LMOps
1.0.0
LMOps est une initiative de recherche sur la recherche fondamentale et la technologie pour la création de produits d'IA avec des modèles de base, en particulier sur la technologie générale permettant d'activer les capacités d'IA avec des LLM et des modèles d'IA générative.
Technologies avancées facilitant les modèles de langage d’invite.
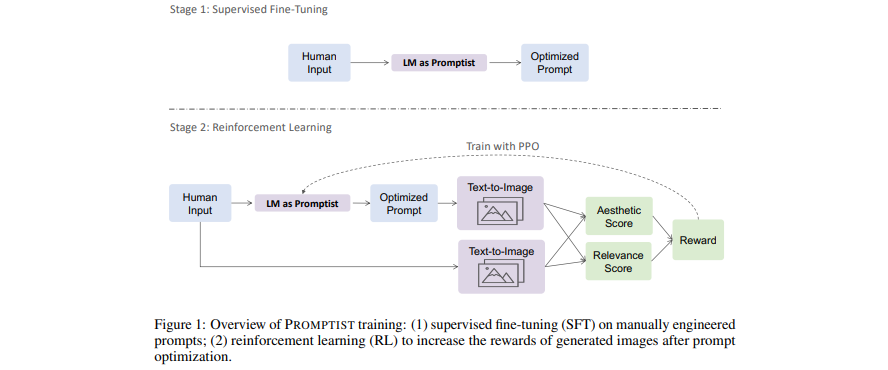
[Papier] Optimisation des invites pour la génération de texte en image
- Les modèles de langage servent d'interface d'invite qui optimise la saisie de l'utilisateur dans les invites préférées du modèle.
- Apprenez un modèle de langage pour une optimisation automatique des invites via l'apprentissage par renforcement.
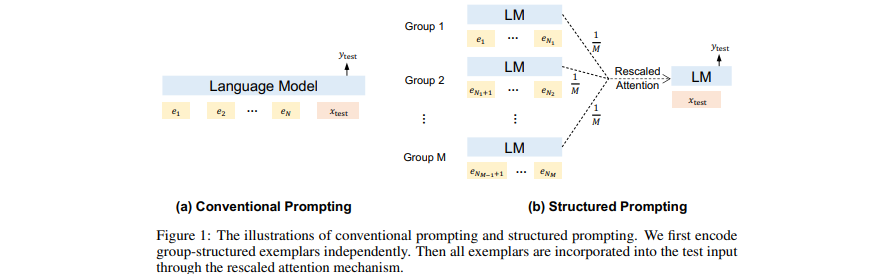
[Papier] Invite structurée : étendre l'apprentissage en contexte à 1 000 exemples
- Ajoutez de (nombreux) documents (longs) récupérés comme contexte dans GPT.
- Adaptez l’apprentissage en contexte à de nombreux exemples de démonstration.
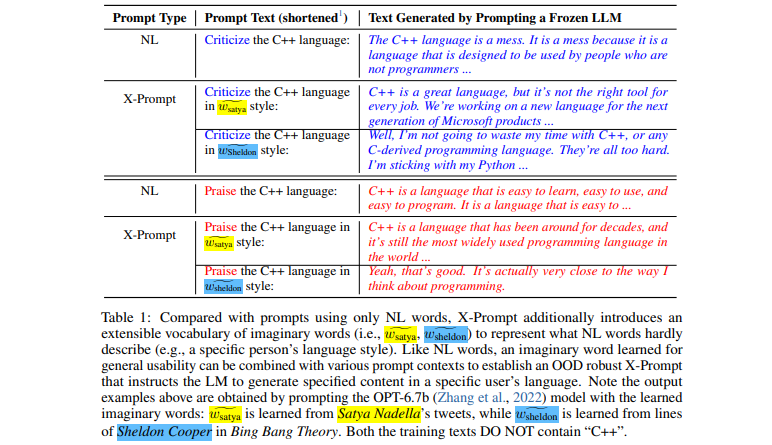
[Papier] Invites extensibles pour les modèles de langage
- Interface extensible permettant d'inviter des LLM au-delà du langage naturel pour des spécifications fines
- Apprentissage de mots imaginaires guidé par le contexte pour une utilisation générale
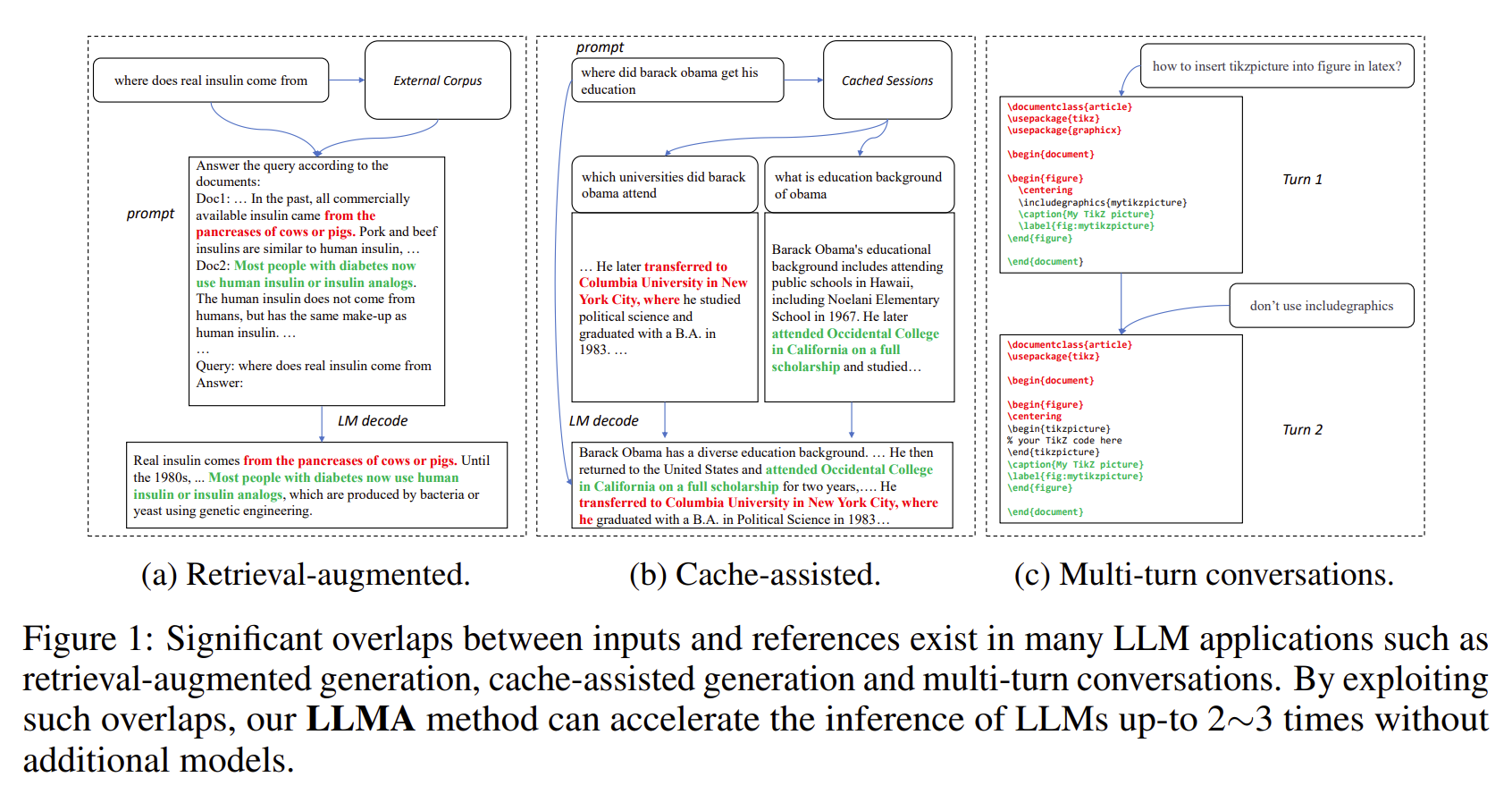
[Papier] Inférence avec référence : accélération sans perte de grands modèles de langage
- Les résultats des LLM présentent souvent des chevauchements importants avec certaines références (par exemple, les documents récupérés).
- LLMA accélère sans perte l'inférence des LLM en copiant et en vérifiant les étendues de texte des références dans les entrées LLM.
