Machine Learning Guide
1.0.0
Remarque : Vous pouvez facilement convertir ce fichier markdown en PDF dans VSCode à l'aide de cette extension pratique Markdown PDF.

Cadres d’apprentissage automatique/d’apprentissage profond.
Ressources d'apprentissage pour le ML
Frameworks, bibliothèques et outils ML
Algorithmes
Développement PyTorch
Développement TensorFlow
Développement de base de ML
Développement de l'apprentissage profond
Développement de l’apprentissage par renforcement
Développement de la vision par ordinateur
Développement du traitement du langage naturel (NLP)
Bioinformatique
Développement CUDA
Développement MATLAB
Développement C/C++
Développement Java
Développement Python
Développement Scala
Développement R
Développement de Julia
Retour au sommet
L'apprentissage automatique est une branche de l'intelligence artificielle (IA) axée sur la création d'applications à l'aide d'algorithmes qui apprennent des modèles de données et améliorent leur précision au fil du temps sans avoir besoin d'être programmés.

Retour au sommet
Meilleures pratiques de traitement du langage naturel (NLP) par Microsoft
Le livre de recettes sur la conduite autonome de Microsoft
Azure Machine Learning – ML en tant que service | Microsoft Azure
Comment exécuter Jupyter Notebooks dans votre espace de travail Azure Machine Learning
Apprentissage automatique et intelligence artificielle | Services Web Amazon
Planification de blocs-notes Jupyter sur des instances éphémères Amazon SageMaker
IA et apprentissage automatique | Google Cloud
Utiliser des notebooks Jupyter avec Apache Spark sur Google Cloud
Apprentissage automatique | Développeur Apple
Intelligence artificielle et pilote automatique | Tesla
Outils méta-IA | Facebook
Tutoriels PyTorch
Tutoriels TensorFlow
Laboratoire Jupyter
Diffusion stable avec Core ML sur Apple Silicon
Retour au sommet
Apprentissage automatique par l'Université de Stanford par Andrew Ng | Coursera
Formation et certification AWS pour les cours d'apprentissage automatique (ML)
Programme de bourses d'apprentissage automatique pour Microsoft Azure | Udacité
Certifié Microsoft : Azure Data Scientist Associate
Certifié Microsoft : Associé ingénieur Azure AI
Formation et déploiement Azure Machine Learning
Apprentissage Machine learning et intelligence artificielle grâce à Google Cloud Training
Cours intensif d'apprentissage automatique pour Google Cloud
Cours d'apprentissage automatique en ligne | Udemy
Cours d'apprentissage automatique en ligne | Coursera
Apprenez l'apprentissage automatique avec des cours et des classes en ligne | edX
Retour au sommet
Introduction à l'apprentissage automatique (PDF)
Intelligence artificielle : une approche moderne par Stuart J. Russel et Peter Norvig
Apprentissage profond par Ian Goodfellow, Yoshoua Bengio et Aaron Courville
Le livre d'apprentissage automatique de cent pages par Andriy Burkov
Apprentissage automatique par Tom M. Mitchell
Programmation de l'intelligence collective : création d'applications Web intelligentes 2.0 par Toby Segaran
Apprentissage automatique : une perspective algorithmique, deuxième édition
Reconnaissance de formes et apprentissage automatique par Christopher M. Bishop
Traitement du langage naturel avec Python par Steven Bird, Ewan Klein et Edward Loper
Python Machine Learning : une approche technique de l'apprentissage automatique pour les débutants par Leonard Eddison
Raisonnement bayésien et apprentissage automatique par David Barber
Apprentissage automatique pour les débutants absolus : une introduction en anglais simple par Oliver Theobald
L'apprentissage automatique en action par Ben Wilson
Apprentissage automatique pratique avec Scikit-Learn, Keras et TensorFlow : concepts, outils et techniques pour créer des systèmes intelligents par Aurélien Géron
Introduction à l'apprentissage automatique avec Python : un guide destiné aux scientifiques des données par Andreas C. Müller et Sarah Guido
Apprentissage automatique pour les pirates : études de cas et algorithmes pour vous aider à démarrer par Drew Conway et John Myles White
Les éléments de l'apprentissage statistique : exploration de données, inférence et prédiction par Trevor Hastie, Robert Tibshirani et Jerome Friedman
Modèles d'apprentissage automatique distribués - Livre (lecture gratuite en ligne) + Code
Apprentissage automatique du monde réel [Chapitres gratuits]
Une introduction à l'apprentissage statistique - Book + R Code
Éléments d'apprentissage statistique - Livre
Pensez Bayes - Livre + Code Python
Exploration d'ensembles de données massifs
Une première rencontre avec l'apprentissage automatique
Introduction à l'apprentissage automatique - Alex Smola et SVN Vishwanathan
Une théorie probabiliste de la reconnaissance de formes
Introduction à la recherche d'informations
Prévision : principes et pratique
Introduction à l'apprentissage automatique - Amnon Shashua
Apprentissage par renforcement
Apprentissage automatique
Une quête pour l'IA
Programmation R pour la science des données
Exploration de données - Outils et techniques pratiques d'apprentissage automatique
Apprentissage automatique avec TensorFlow
Systèmes d'apprentissage automatique
Fondements de l'apprentissage automatique - Mehryar Mohri, Afshin Rostamizadeh et Ameet Talwalkar
Recherche basée sur l'IA - Trey Grainger, Doug Turnbull, Max Irwin -
Méthodes d'ensemble pour l'apprentissage automatique - Gautam Kunapuli
L'ingénierie de l'apprentissage automatique en action - Ben Wilson
Apprentissage automatique préservant la confidentialité - J. Morris Chang, Di Zhuang, G. Dumindu Samaraweera
Apprentissage automatique automatisé en action - Qingquan Song, Haifeng Jin et Xia Hu
Modèles d'apprentissage automatique distribués - Yuan Tang
Gestion de projets de Machine Learning : de la conception au déploiement - Simon Thompson
Apprentissage automatique causal - Robert Ness
L'optimisation bayésienne en action - Quan Nguyen
Algorithmes d'apprentissage automatique en profondeur) - Vadim Smolyakov
Algorithmes d'optimisation - Alaa Khamis
Le Boosting de Dégradé Pratique par Guillaume Saupin
Retour au sommet
Retour au sommet
TensorFlow est une plateforme open source de bout en bout pour l'apprentissage automatique. Il dispose d'un écosystème complet et flexible d'outils, de bibliothèques et de ressources communautaires qui permettent aux chercheurs de pousser l'état de l'art en matière de ML et aux développeurs de créer et de déployer facilement des applications basées sur le ML.
Keras est une API de réseaux neuronaux de haut niveau, écrite en Python et capable de s'exécuter sur TensorFlow, CNTK ou Theano. Elle a été développée dans le but de permettre une expérimentation rapide. Il est capable de fonctionner sur TensorFlow, Microsoft Cognitive Toolkit, R, Theano ou PlaidML.
PyTorch est une bibliothèque d'apprentissage en profondeur sur des données d'entrée irrégulières telles que des graphiques, des nuages de points et des variétés. Principalement développé par le laboratoire de recherche sur l'IA de Facebook.
Amazon SageMaker est un service entièrement géré qui offre à chaque développeur et data scientist la possibilité de créer, former et déployer rapidement des modèles d'apprentissage automatique (ML). SageMaker supprime le gros du travail de chaque étape du processus d'apprentissage automatique pour faciliter le développement de modèles de haute qualité.
Azure Databricks est un service d'analyse Big Data rapide et collaboratif basé sur Apache Spark, conçu pour la science et l'ingénierie des données. Azure Databricks configure votre environnement Apache Spark en quelques minutes, évolue automatiquement et collabore sur des projets partagés dans un espace de travail interactif. Azure Databricks prend en charge Python, Scala, R, Java et SQL, ainsi que les frameworks et bibliothèques de science des données, notamment TensorFlow, PyTorch et scikit-learn.
Microsoft Cognitive Toolkit (CNTK) est une boîte à outils open source pour l'apprentissage profond distribué de qualité commerciale. Il décrit les réseaux de neurones comme une série d'étapes de calcul via un graphe orienté. CNTK permet à l'utilisateur de réaliser et de combiner facilement des types de modèles populaires tels que les DNN à action directe, les réseaux de neurones convolutifs (CNN) et les réseaux de neurones récurrents (RNN/LSTM). CNTK implémente l'apprentissage par descente de gradient stochastique (SGD, rétropropagation des erreurs) avec différenciation et parallélisation automatiques sur plusieurs GPU et serveurs.
