metal flash attention
v1.0.1
Este repositorio traslada la implementación oficial de FlashAttention al silicio de Apple. Es un conjunto mínimo y mantenible de archivos fuente que reproduce el algoritmo FlashAttention.
Atención unidireccional únicamente, para centrarse en los cuellos de botella centrales de diferentes algoritmos de atención (presión de registro, paralelismo). Con el algoritmo básico realizado correctamente, debería ser comparativamente trivial agregar personalizaciones como la escasez de bloques.
Todo está compilado JIT en tiempo de ejecución. Esto contrasta con la implementación anterior, que se basaba en un ejecutable integrado en Xcode 14.2.
El pase hacia atrás usa menos memoria que Dao-AILab/flash-attention. La implementación oficial asigna espacio temporal para sumas atómicas y parciales. El hardware de Apple carece de átomos FP32 nativos (se emula metal::atomic<float> ). Al intentar sortear la falta de soporte de hardware, se revelaron cuellos de botella de ancho de banda y paralelización en el kernel inverso FlashAttention-2. Se diseñó un paso hacia atrás alternativo con un mayor costo de cómputo (7 GEMM en lugar de 5 GEMM). Logra una eficiencia de paralelización del 100 % en las dimensiones de fila y columna de la matriz de atención. Lo más importante es que es más fácil de codificar y mantener.
Se hicieron muchas cosas locas para superar los cuellos de botella de presión de registro. Con dimensiones de cabezal grandes (por ejemplo, 256), ninguno de los bloques de matriz puede caber en los registros. Ni siquiera el acumulador puede hacerlo. Por tanto, se realiza el derrame de registros intencional, pero de forma más optimizada. Se agregó una tercera