guidance for natural language queries of relational databases on aws
1.0.0
Cette solution AWS contient une démonstration de l'IA générative, en particulier l'utilisation de Natural Language Query (NLQ) pour poser des questions à une base de données Amazon RDS pour PostgreSQL. Cette solution propose trois options architecturales pour les modèles de base : 1. Amazon SageMaker JumpStart, 2. Amazon Bedrock et 3. API OpenAI. L'application Web de la démonstration, exécutée sur Amazon ECS sur AWS Fargate, utilise une combinaison de LangChain, Streamlit, Chroma et HuggingFace SentenceTransformers. L'application accepte les questions en langage naturel des utilisateurs finaux et renvoie des réponses en langage naturel, ainsi que la requête SQL associée et l'ensemble de résultats compatible Pandas DataFrame.
La sélection du Foundation Model (FM) pour Natural Language Query (NLQ) joue un rôle crucial dans la capacité de l'application à traduire avec précision des questions en langage naturel en réponses en langage naturel. Tous les FM ne sont pas capables d'effectuer le NLQ. En plus du choix du modèle, la précision de NLQ repose également en grande partie sur des facteurs tels que la qualité de l'invite, le modèle d'invite, les exemples de requêtes étiquetées utilisées pour l'apprentissage en contexte ( c'est-à-dire l'invite en quelques étapes ) et les conventions de dénomination utilisées pour le schéma de base de données. , à la fois les tableaux et les colonnes.
L'application NLQ a été testée sur une variété de FM open source et commerciaux. À titre de référence, les modèles des séries Generative Pre-trained Transformer GPT-3 et GPT-4 d'OpenAI, y compris gpt-3.5-turbo et gpt-4 , fournissent tous des réponses précises à un large éventail de requêtes en langage naturel simples à complexes en utilisant une moyenne quantité d'apprentissage en contexte et d'ingénierie rapide minimale.
Amazon Titan Text G1 - Express, amazon.titan-text-express-v1 , disponible via Amazon Bedrock, a également été testé. Ce modèle a fourni des réponses précises aux requêtes de base en langage naturel en utilisant une optimisation d'invite spécifique au modèle. Cependant, ce modèle n’était pas capable de répondre à des requêtes plus complexes. Une optimisation plus rapide pourrait améliorer la précision du modèle.
Les modèles open source, tels que google/flan-t5-xxl et google/flan-t5-xxl-fp16 (version au format à virgule flottante demi-précision (FP16) du modèle complet), sont disponibles via Amazon SageMaker JumpStart. Bien que la série de modèles google/flan-t5 soit un choix populaire pour créer des applications d'IA générative, leurs capacités pour NLQ sont limitées par rapport aux nouveaux modèles open source et commerciaux. Le google/flan-t5-xxl-fp16 de la démonstration est capable de répondre aux requêtes de base en langage naturel avec un apprentissage en contexte suffisant. Cependant, lors des tests, il ne parvenait souvent pas à renvoyer une réponse ou à fournir des réponses correctes, et cela provoquait fréquemment des délais d'attente des points de terminaison du modèle SageMaker en raison de l'épuisement des ressources face à des requêtes modérées à complexes.
