ffhq dataset
1.0.0

Flickr-Faces-HQ (FFHQ) est un ensemble de données d'images de haute qualité de visages humains, créé à l'origine comme référence pour les réseaux contradictoires génératifs (GAN) :
Une architecture génératrice basée sur le style pour les réseaux adverses génératifs
Tero Karras (NVIDIA), Samuli Laine (NVIDIA), Timo Aila (NVIDIA)
https://arxiv.org/abs/1812.04948
L'ensemble de données se compose de 70 000 images PNG de haute qualité à une résolution de 1 024 × 1 024 et contient des variations considérables en termes d'âge, d'origine ethnique et d'arrière-plan de l'image. Il couvre également bien les accessoires tels que les lunettes, les lunettes de soleil, les chapeaux, etc. Les images ont été explorées depuis Flickr, héritant ainsi de tous les biais de ce site Web, et automatiquement alignées et recadrées à l'aide de dlib. Seules les images sous licences permissives ont été collectées. Divers filtres automatiques ont été utilisés pour élaguer l'ensemble, et enfin Amazon Mechanical Turk a été utilisé pour supprimer les statues, peintures ou photos occasionnelles.
Veuillez noter que cet ensemble de données n'est pas destiné et ne doit pas être utilisé pour le développement ou l'amélioration des technologies de reconnaissance faciale. Pour toute demande commerciale, veuillez visiter notre site Web et soumettre le formulaire : NVIDIA Research Licensing
Les images individuelles ont été publiées sur Flickr par leurs auteurs respectifs sous licence Creative Commons BY 2.0, Creative Commons BY-NC 2.0, Public Domain Mark 1.0, Public Domain CC0 1.0 ou US Government Works. Toutes ces licences permettent une utilisation, une redistribution et une adaptation gratuites à des fins non commerciales . Cependant, certains d’entre eux nécessitent de mentionner de manière appropriée l’auteur original, ainsi que d’indiquer les modifications apportées aux images. La licence et l'auteur original de chaque image sont indiqués dans les métadonnées.
L'ensemble de données lui-même (y compris les métadonnées JSON, le script de téléchargement et la documentation) est mis à disposition sous licence Creative Commons BY-NC-SA 4.0 par NVIDIA Corporation. Vous pouvez l'utiliser, le redistribuer et l'adapter à des fins non commerciales , à condition que vous (a) accordiez le crédit approprié en citant notre article , (b) indiquiez toutes les modifications que vous avez apportées et (c) distribuiez toute œuvre dérivée. sous la même licence .
Toutes les données sont hébergées sur Google Drive :
| Chemin | Taille | Fichiers | Format | Description |
|---|---|---|---|---|
| ensemble de données ffhq | 2,56 To | 210 014 | Dossier principal | |
| ├ ffhq-dataset-v2.json | 255 Mo | 1 | JSON | Métadonnées comprenant des informations sur les droits d'auteur, des URL, etc. |
| ├images1024x1024 | 89,1 Go | 70 000 | PNG | Images alignées et recadrées à 1024×1024 |
| ├ vignettes128x128 | 1,95 Go | 70 000 | PNG | Miniatures à 128×128 |
| ├ images-dans-la-sauvage | 955 Go | 70 000 | PNG | Images originales de Flickr |
| ├ tfrecords | 273 Go | 9 | tfrecords | Données multi-résolution pour StyleGAN et StyleGAN2 |
| └ fermetures éclair | 1,28 To | 4 | FERMETURE ÉCLAIR | Contenu de chaque dossier sous forme d'archive ZIP. |
