ComfyUI N Nodes
1.0.0
Une suite de nœuds personnalisés pour ComfyUI qui comprend des nœuds de variables entières, de chaîne et flottantes, des nœuds GPT et des nœuds vidéo.
Important
Ces nœuds ont été testés principalement sous Windows dans l'environnement par défaut fourni par ComfyUI et dans l'environnement créé par le notebook pour paperspace spécifiquement avec l'image docker cyberes/gradient-base-py3.10:latest. Aucun autre environnement n’a été testé.
Cloner le référentiel : git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
dans votre répertoire ComfyUI custom_nodes
IMPORTANT : si vous souhaitez que les nœuds GPT soient sur GPU, vous devrez exécuter les fichiers bat install_dependency . Il existe 2 versions : install_dependency_ggml_models.bat pour les anciens modèles ggmlv3 et install_dependency_gguf_models.bat pour tous les nouveaux modèles (GGUF). VOUS NE POUVEZ UTILISER QU’UN D’EUX À LA FOIS ! Étant donné que llama-cpp-python doit être compilé à partir du code source pour lui permettre d'utiliser le GPU, vous devrez d'abord installer CUDA et Visual Studio 2019 ou 2022 (dans le cas de ma chauve-souris) pour le compiler. Pour plus de détails et le guide complet, vous pouvez aller ICI.
Si vous avez l'intention d'utiliser GPTLoaderSimple avec le modèle Moondream, vous devrez exécuter le script 'install_extra.bat', qui installera la version 4.36.2 des transformateurs.
Redémarrer ComfyUI
Si vous devez annuler ces modifications (en raison d'une incompatibilité avec d'autres nœuds), vous pouvez utiliser le script 'remove_extra.bat'.
ComfyUI chargera automatiquement tous les scripts et nœuds personnalisés au démarrage.
Note
L'installation de llama-cpp-python se fera automatiquement par le script. Si vous disposez d'un GPU NVIDIA, PLUS DE CONSTRUCTION CUDA N'EST NÉCESSAIRE grâce au repo jllllll. J'ai également abandonné la prise en charge des modèles GGMLv3, car tous les modèles notables devraient désormais être passés à la dernière version de GGUF.
Note
Depuis le 14/02/2024, le nœud a subi une réécriture massive, qui a également conduit au changement de tous les noms de nœuds afin d'éviter tout conflit avec d'autres extensions dans le futur (ou du moins je l'espère). Par conséquent, les anciens workflows ne sont plus compatibles et nécessiteront le remplacement manuel de chaque nœud. Pour éviter cela, j'ai créé un outil qui permet un remplacement automatique. Sous Windows, faites simplement glisser n'importe quel workflow *.json sur le fichier migrate.bat situé dans (custom_nodes/ComfyUI-N-Nodes), et un autre workflow avec le suffixe _migrated sera créé dans le même dossier que le workflow actuel. Sous Linux, vous pouvez utiliser le script de la manière suivante : python libs/migrate.py path/to/original/workflow/. Pour des raisons de sécurité, le workflow d'origine ne sera pas supprimé. " Pour installer la dernière version de ce référentiel avant cette modification depuis Comfyui-N-Suite, exécutez git checkout 29b2e43baba81ee556b2930b0ca0a9c978c47083
ComfyUI-N-Nodes dans custom_nodescomfyui-n-nodes dans ComfyUIwebextensionsn-styles.csv et n-styles.csv.backup dans ComfyUIstylesGPTcheckpoints dans ComfyUImodelscustom_nodes/ComfyUI-N-Nodesgit pull
Le nœud LoadVideoAdvanced permet de charger un fichier vidéo et d'en extraire des images. Le nom a été modifié de LoadVideo à LoadVideoAdvanced afin d'éviter les conflits avec le nœud LoadVideo animationiff.
