porque en la operación de ikcp_recv en el extremo receptor para leer datos, cuando la longitud de kcp.rcv_queue es mayor o igual que la ventana de recepción kcp.rcv_wnd antes de leer los datos (la ventana de lectura está llena), se genera un bit de bandera (ikcp .c:431) y envíe un paquete de tipo IKCP_CMD_WINS (ikcp.c:1005) la próxima vez ikcp_flush Para notificar al remitente que actualice el último tamaño de ventana remota.
Para evitar este problema, los datos deben leerse en el extremo receptor de manera oportuna. Sin embargo, incluso si la ventana remota se reduce, la ventana de envío del remitente se reducirá, lo que provocará retrasos adicionales. Al mismo tiempo, también es necesario aumentar la ventana de recepción del extremo receptor.
Intente modificar el valor RECV_TIME a un valor relativamente grande (por ejemplo, 300 segundos) y luego observe el envío del paquete IKCP_CMD_WASK.
Como se describe en la descripción de la cola kcp.snd_buf , al llamar a ikcp_flush, se atravesarán todos los paquetes de la cola, si el paquete no se envía por primera vez. Luego comprobará si el paquete ha sido cruzado confirmando el número de veces especificado o si se ha alcanzado el período de tiempo de espera.
Los campos relacionados con el tiempo de ida y vuelta y el cálculo del tiempo de espera son:
kcp.rx_rttval : tiempo de fluctuación de red fluidokcp.rx_srtt : tiempo de ida y vuelta fluidokcp.rx_rto (Tiempo de espera de retransmisión de recepción): tiempo de espera de retransmisión, valor inicial 200kcp.rx_minrto : tiempo de espera mínimo de retransmisión, valor inicial 100kcp.xmit : recuento de retransmisiones globalesseg.resendts : marca de tiempo de retransmisiónseg.rto : tiempo de espera de retransmisiónseg.xmit : recuento de retransmisionesAntes de discutir cómo el paquete calcula los tiempos de espera, primero veamos cómo se calculan los campos relacionados de tiempo de ida y vuelta y tiempo de espera:
Registro de tiempo de ida y vuelta : cada vez que se procesa un paquete de confirmación ACK, el paquete de confirmación llevará seg.ts número de secuencia y la hora en que se envió el número de secuencia al remitente ( seg.sn ). Cuando sea legal, el viaje de ida y vuelta. hora en que se ejecuta el proceso de actualización.
El valor de RTT es el tiempo de ida y vuelta de un solo paquete, es decir, rtt = kcp.current - seg.ts
Si el tiempo de ida y vuelta suavizado kcp.rx_srtt es 0, significa que la inicialización se realiza: kcp.rx_srtt se registra directamente como RTT, kcp.rx_rttval se registra como la mitad de RTT.
En el proceso de no inicialización, se calcula un valor delta, que representa el valor de fluctuación de este RTT y el kcp.rx_srtt registrado (IKCP.C: 550):
delta = abs(rtt - rx_srtt)
El nuevo kcp.rx_rttval se actualiza por el valor ponderado del antiguo kcp.rx_rttval y delta:
rx_rttval = (3 * rx_rttval + delta) / 4
El nuevo kcp.rx_srtt se actualiza mediante el valor ponderado del antiguo kcp.rx_srtt y rtt, y no puede ser inferior a 1:
rx_srtt = (7 * rx_srtt + rtt) / 8
rx_srtt = max(1, rx_srtt)
El nuevo rx_rto se actualiza mediante el valor mínimo del tiempo de viaje redondo suavizado kcp.rx_srtt más el ciclo de reloj kcp.interval y 4 veces rx_rttval , y el rango está limitado a [ kcp.rx_minrto , 60000]::
rto = rx_srtt + max(interval, 4 * rttval)
rx_rto = min(max(`kcp.rx_minrto`, rto), 60000)
Idealmente, cuando la red solo tiene un retraso fijo y no tiene jitter, el valor de kcp.rx_rttval se acercará 0, y el valor de kcp.rx_rto está determinado por el tiempo de ida y vuelta suave y el ciclo de reloj.
Diagrama de cálculo de tiempo de ida y vuelta suave:
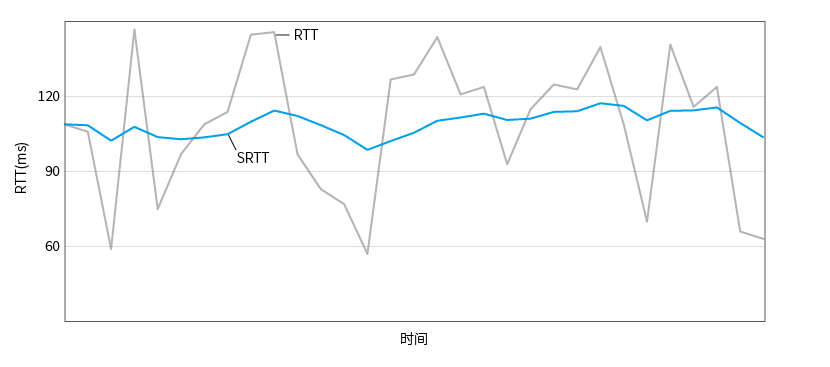
Primer tiempo de entrega de contrato (IKCP.C: 1052):
seg.rto registrará el estado kcp.rx_rto , y el primer tiempo de tiempo de espera del paquete de datos es seg.rto + Rtomin Millisegunds.
