distrifuser
v0.0.1beta0
[29 juillet 2024] DistriFusion est pris en charge dans ColossalAI !
[4 avril 2024] DistriFusion est sélectionnée comme affiche phare du CVPR 2024 !
[29 février 2024] DistriFusion est accepté par CVPR 2024 ! Notre code est accessible au public !
 Nous présentons DistriFusion, un algorithme sans formation permettant d'exploiter plusieurs GPU afin d'accélérer l'inférence de modèle de diffusion sans sacrifier la qualité de l'image. Naïve Patch (Présentation (b)) souffre d'un problème de fragmentation en raison du manque d'interaction entre les correctifs. Les exemples présentés sont générés avec SDXL à l'aide d'un échantillonneur Euler en 50 étapes à une résolution de 1 280 × 1 920, et la latence est mesurée sur les GPU A100.
Nous présentons DistriFusion, un algorithme sans formation permettant d'exploiter plusieurs GPU afin d'accélérer l'inférence de modèle de diffusion sans sacrifier la qualité de l'image. Naïve Patch (Présentation (b)) souffre d'un problème de fragmentation en raison du manque d'interaction entre les correctifs. Les exemples présentés sont générés avec SDXL à l'aide d'un échantillonneur Euler en 50 étapes à une résolution de 1 280 × 1 920, et la latence est mesurée sur les GPU A100.
DistriFusion : inférence parallèle distribuée pour les modèles de diffusion haute résolution
Muyang Li*, Tianle Cai*, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li et Song Han
MIT, Princeton, Lepton AI et NVIDIA
Dans CVPR 2024.
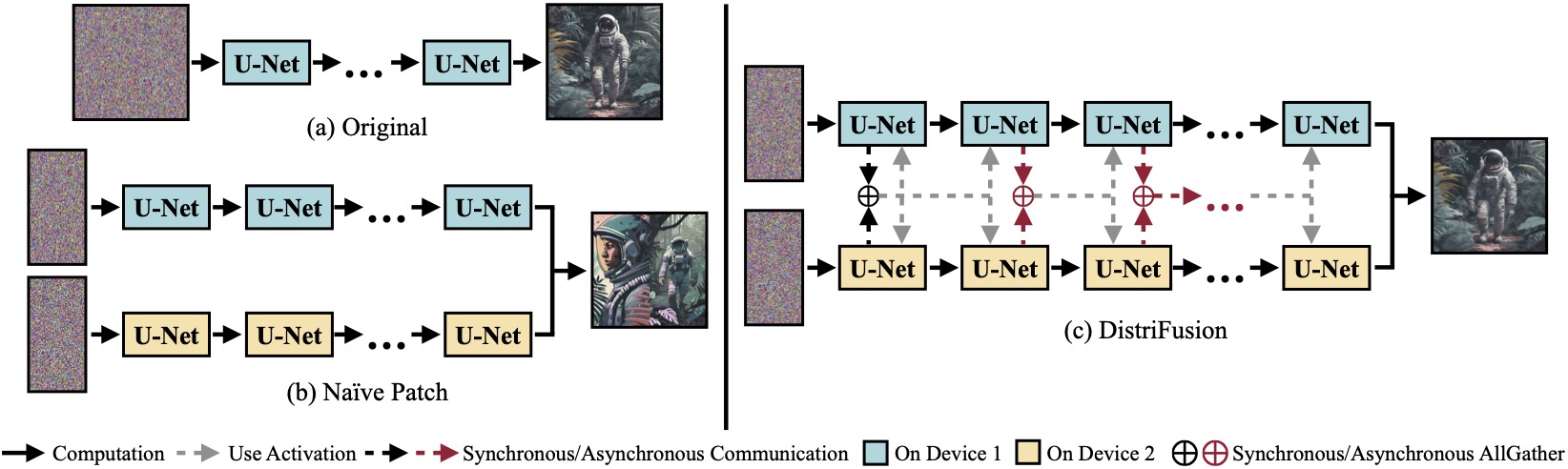 (a) Modèle de diffusion original fonctionnant sur un seul appareil. (b) La division naïve de l'image en 2 patchs sur 2 GPU présente une couture évidente à la limite en raison de l'absence d'interaction entre les patchs. (c) Notre DistriFusion utilise une communication synchrone pour l'interaction des correctifs dès la première étape. Après cela, nous réutilisons les activations de l'étape précédente via une communication asynchrone. De cette manière, la surcharge de communication peut être cachée dans le pipeline de calcul.
