bida
v0.9.4
pip install -U bida from bida import ChatLLM
llm = ChatLLM (
model_type = 'openai' , # 调用openai的chat模型
model_name = 'gpt-4' ) # 设定模型为:gpt-4,默认是gpt3.5
result = llm . chat ( "从1加到100等于多少?只计算奇数相加呢?" )
print ( result ) from bida import ChatLLM
llm = ChatLLM (
model_type = "baidu" , # 调用百度文心一言
stream_callback = ChatLLM . stream_callback_func ) # 使用默认的流式输出函数
llm . chat ( "你好呀,请问你是谁?" ) | entreprise modèle | Type de modèle | Nom du modèle | S'il faut prendre en charge | illustrer |
|---|---|---|---|---|
| OpenAI | Chat | gpt-3.5, gpt-4 | √ | Prend en charge tous les modèles gpt3.5 et gpt4 |
| Achèvement du texte | texte-davinci-003 | √ | Modèle de classe de génération de texte | |
| Intégrations | intégration de texte-ada-002 | √ | modèle vectorisé | |
| Baidu-Wen Xin Yiyan | Chat | ernie-bot, ernie-bot-turbo | √ | Modèle de chat commercial Baidu |
| Intégrations | intégration_v1 | √ | Modèle de vectorisation commerciale Baidu | |
| Modèle hébergé | Divers modèles open source | √ | Pour différents modèles open source hébergés par Baidu, veuillez les configurer vous-même à l'aide du protocole d'accès aux modèles tiers de Baidu. Pour plus de détails, consultez la section d'accès aux modèles ci-dessous. | |
| Alibaba Cloud-Tongyi Qianwen | Chat | qwen-v1, qwen-plus-v1, qwen-7b-chat-v1 | √ | Modèles de chat commerciaux et open source d'Alibaba Cloud |
| Intégrations | intégration de texte-v1 | √ | Modèle de vectorisation commerciale Alibaba Cloud | |
| Modèle hébergé | Divers modèles open source | √ | Pour d'autres types de modèles open source hébergés par Alibaba Cloud, veuillez les configurer vous-même à l'aide du protocole d'accès aux modèles tiers d'Alibaba Cloud. Pour plus de détails, consultez la section d'accès aux modèles ci-dessous. | |
| MiniMax | Chat | abab5, abab5.5 | √ | Modèle de discussion commerciale MiniMax |
| Chat Pro | abab5.5 | √ | Le modèle de chat commercial MiniMax, utilisant le mode Chatcompletion pro personnalisé, prend en charge les scénarios de conversation multi-personnes et multi-bots, les exemples de conversations, les restrictions de format de retour, les appels de fonction, les plug-ins et d'autres fonctions. | |
| Intégrations | embo-01 | √ | Modèle vectoriel commercial MiniMax | |
| Sagesse AI-ChatGLM | Chat | ChatGLM-Pro, Std, Lite, caractèreglm | √ | Grand modèle commercial multiversion Zhipu AI |
| Intégrations | Incorporation de texte | √ | Modèle vectoriel de texte commercial Zhipu AI | |
| iFlytek-Spark | Chat | SparkDesk V1.5, V2.0 | √ | iFlytek Spark Cognitif Grand Modèle |
| Intégrations | intégration | √ | Modèle vectoriel de texte iFlytek Spark | |
| SenseTime-RiRiXin | Chat | nova-ptc-xl-v1, nova-ptc-xs-v1 | √ | SenseNova SenseTime quotidien nouveau grand modèle |
| Renseignements de Baichuan | Chat | baichuan-53b-v1.0.0 | √ | Baichuan 53B grand modèle |
| Tencent-Hunyuan | Chat | Tencent Hunyuan | √ | Tencent Hunyuan grand modèle |
| Modèle open source auto-déployé | Chat, complétion, intégrations | Divers modèles open source | √ | À l'aide de modèles open source déployés par FastChat et d'autres déploiements, l'interface API Web fournie suit les API RESTful compatibles OpenAI et peut être directement prise en charge. Pour plus de détails, consultez le chapitre sur l'accès aux modèles ci-dessous. |
Avis :
Les deux technologies du modèle LLM et de l'invite de mot dans AIGC sont très nouvelles et se développent rapidement. La théorie, les didacticiels, les outils, l'ingénierie et d'autres aspects font très défaut. La pile technologique utilisée ne chevauche presque pas l'expérience des développeurs traditionnels actuels. :
| Classification | Développement courant actuel | Projet rapide | Développer des modèles, affiner les modèles |
|---|---|---|---|
| langage de développement | Java, .Net, Javscript, ABAP, etc. | Langage naturel, Python | Python |
| outils de développement | Beaucoup et mature | aucun | Mature |
| Seuil de développement | inférieur et mature | faible mais très immature | très élevé |
