INTR
1.0.0
Ce référentiel est l'implémentation officielle d'INTR : un transformateur simple interprétable pour la classification et l'analyse d'images à grain fin. Il comprend actuellement du code et des modèles pour l'interprétation de données à granularité fine. Nous fournirons un lien vers les prochains actes de l'ICLR 2024 pour cet article lorsqu'il sera disponible en ligne.
INTR est une nouvelle utilisation de Transformers pour rendre la classification d'images interprétable. Dans INTR, nous étudions une approche proactive de classification, demandant à chaque classe de se chercher elle-même dans une image. Nous apprenons des requêtes spécifiques à une classe (une pour chaque classe) en entrée du décodeur, leur permettant de rechercher leur présence dans une image via une attention croisée. Nous montrons que INTR encourage intrinsèquement chaque classe à y assister distinctement ; les poids d'attention croisée fournissent ainsi une interprétation significative de la prédiction du modèle. Il est intéressant de noter que, grâce à une attention croisée multi-têtes, INTR pourrait apprendre à localiser différents attributs d'une classe, ce qui la rendrait particulièrement adaptée à la classification et à l'analyse fine.
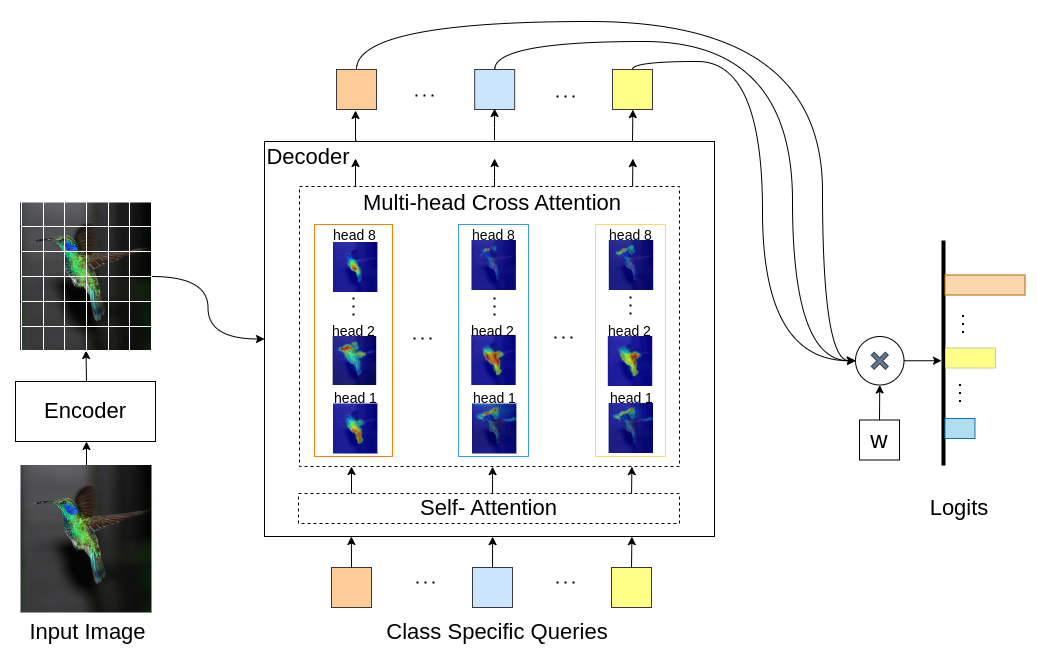
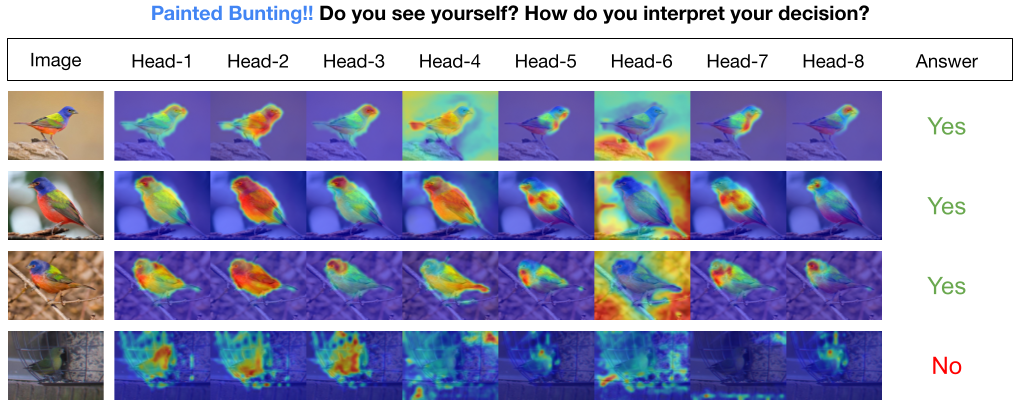
Dans le modèle INTR, chaque requête dans le décodeur est responsable de la prédiction d'une classe. Ainsi, une requête s’examine elle-même pour trouver des fonctionnalités spécifiques à une classe à partir de la carte des fonctionnalités. Tout d'abord, nous visualisons la carte des caractéristiques, c'est-à-dire la matrice de valeurs de l'architecture du transformateur pour voir les parties importantes de l'objet dans l'image. Pour trouver les caractéristiques spécifiques auxquelles le modèle prête attention dans la matrice de valeurs, nous montrons la carte thermique de l'attention du modèle. Pour éviter les interférences externes dans la classification, nous utilisons un vecteur de poids partagé pour la classification, de sorte que le poids d'attention explique la prédiction du modèle.