dimensión de bloque al algoritmo de atención, que bloquea a lo largo de D La relación de aspecto de los bloques de la matriz de atención se deformó mucho para minimizar el costo del ancho de banda debido al desbordamiento de registros. Por ejemplo, 16-32 a lo largo de la dimensión de paralelización y 80-128 a lo largo de la dimensión transversal. Hay un archivo de parámetros grande que toma la dimensión D y determina qué operandos pueden caber en los registros. Luego asigna un tamaño de bloque que equilibra muchos cuellos de botella en competencia.
El resultado final son 4400 gigainstrucciones consistentes por segundo en M1 Max (83% de utilización de ALU), con una longitud de secuencia infinita y un tamaño de cabeza infinito. La emulación BF16 proporcionada se utiliza para precisión mixta ( bfloat de Metal tiene redondeo compatible con IEEE, una sobrecarga importante en chips más antiguos sin hardware BF16).
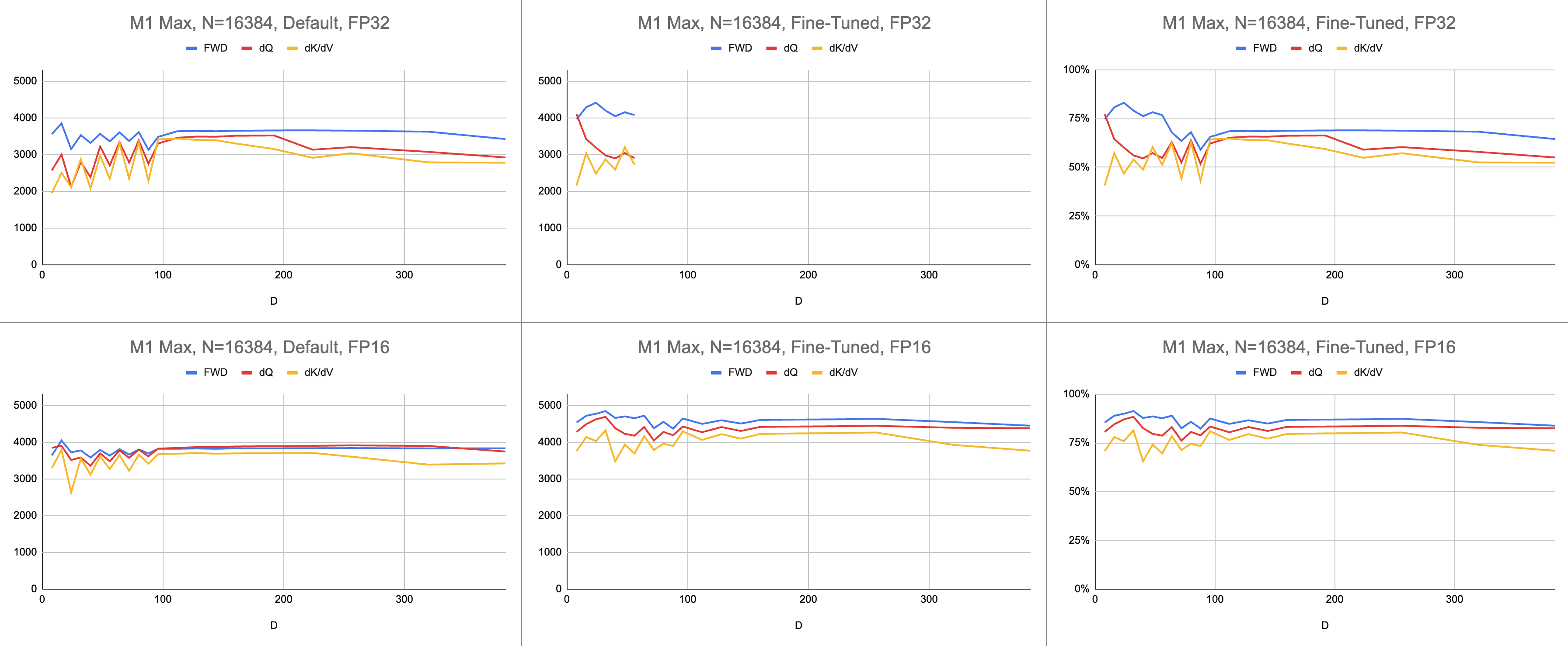
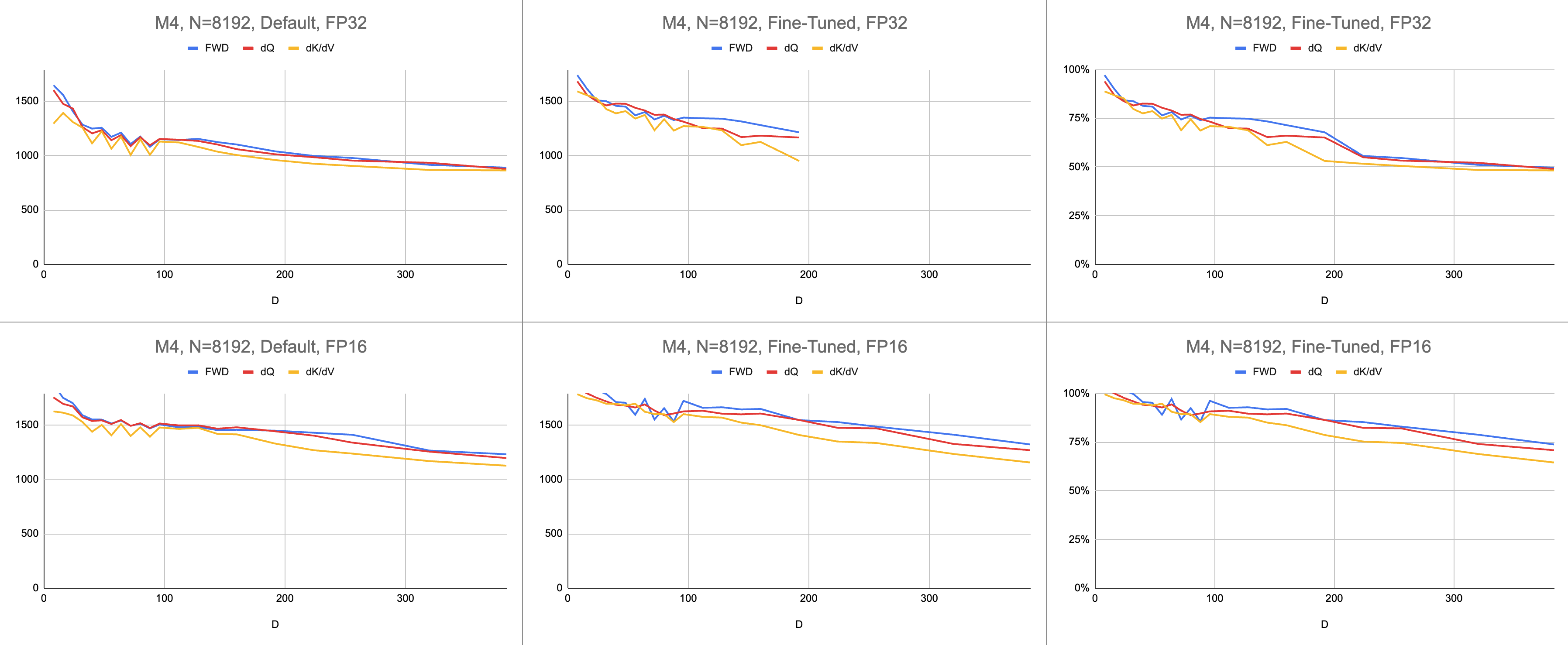
Datos sin procesar: https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
En el campo de la IA, el rendimiento se informa con mayor frecuencia en operaciones de gigacoma flotante por segundo (GFLOPS). Esta métrica refleja un modelo simplificado de rendimiento, en el que cada instrucción ocurre en GEMM. A medida que el hardware avanzó desde las primeras FPU hasta los procesadores vectoriales modernos, las operaciones de punto flotante más comunes se fusionaron en una sola instrucción. Fusionado de suma múltiple (FMA). Cuando se multiplican dos matrices de 100x100, se emiten 1 millón de instrucciones FMA. ¿Por qué debemos tratar esta FMA como dos instrucciones separadas?
