Découverte des connexions cachées dans les données financières non structurées à l'aide d'Amazon Bedrock et d'Amazon Neptune
Ce référentiel contient du code pour déployer un prototype de solution qui démontre comment l'IA générative et le graphe de connaissances peuvent être combinés pour créer un système sans serveur évolutif, piloté par événements, pour traiter les données non structurées pour les services financiers. Cette solution peut aider les gestionnaires d'actifs de votre organisation à découvrir les connexions cachées dans leurs portefeuilles d'investissement et fournit un exemple d'interface utilisateur facile à utiliser pour consulter l'actualité financière et comprendre ses connexions avec leurs portefeuilles d'investissement.
Cas d'utilisation professionnelle
Les gestionnaires d'actifs investissent généralement dans un grand nombre de sociétés dans leurs portefeuilles et ils doivent être en mesure de suivre toute actualité relative à ces sociétés, car ces actualités les aideraient à garder une longueur d'avance sur les mouvements du marché, à identifier les opportunités d'investissement et à mieux gérer leur investissement. portefeuille.
Généralement, le suivi des actualités peut être effectué facilement en configurant une simple alerte d'actualité basée sur un mot clé utilisant le nom de la société dans laquelle nous investissons, mais cela devient de plus en plus difficile lorsque l'événement d'actualité n'a pas d'impact direct sur la société dans laquelle nous investissons. Par exemple, l'impact pourrait être sur un fournisseur d'une entreprise dans laquelle nous investissons, ce qui pourrait potentiellement perturber la chaîne d'approvisionnement de l'entreprise. L’impact pourrait également concerner le client d’un client de la société dans laquelle vous investissez. Si ces entreprises concentrent leurs revenus sur quelques clients clés, cela pourrait avoir un impact financier négatif sur votre investissement.
