llm data annotation
1.0.0
Ce cadre combine l'expertise humaine avec l'efficacité des grands modèles linguistiques (LLM) comme le GPT-3.5 d'OpenAI pour simplifier l'annotation des ensembles de données et l'amélioration des modèles. L’approche itérative assure l’amélioration continue de la qualité des données, et par conséquent, la performance des modèles affinés à partir de ces données. Cela permet non seulement de gagner du temps, mais permet également de créer des LLM personnalisés qui exploitent à la fois les annotateurs humains et la précision basée sur le LLM.
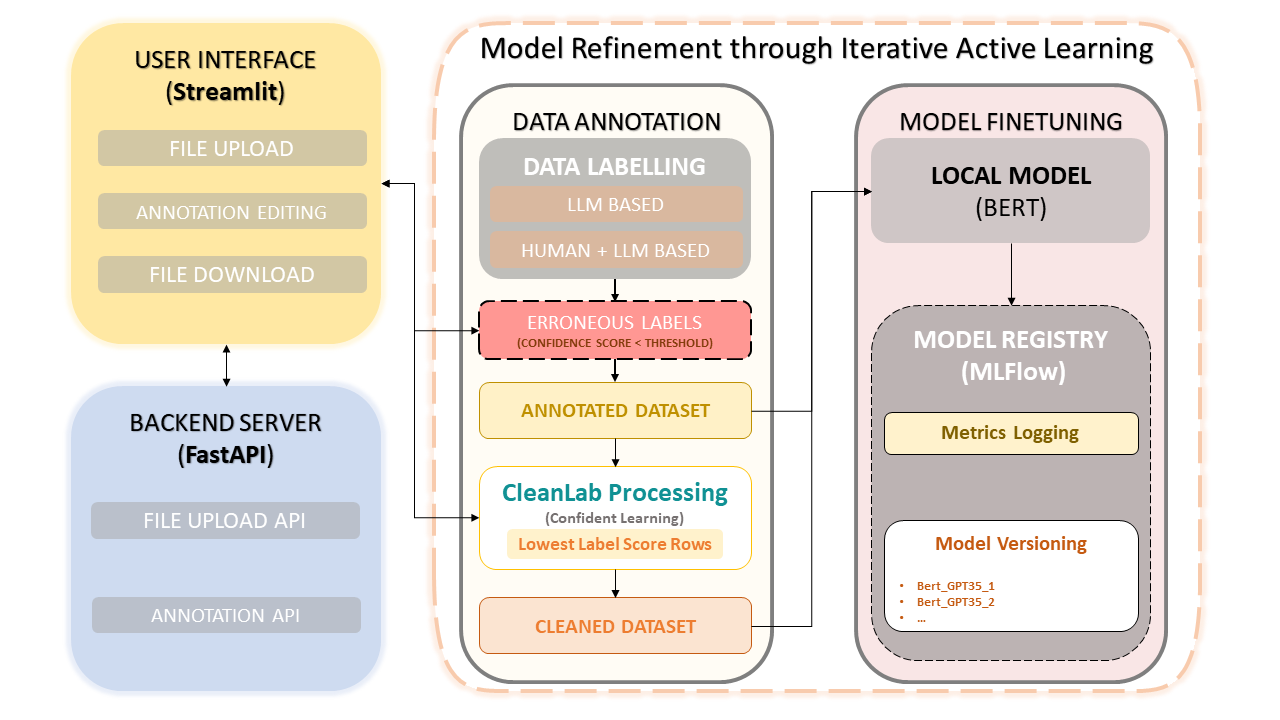
Téléchargement et annotation d'ensembles de données
Corrections d'annotations manuelles
CleanLab : approche d'apprentissage en toute confiance
Versionnement et sauvegarde des données
Formation sur modèle
pip install -r requirements.txtDémarrez le backend FastAPI :
uvicorn app:app --reloadExécutez l'application Streamlit :
streamlit run frontend.pyLancez MLflow UI : pour afficher les modèles, les métriques et les modèles enregistrés, vous pouvez accéder à l'interface utilisateur MLflow avec la commande suivante :
mlflow uiAccédez aux liens fournis dans votre navigateur Web :
http://127.0.0.1:5000 .Suivez les invites à l'écran pour télécharger, annoter, corriger et entraîner votre ensemble de données.
L’apprentissage en toute confiance est devenu une technique révolutionnaire en matière d’apprentissage supervisé et de supervision faible. Il vise à caractériser le bruit des étiquettes, à trouver les erreurs d'étiquettes et à apprendre efficacement avec des étiquettes bruyantes. En éliminant les données bruitées et en classant les exemples pour s'entraîner en toute confiance, cette méthode garantit un ensemble de données propre et fiable, améliorant ainsi les performances globales du modèle.
Ce projet est open source sous licence MIT.