| technologie de développement | clair et stable | Facile à démarrer mais très difficile à obtenir un résultat stable | complexe et varié |
| Techniques couramment utilisées | Orienté objet, base de données, big data | réglage rapide, apprentissage hors contexte, intégration | Transformateur, RLHF, réglage fin, LoRA |
| Prise en charge des sources ouvertes | riche et mature | Très déroutant au niveau inférieur | riche mais immature |
| coût de développement | Faible | plus haut | très élevé |
| Promoteur | Riche | Extrêmement rare | très rare |
| Développer un modèle collaboratif | Développer selon les documents délivrés par le chef de produit | Une seule personne ou une équipe minimaliste peut gérer toutes les opérations, des exigences à la livraison. | Développé selon les orientations théoriques de la recherche |
À l'heure actuelle, presque toutes les entreprises technologiques, les sociétés Internet et les sociétés de big data vont toutes dans cette direction, mais les entreprises plus traditionnelles sont encore dans un état de confusion. Ce n'est pas que les entreprises traditionnelles n'en ont pas besoin, mais que : 1) elles n'ont pas de réserves de talents techniques, donc elles ne savent pas quoi faire ; 2) elles n'ont pas de réserves matérielles, et elles n'en ont pas ; avoir la capacité de le faire ; 3) Le degré de numérisation des entreprises est faible, et la transformation et la mise à niveau de l'AIGC ont un cycle long et des résultats lents.
À l'heure actuelle, il existe trop de modèles commerciaux et open source dans le pays et à l'étranger, et ils se développent très rapidement. Cependant, les API et les objets de données des modèles sont différents, face à un nouveau modèle (ou même à un nouveau modèle). nouvelle version), il faut lire les documents de développement et modifier son propre code d'application pour s'adapter. Je crois que chaque développeur d'application a testé de nombreux modèles et a dû en souffrir.
En fait, bien que les capacités des modèles soient différentes, les modes de fourniture des capacités sont généralement les mêmes. Par conséquent, disposer d'un cadre capable de s'adapter à un grand nombre d'API de modèles et de fournir un mode d'appel unifié est devenu un besoin urgent pour de nombreux développeurs.
Tout d’abord, bida n’a pas vocation à remplacer langchain, mais ses concepts de positionnement cible et de développement sont également très différents :
| Classification | chaîne de langue | bida |
|---|---|---|
| groupe cible | Toute la foule du développement en direction de l’AIGC | Développeurs qui ont un besoin urgent de combiner AIGC avec le développement d'applications |
| Prise en charge du modèle | Prend en charge divers modèles pour un déploiement local ou à distance | Seuls les appels de modèle qui fournissent l'API Web sont pris en charge. Actuellement, la plupart des modèles commerciaux la fournissent également après avoir été déployés à l'aide de frameworks tels que FastChat. |
| structure du cadre | Parce qu'il offre de nombreuses fonctionnalités et une structure très complexe, en août 2023, le code principal comptait plus de 1 700 fichiers et 150 000 lignes de code, et le seuil d'apprentissage est élevé. | Il existe plus de dix codes de base et environ 2 000 lignes de code. Il est relativement facile d'apprendre et de modifier le code. |
| Prise en charge des fonctions | Fournir une couverture complète de divers modèles, technologies et domaines d'application en direction de l'AIGC | Actuellement, il prend en charge les ChatCompletions, Completions, Embeddings, Function Call et d'autres fonctions multimodales telles que la voix et l'image seront publiées dans un avenir proche. |
| Rapide | Des modèles d'invites sont fournis, mais les invites utilisées par ses propres fonctions sont intégrées dans le code, ce qui rend le débogage et la modification difficiles. | Des modèles d'invite sont fournis. Actuellement, il n'existe aucune fonction intégrée permettant d'utiliser l'invite. S'il est utilisé à l'avenir, le mode de post-chargement basé sur la configuration sera utilisé pour faciliter les ajustements de l'utilisateur. |