Apple CoreML est un framework qui permet d'intégrer des modèles d'apprentissage automatique dans votre application. Core ML fournit une représentation unifiée pour tous les modèles. Votre application utilise les API Core ML et les données utilisateur pour effectuer des prédictions et pour entraîner ou affiner des modèles, le tout sur l'appareil de l'utilisateur. Un modèle est le résultat de l’application d’un algorithme d’apprentissage automatique à un ensemble de données d’entraînement. Vous utilisez un modèle pour effectuer des prédictions basées sur de nouvelles données d'entrée.
Apache OpenNLP est une bibliothèque open source pour une boîte à outils basée sur l'apprentissage automatique utilisée dans le traitement du texte en langage naturel. Il dispose d'une API pour des cas d'utilisation tels que la reconnaissance d'entités nommées, la détection de phrases, le marquage POS (Part-Of-Speech), l'extraction de fonctionnalités de tokenisation, le découpage, l'analyse et la résolution de coréférence.
Apache Airflow est une plateforme de gestion de flux de travail open source créée par la communauté pour créer, planifier et surveiller des flux de travail par programmation. Installer. Principes. Évolutif. Airflow a une architecture modulaire et utilise une file d'attente de messages pour orchestrer un nombre arbitraire de travailleurs. Airflow est prêt à évoluer à l’infini.
Open Neural Network Exchange (ONNX) est un écosystème ouvert qui permet aux développeurs d'IA de choisir les bons outils à mesure que leur projet évolue. ONNX fournit un format open source pour les modèles d'IA, à la fois d'apprentissage en profondeur et de ML traditionnel. Il définit un modèle de graphe de calcul extensible, ainsi que des définitions d'opérateurs intégrés et de types de données standard.
Apache MXNet est un framework d'apprentissage en profondeur conçu à la fois pour l'efficacité et la flexibilité. Il vous permet de mélanger la programmation symbolique et impérative pour maximiser l’efficacité et la productivité. À la base, MXNet contient un planificateur de dépendances dynamique qui parallélise automatiquement les opérations symboliques et impératives à la volée. Une couche d'optimisation graphique en plus rend l'exécution symbolique rapide et efficace en mémoire. MXNet est portable et léger, s'adaptant efficacement à plusieurs GPU et plusieurs machines. Prise en charge de Python, R, Julia, Scala, Go, Javascript et plus encore.
AutoGluon est une boîte à outils pour le Deep Learning qui automatise les tâches d'apprentissage automatique vous permettant d'obtenir facilement de fortes performances prédictives dans vos applications. Avec seulement quelques lignes de code, vous pouvez former et déployer des modèles d'apprentissage profond de haute précision sur des données tabulaires, images et texte.
Anaconda est une plateforme de science des données très populaire pour l'apprentissage automatique et l'apprentissage profond qui permet aux utilisateurs de développer des modèles, de les former et de les déployer.
PlaidML est un compilateur tensoriel avancé et portable permettant l'apprentissage en profondeur sur les ordinateurs portables, les appareils intégrés ou d'autres appareils où le matériel informatique disponible n'est pas bien pris en charge ou où la pile logicielle disponible contient des restrictions de licence désagréables.
OpenCV est une bibliothèque hautement optimisée axée sur les applications de vision par ordinateur en temps réel. Les interfaces C++, Python et Java prennent en charge Linux, MacOS, Windows, iOS et Android.
Scikit-Learn est un module Python pour l'apprentissage automatique construit sur SciPy, NumPy et matplotlib, facilitant l'application d'implémentations robustes et simples de nombreux algorithmes d'apprentissage automatique populaires.
Weka est un logiciel d'apprentissage automatique open source accessible via une interface utilisateur graphique, des applications de terminal standard ou une API Java. Il est largement utilisé pour l'enseignement, la recherche et les applications industrielles, contient une multitude d'outils intégrés pour les tâches standard d'apprentissage automatique et donne en outre un accès transparent à des boîtes à outils bien connues telles que scikit-learn, R et Deeplearning4j.
Caffe est un framework d'apprentissage en profondeur conçu dans un souci d'expression, de rapidité et de modularité. Il est développé par Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) et des contributeurs de la communauté.
Theano est une bibliothèque Python qui vous permet de définir, d'optimiser et d'évaluer efficacement des expressions mathématiques impliquant des tableaux multidimensionnels, y compris une intégration étroite avec NumPy.
nGraph est une bibliothèque C++ open source, un compilateur et un runtime pour le Deep Learning. Le compilateur nGraph vise à accélérer le développement de charges de travail d'IA à l'aide de n'importe quel cadre d'apprentissage profond et à se déployer sur une variété de cibles matérielles. Il offre liberté, performances et facilité d'utilisation aux développeurs d'IA.
NVIDIA cuDNN est une bibliothèque de primitives accélérée par GPU pour les réseaux neuronaux profonds. cuDNN fournit des implémentations hautement optimisées pour les routines standard telles que les couches de convolution avant et arrière, de regroupement, de normalisation et d'activation. cuDNN accélère les frameworks d'apprentissage en profondeur largement utilisés, notamment Caffe2, Chainer, Keras, MATLAB, MxNet, PyTorch et TensorFlow.
Huginn est un système auto-hébergé pour les agents de création qui effectuent des tâches automatisées pour vous en ligne. Il peut lire le Web, surveiller les événements et prendre des mesures en votre nom. Les agents de Huginn créent et consomment des événements, les propageant le long d'un graphique orienté. Considérez-le comme une version piratable d'IFTTT ou de Zapier sur votre propre serveur.
Netron est un visualiseur de modèles de réseaux neuronaux, d'apprentissage profond et d'apprentissage automatique. Il prend en charge ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 et UFF.
Dopamine est un cadre de recherche pour le prototypage rapide d'algorithmes d'apprentissage par renforcement.
DALI est une bibliothèque accélérée par GPU contenant des blocs de construction hautement optimisés et un moteur d'exécution pour le traitement des données afin d'accélérer les applications de formation et d'inférence de deep learning.
MindSpore Lite est un nouveau cadre de formation/inférence d'apprentissage profond open source qui pourrait être utilisé pour des scénarios mobiles, Edge et Cloud.
Darknet est un framework de réseau neuronal open source écrit en C et CUDA. Il est rapide, facile à installer et prend en charge le calcul CPU et GPU.
PaddlePaddle est une plateforme d'apprentissage en profondeur facile à utiliser, efficace, flexible et évolutive, développée à l'origine par des scientifiques et des ingénieurs de Baidu dans le but d'appliquer l'apprentissage en profondeur à de nombreux produits de Baidu.
GoogleNotebookLM est un outil d'IA expérimental utilisant la puissance de modèles linguistiques associés à votre contenu existant pour obtenir plus rapidement des informations critiques. Semblable à un assistant de recherche virtuel capable de résumer des faits, d'expliquer des idées complexes et de réfléchir à de nouvelles connexions en fonction des sources que vous sélectionnez.
Unilm est une pré-formation auto-supervisée à grande échelle couvrant les tâches, les langues et les modalités.
Semantic Kernel (SK) est un SDK léger permettant l'intégration de modèles de langage étendus (LLM) d'IA avec des langages de programmation conventionnels. Le modèle de programmation extensible SK combine des fonctions sémantiques en langage naturel, des fonctions natives de code traditionnel et une mémoire basée sur l'intégration, libérant ainsi un nouveau potentiel et ajoutant de la valeur aux applications avec l'IA.
Pandas AI est une bibliothèque Python qui intègre des capacités d'intelligence artificielle générative dans Pandas, rendant les trames de données conversationnelles.
NCNN est un cadre d'inférence de réseau neuronal haute performance optimisé pour la plate-forme mobile.
MNN est un cadre d'apprentissage profond ultra-rapide et léger, testé par des cas d'utilisation critiques pour l'entreprise chez Alibaba.
MediaPipe est optimisé pour des performances de bout en bout sur un large éventail de plates-formes. Voir les démos En savoir plus ML complexe sur appareil, simplifié Nous avons éliminé les complexités liées à la création d'un ML sur appareil personnalisable, prêt pour la production et accessible sur toutes les plateformes.
MegEngine est un framework d'apprentissage en profondeur rapide, évolutif et convivial avec 3 fonctionnalités clés : Un framework unifié pour la formation et l'inférence.
