flash attention jax
0.3.1
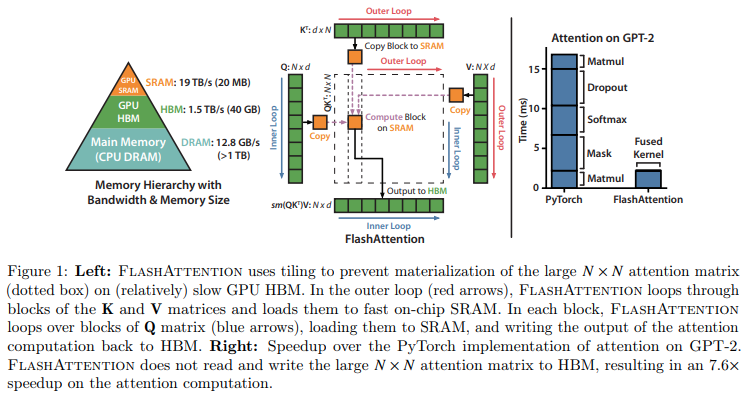
Implementación de Flash Atención en Jax. Probablemente no tendrá tanto rendimiento como la versión oficial de CUDA, dada la falta de capacidad para una gestión precisa de la memoria. Pero solo con fines educativos y para ver qué tan inteligente es (o no es) el compilador XLA.
$ pip install flash-attention-jax from jax import random
from flash_attention_jax import flash_attention
rng_key = random . PRNGKey ( 42 )
q = random . normal ( rng_key , ( 1 , 2 , 131072 , 512 )) # (batch, heads, seq, dim)
k = random . normal ( rng_key , ( 1 , 2 , 131072 , 512 ))
v = random . normal ( rng_key , ( 1 , 2 , 131072 , 512 ))
mask = random . randint ( rng_key , ( 1 , 131072 ,), 0 , 2 ) # (batch, seq)
out , _ = flash_attention ( q , k , v , mask )
out . shape # (1, 2, 131072, 512) - (batch, heads, seq, dim)Comprobación rápida de cordura
from flash_attention_jax import plain_attention , flash_attention , value_and_grad_difference
diff , ( dq_diff , dk_diff , dv_diff ) = value_and_grad_difference (
plain_attention ,
flash_attention ,
seed = 42
)
print ( 'shows differences between normal and flash attention for output, dq, dk, dv' )
print ( f'o: { diff } ' ) # < 1e-4
print ( f'dq: { dq_diff } ' ) # < 1e-6
print ( f'dk: { dk_diff } ' ) # < 1e-6
print ( f'dv: { dv_diff } ' ) # < 1e-6Atención de flash autorregresivo: atención de decodificador tipo GPT
from jax import random
from flash_attention_jax import causal_flash_attention
rng_key = random . PRNGKey ( 42 )
q = random . normal ( rng_key , ( 131072 , 512 ))
k = random . normal ( rng_key , ( 131072 , 512 ))
v = random . normal ( rng_key , ( 131072 , 512 ))
out , _ = causal_flash_attention ( q , k , v )
out . shape # (131072, 512) Dimensiones principales para la variante causal de atención flash.
resolver el problema con jit y argumentos estáticos
comentario con referencias a algoritmos y explicaciones en papel
asegúrese de que pueda funcionar con claves/valores de un solo cabezal, como en PaLM
@article { Dao2022FlashAttentionFA ,
title = { FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness } ,
author = { Tri Dao and Daniel Y. Fu and Stefano Ermon and Atri Rudra and Christopher R'e } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2205.14135 }
} @article { Rabe2021SelfattentionDN ,
title = { Self-attention Does Not Need O(n2) Memory } ,
author = { Markus N. Rabe and Charles Staats } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2112.05682 }
}