Statistiques de haut niveau :
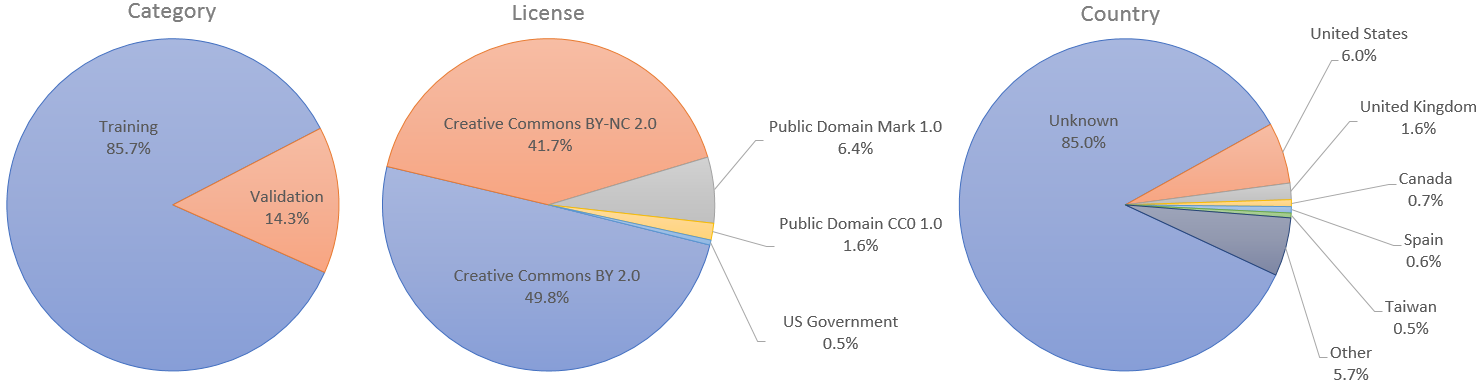
Pour les cas d'utilisation qui nécessitent des ensembles de formation et de validation distincts, nous avons désigné les 60 000 premières images à utiliser pour la formation et les 10 000 restantes pour la validation. Dans l'article StyleGAN, cependant, nous avons utilisé les 70 000 images pour la formation.
Nous nous sommes explicitement assurés qu'il n'y avait pas d'images en double dans l'ensemble de données lui-même. Veuillez toutefois noter que le dossier in-the-wild peut contenir plusieurs copies de la même image dans les cas où nous avons extrait plusieurs visages différents de la même image.
Vous pouvez soit récupérer les données directement depuis Google Drive, soit utiliser le script de téléchargement fourni. Le script rend les choses considérablement plus faciles en téléchargeant automatiquement tous les fichiers demandés, en vérifiant leurs sommes de contrôle, en réessayant chaque fichier plusieurs fois en cas d'erreur et en utilisant plusieurs connexions simultanées pour maximiser la bande passante.
> python download_ffhq.py -h
usage: download_ffhq.py [-h] [-j] [-s] [-i] [-t] [-w] [-r] [-a]
[--num_threads NUM] [--status_delay SEC]
[--timing_window LEN] [--chunk_size KB]
[--num_attempts NUM]
Download Flickr-Face-HQ (FFHQ) dataset to current working directory.
optional arguments:
-h, --help show this help message and exit
-j, --json download metadata as JSON (254 MB)
-s, --stats print statistics about the dataset
-i, --images download 1024x1024 images as PNG (89.1 GB)
-t, --thumbs download 128x128 thumbnails as PNG (1.95 GB)
-w, --wilds download in-the-wild images as PNG (955 GB)
-r, --tfrecords download multi-resolution TFRecords (273 GB)
-a, --align recreate 1024x1024 images from in-the-wild images
--num_threads NUM number of concurrent download threads (default: 32)
--status_delay SEC time between download status prints (default: 0.2)
--timing_window LEN samples for estimating download eta (default: 50)
--chunk_size KB chunk size for each download thread (default: 128)
--num_attempts NUM number of download attempts per file (default: 10)
--random-shift SHIFT standard deviation of random crop rectangle jitter
--retry-crops retry random shift if crop rectangle falls outside image (up to 1000
times)
--no-rotation keep the original orientation of images
--no-padding do not apply blur-padding outside and near the image borders
--source-dir DIR where to find already downloaded FFHQ source data
> python ..download_ffhq.py --json --images
Downloading JSON metadata...
100.00% done 2/2 files 0.25/0.25 GB 43.21 MB/s ETA: done
Parsing JSON metadata...
Downloading 70000 files...
| 100.00% done 70001/70001 files 89.19 GB/89.19 GB 59.87 MB/s ETA: done
Le script sert également d'implémentation de référence du schéma automatisé que nous avons utilisé pour aligner et recadrer les images. Une fois que vous avez téléchargé les images sauvages avec python download_ffhq.py --wilds , vous pouvez exécuter python download_ffhq.py --align pour reproduire des répliques exactes des images 1024×1024 alignées en utilisant les emplacements des repères faciaux inclus dans les métadonnées. .