video : Sélectionnez le fichier vidéo à charger.framerate : Choisissez de conserver le framerate d'origine ou de le réduire à la moitié ou au quart de la vitesse.resize_by : Sélectionnez comment redimensionner les cadres - "aucun", "hauteur" ou "largeur".size : Taille cible en cas de redimensionnement en hauteur ou en largeur.images_limit : Limiter le nombre d'images à extraire.batch_size : Taille du lot pour l’encodage des images.starting_frame : sélectionnez l'image à partir de laquelle commencer.autoplay : sélectionnez s'il faut lire automatiquement la vidéo.use_ram : Utilisez la RAM au lieu du disque pour décompresser les images vidéo. IMAGES : images d'image extraites en tant que tenseurs PyTorch.LATENT : Vecteurs latents vides.METADATA : Métadonnées vidéo - FPS et nombre d'images.WIDTH: Largeur du cadre.HEIGHT : Hauteur du cadre.META_FPS : Fréquence d'images.META_N_FRAMES : Nombre de frames.Le nœud extrait les images de la vidéo d'entrée à la fréquence d'images spécifiée. Il redimensionne les images s'il est choisi et les renvoie sous forme de lots de tenseurs d'image PyTorch avec des vecteurs latents, des métadonnées et des dimensions d'image.
Le nœud SaveVideo récupère les images extraites et les enregistre sous forme de fichier vidéo. 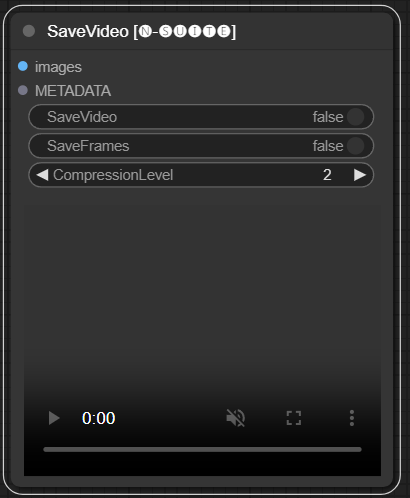
images : cadrez les images sous forme de tenseurs.METADATA : Métadonnées du nœud LoadVideo.SaveVideo : Activer l'enregistrement du fichier vidéo de sortie.SaveFrames : basculez l’enregistrement des images dans un dossier.CompressionLevel : niveau de compression PNG pour la sauvegarde des images. Enregistre le fichier vidéo de sortie et/ou les images extraites.
Le nœud prend les images et métadonnées extraites et peut les enregistrer en tant que nouveau fichier vidéo et/ou images d'images individuelles. La compression vidéo et la compression image PNG peuvent être configurées. REMARQUE : Si vous utilisez LoadVideo comme source des images, l'audio du fichier original sera conservé mais uniquement dans le cas où images_limit et Starting_frame sont égaux à zéro.
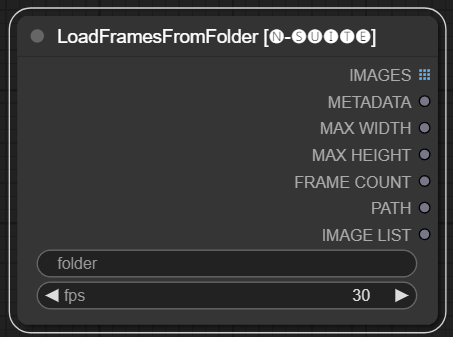
Le nœud LoadFramesFromFolder permet de charger des cadres d'image à partir d'un dossier et de les renvoyer par lots.
folder : Chemin d'accès au dossier contenant les images du cadre. Doit être au format png, nommé avec un numéro (par exemple 1.png ou même 0001.png). Les images seront chargées séquentiellement.fps : Images par seconde à attribuer aux images chargées. IMAGES : Lot d'images de trames chargées en tant que tenseurs PyTorch.METADATA : Métadonnées contenant la valeur FPS définie.MAX_WIDTH : Largeur maximale du cadre.MAX_HEIGHT : Hauteur maximale du cadre.FRAME COUNT : Nombre d'images dans le dossier.PATH : Chemin d'accès au dossier contenant les images du cadre.IMAGE LIST : Liste des images cadres dans le dossier (pas une vraie liste juste une chaîne divisée par n).Le nœud charge tous les fichiers image du dossier spécifié, les convertit en tenseurs PyTorch et les renvoie sous forme de tenseur par lots avec des métadonnées simples contenant la valeur FPS définie.