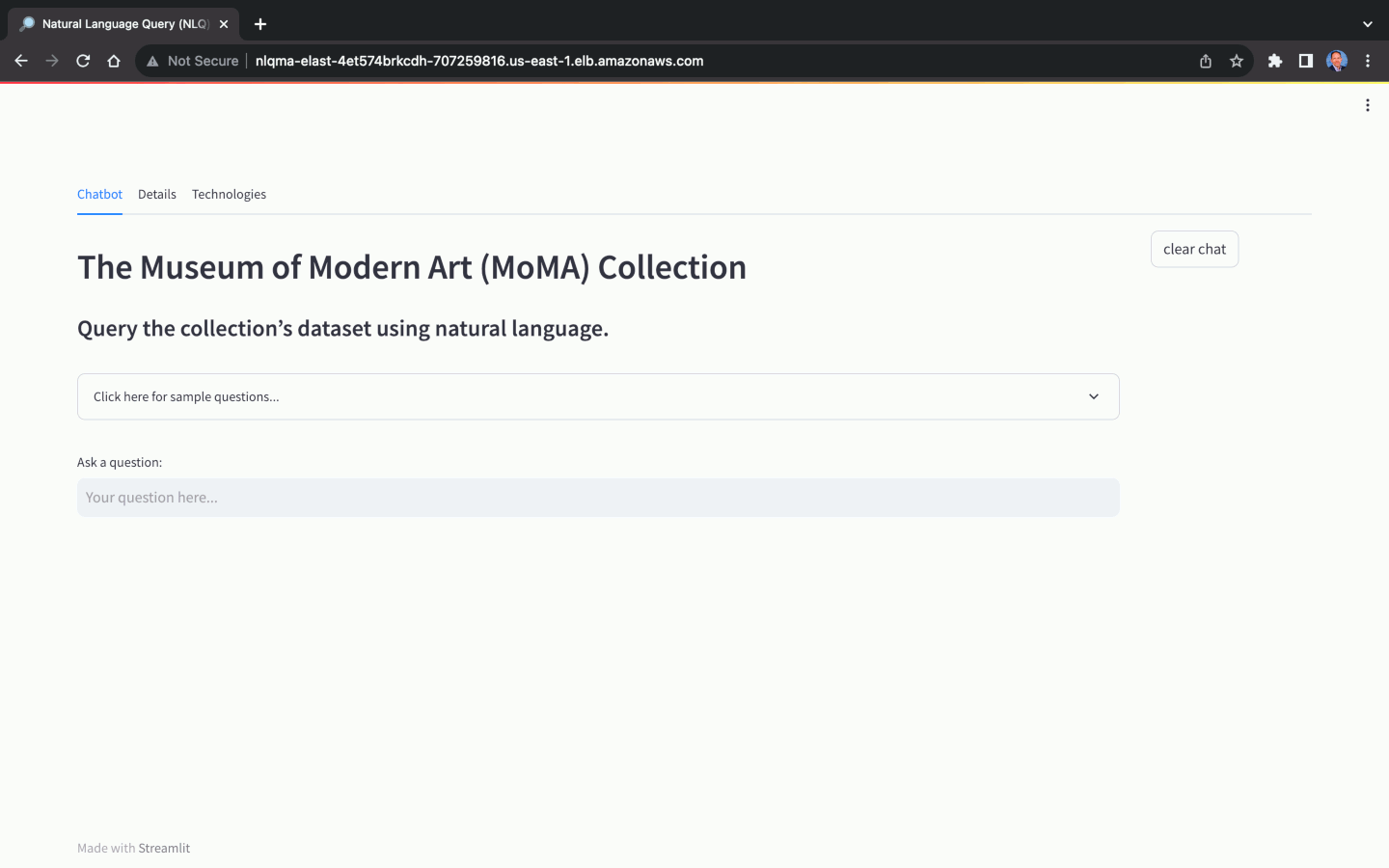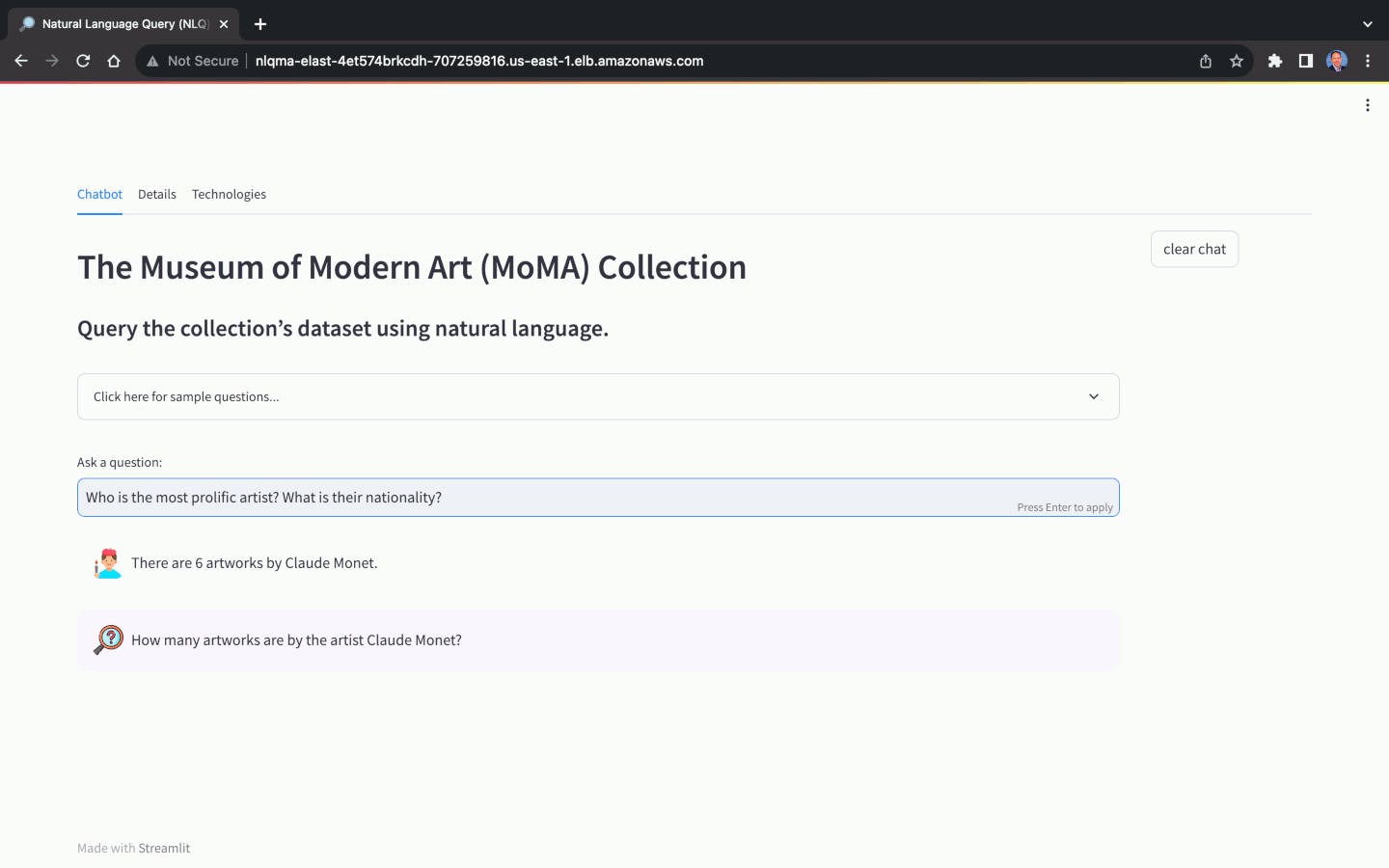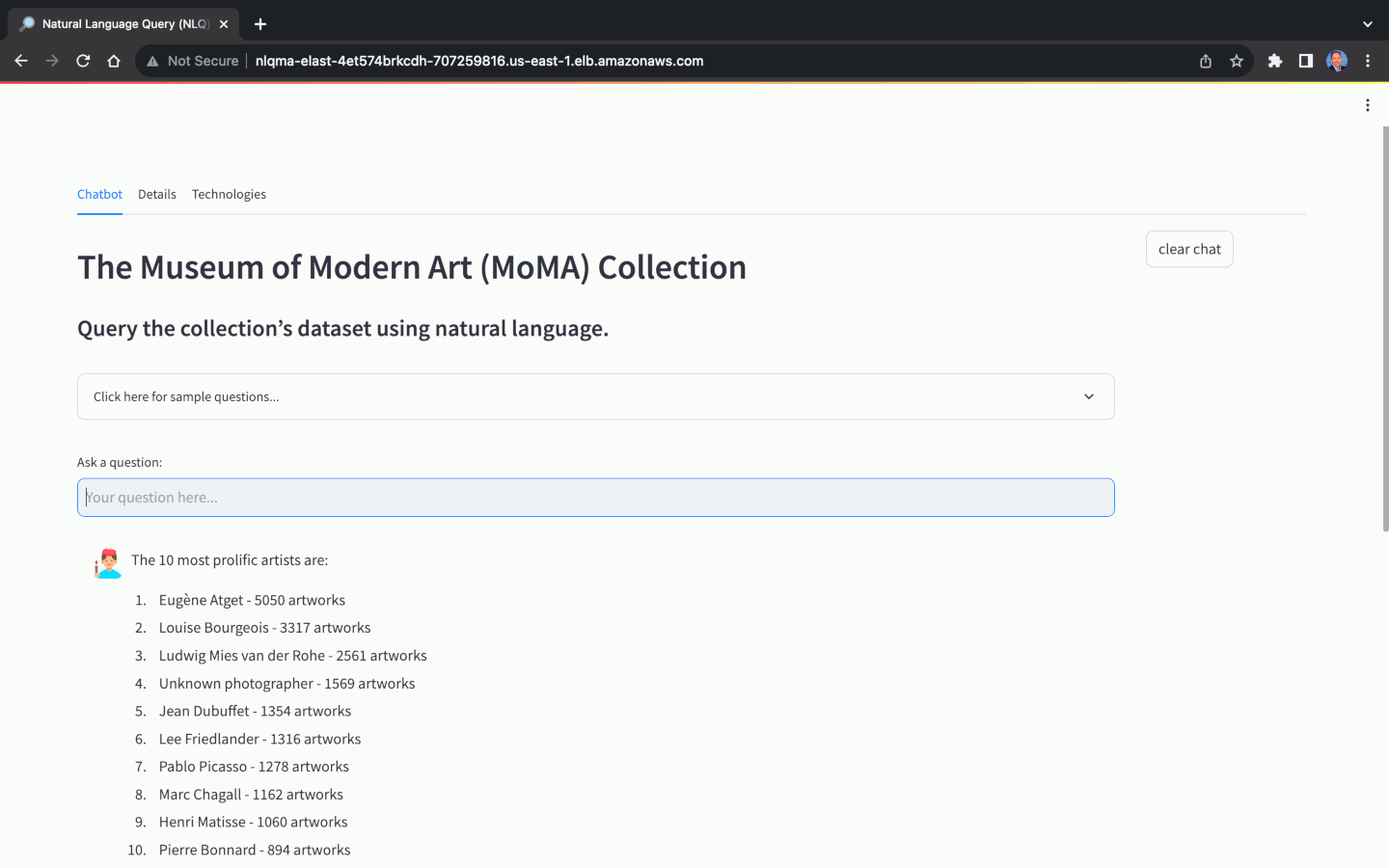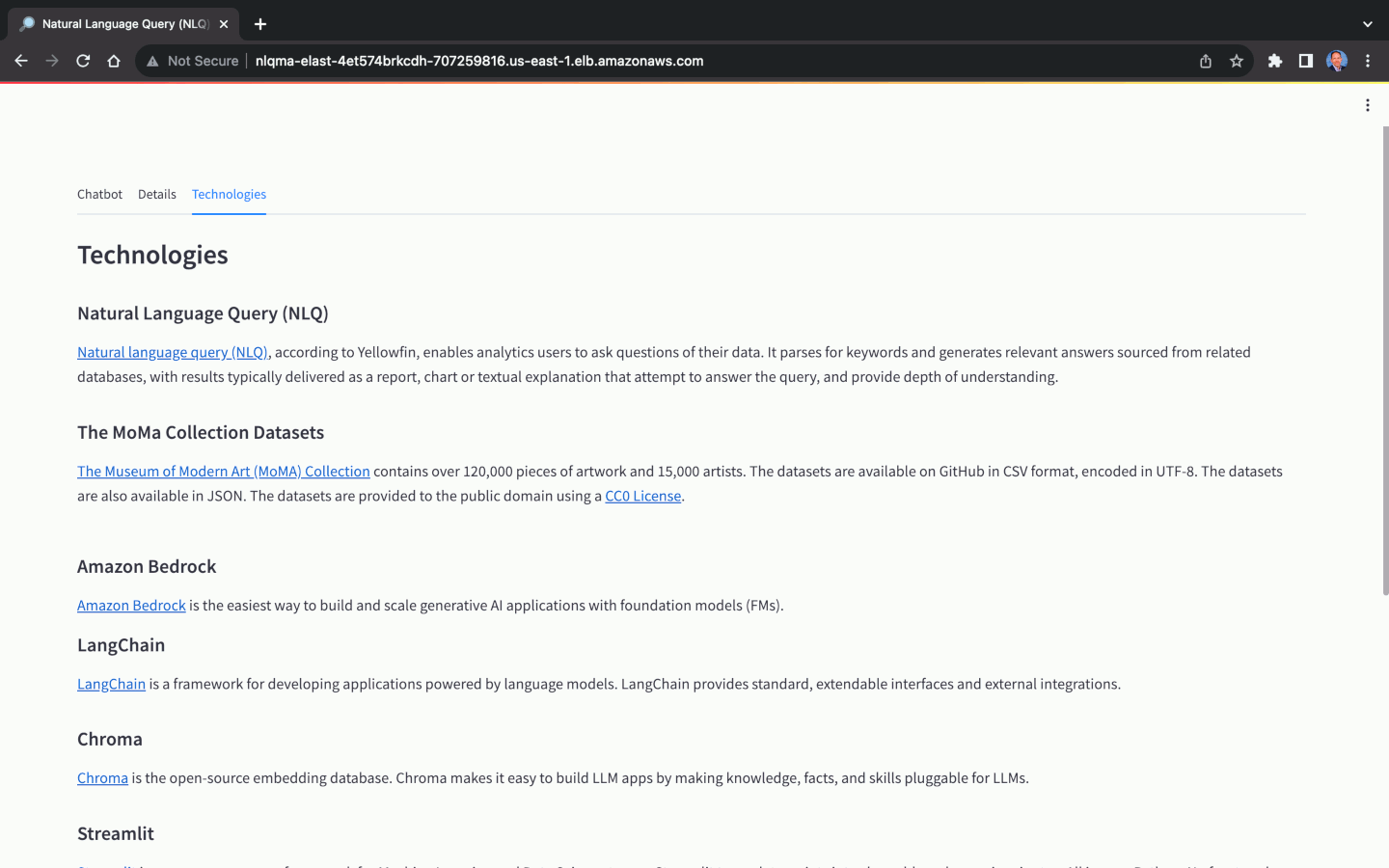
Cette solution utilise une copie optimisée pour NLQ de la base de données open source, The Museum of Modern Art (MoMA) Collection, disponible sur GitHub. La base de données du MoMA contient plus de 121 000 œuvres d'art et 15 000 artistes. Ce référentiel de projet contient des fichiers texte délimités par des barres qui peuvent être facilement importés dans l'instance de base de données Amazon RDS pour PostgreSQL.
À l’aide de l’ensemble de données du MoMA, nous pouvons poser des questions en langage naturel, avec différents niveaux de complexité :