ML.NET est une bibliothèque d'apprentissage automatique conçue comme une plate-forme extensible afin que vous puissiez utiliser d'autres frameworks ML populaires (TensorFlow, ONNX, Infer.NET, etc.) et avoir accès à encore plus de scénarios d'apprentissage automatique, comme la classification d'images, détection d'objets, et plus encore.
Ludwig est un framework d'apprentissage automatique déclaratif qui facilite la définition de pipelines d'apprentissage automatique à l'aide d'un système de configuration simple et flexible basé sur les données.
MMdnn est un outil complet et multi-framework pour convertir, visualiser et diagnostiquer des modèles d'apprentissage profond (DL). Le « MM » signifie gestion de modèles et « dnn » est l'acronyme de réseau neuronal profond. Convertissez des modèles entre Caffe, Keras, MXNet, Tensorflow, CNTK, PyTorch Onnx et CoreML.
Horovod est un framework de formation d'apprentissage profond distribué pour TensorFlow, Keras, PyTorch et Apache MXNet.
Vaex est une bibliothèque Python hautes performances pour les DataFrames Out-of-Core paresseux (similaires aux Pandas), permettant de visualiser et d'explorer de grands ensembles de données tabulaires.
GluonTS est un package Python pour la modélisation probabiliste de séries chronologiques, axé sur les modèles basés sur l'apprentissage profond, basés sur PyTorch et MXNet.
MindsDB est un serveur ML-SQL qui permet des flux de travail d'apprentissage automatique pour les bases de données et entrepôts de données les plus puissants utilisant SQL.
Jupyter Notebook est une application Web open source qui vous permet de créer et de partager des documents contenant du code en direct, des équations, des visualisations et du texte narratif. Jupyter est largement utilisé dans les secteurs qui effectuent le nettoyage et la transformation de données, la simulation numérique, la modélisation statistique, la visualisation de données, la science des données et l'apprentissage automatique.
Apache Spark est un moteur d'analyse unifié pour le traitement de données à grande échelle. Il fournit des API de haut niveau en Scala, Java, Python et R, ainsi qu'un moteur optimisé qui prend en charge les graphiques de calcul généraux pour l'analyse des données. Il prend également en charge un riche ensemble d'outils de niveau supérieur, notamment Spark SQL pour SQL et DataFrames, MLlib pour l'apprentissage automatique, GraphX pour le traitement des graphiques et Structured Streaming pour le traitement des flux.
Apache Spark Connector pour SQL Server et Azure SQL est un connecteur hautes performances qui vous permet d'utiliser des données transactionnelles dans l'analyse du Big Data et de conserver les résultats pour les requêtes ou les rapports ad hoc. Le connecteur vous permet d'utiliser n'importe quelle base de données SQL, sur site ou dans le cloud, comme source de données d'entrée ou récepteur de données de sortie pour les tâches Spark.
Apache PredictionIO est un framework d'apprentissage automatique open source destiné aux développeurs, aux data scientists et aux utilisateurs finaux. Il prend en charge la collecte d'événements, le déploiement d'algorithmes, l'évaluation et l'interrogation de résultats prédictifs via les API REST. Il est basé sur des services open source évolutifs comme Hadoop, HBase (et autres bases de données), Elasticsearch, Spark et implémente ce qu'on appelle une architecture Lambda.
Cluster Manager for Apache Kafka (CMAK) est un outil de gestion des clusters Apache Kafka.
BigDL est une bibliothèque d'apprentissage profond distribuée pour Apache Spark. Avec BigDL, les utilisateurs peuvent écrire leurs applications de deep learning sous forme de programmes Spark standard, qui peuvent s'exécuter directement sur les clusters Spark ou Hadoop existants.
Eclipse Deeplearning4J (DL4J) est un ensemble de projets destinés à prendre en charge tous les besoins d'une application d'apprentissage profond basée sur JVM (Scala, Kotlin, Clojure et Groovy). Cela signifie commencer par les données brutes, les charger et les prétraiter où que ce soit et quel que soit leur format, pour créer et régler une grande variété de réseaux d'apprentissage en profondeur simples et complexes.
Tensorman est un utilitaire permettant de gérer facilement les conteneurs Tensorflow développé par System76. Tensorman permet à Tensorflow de fonctionner dans un environnement isolé, confiné au reste du système. Cet environnement virtuel peut fonctionner indépendamment du système de base, vous permettant d'utiliser n'importe quelle version de Tensorflow sur n'importe quelle version d'une distribution Linux prenant en charge le runtime Docker.
Numba est un compilateur d'optimisation open source compatible NumPy pour Python sponsorisé par Anaconda, Inc. Il utilise le projet de compilateur LLVM pour générer du code machine à partir de la syntaxe Python. Numba peut compiler un large sous-ensemble de Python à orientation numérique, y compris de nombreuses fonctions NumPy. De plus, Numba prend en charge la parallélisation automatique des boucles, la génération de code accéléré par GPU et la création d'ufuncs et de rappels C.
Chainer est un framework d'apprentissage en profondeur basé sur Python visant la flexibilité. Il fournit des API de différenciation automatique basées sur l'approche de définition par exécution (graphiques informatiques dynamiques) ainsi que des API de haut niveau orientées objet pour créer et former des réseaux de neurones. Il prend également en charge CUDA/cuDNN en utilisant CuPy pour une formation et une inférence hautes performances.
XGBoost est une bibliothèque distribuée optimisée d'amélioration de gradient conçue pour être très efficace, flexible et portable. Il implémente des algorithmes d'apprentissage automatique dans le cadre du framework Gradient Boosting. XGBoost fournit un boosting d'arbre parallèle (également connu sous le nom de GBDT, GBM) qui résout de nombreux problèmes de science des données de manière rapide et précise. Il prend en charge la formation distribuée sur plusieurs machines, notamment les clusters AWS, GCE, Azure et Yarn. En outre, il peut être intégré à Flink, Spark et d'autres systèmes de flux de données cloud.
cuML est une suite de bibliothèques qui implémentent des algorithmes d'apprentissage automatique et des fonctions de primitives mathématiques qui partagent des API compatibles avec d'autres projets RAPIDS. cuML permet aux data scientists, aux chercheurs et aux ingénieurs logiciels d'exécuter des tâches de ML tabulaires traditionnelles sur des GPU sans entrer dans les détails de la programmation CUDA. Dans la plupart des cas, l'API Python de cuML correspond à l'API de scikit-learn.
Emu est une bibliothèque GPGPU pour Rust axée sur la portabilité, la modularité et les performances. Il s'agit d'une abstraction spécifique au calcul de type CUDA sur WebGPU fournissant des fonctionnalités spécifiques pour que WebGPU ressemble davantage à CUDA.
Scalene est un profileur de CPU, GPU et mémoire hautes performances pour Python qui fait un certain nombre de choses que les autres profileurs Python ne font pas et ne peuvent pas faire. Il s'exécute plusieurs fois plus rapidement que de nombreux autres profileurs tout en fournissant des informations beaucoup plus détaillées.
MLpack est une bibliothèque d'apprentissage automatique C++ rapide et flexible écrite en C++ et construite sur la bibliothèque d'algèbre linéaire Armadillo, la bibliothèque d'optimisation numérique ensmallen et des parties de Boost.
Netron est un visualiseur de modèles de réseaux neuronaux, d'apprentissage profond et d'apprentissage automatique. Il prend en charge ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 et UFF.
Lightning est un outil qui crée et entraîne des modèles PyTorch et les connecte au cycle de vie du ML à l'aide de modèles d'application Lightning, sans gérer l'infrastructure de bricolage, la gestion des coûts, la mise à l'échelle, etc.
OpenNN est une bibliothèque de réseaux de neurones open source pour l'apprentissage automatique. Il contient des algorithmes et des utilitaires sophistiqués pour gérer de nombreuses solutions d'intelligence artificielle.
H20 est une plateforme AI Cloud qui résout des problèmes commerciaux complexes et accélère la découverte de nouvelles idées avec des résultats que vous pouvez comprendre et auxquels vous pouvez faire confiance.
Gensim est une bibliothèque Python pour la modélisation de sujets, l'indexation de documents et la récupération de similarités avec de grands corpus. Le public cible est la communauté du traitement du langage naturel (NLP) et de la recherche d'informations (RI).
llama.cpp est un portage du modèle LLaMA de Facebook en C/C++.
hmmlearn est un ensemble d'algorithmes pour l'apprentissage et l'inférence non supervisés de modèles de Markov cachés.