Esta pregunta es relevante para la atención, donde no todas las operaciones de punto flotante son iguales. La exponenciación durante softmax ocurre en un solo ciclo de reloj, dado que la mayoría de las otras instrucciones van a la unidad FMA. Algunas de las multiplicaciones y sumas durante softmax no se pueden fusionar con una suma o multiplicación cercana. ¿Deberíamos tratarlos de la misma manera que FMA y pretender que el hardware simplemente ejecuta FMA dos veces más lento? No está claro cómo el modelo de rendimiento GEMM puede explicar si mi sombreador está utilizando el hardware ALU de manera efectiva.
En lugar de gigaflops, utilizo gigainstrucciones para comprender qué tan bien está funcionando el sombreador. Se asigna más directamente al algoritmo. Por ejemplo, un GEMM son N^3 instrucciones FMA. La atención directa realiza dos multiplicaciones de matrices, o instrucciones FMA 2 * D * N^2 . La atención hacia atrás (según la implementación de Dao-AILab/flash-attention) son 5 * D * N^2 instrucciones FMA. Intente comparar esta tabla con los modelos de línea de techo en los artículos Flash1, Flash2 o Flash3.
| Operación | Trabajar |
|---|---|
| GEMM cuadrado | N^3 |
| Atención hacia adelante | (2D + 5) * N^2 |
| Atención ingenua hacia atrás | 4D * N^2 |
| Flash hacia atrásAtención | (5D + 5) * N^2 |
| FWD + BWD combinado | (7D + 10) * N^2 |
Debido a la complejidad de los átomos de FP32, MFA utilizó un enfoque diferente para el paso hacia atrás. Éste tiene un costo de cómputo más alto. Divide el pase hacia atrás en dos núcleos separados: dQ y dK/dV . Un menú desplegable muestra el pseudocódigo. Compare esto con uno de los algoritmos de los artículos Flash1, Flash2 o Flash3.