Encore une fois, la capacité de l'application NLQ à renvoyer une réponse et à renvoyer une réponse précise dépend principalement du choix du modèle. Tous les modèles ne sont pas capables de NLQ, tandis que d'autres ne renvoient pas de réponses précises. L'optimisation des invites ci-dessus pour des modèles spécifiques peut contribuer à améliorer la précision.
ml.g5.24xlarge pour le google/flan-t5-xxl-fp16 modèle google/flan-t5-xxl-fp16 ). Reportez-vous à la documentation du modèle pour le choix des types d'instances.NlqMainStack CloudFormation. Veuillez noter que vous devrez avoir utilisé Amazon ECS au moins un dans votre compte, sinon le rôle lié au service AWSServiceRoleForECS n'existera pas encore et la pile échouera. Vérifiez le rôle lié au service AWSServiceRoleForECS avant de déployer la pile NlqMainStack . Ce rôle est créé automatiquement la première fois que vous créez un cluster ECS dans votre compte.nlq-genai:2.0.0-sm vers le nouveau référentiel Amazon ECR. Vous pouvez également créer et transmettre l'image Docker nlq-genai:2.0.0-bedrock ou nlq-genai:2.0.0-oai à utiliser avec l'option 2 : Amazon Bedrock ou l'option 3 : API OpenAI.nlqapp à la base de données MoMA.NlqSageMakerEndpointStack CloudFormation.NlqEcsSageMakerStack CloudFormation. Vous pouvez également déployer le modèle NlqEcsBedrockStack CloudFormation à utiliser avec l'option 2 : Amazon Bedrock ou le modèle NlqEcsOpenAIStack à utiliser avec l'option 3 : API OpenAI. Pour l'option 1 : Amazon SageMaker JumpStart, assurez-vous que vous disposez de l'instance EC2 requise pour l'inférence du point de terminaison Amazon SageMaker JumpStart ou demandez-la à l'aide des quotas de service dans la console de gestion AWS (par exemple, ml.g5.24xlarge pour le google/flan-t5-xxl-fp16 modèle google/flan-t5-xxl-fp16 ). Reportez-vous à la documentation du modèle pour le choix des types d'instances.