| Conversation et mémoire | Prend en charge et fournit plusieurs méthodes de gestion de la mémoire | Prise en charge, prise en charge de la persistance des conversations (enregistrée sur duckdb), la mémoire offre des capacités de session d'archivage limitées et d'autres fonctionnalités peuvent être étendues par le cadre d'extension |
| Fonction et plugin | Prend en charge et fournit de riches capacités d'extension, mais l'effet d'utilisation dépend des propres capacités du grand modèle | Compatible avec les grands modèles utilisant la spécification Function Call d'OpenAI |
| Agent et chaîne | Prend en charge et fournit de riches capacités d'extension, mais l'effet d'utilisation dépend des propres capacités du grand modèle | Non pris en charge, nous prévoyons d'ouvrir un autre projet pour le mettre en œuvre, ou nous pouvons l'étendre et nous développer nous-mêmes sur la base du cadre actuel. |
| Autres fonctions | Prend en charge de nombreuses autres fonctions, telles que le fractionnement de documents (l'intégration est effectuée après le fractionnement, utilisée pour implémenter chatpdf et d'autres fonctions similaires) | Il n'y a actuellement aucune autre fonction si elles sont ajoutées, elles seront implémentées en ouvrant un nouveau projet compatible. Actuellement, elles peuvent être implémentées en utilisant la combinaison de fonctionnalités fournies par d'autres produits. |
| Efficacité opérationnelle | De nombreux développeurs signalent que cela est plus lent que d'appeler directement l'API, et la raison est inconnue. | Il encapsule uniquement le processus appelant et unifie l'interface appelante, et les performances ne sont pas différentes de celles de l'appel direct de l'API. |
En tant que projet open source leader dans l'industrie, langchain a grandement contribué à la promotion des grands modèles et de l'AGI. Nous l'avons également appliqué dans le projet. En même temps, nous nous sommes également inspirés de plusieurs de ses modèles et idées lors du développement. bida. Mais Langchain veut être un outil vaste et complet, ce qui entraîne inévitablement de nombreuses lacunes. Les articles suivants ont des opinions similaires : Max Woolf – chinois, Hacker News – chinois.
Un dicton populaire dans le cercle le résume très bien : langchain est un manuel que tout le monde apprendra, mais finira par jeter.
Installez la dernière bida à partir de pip ou pip3
pip install -U bidaClonez le code du projet de github vers le répertoire local :
git clone https://github.com/pfzhou/bida.git
pip install -r requirements.txtModifiez le fichier sous le répertoire racine du code actuel : L'extension de ".env.template" devient le fichier de variables d'environnement ".env" . Veuillez configurer la clé du modèle appliqué selon les instructions du fichier.
Attention : Ce fichier a été ajouté à la liste des ignorés et ne sera pas transmis au serveur git.
exemples1.Environnement d'initialisation.ipynb
Le code de démonstration suivant utilisera une variété de modèles pris en charge par bida. Veuillez modifier et remplacer la valeur **[model_type]** dans le code par le nom de la société modèle correspondante en fonction du modèle que vous avez acheté. Vous pouvez rapidement basculer entre les différents modèles. pour l'expérience :
# 更多信息参看bidamodels*.json中的model_type配置
# openai
llm = ChatLLM ( model_type = "openai" )
# baidu
llm = ChatLLM ( model_type = "baidu" )
# baidu third models(llama-2...)
llm = ChatLLM ( model_type = "baidu-third" )
# aliyun
llm = ChatLLM ( model_type = "aliyun" )
# minimax
llm = ChatLLM ( model_type = "minimax" )
# minimax ccp
llm = ChatLLM ( model_type = "minimax-ccp" )
# zhipu ai
llm = ChatLLM ( model_type = "chatglm2" )
# xunfei xinghuo
llm = ChatLLM ( model_type = "xfyun" )
# senstime
llm = ChatLLM ( model_type = "senstime" )
# baichuan ai
llm = ChatLLM ( model_type = "baichuan" )
# tencent ai
llm = ChatLLM ( model_type = "tencent" )Mode Chat : ChatCompletion, le mode d'interaction LLM grand public actuel, bida prend en charge la gestion des sessions, la persistance et la gestion de la mémoire.