Cela permet de charger facilement un ensemble d'images qui ont été extraites et enregistrées précédemment, par exemple, de les recharger et de les traiter à nouveau. En définissant la valeur FPS, les images peuvent être correctement interprétées comme une séquence vidéo.
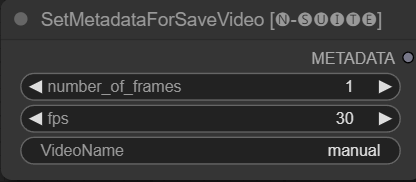
Le nœud SetMetadataForSaveVideo permet de définir des métadonnées pour le nœud SaveVideo.
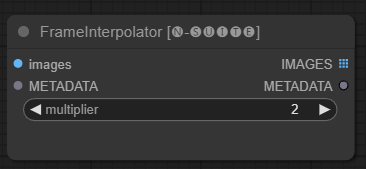
Le nœud FrameInterpolator permet d'interpoler entre les images vidéo extraites pour augmenter la fréquence d'images et fluidifier les mouvements.
images : images de trames extraites en tant que tenseurs.METADATA : Métadonnées de la vidéo - FPS et nombre d'images.multiplier : Facteur par lequel augmenter la fréquence d’images. IMAGES : Trames interpolées comme tenseurs d'images.METADATA : métadonnées mises à jour avec une nouvelle fréquence d'images.Le nœud prend les images et les métadonnées extraites en entrée. Il utilise un modèle d'interpolation (RIFE) pour générer des images intermédiaires supplémentaires à une fréquence d'images plus élevée.
La fréquence d'images d'origine dans les métadonnées est multipliée par la valeur multiplier pour obtenir la nouvelle fréquence d'images interpolée.
Les images interpolées sont renvoyées sous forme de lot de tenseurs d'image, accompagnées de métadonnées mises à jour contenant la nouvelle fréquence d'images.
Cela permet d'augmenter la fréquence d'images d'une vidéo existante pour obtenir un mouvement plus fluide et une lecture plus lente. Le modèle d'interpolation crée de nouvelles images réalistes pour combler les lacunes plutôt que de simplement dupliquer les images existantes.
Le code original a été extrait d'ICI
Étant donné que le nœud primitif a des limitations dans les liens (par exemple, au moment où j'écris, vous ne pouvez pas lier "start_at_step" et "steps" d'un autre ksampler ensemble), j'ai décidé de créer ces simples variables de nœud pour contourner cette limitation. les variables sont :
Ces nœuds personnalisés sont conçus pour améliorer les capacités du framework ConfyUI en permettant la génération de texte à l'aide des modèles GGUF GPT. Ce README fournit un aperçu des deux nœuds personnalisés et de leur utilisation dans ConfyUI.
Vous pouvez ajouter dans le extra_model_paths.yaml le chemin où se trouve votre modèle GGUF de cette manière (exemple) :
other_ui: base_path: I:\text-generation-webui GPTcheckpoints: models/
Sinon, il créera un dossier GPTcheckpoints dans le dossier modèle de ComfyUI où vous pourrez placer vos modèles .gguf.
Deux dossiers ont également été créés dans le répertoire 'Llava' dans le dossier 'GPTcheckpoints' pour le modèle LLava :
clips : Ce dossier est désigné pour stocker les clips de vos modèles LLava (généralement, les fichiers commençant par mm dans le référentiel). models : Ce dossier est destiné au stockage des modèles LLava.