De tels impacts de deuxième ou troisième ordre sont difficiles à identifier et encore plus difficiles à suivre. Grâce à cette solution automatisée, les gestionnaires d'actifs peuvent créer un graphique de connaissances des relations entourant leur portefeuille d'investissement, puis utiliser ces connaissances pour tirer des corrélations et des informations à partir des dernières actualités.
Architecture
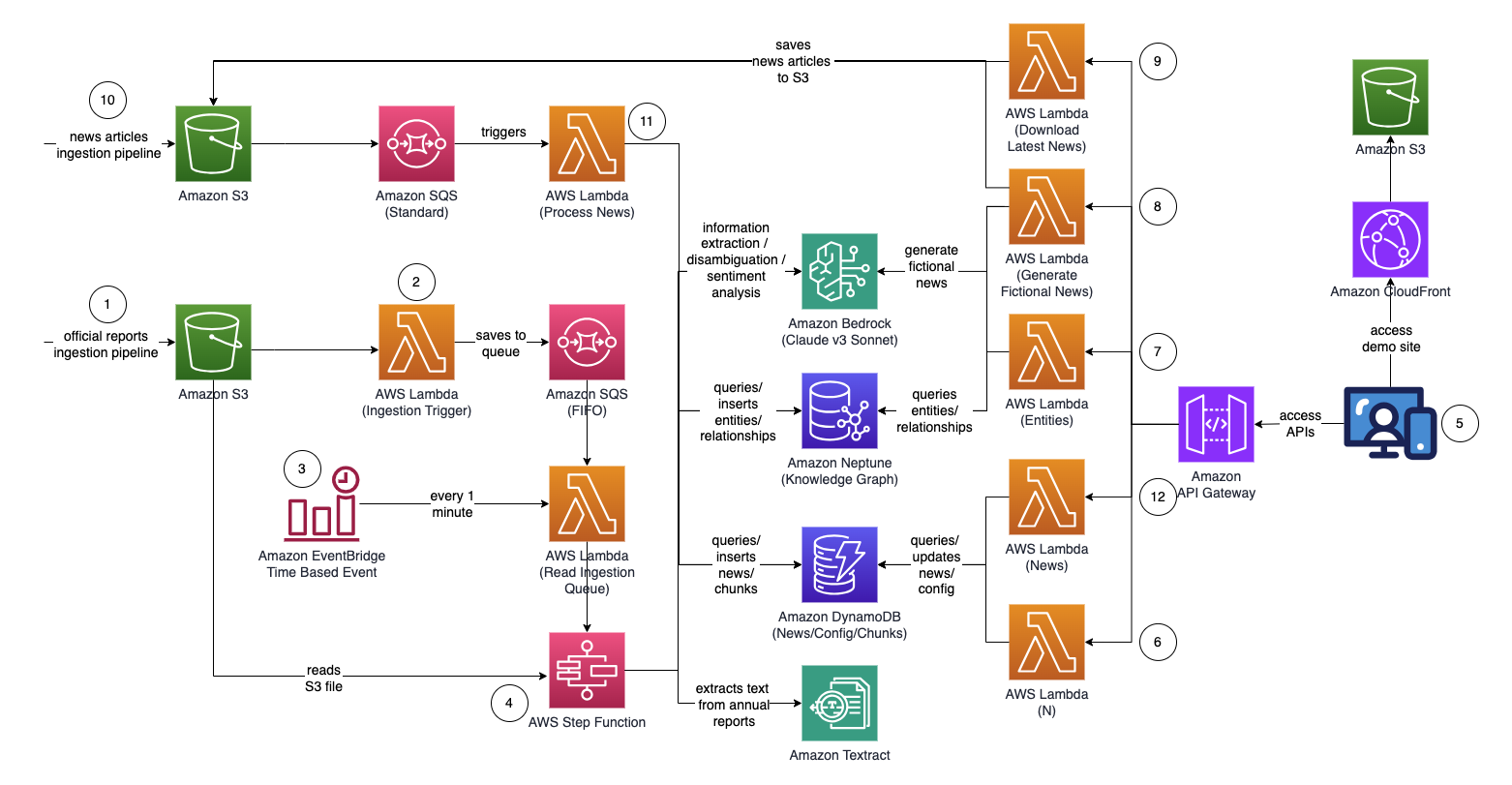
Graphique de fonction d'étape (à partir du point 4)
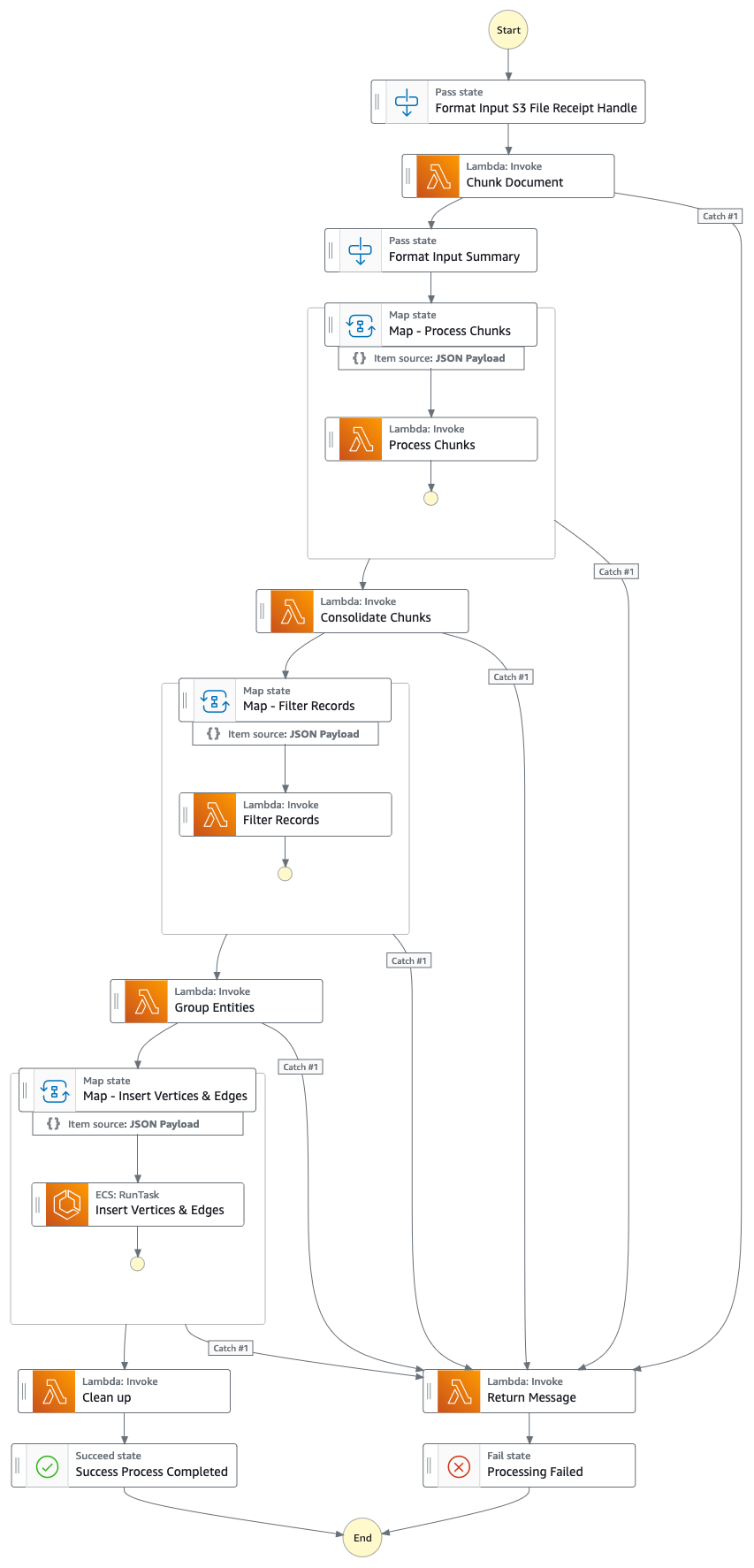
Flux de solution (étape par étape)
- Téléchargez des rapports proxy/annuels/10 000 officiels (.PDF) dans le compartiment Amazon S3.
- Le nom du compartiment S3 vers lequel télécharger peut être récupéré à partir de la console CloudFormation - sortie de la pile principale - "IngestionBucket"
- Notez que les rapports utilisés doivent être des rapports officiellement publiés afin de minimiser l'inclusion de données inexactes dans votre graphique de connaissances (par opposition aux actualités/tabloïds).
- La notification d'événement S3 déclenche une fonction AWS Lambda qui envoie le nom du compartiment/fichier S3 à une file d'attente Amazon Simple Queue Service (FIFO).
- L'utilisation de la file d'attente FIFO vise à garantir que le processus d'ingestion du rapport est effectué de manière séquentielle afin de réduire le risque d'introduction de données en double dans votre graphique de connaissances.
- Un événement temporel Amazon EventBridge s'exécute toutes les minutes pour appeler une fonction AWS Lambda. La fonction récupérera le prochain message de file d'attente disponible de SQS et démarrera l'exécution d'une AWS Step Function de manière asynchrone.