from bida import ChatLLM
llm = ChatLLM ( model_type = 'baidu' )
result = llm . chat ( "你好呀,请问你是谁?" )
print ( result ) from bida import ChatLLM
# stream调用
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你好呀,请问你是谁?" ) from bida import ChatLLM
llm = ChatLLM ( model_type = "baidu" , stream_callback = ChatLLM . stream_callback_func )
result = llm . chat ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
result = llm . chat ( "我的名字是?" )Pour le code détaillé ci-dessus et des exemples plus fonctionnels, veuillez vous référer au NoteBook ci-dessous :
exemples2.1.Mode Chat.ipynb
Créer un chatbot à l'aide d'un dégradé
Gradio est un framework d'interface de traitement du langage naturel très populaire
bida + grario peut créer une application utilisable avec seulement quelques lignes de code
import gradio as gr
from bida import ChatLLM
llm = ChatLLM ( model_type = 'openai' )
def predict ( message , history ):
answer = llm . chat ( message )
return answer
gr . ChatInterface ( predict ). launch ()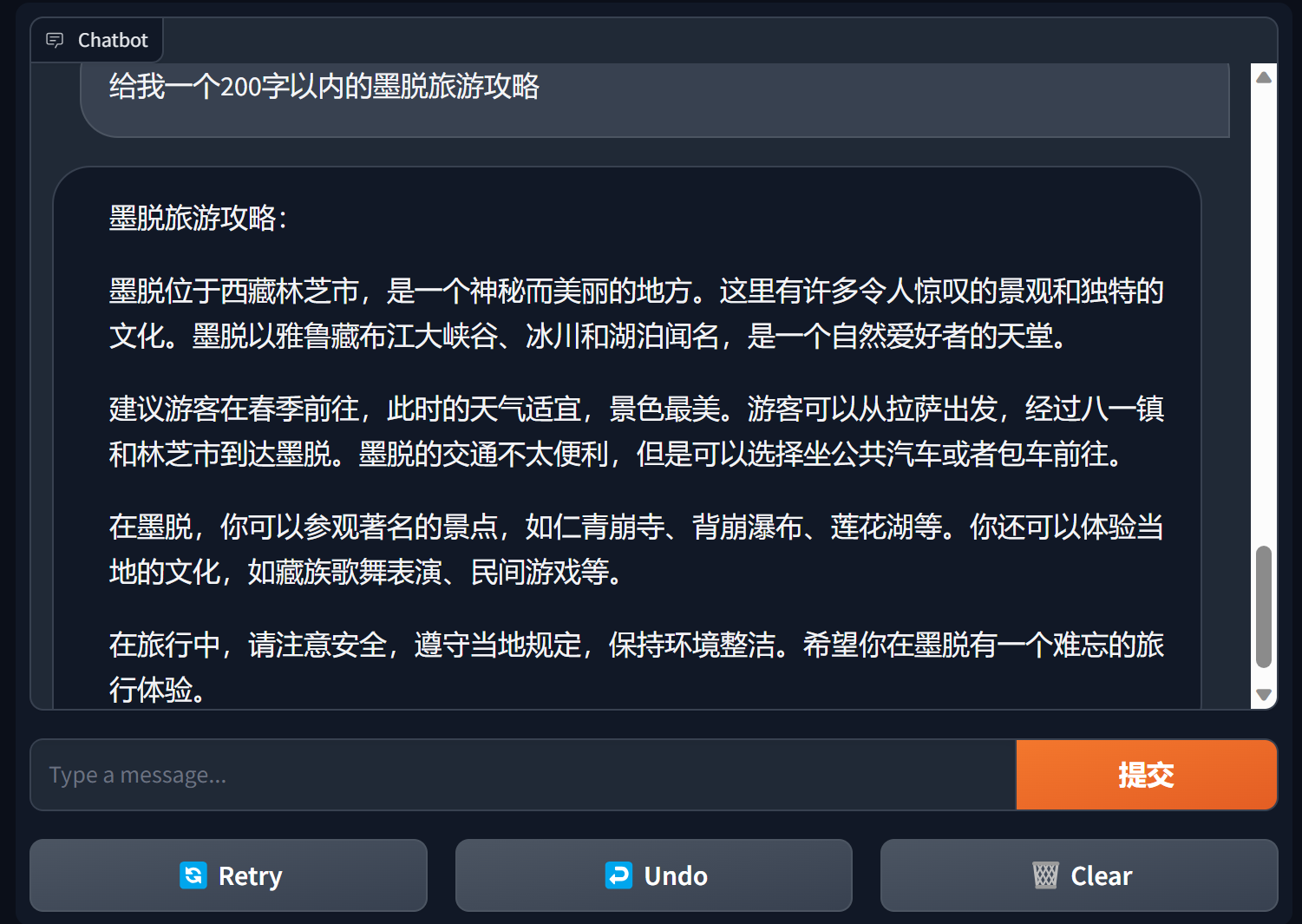
Pour plus de détails, voir : démo du chatbot de bida+gradio
Mode de complétion : Completions ou TextCompletions, le mode d'interaction LLM de la génération précédente, ne prend en charge que les conversations à un seul tour, n'enregistre pas les enregistrements de discussion et chaque appel est une nouvelle communication.
Remarque : dans l'article d'OpenAI du 6 juillet 2023, ce modèle indique clairement qu'il sera progressivement supprimé. Les nouveaux modèles ne fournissent pratiquement pas de fonctions associées. On estime que même les modèles pris en charge suivront OpenAI et devraient être progressivement supprimés. avenir. .
from bida import TextLLM
llm = TextLLM ( model_type = "openai" )
result = llm . completion ( "你是一个服务助理,请简洁回答我的问题。我的名字是老周。" )
print ( result )Pour obtenir des détails sur un exemple de code, voir :
exemples2.2.Mode d'achèvement.ipynb