(a) Modèle de diffusion original fonctionnant sur un seul appareil. (b) La division naïve de l'image en 2 patchs sur 2 GPU présente une couture évidente à la limite en raison de l'absence d'interaction entre les patchs. (c) Notre DistriFusion utilise une communication synchrone pour l'interaction des correctifs dès la première étape. Après cela, nous réutilisons les activations de l'étape précédente via une communication asynchrone. De cette manière, la surcharge de communication peut être cachée dans le pipeline de calcul.
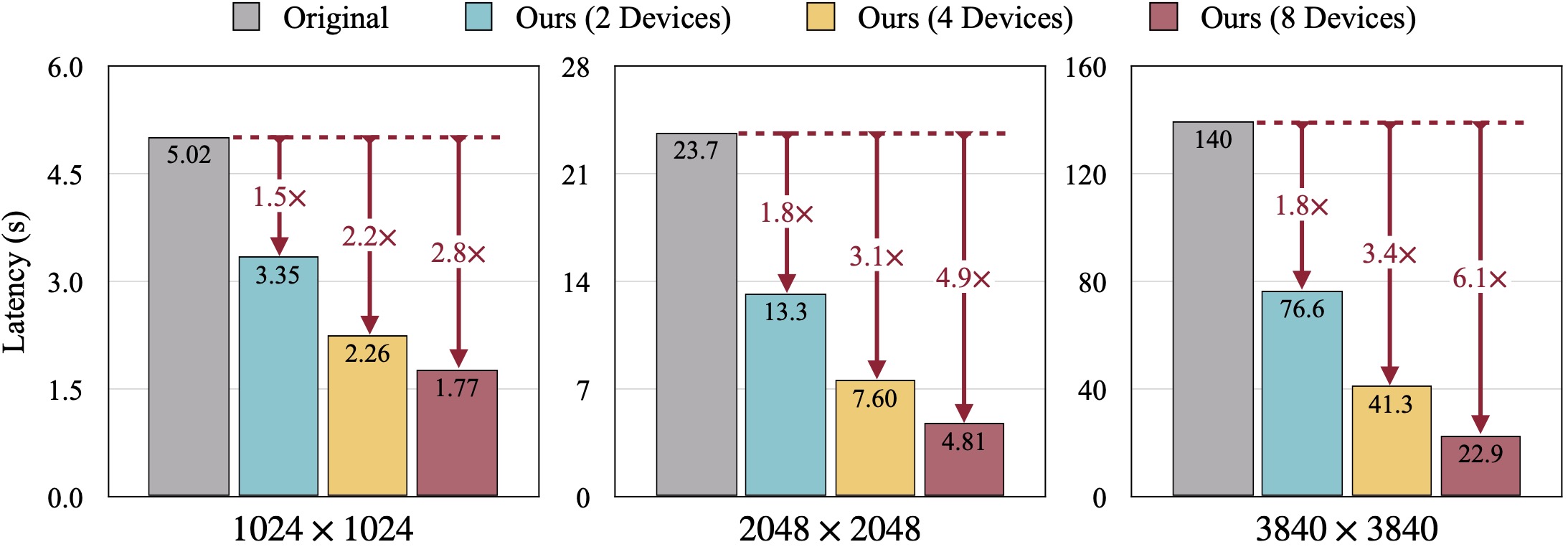
 Résultats qualitatifs du SDXL. Le FID est calculé par rapport aux images de vérité terrain. Notre DistriFusion permet de réduire la latence en fonction du nombre d'appareils utilisés tout en préservant la fidélité visuelle.
Résultats qualitatifs du SDXL. Le FID est calculé par rapport aux images de vérité terrain. Notre DistriFusion permet de réduire la latence en fonction du nombre d'appareils utilisés tout en préservant la fidélité visuelle.
Références :
Après avoir installé PyTorch, vous devriez pouvoir installer distrifuser avec PyPI
pip install distrifuserou via GitHub :
pip install git+https://github.com/mit-han-lab/distrifuser.gitou localement pour le développement
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e . Dans scripts/sdxl_example.py , nous fournissons un script minimal pour exécuter SDXL avec DistriFusion.