Nextjournal est un cahier de recherche reproductible. Il exécute tout ce que vous pouvez mettre dans un conteneur Docker. Améliorez votre flux de travail avec des blocs-notes polyglottes, une gestion automatique des versions et une collaboration en temps réel. Économisez du temps et de l'argent grâce au provisionnement à la demande, y compris la prise en charge du GPU.
IPython fournit une architecture riche pour l'informatique interactive avec :
Veles est une plate-forme distribuée pour le développement rapide d'applications d'apprentissage profond actuellement développée par Samsung.
DyNet est une bibliothèque de réseaux neuronaux développée par l'Université Carnegie Mellon et bien d'autres. Il est écrit en C++ (avec des liaisons en Python) et est conçu pour être efficace lorsqu'il est exécuté sur CPU ou GPU, et pour bien fonctionner avec des réseaux dotés de structures dynamiques qui changent pour chaque instance de formation. Ces types de réseaux sont particulièrement importants dans les tâches de traitement du langage naturel, et DyNet a été utilisé pour créer des systèmes de pointe pour l'analyse syntaxique, la traduction automatique, l'inflexion morphologique et de nombreux autres domaines d'application.
Ray est un framework unifié pour faire évoluer les applications IA et Python. Il se compose d'un environnement d'exécution distribué de base et d'une boîte à outils de bibliothèques (Ray AIR) pour accélérer les charges de travail de ML.
murmur.cpp est une inférence haute performance du modèle de reconnaissance vocale automatique (ASR) Whisper d'OpenAI.
ChatGPT Plus est un plan d'abonnement pilote ( 20 $/mois ) pour ChatGPT, une IA conversationnelle qui peut discuter avec vous, répondre à des questions de suivi et contester des hypothèses incorrectes.
Auto-GPT est un « agent IA » qui, étant donné un objectif en langage naturel, peut tenter de l'atteindre en le divisant en sous-tâches et en utilisant Internet et d'autres outils dans une boucle automatique. Il utilise les API GPT-4 ou GPT-3.5 d'OpenAI et fait partie des premiers exemples d'application utilisant GPT-4 pour effectuer des tâches autonomes.
Chatbot UI de mckaywrigley est un kit de chatbot avancé pour les modèles de chat d'OpenAI construit sur Chatbot UI Lite à l'aide de Next.js, TypeScript et Tailwind CSS. Cette version de ChatBot UI prend en charge les modèles GPT-3.5 et GPT-4. Les conversations sont stockées localement dans votre navigateur. Vous pouvez exporter et importer des conversations pour vous protéger contre la perte de données. Voir une démo.
Chatbot UI Lite de mckaywrigley est un simple kit de démarrage de chatbot pour le modèle de chat d'OpenAI utilisant Next.js, TypeScript et Tailwind CSS. Voir une démo.
MiniGPT-4 est une compréhension améliorée du langage visuel avec des modèles de langage étendus avancés.
GPT4All est un écosystème de chatbots open source formés sur une collection massive de données d'assistant propres, notamment du code, des histoires et des dialogues basés sur LLaMa.
GPT4All UI est une application Web Flask qui fournit une interface utilisateur de chat pour interagir avec le chatbot GPT4All.
Alpaca.cpp est un modèle rapide de type ChatGPT localement sur votre appareil. Il combine le modèle de base LLaMA avec une reproduction ouverte de Stanford Alpaca, un réglage fin du modèle de base pour obéir aux instructions (semblable au RLHF utilisé pour entraîner ChatGPT) et un ensemble de modifications à lama.cpp pour ajouter une interface de discussion.
llama.cpp est un portage du modèle LLaMA de Facebook en C/C++.
OpenPlayground est un terrain de jeu pour exécuter des modèles de type ChatGPT localement sur votre appareil.
Vicuna est un chatbot open source formé par le réglage fin de LLaMA. Il atteint apparemment une qualité de chatgpt supérieure à 90 % et coûte 300 $ pour s'entraîner.
Yeagar ai est un créateur d'agents Langchain conçu pour vous aider à créer, prototyper et déployer facilement des agents basés sur l'IA.
Vicuna est créé en affinant un modèle de base LLaMA à l'aide d'environ 70 000 conversations partagées par les utilisateurs recueillies sur ShareGPT.com avec des API publiques. Pour garantir la qualité des données, il reconvertit le HTML en markdown et filtre certains échantillons inappropriés ou de mauvaise qualité.
ShareGPT est un endroit pour partager vos conversations ChatGPT les plus folles en un seul clic. Avec 198 404 conversations partagées jusqu’à présent.
FastChat est une plate-forme ouverte pour la formation, le service et l'évaluation de chatbots basés sur de grands modèles de langage.
Haystack est un framework NLP open source pour interagir avec vos données à l'aide de modèles Transformer et LLM (GPT-4, ChatGPT et similaires). Il offre des outils prêts pour la production pour créer rapidement des applications complexes de prise de décision, de réponse aux questions, de recherche sémantique, de génération de texte, etc.
StableLM (Stability AI Language Models) est une série de modèles de langage StableLM et sera continuellement mise à jour avec de nouveaux points de contrôle.
Databricks' Dolly est un grand modèle de langage qui suit des instructions et qui est formé sur la plateforme d'apprentissage automatique Databricks sous licence pour un usage commercial.
GPTCach est une bibliothèque permettant de créer un cache sémantique pour les requêtes LLM.
AlaC est un générateur d'infrastructure en tant que code d'intelligence artificielle.
Adrenaline est un outil qui vous permet de parler à votre base de code. Il est alimenté par l'analyse statique, la recherche vectorielle et de grands modèles de langage.
OpenAssistant est un assistant basé sur le chat qui comprend les tâches, peut interagir avec des systèmes tiers et récupérer des informations de manière dynamique pour ce faire.
DoctorGPT est un binaire autonome léger qui surveille les journaux de vos applications à la recherche de problèmes et les diagnostique.
HttpGPT est un plugin Unreal Engine 5 qui facilite l'intégration avec les services basés sur GPT d'OpenAI (ChatGPT et DALL-E) via des requêtes REST asynchrones, permettant aux développeurs de communiquer facilement avec ces services. Il comprend également des outils d'édition pour intégrer la génération d'images Chat GPT et DALL-E directement dans le moteur.
PaLM 2 est un grand modèle de langage de nouvelle génération qui s'appuie sur l'héritage de recherche révolutionnaire de Google en matière d'apprentissage automatique et d'IA responsable. Il comprend des tâches de raisonnement avancées, notamment le code et les mathématiques, la classification et la réponse aux questions, la traduction et la maîtrise du multilingue, ainsi que la génération de langage naturel, meilleures que nos précédents LLM de pointe.
Med-PaLM est un grand modèle de langage (LLM) conçu pour fournir des réponses de haute qualité aux questions médicales. Il exploite la puissance des grands modèles linguistiques de Google, que nous avons alignés sur le domaine médical avec un ensemble de démonstrations d'experts médicaux soigneusement organisées.
Sec-PaLM est un grand modèle de langage (LLM) qui accélère la capacité d'aider les personnes responsables de la sécurité de leur organisation. Ces nouveaux modèles offrent non seulement aux utilisateurs une manière plus naturelle et créative de comprendre et de gérer la sécurité.
Retour au sommet
Retour au sommet
Retour au sommet
Localai est une API locale compatible ouverte locale, axée sur la communauté et locale. Remplacement de dépôt pour les LLM en cours d'exécution OpenAI sur le matériel de qualité grand public sans aucun GPU requis. C'est une API pour exécuter des modèles compatibles GGML: Llama, GPT4ALL, RWKV, Whisper, Vicuna, Koala, GPT4ALL-J, Cerebras, Falcon, Dolly, Starcoder et bien d'autres.
Lama.cpp est un port du modèle LLAMA de Facebook en C / C ++.
Olllama est un outil pour se présenter avec LLAMA 2 et d'autres modèles de grande langue localement.
Localai est une API locale compatible ouverte locale, axée sur la communauté et locale. Remplacement de dépôt pour les LLM en cours d'exécution OpenAI sur le matériel de qualité grand public sans aucun GPU requis. C'est une API pour exécuter des modèles compatibles GGML: Llama, GPT4ALL, RWKV, Whisper, Vicuna, Koala, GPT4ALL-J, Cerebras, Falcon, Dolly, Starcoder et bien d'autres.
Serge est une interface Web pour discuter avec Alpaca via llama.cpp. Entièrement auto-hébergé et dockée, avec une API facile à utiliser.
OpenLLM est une plate-forme ouverte pour faire fonctionner de grands modèles de langage (LLMS) en production. Affiner, servir, déployer et surveiller les LLM avec facilité.