Pour reproduire l'ensemble de données « FFHQ non aligné » tel qu'utilisé dans le document Alias-Free Generative Adversarial Networks, utilisez les options suivantes :
python download_ffhq.py
--source-dir <path/to/downloaded/ffhq>
--align --no-rotation --random-shift 0.2 --no-padding --retry-crops
Le fichier ffhq-dataset-v2.json contient les informations suivantes pour chaque image dans un format lisible par machine :
{
"0": { # Image index
"category": "training", # Training or validation
"metadata": { # Info about the original Flickr photo:
"photo_url": "https://www.flickr.com/photos/...", # - Flickr URL
"photo_title": "DSCF0899.JPG", # - File name
"author": "Jeremy Frumkin", # - Author
"country": "", # - Country where the photo was taken
"license": "Attribution-NonCommercial License", # - License name
"license_url": "https://creativecommons.org/...", # - License detail URL
"date_uploaded": "2007-08-16", # - Date when the photo was uploaded to Flickr
"date_crawled": "2018-10-10" # - Date when the photo was crawled from Flickr
},
"image": { # Info about the aligned 1024x1024 image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "images1024x1024/00000/00000.png", # - Google Drive path
"file_size": 1488194, # - Size of the PNG file in bytes
"file_md5": "ddeaeea6ce59569643715759d537fd1b", # - MD5 checksum of the PNG file
"pixel_size": [1024, 1024], # - Image dimensions
"pixel_md5": "47238b44dfb87644460cbdcc4607e289", # - MD5 checksum of the raw pixel data
"face_landmarks": [...] # - 68 face landmarks reported by dlib
},
"thumbnail": { # Info about the 128x128 thumbnail:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "thumbnails128x128/00000/00000.png", # - Google Drive path
"file_size": 29050, # - Size of the PNG file in bytes
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1", # - MD5 checksum of the PNG file
"pixel_size": [128, 128], # - Image dimensions
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161" # - MD5 checksum of the raw pixel data
},
"in_the_wild": { # Info about the in-the-wild image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "in-the-wild-images/00000/00000.png", # - Google Drive path
"file_size": 3991569, # - Size of the PNG file in bytes
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4", # - MD5 checksum of the PNG file
"pixel_size": [2016, 1512], # - Image dimensions
"pixel_md5": "86b3470c42e33235d76b979161fb2327", # - MD5 checksum of the raw pixel data
"face_rect": [667, 410, 1438, 1181], # - Axis-aligned rectangle of the face region
"face_landmarks": [...], # - 68 face landmarks reported by dlib
"face_quad": [...] # - Aligned quad of the face region
}
},
...
}
Nous remercions Jaakko Lehtinen, David Luebke et Tuomas Kynkäänniemi pour leurs discussions approfondies et leurs commentaires utiles ; Janne Hellsten, Tero Kuosmanen et Pekka Jänis pour l'infrastructure de calcul et l'aide à la publication du code.
Nous remercions également Vahid Kazemi et Josephine Sullivan pour leur travail sur la détection et l'alignement automatiques des visages qui nous ont permis de collecter les données en premier lieu :
Alignement de visage en une milliseconde avec un ensemble d'arbres de régression
Vahid Kazemi, Joséphine Sullivan
Proc. CVPR 2014
https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Kazemi_One_Millisecond_Face_2014_CVPR_paper.pdf
Lors de la collecte des données, nous avons pris soin de n’inclure que des photos qui – à notre connaissance – étaient destinées à être utilisées et redistribuées gratuitement par leurs auteurs respectifs. Cela dit, nous nous engageons à protéger la vie privée des personnes qui ne souhaitent pas que leurs photos soient incluses.
Pour savoir si votre photo est incluse dans l'ensemble de données Flickr-Faces-HQ, veuillez cliquer sur ce lien pour rechercher l'ensemble de données avec votre nom d'utilisateur Flickr.
Pour supprimer votre photo de l'ensemble de données Flickr-Faces-HQ :
no_cv pour indiquer que vous ne souhaitez pas qu'elle soit utilisée pour la recherche en vision par ordinateur.None (Tous droits réservés) ou toute licence Creative Commons avec NoDerivs pour indiquer que vous ne souhaitez pas qu'elle soit redistribuée.