| Operación | Trabajar |
|---|---|
| Adelante | (2D + 5) * N^2 |
| dq hacia atrás | (3D + 5) * N^2 |
| Hacia atrás dK/dV | (4D + 5) * N^2 |
| FWD + BWD combinado | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }El rendimiento se mide calculando la cantidad de trabajo informático y luego dividiéndolo por segundos. El resultado final son "gigainstrucciones por segundo". A continuación, necesitamos un modelo de línea de techo. La siguiente tabla muestra las líneas de techo para GINSTRS, calculadas como la mitad de GFLOPS. La utilización de ALU es (gigainstrucciones reales por segundo) / (gigainstrucciones esperadas por segundo). Por ejemplo, M1 Max normalmente logra una utilización de ALU del 80% con precisión mixta.
Hay límites para este modelo. Se descompone con la generación M3 con dimensiones de cabeza pequeñas. Se pueden utilizar diferentes unidades de cómputo simultáneamente, lo que hace que la utilización aparente supere el 100%. En su mayor parte, el punto de referencia proporciona un modelo preciso de cuánto rendimiento queda sobre la mesa.
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| Hardware | GFLOPS | GINSTRS |
|---|---|---|
| M1 máx. | 10616 | 5308 |
| M4 | 3580 | 1790 |
¿Qué tan bien se compara el port Metal con el repositorio oficial FlashAttention? Imagínese que elegí el algoritmo "atómico dQ" y logré un rendimiento del 100%. Luego, cambié al repositorio de MFA real y descubrí que el entrenamiento del modelo era 4 veces más lento. Eso sería el 25% de la línea del techo del depósito oficial. Para obtener este porcentaje, multiplique la utilización promedio de ALU en los tres núcleos por 7 / 9 . Se utilizó un modelo más matizado para las estadísticas sobre el hardware de Apple, pero esto es lo esencial.
Para calcular la utilización del hardware de Nvidia, utilicé GFLOPS para las ALU FP16/BF16. Dividí los GFLOPS más altos de cada gráfico del artículo entre 312000 (A100 SXM), 989000 (H100 SXM). Tenga en cuenta que, para dimensiones de cabeza más grandes y núcleos intensivos en registro (paso hacia atrás), no se informaron puntos de referencia. Confirmé que no resolvieron el problema de la presión de registro en dimensiones de cabeza infinitas. Por ejemplo, el acumulador siempre se guarda en registros. Al momento de escribir este artículo, no había visto evidencia concreta de que el gradiente hacia atrás D=256 se ejecutara con resultados correctos.
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Adelante | 192000 | 223000 | 0 |
| Hacia atrás | 170000 | 196000 | 0 |
| Adelante + Atrás | 176000 | 203000 | 0 |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Adelante | 497000 | 648000 | 756000 |
| Hacia atrás | 474000 | 561000 | 0 |
| Adelante + Atrás | 480000 | 585000 | 0 |
| H100, Flash3, FP8 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Adelante | 613000 | 1008000 | 1171000 |
| Hacia atrás | 0 | 0 | 0 |
| Adelante + Atrás | 0 | 0 | 0 |
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Adelante | 62% | 71% | 0% |
| Adelante + Atrás | 56% | 65% | 0% |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Adelante | 50% | 66% | 76% |
| Adelante + Atrás | 48% | 59% | 0% |
| Arquitectura M1, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Adelante | 86% | 85% | 86% |
| Adelante + Atrás | 62% | 63% | 64% |
| Arquitectura M3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Adelante | 94% | 91% | 82% |
| Adelante + Atrás | 71% | 69% | 61% |
| Hardware producido en 2020 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| Arquitectura M1—M2 | 62% | 63% | 64% |
| Hardware producido en 2023 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| H100 (usando FP8 GFLOPS) | 24% | 30% | 0% |
| H100 (usando FP16 GFLOPS) | 48% | 59% | 0% |
| Arquitectura M3—M4 | 71% | 69% | 61% |
A pesar de emitir más cálculos, el hardware de Apple está entrenando transformadores más rápido que el hardware de Nvidia que realiza el mismo trabajo . Normalizando la diferencia de tamaño entre diferentes GPU. Centrándonos únicamente en la eficiencia con la que se utiliza la GPU.