Llama-GPT est un chatbot auto-hébergé, hors ligne et semblable à un chatpt. Propulsé par Llama 2. 100% privé, sans données quittant votre appareil.
LLAMA2 WEBUI est un outil pour exécuter n'importe quel Llama 2 localement avec Gradio UI sur GPU ou CPU de n'importe où (Linux / Windows / Mac). Utilisez llama2-wrapper comme backend LLAMA2 local pour les agents / applications génératifs.
LLAMA2.C est un outil pour former l'architecture LLAMA 2 LLM à Pytorch puis l'inférer avec un fichier C simple à 700 lignes (Run.C).
Alpaca.cpp est un modèle rapide de type chatppt localement sur votre appareil. Il combine le modèle de fondation lama avec une reproduction ouverte de Stanford Alpaca un réglage fin du modèle de base pour obéir aux instructions (semblable au RLHF utilisé pour former le chatppt) et un ensemble de modifications sur llama.cpp pour ajouter une interface de chat.
GPT4ALL est un écosystème de chatbots open source formé sur une collection massive de données assistantes propres, notamment du code, des histoires et du dialogue basé sur LLAMA.
Minigpt-4 est une compréhension améliorante de la vision avec des modèles avancés de grande langue
Lollms Webui est un modèle de hub pour les modèles LLM (modèle grand langage). Il vise à fournir une interface conviviale pour accéder et utiliser divers modèles LLM pour une large gamme de tâches. Que vous ayez besoin d'aide pour l'écriture, le codage, l'organisation de données, la génération d'images ou la recherche de réponses à vos questions.
LM Studio est un outil pour découvrir, télécharger et exécuter des LLM locaux.
L'interface utilisateur Web Gradio est un outil pour les modèles de grande langue. Soutient Transformers, GPTQ, LLAMA.CPP (GGML / GGUF), LLAMA Models.
OpenPlayground est un PlayFround pour exécuter des modèles de type ChatGPT localement sur votre appareil.
Vicuna est un chatbot open source formé par Fine Tuning Llama. Il obtient apparemment plus de 90% de la qualité de Chatgpt et coûte 300 $ pour s'entraîner.
Yeagar AI est un créateur d'agent de Langchain conçu pour vous aider à construire, prototyper et déployer facilement les agents alimentés par AI.
KoboldCPP est un logiciel de génération de texte AI facile à utiliser pour les modèles GGML. Il s'agit d'un seul auto-contenu distribuable de Concedo, qui construit sur Llama.cpp, et ajoute un point de terminaison de l'API Kobold polyvalent, un support de format supplémentaire, une compatibilité arriérée, ainsi qu'une interface utilisateur fantaisie avec des histoires persistantes, des outils d'édition, des formats de sauvegarde, de la mémoire, du monde Informations, note, personnages et scénarios de l'auteur.
Retour au sommet
Fuzzy Logic est une approche heuristique qui permet un traitement plus avancé de la décision et une meilleure intégration avec une programmation basée sur des règles.
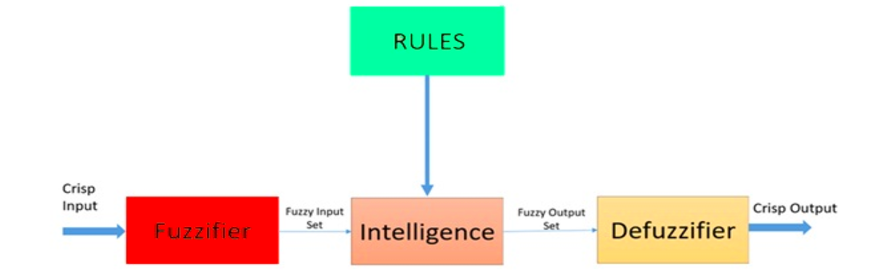
Architecture d'un système logique floue. Source: Researchgate
Support Vector Machine (SVM) est un modèle d'apprentissage automatique supervisé qui utilise des algorithmes de classification pour des problèmes de classification à deux groupes.

Support Vector Machine (SVM). Source: OpenClipart
Les réseaux de neurones sont un sous-ensemble d'apprentissage automatique et sont au cœur des algorithmes d'apprentissage en profondeur. Le nom / structure est inspiré par le cerveau humain copie le processus que les neurones / nœuds biologiques se signalent.
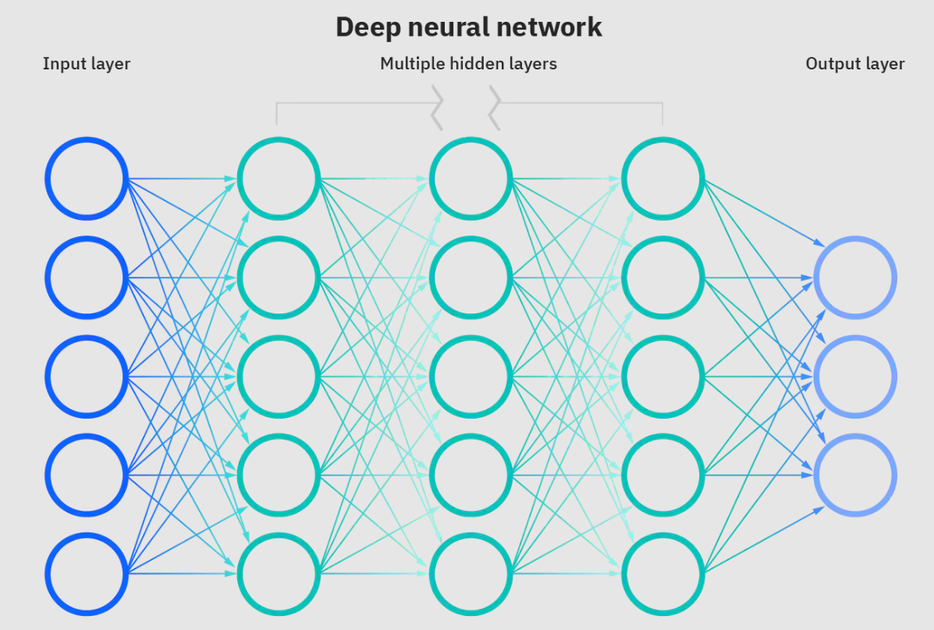
Réseau neuronal profond. Source: IBM
Les réseaux de neurones convolutionnels (R-CNN) sont un algorithme de détection d'objet qui segmente d'abord l'image pour trouver des boîtes de délimitation pertinentes potentielles, puis exécutez l'algorithme de détection pour trouver la plupart des objets probables dans ces boîtes de délimitation.
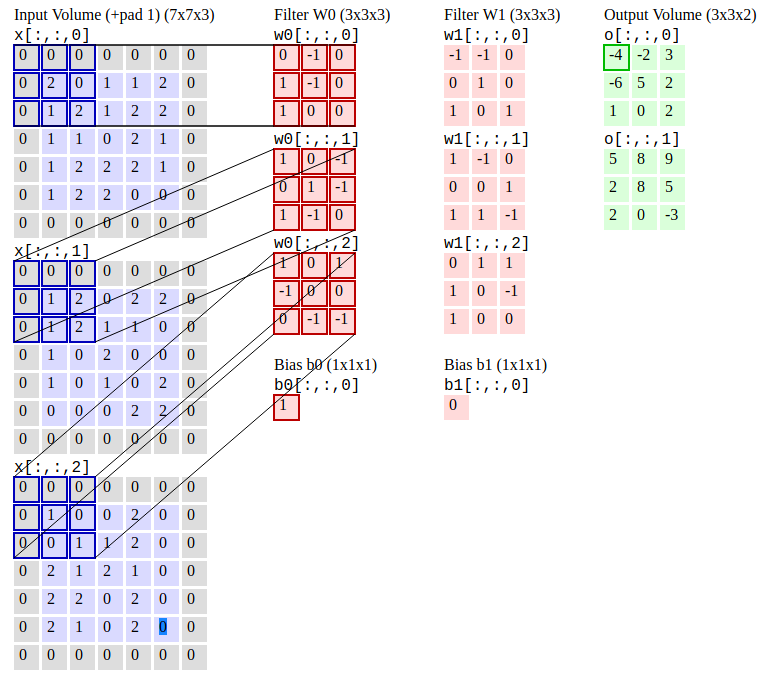
Réseaux de neurones convolutionnels. Source: CS231N
Les réseaux de neurones récurrents (RNN) sont un type de réseau neuronal artificiel qui utilise des données séquentielles ou des données de séries temporelles.