Assurez-vous de mettre à jour les valeurs secrètes ci-dessous avant de continuer. Cette étape créera des secrets pour les informations d'identification de l'application NLQ. L'accès des applications NLQ à la base de données est limité en lecture seule. Pour l'option 3 : API OpenAI, cette étape créera un secret pour stocker votre clé API OpenAI. Les informations d'identification de l'utilisateur principal pour l'instance Amazon RDS sont définies automatiquement et stockées dans AWS Secret Manager dans le cadre du déploiement du modèle NlqMainStack CloudFormation. Ces valeurs peuvent être trouvées dans AWS Secret Manager.
aws secretsmanager create-secret
--name /nlq/NLQAppUsername
--description " NLQ Application username for MoMA database. "
--secret-string " <your_nlqapp_username> "
aws secretsmanager create-secret
--name /nlq/NLQAppUserPassword
--description " NLQ Application password for MoMA database. "
--secret-string " <your_nlqapp_password> "
# Only for Option 2: OpenAI API/model
aws secretsmanager create-secret
--name /nlq/OpenAIAPIKey
--description " OpenAI API key. "
--secret-string " <your_openai_api_key "L'accès à l'ALB et au RDS sera limité en externe à votre adresse IP actuelle. Vous devrez mettre à jour si votre adresse IP change après le déploiement.
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqMainStack
--template-body file://NlqMainStack.yaml
--capabilities CAPABILITY_NAMED_IAM
--parameters ParameterKey= " MyIpAddress " ,ParameterValue= $( curl -s http://checkip.amazonaws.com/ ) /32Créez la ou les images Docker pour l'application NLQ, en fonction de votre choix d'options de modèle. Vous pouvez créer la ou les images Docker localement, dans un pipeline CI/CD, à l'aide de l'environnement SageMaker Notebook ou d'AWS Cloud9. Je préfère AWS Cloud9 pour développer et tester l'application et créer les images Docker.
cd docker/
# Located in the output from the NlqMlStack CloudFormation template
# e.g. 111222333444.dkr.ecr.us-east-1.amazonaws.com/nlq-genai
ECS_REPOSITORY= " <you_ecr_repository> "
aws ecr get-login-password --region us-east-1 |
docker login --username AWS --password-stdin $ECS_REPOSITORYOption 1 : Amazon SageMaker JumpStart
TAG= " 2.0.0-sm "
docker build -f Dockerfile_SageMaker -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAGOption 2 : substrat rocheux amazonien
TAG= " 2.0.0-bedrock "
docker build -f Dockerfile_Bedrock -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAGOption 3 : API OpenAI
TAG= " 2.0.0-oai "
docker build -f Dockerfile_OpenAI -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAG 5a. Connectez-vous à la base de données moma à l'aide de votre outil PostgreSQL préféré. Vous devrez activer temporairement Public access pour l'instance RDS en fonction de la manière dont vous vous connectez à la base de données.
5b. Créez les deux tables de collection MoMA dans la base de données moma .
CREATE TABLE public .artists
(
artist_id integer NOT NULL ,
full_name character varying ( 200 ),
nationality character varying ( 50 ),
gender character varying ( 25 ),
birth_year integer ,
death_year integer ,
CONSTRAINT artists_pk PRIMARY KEY (artist_id)
)
CREATE TABLE public .artworks
(
artwork_id integer NOT NULL ,
title character varying ( 500 ),
artist_id integer NOT NULL ,
date integer ,
medium character varying ( 250 ),
dimensions text ,
acquisition_date text ,
credit text ,
catalogue character varying ( 250 ),
department character varying ( 250 ),
classification character varying ( 250 ),
object_number text ,
diameter_cm text ,
circumference_cm text ,
height_cm text ,
length_cm text ,
width_cm text ,
depth_cm text ,
weight_kg text ,
durations integer ,
CONSTRAINT artworks_pk PRIMARY KEY (artwork_id)
) 5c. Décompressez et importez les deux fichiers de données dans la base de données moma en utilisant les fichiers texte du sous-répertoire /data . Les deux fichiers contiennent une ligne d'en-tête et délimités par des barres verticales (« | »).