INTR sur le backbone DETR-R50, performances de classification et modèles affinés sur différents ensembles de données.
| Ensemble de données | acc@1 | acc@5 | Modèle |
|---|---|---|---|
| CUBE | 71,8 | 89,3 | téléchargement du point de contrôle |
| Oiseau | 97,4 | 99,2 | téléchargement du point de contrôle |
| Papillon | 95,0 | 98,3 | téléchargement du point de contrôle |
Créer un environnement Python (facultatif)
conda create -n intr python=3.8 -y
conda activate intrCloner le référentiel
git clone https://github.com/dipanjyoti/INTR.git
cd INTRInstaller les dépendances Python
pip install -r requirements.txtSuivez le format ci-dessous pour les données.
datasets
├── dataset_name
│ ├── train
│ │ ├── class1
│ │ │ ├── img1.jpeg
│ │ │ ├── img2.jpeg
│ │ │ └── ...
│ │ ├── class2
│ │ │ ├── img3.jpeg
│ │ │ └── ...
│ │ └── ...
│ └── val
│ ├── class1
│ │ ├── img4.jpeg
│ │ ├── img5.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img6.jpeg
│ │ └── ...
│ └── ...
Pour évaluer les performances d'INTR sur l'ensemble de données CUB , sur des paramètres multi-GPU (par exemple, 4 GPU), exécutez la commande ci-dessous. Les points de contrôle INTR sont disponibles sur Affiner le modèle et les résultats.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > Pour générer des représentations visuelles des interprétations de l'INTR, exécutez la commande fournie ci-dessous. Cette commande présentera l'interprétation pour une classe spécifique avec l'index <class_number>. Par défaut, il affichera les interprétations de toutes les têtes d’attention. Pour vous concentrer également sur les interprétations associées aux principales requêtes étiquetées top_q, définissez le paramètre sim_query_heads sur 1. Utilisez une taille de lot de 1 pour la visualisation.
python -m tools.visualization --eval --resume < path/to/intr_checkpoint_cub_detr_r50.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --class_index < class_number >Prédiction et visualisation d'une image unique au moment de l'inférence : nous avons également fourni un bloc-notes Jupyter, demo.ipynb, conçu pour la prédiction et la visualisation d'une image unique pendant le processus d'inférence. Veuillez noter que la démo se concentre sur l'ensemble de données CUB.
Pour préparer INTR à la formation, utilisez le modèle pré-entraîné DETR-R50. Pour vous entraîner pour un ensemble de données particulier, modifiez « --num_queries » en le définissant sur le nombre de classes dans l'ensemble de données. Dans l'architecture INTR, chaque requête du décodeur se voit confier la tâche de capturer des fonctionnalités spécifiques à la classe, ce qui signifie que chaque requête peut être adaptée tout au long du processus d'apprentissage. Par conséquent, le nombre total de paramètres du modèle augmentera proportionnellement au nombre de classes dans l’ensemble de données. Pour entraîner INTR sur un système multi-GPU (par exemple, 4 GPU), exécutez la commande ci-dessous.
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port 12345 --use_env main.py --finetune < path/to/detr-r50-e632da11.pth > --dataset_path < path/to/datasets > --dataset_name < dataset_name > --num_queries < num_of_classes > Notre modèle est inspiré de la méthode DEtection TRansformer (DETR).
Nous remercions les auteurs de DETR pour leur excellent travail.
Si vous trouvez notre travail utile pour votre recherche, pensez à citer l'entrée BibTeX.
@inproceedings{paul2024simple,
title={A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis},
author={Paul, Dipanjyoti and Chowdhury, Arpita and Xiong, Xinqi and Chang, Feng-Ju and Carlyn, David and Stevens, Samuel and Provost, Kaiya and Karpatne, Anuj and Carstens, Bryan and Rubenstein, Daniel and Stewart, Charles and Berger-Wolf, Tanya and Su, Yu and Chao, Wei-Lun},
booktitle={International Conference on Learning Representations},
year={2024}
}