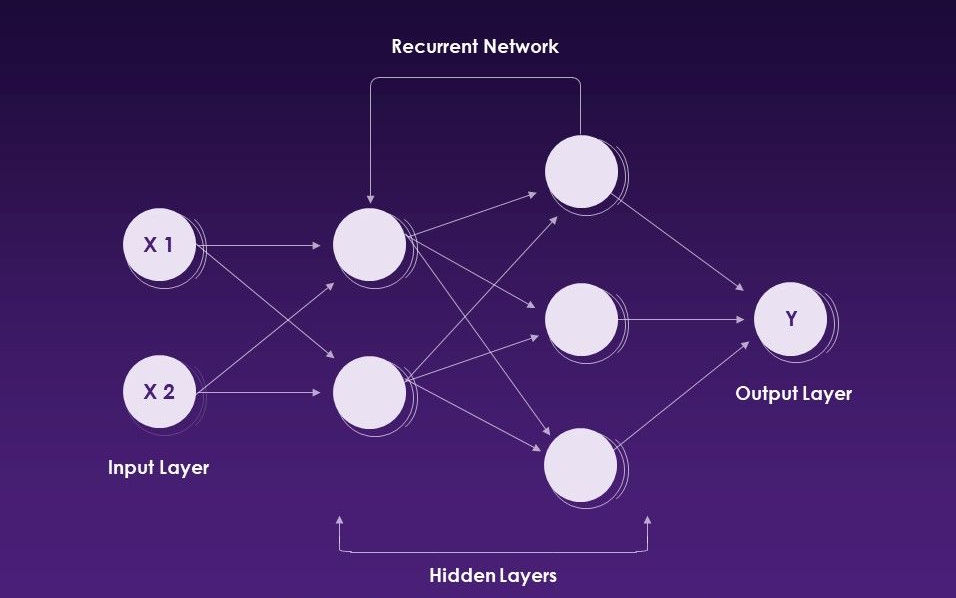
Réseaux de neurones récurrents. Source: Slideteam
Les perceptrons multicouches (MLP) sont des réseaux neuronaux multicouches composés de plusieurs couches de perceptrons avec une activation seuil.
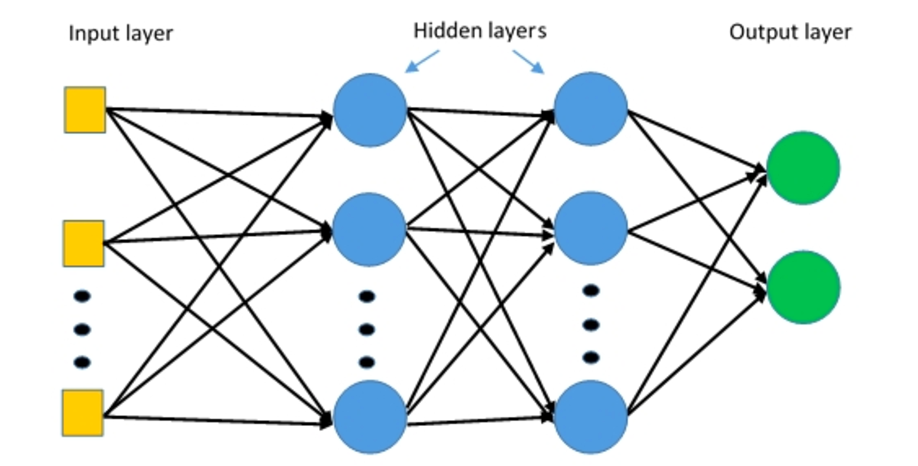
Perceptrons multicouches. Source: Deepai
La forêt aléatoire est un algorithme d'apprentissage automatique couramment utilisé, qui combine la sortie de plusieurs arbres de décision pour atteindre un seul résultat. Un arbre de décision dans une forêt ne peut pas être taillé pour l'échantillonnage et donc la sélection de prédiction. Sa facilité d'utilisation et sa flexibilité ont alimenté son adoption, car il gère à la fois les problèmes de classification et de régression.
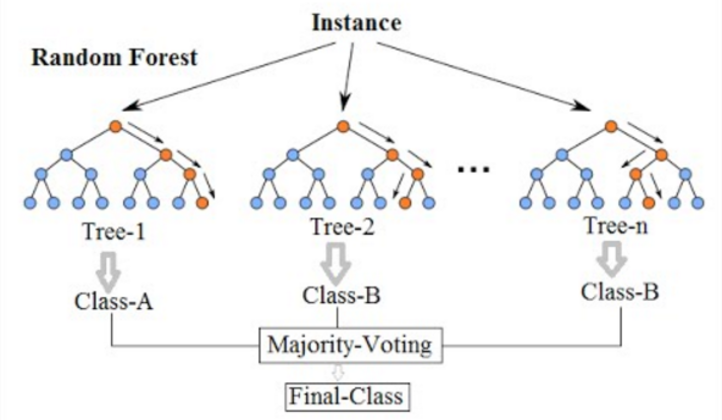
Forêt aléatoire. Source : wikimédia
Les arbres de décision sont des modèles structurés des arbres pour la classification et la régression.
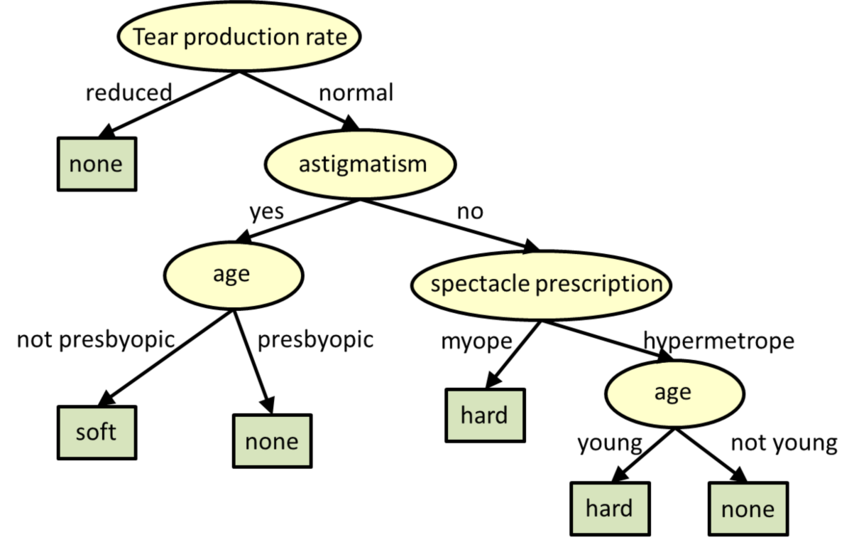
** Arbres de décision. Source: CMU
Naive Bayes est un algorithme d'apprentissage automatique qui est utilisé des problèmes de calsification résolu. Il est basé sur l'application du théorème de Bayes avec de fortes hypothèses d'indépendance entre les fonctionnalités.

Théorème de Bayes. Source: Mathisfun
Retour au sommet

Pytorch est un cadre d'apprentissage en profondeur open source qui accélère la voie de la recherche à la production, utilisé pour des applications telles que la vision par ordinateur et le traitement du langage naturel. Pytorch est développé par le laboratoire de recherche AI de Facebook.
Commencer avec Pytorch
Documentation Pytorch
Forum de discussion Pytorch
Top Pytorch Cours en ligne | Coursera
Top Pytorch Cours en ligne | Udemy
Apprenez Pytorch avec des cours et des cours en ligne | edX
Pytorch Fundamentals - Learn | Microsoft Docs
Intro à l'apprentissage en profondeur avec Pytorch | Udacité
Pytorch Development in Visual Studio Code
Pytorch sur Azure - Deep Learning with Pytorch | Microsoft Azure
Pytorch - Azure Databricks | Microsoft Docs
Deep Learning with Pytorch | Amazon Web Services (AWS)
Début avec Pytorch sur Google Cloud
Pytorch Mobile est un flux de travail ML de bout en bout de la formation au déploiement pour les appareils mobiles iOS et Android.
TorchScript est un moyen de créer des modèles sérialisables et optimisables à partir du code Pytorch. Cela permet à tout programme TORCHScript d'être enregistré à partir d'un processus Python et chargé dans un processus où il n'y a pas de dépendance Python.
Torchserve est un outil flexible et facile à utiliser pour servir les modèles Pytorch.