La rtomin se calcula por kcp.rx_rto , si el modo noDelay está habilitado. Rtomin es 0, de lo contrario kcp.rx_rto /8.
Tiempo de espera para nodelay no habilitado:
resendts = current + rx_rto + rx_rto / 8
Habilitar el tiempo de espera de Nodelay:
resendts = current + rx_rto
Tiempo de espera de retransmisión (IKCP.C: 1058):
Cuando el tiempo interno alcanza el tiempo de tiempo de espera seg.resendts del paquete de datos, el paquete con este número de secuencia se retransmite.
Cuando el modo Nodelay no está habilitado, el incremento de seg.rto es Max ( seg.rto , kcp.rx_rto ) (doble crecimiento):
rto += max(rto, rx_rto)
Cuando Nodelay está habilitado y Nodelay es 1, aumente seg.rto a la mitad cada vez (1.5 veces aumenta):
rto += rto / 2
Cuando Nodelay está habilitado y Nodelay es 2, kcp.rx_rto se incrementa en la mitad cada vez (aumento de 1.5 veces):
rto += rx_rto / 2
El nuevo tiempo de espera es después de seg.rto milisegundos:
resendts = current + rx_rto
Retransmisión a través del tiempo (IKCP.C: 1072):
Cuando se cruza un paquete de datos un número especificado de veces, se activa una retransmisión de cruce.
seg.rto no se actualiza cuando se retransmite a través del tiempo, y el próximo tiempo de retransmisión de tiempo de espera se recalcula directamente:
resendts = current + rto
Observe el tiempo de espera predeterminado
Solo envíe un paquete, suelte cuatro veces y observe el tiempo de espera y el tiempo de retransmisión.
Para la configuración predeterminada, el valor inicial de kcp.rx_rto es de 200 milisegundos, y el primer tiempo de tiempo de espera es de 225 milisegundos. .
#define SEND_STEP 1
#define K1_DROP_SN 0,0,0,0
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=300 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=700 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1500 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=3100 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
Observe un aumento de 1.5x en RTO basado en el paquete en sí
#define KCP_NODELAY 1, 100, 0, 0
#define SEND_STEP 1
#define K1_DROP_SN 0,0,0,0
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=200 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=500 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1000 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1700 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
Mira el crecimiento de 1.5x basado en RTO
#define KCP_NODELAY 2, 100, 0, 0
#define SEND_STEP 1
#define K1_DROP_SN 0,0,0,0
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=200 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=500 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=900 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1400 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
Observe las retransmisiones del tramo
Los paquetes [sn=0] [sn=1] procesados por la fusión no activarán [sn=2] retransmisión del tramo. Al final, fue retransmitido a través del tiempo de espera.
#define KCP_NODELAY 0, 100, 2, 1
#define SEND_DATA_SIZE (KCP_MSS*3)
#define SEND_STEP 1
#define K1_DROP_SN 0
t=0 n=3 una=0 nxt=3 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=0 una=0 nxt=3 cwnd=32|1 ssthresh=2 incr=1376
t=200 n=0 una=0 nxt=3 cwnd=32|1 ssthresh=2 incr=1376
t=300 n=1 una=0 nxt=3 cwnd=32|1 ssthresh=16 incr=1376
Al enviar paquetes de datos en dos pasos, el segundo grupo de paquetes se cruzará dos veces al realizar la confirmación de IKCP_Input, y [sn=0] se acumulará y retransmitirá durante el próximo IKCP_FLUSH.
#define KCP_NODELAY 0, 100, 2, 1
#define SEND_DATA_SIZE (KCP_MSS*2)
#define SEND_STEP 2
#define K1_DROP_SN 0
t=0 n=2 una=0 nxt=2 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=2 una=0 nxt=4 cwnd=32|1 ssthresh=2 incr=1376
t=200 n=1 una=0 nxt=4 cwnd=32|4 ssthresh=2 incr=5504
t=300 n=0 una=4 nxt=4 cwnd=32|4 ssthresh=2 incr=5934
El artículo tiene licencia bajo una licencia internacional de atribución de Commons-Commons-Noderivs 4.0.
El código en el proyecto es de código abierto utilizando la licencia MIT.
Sobre la fuente de la imagen: noto sans sc