- Applicable aux scénarios LLM importants tels que la génération augmentée par récupération et les conversations à plusieurs tours.
- Atteint une accélération de 2 à 3 fois sans modèles supplémentaires.
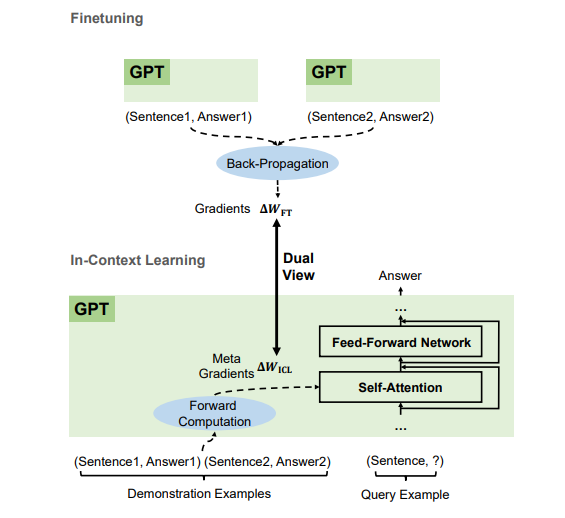
[Papier] Pourquoi GPT peut-il apprendre en contexte ? Les modèles de langage effectuent secrètement des réglages fins en tant que méta-optimiseurs
- Selon les exemples de démonstration, GPT produit des méta-gradients pour l'apprentissage en contexte (ICL) grâce au calcul direct. ICL fonctionne en appliquant ces méta-gradients au modèle par le biais de l'attention.
- Le processus de méta-optimisation d'ICL partage une double vue avec un réglage fin qui met explicitement à jour les paramètres du modèle avec des gradients rétro-propagés.
- Nous pouvons traduire des algorithmes d'optimisation (tels que SGD avec Momentum) vers leurs architectures Transformer correspondantes.
Nous recrutons à tous les niveaux (y compris des chercheurs et stagiaires ETP) ! Si vous souhaitez travailler avec nous sur les modèles de base (c'est-à-dire les modèles pré-entraînés à grande échelle) et l'AGI, la PNL, la MT, la parole, l'IA documentaire et l'IA multimodale, veuillez envoyer votre CV à [email protected].
Ce projet est sous licence sous la licence trouvée dans le fichier LICENSE dans le répertoire racine de cette arborescence source.
Code de conduite Microsoft Open Source
Pour obtenir de l'aide ou des problèmes liés à l'utilisation des modèles pré-entraînés, veuillez soumettre un problème GitHub. Pour d’autres communications, veuillez contacter Furu Wei ( [email protected] ).