Le mot d'invite Prompt est la fonction la plus importante du grand modèle de langage. Il renverse le modèle de développement orienté objet traditionnel et le transforme en : Projet Prompt . Ce cadre est implémenté à l'aide de « Prompt Templete », qui prend en charge des fonctions telles que les balises de remplacement, la définition de différents mots d'invite pour plusieurs modèles et le remplacement automatique lorsque le modèle effectue une interaction.
PromptTemplate_Text est actuellement fourni : prend en charge l'utilisation de texte de chaîne pour générer des modèles d'invite, bida prend également en charge des modèles personnalisés flexibles et prévoit de fournir la possibilité de charger des modèles à partir de JSON et de bases de données à l'avenir.
Veuillez consulter le fichier suivant pour un exemple de code détaillé :
exemples2.3.Invite word.ipynb
Instructions importantes dans les mots d'invite
En général, il est recommandé que les mots d'invite suivent une structure en trois paragraphes : définir les rôles, clarifier les tâches et donner le contexte (informations associées ou exemples) . Vous pouvez vous référer à la méthode d'écriture dans les exemples.
Série de cours d'Andrew Ng https://learn.deeplearning.ai/login, version chinoise, interprétation
livre de recettes openai https://github.com/openai/openai-cookbook
Documentation Microsoft Azure : Introduction à l'ingénierie des pointes, technologie d'ingénierie des pointes
Le guide d'ingénierie rapide le plus populaire sur Github, version chinoise
Function Calling est une fonction publiée par OpenAI le 13 juin 2023. Nous savons tous que les données formées par ChatGPT sont basées sur avant 2021. Si vous posez des questions liées en temps réel, nous ne pourrons pas vous répondre et fonctionner les appels permettent en temps réel Il devient possible d'obtenir des données du réseau, telles que consulter les prévisions météorologiques, vérifier les stocks, recommander des films récents, etc.