Quizás el repositorio principal debería probar el algoritmo que evita los átomos FP32 y derrama deliberadamente registros cuando no caben en el núcleo de la GPU. Esto parece poco probable, ya que tienen soporte codificado para un pequeño subconjunto de los posibles tamaños de problemas. La motivación parece ser respaldar los modelos más comunes, donde D es una potencia de 2 y menos de 128. Para cualquier otra cosa, los usuarios deben confiar en implementaciones alternativas (por ejemplo, el repositorio MFA), que podrían usar un subyacente completamente diferente. algoritmo.
En macOS, descargue el paquete Swift y compílelo con -Xswiftc -Ounchecked . Esta opción del compilador es necesaria para el código de CPU sensible al rendimiento. El modo de lanzamiento no se puede utilizar porque obliga a volver a compilar todo el código base desde cero, cada vez que hay un solo cambio. Navegue hasta el repositorio de Git en Finder y haga doble clic en Package.swift . Debería aparecer una ventana de Xcode. A la izquierda debería haber una jerarquía de archivos. Si no puedes desentrañar la jerarquía, algo salió mal.
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
Alternativamente, cree un nuevo proyecto Xcode con la plantilla SwiftUI. Anule el mensaje "Hello, world!" string con una llamada a una función que devuelve un String . Esta función ejecutará el script de su elección y luego llamará exit(0) para que la aplicación se bloquee antes de mostrar algo en la pantalla. Utilizará el resultado en la consola Xcode como comentarios sobre su código. Este flujo de trabajo es compatible tanto con macOS como con iOS.
Agregue la opción -Xswiftc -Ounchecked a través de Proyecto > el nombre de su proyecto > Configuración de compilación > Compilador Swift - Generación de código > Nivel de optimización . La segunda columna de la tabla enumera el nombre de su proyecto. Haga clic en Otro en el menú desplegable y escriba -Ounchecked en el panel que aparece. A continuación, agregue este repositorio como una dependencia del paquete Swift. Revise algunas de las pruebas en Tests/FlashAttention . Copie el código fuente sin formato de una de estas pruebas en su proyecto. Invoca la prueba desde la función del párrafo anterior. Examina lo que muestra en la consola.
Para modificar la generación del código Metal (por ejemplo, agregar soporte para máscaras o cabezales múltiples), copie el código Swift sin formato en su proyecto Xcode. Utilice git clone en una carpeta separada o descargue los archivos sin formato en GitHub como ZIP. También hay una manera de vincularse a su bifurcación de metal-flash-attention y guardar automáticamente sus cambios en la nube, pero esto es más difícil de configurar. Elimine la dependencia del paquete Swift del párrafo anterior. Vuelva a ejecutar la prueba de su elección. ¿Compila y muestra algo en la consola?
Localice uno de los literales de cadena de varias líneas en cualquiera de estas carpetas:
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
Añade texto aleatorio a uno de ellos. Compile y ejecute el proyecto nuevamente. Algo debería salir terriblemente mal. Por ejemplo, el compilador Metal puede generar un error. Si esto no sucede, intente estropear una línea de código diferente en otro lugar. Si la prueba aún pasa, Xcode no registra sus cambios.
Continúe codificando la escasez de bloques o algo así. Obtenga comentarios sobre si el código funciona, si funciona rápido y si funciona rápido en todos los tamaños de problemas. Integre el código fuente sin formato en su aplicación o tradúzcalo a otro lenguaje de programación.