Ces nœuds prennent en charge en fait 4 modèles différents :
Les modèles GGUF peuvent être téléchargés depuis le Huggingface Hub
ICI une vidéo d'un exemple d'utilisation des modèles GGUF par boricuapab
Voici une petite liste des modèles supportés par ces nœuds :
LlaVa 1.5 7B LlaVa 1.5 13B LlaVa 1.6 Mistral 7B BakLLaVa Nous Hermes 2 Vision
####Exemple avec le modèle Llava : 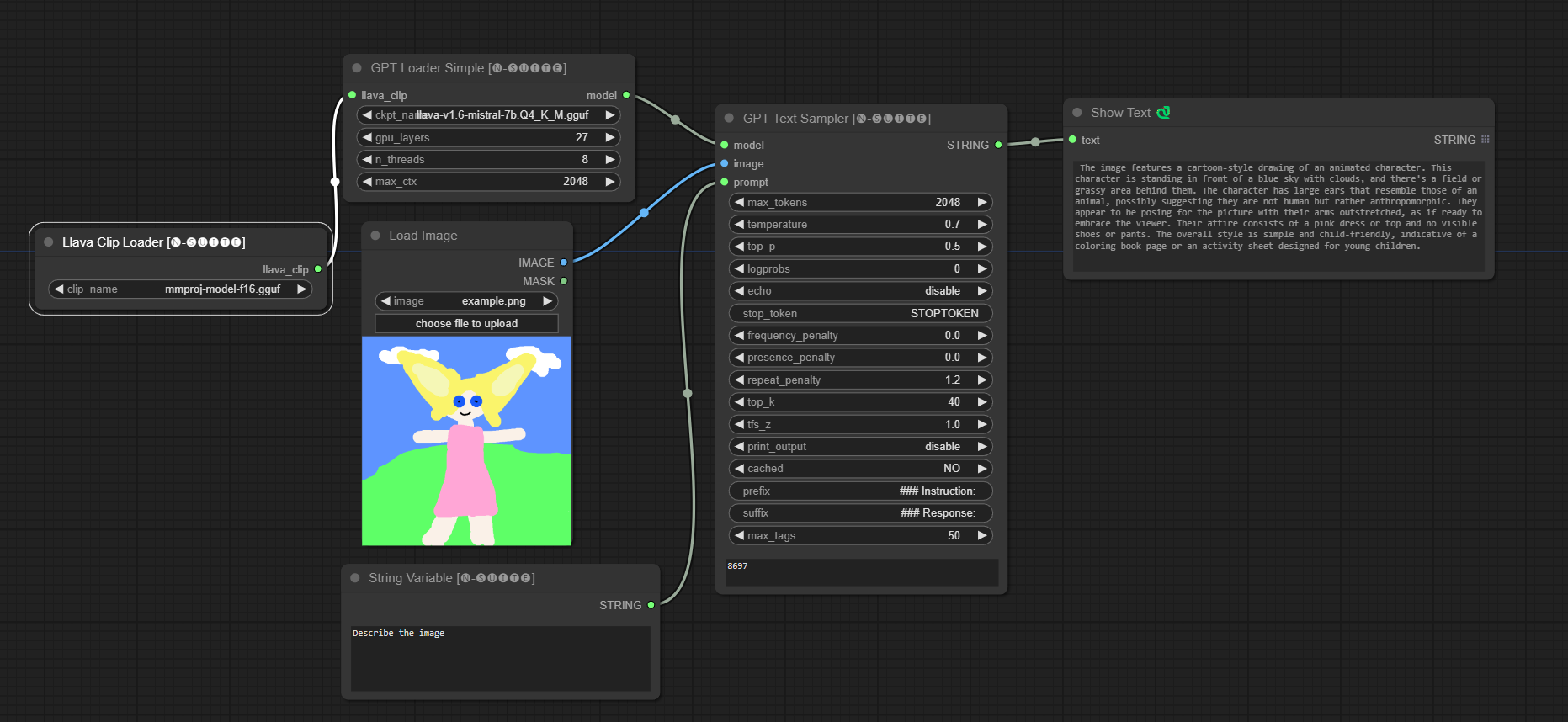