# examples commands from pgAdmin4
--command " "\copy public.artists (artist_id, full_name, nationality, gender, birth_year, death_year) FROM 'moma_public_artists.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""
--command " "\copy public.artworks (artwork_id, title, artist_id, date, medium, dimensions, acquisition_date, credit, catalogue, department, classification, object_number, diameter_cm, circumference_cm, height_cm, length_cm, width_cm, depth_cm, weight_kg, durations) FROM 'moma_public_artworks.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""Créez le compte utilisateur de la base de données de l'application NLQ en lecture seule. Mettez à jour les valeurs du nom d'utilisateur et du mot de passe dans le script SQL, à trois endroits, avec les secrets que vous avez configurés à l'étape 2 ci-dessus.
CREATE ROLE < your_nlqapp_username > WITH
LOGIN
NOSUPERUSER
NOCREATEDB
NOCREATEROLE
INHERIT
NOREPLICATION
CONNECTION LIMIT - 1
PASSWORD ' <your_nlqapp_password> ' ;
GRANT
pg_read_all_data
TO
< your_nlqapp_username > ;Option 1 : Amazon SageMaker JumpStart
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqSageMakerEndpointStack
--template-body file://NlqSageMakerEndpointStack.yaml
--capabilities CAPABILITY_NAMED_IAMOption 1 : Amazon SageMaker JumpStart
aws cloudformation create-stack
--stack-name NlqEcsSageMakerStack
--template-body file://NlqEcsSageMakerStack.yaml
--capabilities CAPABILITY_NAMED_IAMOption 2 : substrat rocheux amazonien
aws cloudformation create-stack
--stack-name NlqEcsBedrockStack
--template-body file://NlqEcsBedrockStack.yaml
--capabilities CAPABILITY_NAMED_IAMOption 3 : API OpenAI
aws cloudformation create-stack
--stack-name NlqEcsOpenAIStack
--template-body file://NlqEcsOpenAIStack.yaml
--capabilities CAPABILITY_NAMED_IAM Vous pouvez remplacer le modèle JumpStart Foundation google/flan-t5-xxl-fp16 par défaut, déployé à l'aide du fichier modèle NlqSageMakerEndpointStack.yaml CloudFormation. Vous devrez d'abord modifier les paramètres du modèle dans le fichier NlqSageMakerEndpointStack.yaml et mettre à jour la pile CloudFormation déployée, NlqSageMakerEndpointStack . De plus, vous devrez apporter des ajustements à l'application NLQ, app_sagemaker.py , en modifiant la classe ContentHandler pour qu'elle corresponde à la charge utile de réponse du modèle choisi. Ensuite, reconstruisez l'image Docker Amazon ECR, en incrémentant la version, par exemple nlq-genai-2.0.1-sm , à l'aide du Dockerfile_SageMaker Dockerfile et transférez-la vers le référentiel Amazon ECR. Enfin, vous devrez mettre à jour la tâche et le service ECS déployés, qui font partie de la pile NlqEcsSageMakerStack CloudFormation.
Pour passer du modèle de base Amazon Titan Text G1 - Express ( amazon.titan-text-express-v1 ) par défaut de la solution, vous devez modifier et redéployer le fichier modèle NlqEcsBedrockStack.yaml CloudFormation. De plus, vous devrez modifier l'application NLQ, app_bedrock.py Ensuite, reconstruisez l'image Docker Amazon ECR à l'aide du Dockerfile_Bedrock Dockerfile et transférez l'image résultante, par exemple nlq-genai-2.0.1-bedrock , vers le référentiel Amazon ECR. . Enfin, vous devrez mettre à jour la tâche et le service ECS déployés, qui font partie de la pile NlqEcsBedrockStack CloudFormation.
Passer de l'API OpenAI par défaut de la solution à l'API d'un autre fournisseur de modèles tiers, tel que Cohere ou Anthropic, est tout aussi simple. Pour utiliser les modèles OpenAI, vous devrez d'abord créer un compte OpenAI et obtenir votre propre clé API personnelle. Ensuite, modifiez et reconstruisez l'image Docker Amazon ECR à l'aide du fichier Dockerfile_OpenAI et transférez l'image résultante, par exemple nlq-genai-2.0.1-oai , vers le référentiel Amazon ECR. Enfin, modifiez et redéployez le fichier modèle NlqEcsOpenAIStack.yaml CloudFormation.
Voir CONTRIBUTION pour plus d'informations.
Cette bibliothèque est sous licence MIT-0. Voir le fichier LICENCE.