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" ) Plus précisément, notre distrifuser partage les mêmes API que les diffuseurs et peut être utilisé de la même manière. Il vous suffit de définir un DistriConfig et d'utiliser notre DistriSDXLPipeline encapsulé pour charger le modèle SDXL pré-entraîné. Ensuite, nous pouvons générer l'image comme le StableDiffusionXLPipeline dans les diffuseurs. La commande en cours d'exécution est
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py où $N_GPUS est le nombre de GPU que vous souhaitez utiliser.
Nous fournissons également un script minimal pour exécuter SD1.4/2 avec DistriFusion dans scripts/sd_example.py . L'utilisation est la même.
Nos résultats de référence utilisent PyTorch 2.2 et les diffuseurs 0.24.0. Tout d’abord, vous devrez peut-être installer quelques dépendances supplémentaires :
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid Vous pouvez utiliser scripts/generate_coco.py pour générer des images avec des légendes COCO. La commande est
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
où $N_GPUS est le nombre de GPU que vous souhaitez utiliser. Par défaut, les résultats générés seront stockés dans results/coco . Vous pouvez également le personnaliser avec --output_root . Quelques arguments supplémentaires que vous souhaiterez peut-être ajuster :
--num_inference_steps : Le nombre d'étapes d'inférence. Nous utilisons 50 par défaut.--guidance_scale : L'échelle de guidage sans classificateur. Nous utilisons 5 par défaut.--scheduler : L'échantillonneur de diffusion. Nous utilisons l'échantillonneur DDIM par défaut. Vous pouvez également utiliser euler pour l'échantillonneur Euler et dpm-solver pour le solveur DPM.--warmup_steps : Le nombre d'étapes d'échauffement supplémentaires (4 par défaut).--sync_mode : Différents modes de synchronisation GroupNorm. Par défaut, il utilise notre GroupNorm asynchrone corrigé.--parallelism : Le paradigme de parallélisme que vous utilisez. Par défaut, il s'agit du parallélisme des patchs. Vous pouvez utiliser tensor pour le parallélisme tensoriel et naive_patch pour le patch naïf. Après avoir généré toutes les images, vous pouvez utiliser notre script scripts/compute_metrics.py pour calculer le PSNR, le LPIPS et le FID. L'utilisation est
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1 où $IMAGE_ROOT0 et $IMAGE_ROOT1 sont les chemins d'accès aux dossiers d'images que vous essayez de comparer. Si IMAGE_ROOT0 est le dossier de vérité terrain, veuillez ajouter un indicateur --is_gt pour le redimensionnement. Nous fournissons également un script scripts/dump_coco.py pour vider les images de vérité terrain.
Vous pouvez utiliser scripts/run_sdxl.py pour comparer la latence de nos différentes méthodes. La commande est
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent où $N_GPUS est le nombre de GPU que vous souhaitez utiliser. Semblable à scripts/generate_coco.py , vous pouvez également modifier certains arguments :
--num_inference_steps : Le nombre d'étapes d'inférence. Nous utilisons 50 par défaut.--image_size : La taille de l'image générée. Par défaut, c'est 1024×1024.--no_split_batch : désactivez le fractionnement des lots pour un guidage sans classificateur.--warmup_steps : Le nombre d'étapes d'échauffement supplémentaires (4 par défaut).--sync_mode : Différents modes de synchronisation GroupNorm. Par défaut, il utilise notre GroupNorm asynchrone corrigé.--parallelism : Le paradigme de parallélisme que vous utilisez. Par défaut, il s'agit du parallélisme des patchs. Vous pouvez utiliser tensor pour le parallélisme tensoriel et naive_patch pour le patch naïf.--warmup_times / --test_times : Le nombre d'exécutions de préchauffage/test. Par défaut, ils sont respectivement 5 et 20. Si vous utilisez ce code pour votre recherche, veuillez citer notre article.
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}Notre code est développé sur la base de huggingface/diffusers et lmxyy/sige. Nous remercions torchprofile pour la mesure des MAC, clean-fid pour le calcul FID et Lightning-AI/torchmetrics pour PSNR et LPIPS.
Nous remercions Jun-Yan Zhu et Ligeng Zhu pour leurs discussions utiles et leurs précieux commentaires. Le projet est soutenu par le MIT-IBM Watson AI Lab, Amazon, le MIT Science Hub et la National Science Foundation.