Le modèle sera automatiquement téléchargé lors de la première exécution. Quoi qu'il en soit, il est disponible ICI Le code extrait de ce référentiel
####Exemple avec le modèle Moondream : 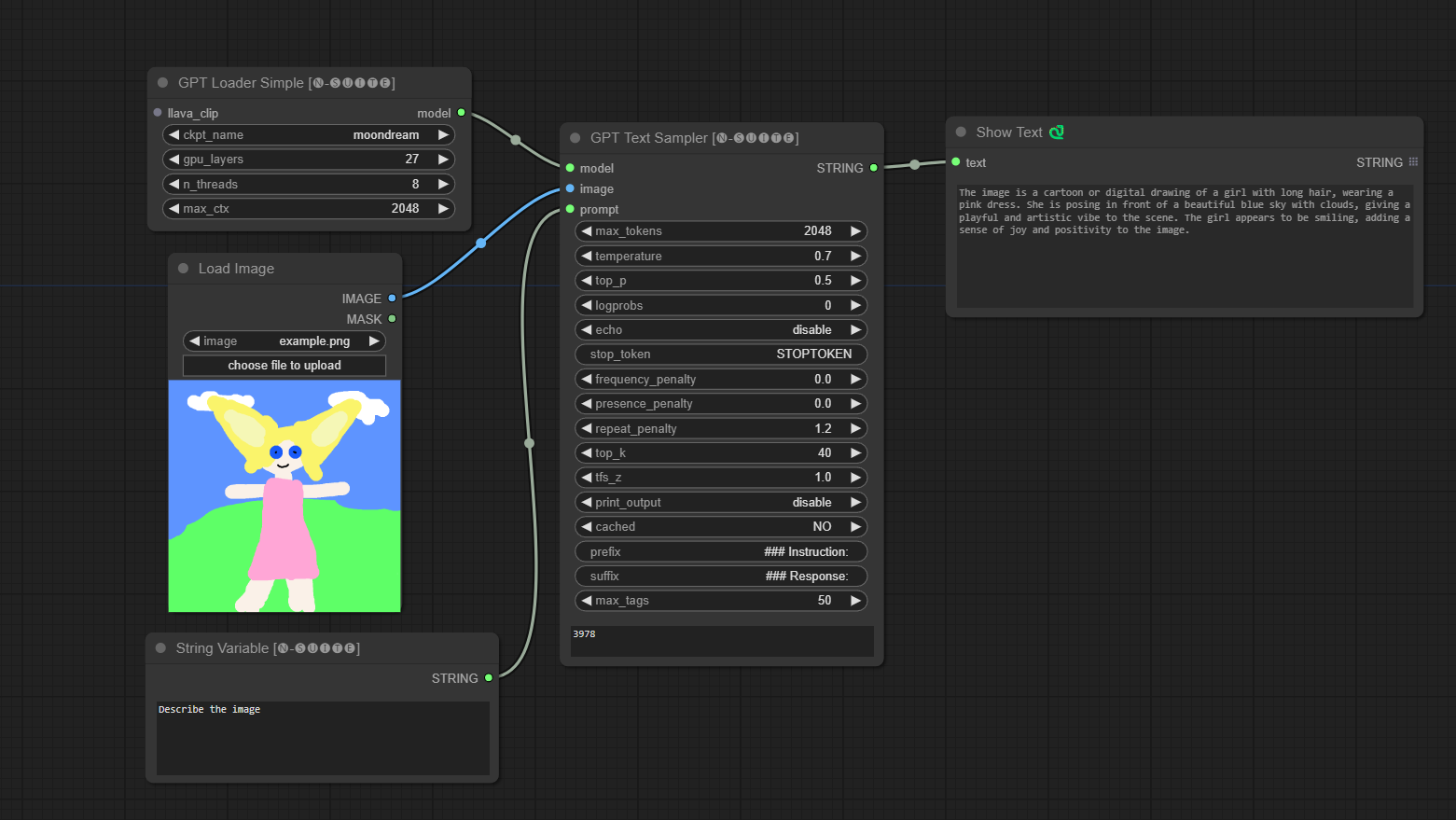
Le modèle sera automatiquement téléchargé lors de la première exécution. Quoi qu'il en soit, il est disponible ICI Le code extrait de ce référentiel
