FLASH pytorch
0.1.9
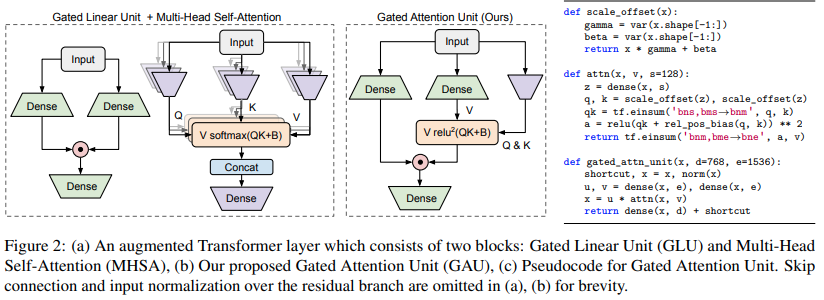
Implementación de la variante Transformer propuesta en el artículo Transformer Quality in Linear Time
$ pip install FLASH-pytorchEl principal circuito novedoso de este artículo es la "Unidad de atención cerrada", que, según afirman, puede reemplazar la atención de múltiples cabezas y reducirla a una sola cabeza.
Utiliza una activación relu cuadrado en lugar de softmax, cuya activación se vio por primera vez en el artículo Primer, y el uso de ReLU en ReLA Transformer. El estilo de activación parece inspirado principalmente en los gMLP.
import torch
from flash_pytorch import GAU
gau = GAU (
dim = 512 ,
query_key_dim = 128 , # query / key dimension
causal = True , # autoregressive or not
expansion_factor = 2 , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1024 , 512 )
out = gau ( x ) # (1, 1024, 512) Luego, los autores combinan GAU con la atención lineal de Katharopoulos, utilizando la agrupación de secuencias para superar un problema conocido con la atención lineal autorregresiva.
Esta combinación de la unidad de atención cerrada cuadrática con atención lineal agrupada la llamaron FLASH
También puedes usar esto con bastante facilidad.
import torch
from flash_pytorch import FLASH
flash = FLASH (
dim = 512 ,
group_size = 256 , # group size
causal = True , # autoregressive or not
query_key_dim = 128 , # query / key dimension
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1111 , 512 ) # sequence will be auto-padded to nearest group size
out = flash ( x ) # (1, 1111, 512)Finalmente, puede utilizar el transformador FLASH completo como se menciona en el documento. Contiene todas las incrustaciones posicionales mencionadas en el artículo. La incrustación posicional absoluta utiliza sinusoidal escalada. La atención cuadrática de GAU obtendrá un sesgo posicional relativo de T5 unidireccional. Además de todo esto, tanto la atención GAU como la atención lineal serán rotativas integradas (RoPE).
import torch
from flash_pytorch import FLASHTransformer
model = FLASHTransformer (
num_tokens = 20000 , # number of tokens
dim = 512 , # model dimension
depth = 12 , # depth
causal = True , # autoregressive or not
group_size = 256 , # size of the groups
query_key_dim = 128 , # dimension of queries / keys
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
norm_type = 'scalenorm' , # in the paper, they claimed scalenorm led to faster training at no performance hit. the other option is 'layernorm' (also default)
shift_tokens = True # discovered by an independent researcher in Shenzhen @BlinkDL, this simply shifts half of the feature space forward one step along the sequence dimension - greatly improved convergence even more in my local experiments
)
x = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
logits = model ( x ) # (1, 1024, 20000) $ python train.py @article { Hua2022TransformerQI ,
title = { Transformer Quality in Linear Time } ,
author = { Weizhe Hua and Zihang Dai and Hanxiao Liu and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.10447 }
} @software { peng_bo_2021_5196578 ,
author = { PENG Bo } ,
title = { BlinkDL/RWKV-LM: 0.01 } ,
month = { aug } ,
year = { 2021 } ,
publisher = { Zenodo } ,
version = { 0.01 } ,
doi = { 10.5281/zenodo.5196578 } ,
url = { https://doi.org/10.5281/zenodo.5196578 }
} @inproceedings { Ma2022MegaMA ,
title = { Mega: Moving Average Equipped Gated Attention } ,
author = { Xuezhe Ma and Chunting Zhou and Xiang Kong and Junxian He and Liangke Gui and Graham Neubig and Jonathan May and Luke Zettlemoyer } ,
year = { 2022 }
}