Keras est une API de réseaux neuronaux de haut niveau, écrite en python et capable de courir sur Tensorflow, CNTK ou Theano.Il a été développé en mettant l'accent sur l'activation d'une expérimentation rapide. Il est capable de fonctionner sur TensorFlow, Microsoft Cognitive Toolkit, R, Theano ou PLAIDML.
L'ONNX Runtime est un accélérateur d'inférence ML haute plateforme et haute performance et de formation. Il prend en charge les modèles de frameworks d'apprentissage en profondeur tels que Pytorch et TensorFlow / Keras ainsi que des bibliothèques d'apprentissage automatique classiques telles que Scikit-Learn, LightGBM, XGBOost, etc.
Kornia est une bibliothèque de vision informatique différente qui se compose d'un ensemble de routines et de modules différenciables pour résoudre les problèmes génériques de CV (vision par ordinateur).
Pytorch-NLP est une bibliothèque pour le traitement du langage naturel (NLP) dans Python. Il est construit avec la toute dernière recherche à l'esprit et a été conçu dès le premier jour pour soutenir le prototypage rapide. Pytorch-NLP est livré avec des incorporations pré-formées, des échantillonneurs, des chargeurs de données, des métriques, des modules de réseau neuronal et des encodeurs de texte.
Ignite est une bibliothèque de haut niveau pour aider à la formation et à l'évaluation des réseaux de neurones en pytorch de manière flexible et transparente.
Hummingbird est une bibliothèque pour compiler les modèles ML traditionnels formés dans les calculs du tenseur. Il permet aux utilisateurs de tirer parti de manière transparente des cadres de réseau neuronal (comme Pytorch) pour accélérer les modèles ML traditionnels.
Deep Graph Library (DGL) est un package Python conçu pour une implémentation facile de la famille du modèle de réseau neuronal graphique, en plus de Pytorch et d'autres cadres.
Tensorly est une API de haut niveau pour les méthodes de tension et les réseaux de neurones tenorisés profonds en Python qui vise à rendre l'apprentissage du tenseur simple.
GPYTORCH est une bibliothèque de processus gaussienne implémentée à l'aide de Pytorch, conçue pour créer des modèles de processus gaussiens flexibles évolutifs et flexibles.
Poutyne est un cadre de type Keras pour Pytorch et gère une grande partie du code de la boiler nécessaire pour former des réseaux de neurones.
Forte est une boîte à outils pour construire des pipelines NLP avec des composants composables, des interfaces de données pratiques et une interaction entre les tâches.
TorchMetrics est une mesure d'apprentissage automatique pour les applications Pytorch distribuées et évolutives.
Captum est une bibliothèque extensible open source pour l'interprétabilité du modèle construite sur Pytorch.
Le transformateur est un traitement du langage naturel à la pointe de la technologie pour Pytorch, TensorFlow et Jax.
HYDRA est un cadre pour configurer élégamment les applications complexes.
Accelerate est un moyen simple de s'entraîner et d'utiliser des modèles Pytorch avec multi-GPU, TPU, précision mixte.
Ray est un cadre rapide et simple pour construire et exécuter des applications distribuées.
Parlai est une plate-forme unifiée pour le partage, la formation et l'évaluation des modèles de dialogue sur de nombreuses tâches.
Pytorchvideo est une bibliothèque d'apprentissage en profondeur pour la recherche de compréhension vidéo. Héberge divers modèles, ensembles de données, des pipelines d'entraînement et plus encore.
Opacus est une bibliothèque qui permet la formation de modèles Pytorch avec une confidentialité différentielle.
Pytorch Lightning est une bibliothèque ML de type Keras pour Pytorch. Il vous laisse une logique de formation et de validation de base et automatise le reste.
Pytorch Geometric Temporal est une bibliothèque d'extension temporelle (dynamique) pour la géométrique Pytorch.
Pytorch Geométrique est une bibliothèque d'apprentissage en profondeur sur des données d'entrée irrégulières telles que les graphiques, les nuages ponctuels et les collecteurs.
Raster Vision est un cadre open source pour l'apprentissage en profondeur sur les images satellites et aériennes.
Crypten est un cadre pour la préservation de la confidentialité ML. Son objectif est de rendre les techniques informatiques sécurisées accessibles aux praticiens de la ML.
Optuna est un cadre d'optimisation hyperparamètre open source pour automatiser la recherche d'hyperparamètre.
Pyro est un langage de programmation probabiliste universel (PPL) écrit en python et soutenu par Pytorch sur le backend.
Albumentations est une bibliothèque d'augmentation d'image rapide et extensible pour différentes tâches CV comme la classification, la segmentation, la détection d'objets et l'estimation de la pose.
Skorch est une bibliothèque de haut niveau pour Pytorch qui offre une compatibilité complète de Scikit-Learn.
MMF est un cadre modulaire pour la recherche multimodale Vision & Language de Facebook AI Research (FAIR).
ADAPTDL est un cadre de formation et de planification d'apprentissage en profondeur adaptatif en ressources.
Le polyaxon est une plate-forme pour la construction, la formation et la surveillance des applications d'apprentissage en profondeur à grande échelle.
TextBrewer est une boîte à outils de distillation de connaissances basée sur Pytorch pour le traitement du langage naturel
Le publicité est une boîte à outils pour la recherche sur la robustesse adversaire. Il contient des modules pour générer des exemples contradictoires et défendre contre les attaques.
Nemo est la boîte à outils AA pour l'IA conversationnelle.
Clinicadl est un cadre de classification reproductible de la maladie d'Alzheimer
STABLE BASELINES3 (SB3) est un ensemble d'implémentations fiables des algorithmes d'apprentissage de renforcement dans Pytorch.
Torchio est un ensemble d'outils pour lire efficacement, prétraitement, échantillonner, augmenter et écrire des images médicales 3D dans des applications d'apprentissage en profondeur écrites en pytorch.
Pysyft est une bibliothèque Python pour l'apprentissage en profondeur crypté et confidentiel.
Flair est un cadre très simple pour le traitement du langage naturel de pointe (NLP).
Glow est un compilateur ML qui accélère les performances des cadres d'apprentissage en profondeur sur différentes plates-formes matérielles.
FairScale est une bibliothèque d'extension Pytorch pour des performances élevées et une formation à grande échelle sur une ou plusieurs machines / nœuds.
Monai est un cadre d'apprentissage en profondeur qui offre des capacités fondamentales optimisées dans le domaine pour développer des flux de travail de formation d'imagerie des soins de santé.
PFRL est une bibliothèque d'apprentissage de renforcement profonde qui implémente divers algorithmes de renforcement profond de pointe à Python à l'aide de Pytorch.
Einops est une opération de tenseur flexible et puissante pour un code lisible et fiable.
Pytorch3d est une bibliothèque d'apprentissage en profondeur qui fournit des composants efficaces et réutilisables pour la recherche sur la vision par ordinateur 3D avec Pytorch.
Ensemble Pytorch est un cadre d'ensemble unifié pour Pytorch afin d'améliorer les performances et la robustesse de votre modèle d'apprentissage en profondeur.
Légèrement est un cadre de vision par ordinateur pour l'apprentissage auto-supervisé.
Plus haut est une bibliothèque qui facilite la mise en œuvre d'algorithmes de méta-apprentissage à base de gradient arbitrairement complexes et de boucles d'optimisation imbriquées avec un pytorch proche de la vanille.
Horovod est une bibliothèque de formation distribuée pour les cadres d'apprentissage en profondeur. Horovod vise à rendre DL distribué rapidement et facile à utiliser.
Pennylane est une bibliothèque pour la ML quantique, la différenciation automatique et l'optimisation des calculs hybrides-classiques quantiques.
Detectron2 est la plate-forme de nouvelle génération de Fair pour la détection et la segmentation des objets.
Fastai est une bibliothèque qui simplifie l'entraînement Fast et précis NEURAL NEURS en utilisant les meilleures pratiques modernes.
Retour au sommet

TensorFlow est une plate-forme open source de bout en bout pour l'apprentissage automatique. Il dispose d'un écosystème complet et flexible d'outils, de bibliothèques et de ressources communautaires qui permet aux chercheurs de pousser l'état de l'art en ML et les développeurs créent et déploient facilement des applications alimentées par ML.