####Exemple avec le modèle Joytag : 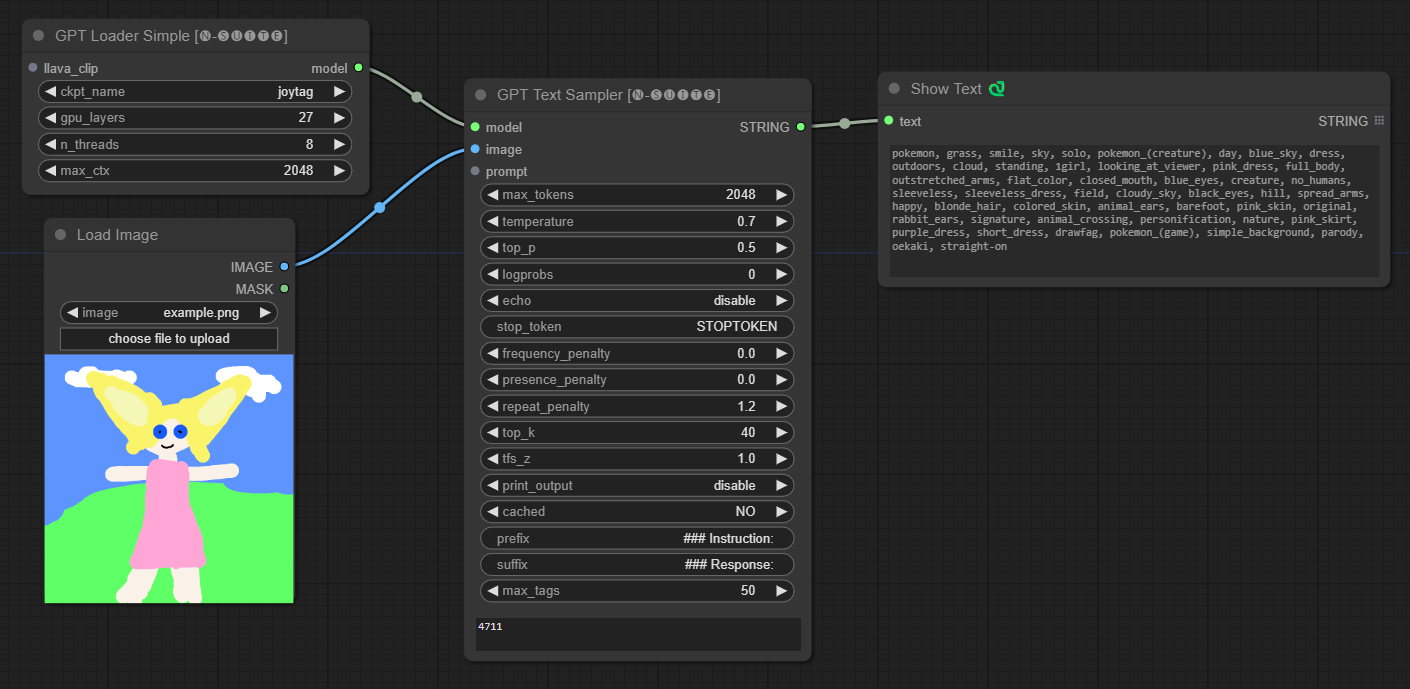
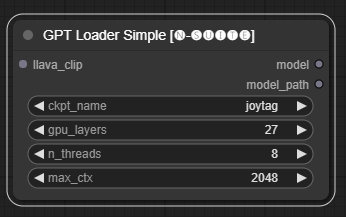
Le nœud GPTLoaderSimple est responsable du chargement des points de contrôle du modèle GPT et de la création d'une instance de la bibliothèque Llama pour la génération de texte. Il fournit une interface pour configurer les couches GPU, le nombre de threads et le contexte maximum pour la génération de texte.