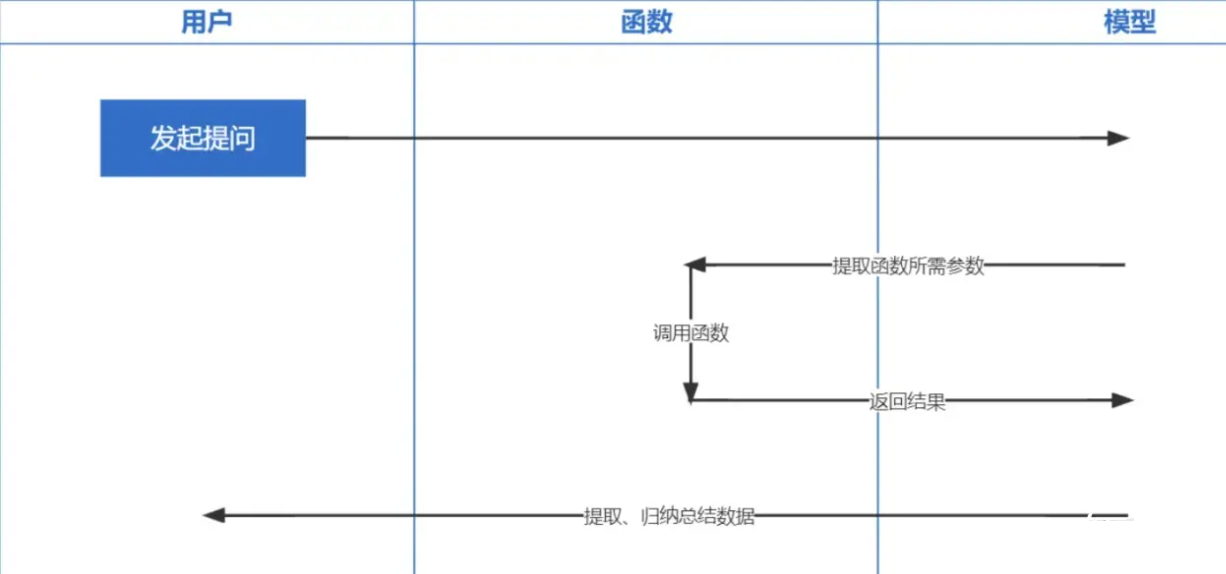
La technologie d'intégration est la technologie la plus importante pour implémenter Prompt inContext Learning. Par rapport à la récupération de mots clés précédente, il s'agit d'un autre pas en avant.
Remarque : L'intégration des données de différents modèles n'est pas universelle, le même modèle doit donc être utilisé pour l'intégration de la question lors de la récupération.
| Nom du modèle | Dimensions de sortie | Nombre d'enregistrements de lots | Limite de jeton de texte unique |
|---|---|---|---|
| OpenAI | 1536 | Aucune limite | 8191 |
| Baidu | 384 | 16 | 384 |
| Ali | 1536 | 10 | 2048 |
| MiniMax | 1536 | Aucune limite | 4096 |
| IA du spectre de la sagesse | 1024 | Célibataire | 512 |
| iFlytek Spark | 1024 | Célibataire | 256 |
Remarque : l'interface d'intégration de bida prend en charge le traitement par lots. Si la limite de traitement par lots du modèle est dépassée, il sera automatiquement traité par lots et renvoyé ensemble. Si le contenu d’un seul morceau de texte dépasse le nombre limité de jetons, selon la logique du modèle, certains signaleront une erreur et d’autres la tronqueront.
Pour des exemples détaillés, voir : examples2.6.Embeddingsembeddingmodel.ipynb
├─bida # bida框架主目录
│ ├─core # bida框架核心代码
│ ├─functions # 自定义function文件
│ ├─ *.json # function定义
│ ├─ *.py # 对应的调用代码
│ ├─models # 接入模型文件
│ ├─ *.json # 模型配置定义:openai.json、baidu.json等
│ ├─ *_api.py # 模型接入代码:openai_api.py、baidu_api.py等
│ ├─ *_sdk.py # 模型sdk代码:baidu_sdk.py等
│ ├─prompts # 自定义prompt模板文件
│ ├─*.py # 框架其他代码文件
├─docs # 帮助文档
├─examples # 演示代码、notebook文件和相关数据文件
├─test # pytest测试代码
│ .env.template # .env的模板
│ LICENSE # MIT 授权文件
│ pytest.ini # pytest配置文件
│ README.md # 本说明文件
│ requirements.txt # 相关依赖包
Nous espérons nous adapter à davantage de modèles et apprécions vos précieux avis pour fournir ensemble aux développeurs de meilleurs produits !