Début avec TensorFlow
Tutoriels TensorFlow
Certificat de développeur TensorFlow | TensorFlow
Communauté Tensorflow
TensorFlow Modèles et ensembles de données
Nuage de tensorflow
Éducation à l'apprentissage automatique | TensorFlow
Top TensorFlow Cours en ligne | Coursera
Top TensorFlow Cours en ligne | Udemy
Apprentissage en profondeur avec TensorFlow | Udemy
Apprentissage en profondeur avec TensorFlow | edX
Intro à TensorFlow pour l'apprentissage en profondeur | Udacité
Intro à TensorFlow: cours de crash d'apprentissage automatique | Développeurs Google
Former et déployer un modèle TensorFlow - Azure Machine Learning
Appliquer des modèles d'apprentissage automatique dans les fonctions Azure avec Python et TensorFlow | Microsoft Azure
Apprentissage en profondeur avec TensorFlow | Amazon Web Services (AWS)
TensorFlow - Amazon EMR | Documentation AWS
TensorFlow Enterprise | Google Cloud
TensorFlow Lite est un cadre de Deep Learning open source pour le déploiement de modèles d'apprentissage automatique sur les appareils mobiles et IoT.
Tensorflow.js est une bibliothèque JavaScript qui vous permet de développer ou d'exécuter des modèles ML dans JavaScript et d'utiliser ML directement dans le côté client du navigateur, côté serveur via Node.js, mobile natif via React natif, de bureau natif via Electron et même sur l'IoT Dispositifs via Node.js sur Raspberry Pi.
Tensorflow_macos est une version optimisée MAC des addons TensorFlow et TensorFlow pour MacOS 11.0+ accéléré à l'aide du cadre de calcul ML d'Apple.
Google Colaboratory est un environnement de carnet de jupyter gratuit qui ne nécessite aucune configuration et fonctionne entièrement dans le cloud, vous permettant d'exécuter du code TensorFlow dans votre navigateur en un seul clic.
L'outil What-If est un outil pour le sondage sans code des modèles d'apprentissage automatique, utile pour la compréhension des modèles, le débogage et l'équité. Disponible dans Tensorboard et Jupyter ou Colab Notebooks.
Tensorboard est une suite d'outils de visualisation pour comprendre, déboguer et optimiser les programmes TensorFlow.
Keras est une API de réseaux neuronaux de haut niveau, écrite en python et capable de courir sur Tensorflow, CNTK ou Theano.Il a été développé en mettant l'accent sur l'activation d'une expérimentation rapide. Il est capable de fonctionner sur TensorFlow, Microsoft Cognitive Toolkit, R, Theano ou PLAIDML.
XLA (algèbre linéaire accélérée) est un compilateur spécifique au domaine pour l'algèbre linéaire qui optimise les calculs de tensorflow. Les résultats sont des améliorations de la vitesse, de l'utilisation de la mémoire et de la portabilité sur les plates-formes de serveurs et mobiles.
ML Perf est une large suite de référence ML pour mesurer les performances des cadres logiciels ML, des accélérateurs matériels ML et des plates-formes Cloud ML.
Tensorflow Playground est un environnement de développement pour bricoler avec un réseau neuronal dans votre navigateur.
TPU Research Cloud (TRC) est un programme permet aux chercheurs de demander l'accès à un groupe de plus de 1 000 TPU cloud sans frais pour les aider à accélérer la prochaine vague de percées de recherche.
Mlir est un nouveau cadre de représentation intermédiaire et de compilateur.
Le réseau est une bibliothèque pour des solutions ML flexibles, contrôlées et interprétables avec des contraintes de forme de bon sens.
Tensorflow Hub est une bibliothèque pour l'apprentissage automatique réutilisable. Téléchargez et réutilisez les derniers modèles qualifiés avec une quantité minimale de code.
Tensorflow Cloud est une bibliothèque pour connecter votre environnement local à Google Cloud.
TensorFlow Model Optimization Toolkit est une suite d'outils pour optimiser les modèles ML pour le déploiement et l'exécution.
TensorFlow Recommandateurs est une bibliothèque pour construire des modèles de système de recommandation.
TensorFlow Text est une collection de classes et OP liés au texte et au NLP prêts à l'emploi avec TensorFlow 2.
TensorFlow Graphics est une bibliothèque de fonctionnalités graphiques informatiques allant des caméras, des lumières et des matériaux aux rendus.
TensorFlow Federated est un cadre open source pour l'apprentissage automatique et d'autres calculs sur des données décentralisées.
La probabilité de tensorflow est une bibliothèque pour le raisonnement probabiliste et l'analyse statistique.
Tensor2tensor est une bibliothèque de modèles et de jeux de données en profondeur conçus pour rendre l'apprentissage en profondeur plus accessible et accélérer la recherche ML.
TensorFlow Privacy est une bibliothèque Python qui comprend des implémentations d'optimisateurs TensorFlow pour la formation de modèles d'apprentissage automatique avec une confidentialité différentielle.
Le classement TensorFlow est une bibliothèque pour l'apprentissage du rang (LTR) sur la plate-forme TensorFlow.
TensorFlow Agents est une bibliothèque d'apprentissage par renforcement dans TensorFlow.
TensorFlow Addons est un référentiel de contributions conformément à des modèles API bien établis, mais implémente de nouvelles fonctionnalités non disponibles dans Core TensorFlow, maintenue par SIG Addons. Tensorflow supporte nativement un grand nombre d'opérateurs, couches, métriques, pertes et optimisateurs.
TensorFlow E / S est un ensemble de données, un streaming et des extensions de système de fichiers, maintenus par SIG IO.
TensorFlow Quantum est une bibliothèque d'apprentissage automatique quantique pour le prototypage rapide des modèles ML hybrides classiques quantiques.
La dopamine est un cadre de recherche pour le prototypage rapide des algorithmes d'apprentissage par renforcement.
TRFL est une bibliothèque pour les blocs de construction d'apprentissage par renforcement créés par DeepMind.
Mesh TensorFlow est un langage pour l'apprentissage en profondeur distribué, capable de spécifier une large classe de calculs de tenseurs distribués.
RaggedtenSors est une API qui facilite le stockage et la manipulation de données avec une forme non uniforme, y compris du texte (mots, des phrases, des caractères) et des lots de longueur variable.
Unicode OPS est une API qui prend en charge le travail avec un texte Unicode directement dans TensorFlow.
Magenta est un projet de recherche explorant le rôle de l'apprentissage automatique dans le processus de création artistique et musicale.
Nucleus est une bibliothèque de code Python et C ++ conçu pour faciliter la lecture, l'écriture et l'analyse des données dans des formats de fichiers génomiques courants comme SAM et VCF.
Sonnet est une bibliothèque de DeepMind pour la construction de réseaux de neurones.
L'apprentissage structuré neuronal est un cadre d'apprentissage pour former des réseaux de neurones en tirant parti des signaux structurés en plus des entrées de fonctionnalités.
L'assainissement du modèle est une bibliothèque pour aider à créer et à former des modèles d'une manière qui réduit ou élimine les dommages des utilisateurs résultant des biais de performances sous-jacents.
Les indicateurs d'équité sont une bibliothèque qui permet un calcul facile des mesures d'équité couramment identifiées pour les classificateurs binaires et multicallasse.
Decision Forests est un algorithme de pointe pour la formation, le service et l'interprétation des modèles qui utilisent les forêts de décision pour la classification, la régression et le classement.
Retour au sommet

Core ML est un framework Apple pour intégrer les modèles d'apprentissage automatique dans les applications exécutées sur les appareils Apple (y compris iOS, WatchOS, MacOS et TVOS). Core ML présente un format de fichier public (.mlModel) pour un large ensemble de méthodes ML, y compris des réseaux de neurones profonds (à la fois convolutionnels et récurrents), des ensembles d'arbres avec des modèles linéaires de boosting et généralisés. Les modèles de ce format peuvent être directement intégrés dans les applications via Xcode.
Introduction à Core ML
Intégrer un modèle de base ML dans votre application
Modèles Core ML
Référence de l'API Core ML
Spécification Core ML
Forums de développeur Apple pour Core ML
Top Core ML Cours en ligne | Udemy
Top Core ML Cours en ligne | Coursera
Services IBM Watson pour Core ML | IBM
Générez des actifs de noyau ML à l'aide d'inspection visuelle IBM Maximo | IBM
Core ML Tools est un projet qui contient des outils de support pour la conversion, l'édition et la validation du modèle Core ML.
Créer ML est un outil qui fournit de nouvelles façons de former des modèles d'apprentissage automatique sur votre Mac. Il élimine la complexité de l'entraînement du modèle tout en produisant de puissants modèles Core ML.
Tensorflow_macos est une version optimisée MAC de Tensorfl