ckpt_name : Sélectionnez le nom du point de contrôle GPT parmi les options disponibles (joytag et moondream seront automatiquement téléchargés lors de la première utilisation).gpu_layers : Spécifiez le nombre de couches GPU à utiliser (par défaut : 27).n_threads : Spécifiez le nombre de threads pour la génération de texte (par défaut : 8).max_ctx : Spécifiez la longueur maximale du contexte pour la génération de texte (par défaut : 2048). Le nœud renvoie une instance de la bibliothèque Llama (MODEL) et le chemin d'accès au point de contrôle chargé (STRING).
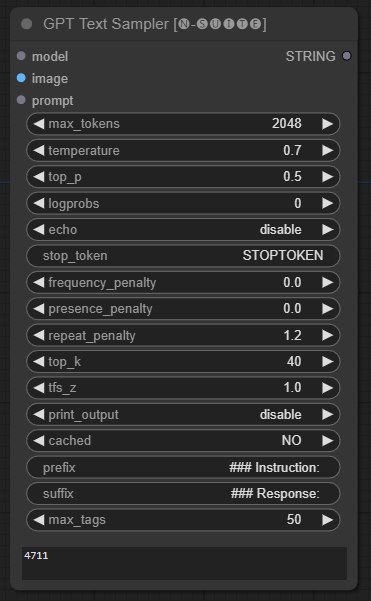
Le nœud GPTSampler facilite la génération de texte à l'aide de modèles GPT basés sur l'invite de saisie et divers paramètres de génération. Il vous permet de contrôler des aspects tels que la température, l’échantillonnage top-p, les pénalités, etc.
prompt : saisissez l'invite de saisie pour la génération de texte.image : Entrée d'image pour les modèles Joytag, moondream et llava.model : Choisissez le modèle GPT à utiliser pour la génération de texte.max_tokens : Définissez le nombre maximum de jetons dans le texte généré (par défaut : 128).temperature : Définissez le paramètre de température pour le caractère aléatoire (par défaut : 0,7).top_p : définit la probabilité top-p pour l'échantillonnage du noyau (par défaut : 0,5).logprobs : Spécifiez le nombre de probabilités de journal à générer (par défaut : 0).echo : Activez ou désactivez l'impression de l'invite de saisie à côté du texte généré.stop_token : Spécifiez le jeton auquel la génération de texte s'arrête.frequency_penalty , presence_penalty , repeat_penalty : Contrôlez les pénalités de génération de mots.top_k : Définissez les top-k jetons à prendre en compte lors de la génération (par défaut : 40).tfs_z : définit le facteur d'échelle de température pour les échantillons les plus fréquents (par défaut : 1,0).print_output : Active ou désactive l'impression du texte généré sur la console.cached : Choisissez d'utiliser ou non la génération en cache (par défaut : NON).prefix , suffix : spécifiez le texte à ajouter en préfixe et à l'invite.max_tags : Cela n'affecte que le nombre maximum de balises générées par joydag. Le nœud renvoie le texte généré avec une représentation conviviale pour l'interface utilisateur.
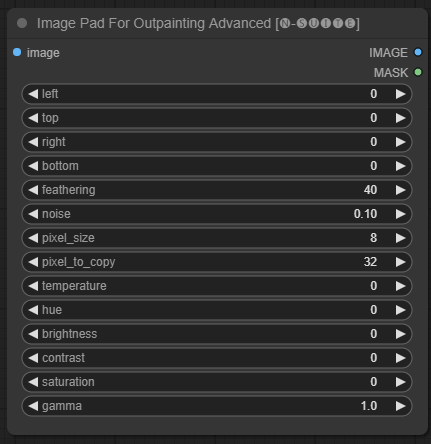
Le nœud ImagePadForOutpaintingAdvanced est une alternative au nœud ImagePadForOutpainting qui applique la technique vue dans cette vidéo sous le masque d'outpainting. La partie correction des couleurs a été extraite de ce nœud personnalisé de Sipherxyz
image : Entrée d’image.left : pixel à étendre depuis la gauche,top : pixel à étendre depuis le haut,right : pixel à étendre depuis la droite,bottom : pixel à étendre depuis le bas.feathering : force de mise en drapeaunoise : mélange la force du bruit et la bordure copiéepixel_size : quelle sera la taille du pixel dans l'effet pixellisépixel_to_copy : combien de pixels copier (de chaque côté)temperature : paramètre de correction des couleurs qui s’applique uniquement à la partie masque.hue : paramètre de correction des couleurs qui s'applique uniquement à la partie masque.brightness : paramètre de correction des couleurs qui s’applique uniquement à la partie masque.contrast : réglage de correction des couleurs qui s'applique uniquement à la partie masque.saturation : paramètre de correction des couleurs qui s'applique uniquement à la partie masque.gamma : paramètre de correction des couleurs qui s'applique uniquement à la partie masque. Le nœud renvoie l'image traitée et le masque.

Le nœud DynamicPrompt génère des invites en combinant une invite fixe avec une sélection aléatoire de balises à partir d'une invite variable. Cela permet une génération d’invites flexible et dynamique pour divers cas d’utilisation.
variable_prompt : saisissez l'invite de variable pour la sélection de balises.cached : Choisissez si vous souhaitez mettre en cache l'invite générée (par défaut : NON).number_of_random_tag : Choisissez entre "Fixed" et "Random" pour le nombre de tags aléatoires à inclure.fixed_number_of_random_tag : If number_of_random_tag if "Fixed" Spécifiez le nombre de tags aléatoires à inclure (par défaut : 1).fixed_prompt (Facultatif) : saisissez l'invite fixe pour générer l'invite finale. Le nœud renvoie l'invite générée, qui est une combinaison de l'invite fixe et des balises aléatoires sélectionnées.
variable_prompt avec la balise séparée par des virgules, le fixed_prompt est facultatif 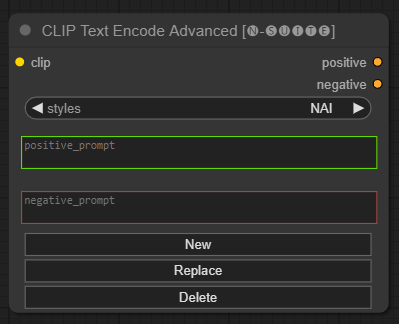
Le nœud CLIP Text Encode Advanced est une alternative au nœud CLIP Text Encode standard. Il prend en charge les styles Ajouter/Remplacer/Supprimer, permettant l'inclusion d'invites positives et négatives dans un seul nœud.
Le fichier de style de base s'appelle n-styles.csv et se trouve dans le dossier ComfyUIstyles . Le fichier de styles suit le même format que le fichier styles.csv actuel utilisé dans A1111 (au moment de la rédaction).
REMARQUE : cette note est expérimentale et contient encore beaucoup de bugs
clip : entrée de clipstyle : il remplira automatiquement les invites positives et négatives en fonction du style choisi positive : conditions positivesnegative : conditions négatives N'hésitez pas à contribuer à ce projet en signalant des problèmes ou en suggérant des améliorations. Ouvrez un ticket ou soumettez une pull request sur le référentiel GitHub.
Ce projet est sous licence MIT. Voir le fichier LICENSE pour plus de détails.