- Une machine à états de fonction étape par étape exécute une série de tâches pour traiter le document téléchargé en extrayant les informations clés et en les insérant dans votre graphique de connaissances.
- Tâches
- À l'aide d'Amazon Textract, extrayez le contenu texte du fichier de rapport proxy/annuel/10 000 (PDF) dans Amazon S3 et divisez-le en plusieurs morceaux de texte plus petits pour le traitement. Stockez les morceaux de texte dans Amazon DynamoDB.
- À l'aide du Sonnet Claude v3 d'Anthropic sur Amazon Bedrock, traitez les premiers morceaux de texte pour déterminer l'entité principale à laquelle le rapport fait référence, ainsi que les attributs pertinents (par exemple, l'industrie).
- Récupère les morceaux de texte de DynamoDB et pour chaque morceau de texte, appelle une fonction lambda pour extraire les entités (entreprise/personne) et sa relation (client/fournisseur/partenaire/concurrent/directeur) avec l'entité principale à l'aide d'Amazon Bedrock.
- Consolider toutes les informations extraites
- Filtre le bruit/les entités non pertinentes (c'est-à-dire les termes génériques tels que « consommateurs ») à l'aide d'Amazon Bedrock.
- Utilisez Amazon Bedrock pour lever l'ambiguïté en raisonnant à l'aide des informations extraites par rapport à la liste des entités similaires du graphe de connaissances. Si l'entité n'existe pas, insérez-la. Sinon, utilisez l'entité qui existe déjà dans le knowledge graph. Insère toutes les relations extraites.
- Effectuez un nettoyage en supprimant le message de la file d'attente SQS et le fichier S3.
- Une fois cette étape terminée, votre graphe de connaissances est mis à jour et prêt à être utilisé.
- Un utilisateur accède à une application Web basée sur React pour afficher les articles d'actualité enrichis d'informations sur l'entité/le sentiment/le chemin de connexion.
- L'URL de l'application Web peut être copiée depuis la console CloudFormation - sortie de la pile d'application Web - "WebApplicationURL"
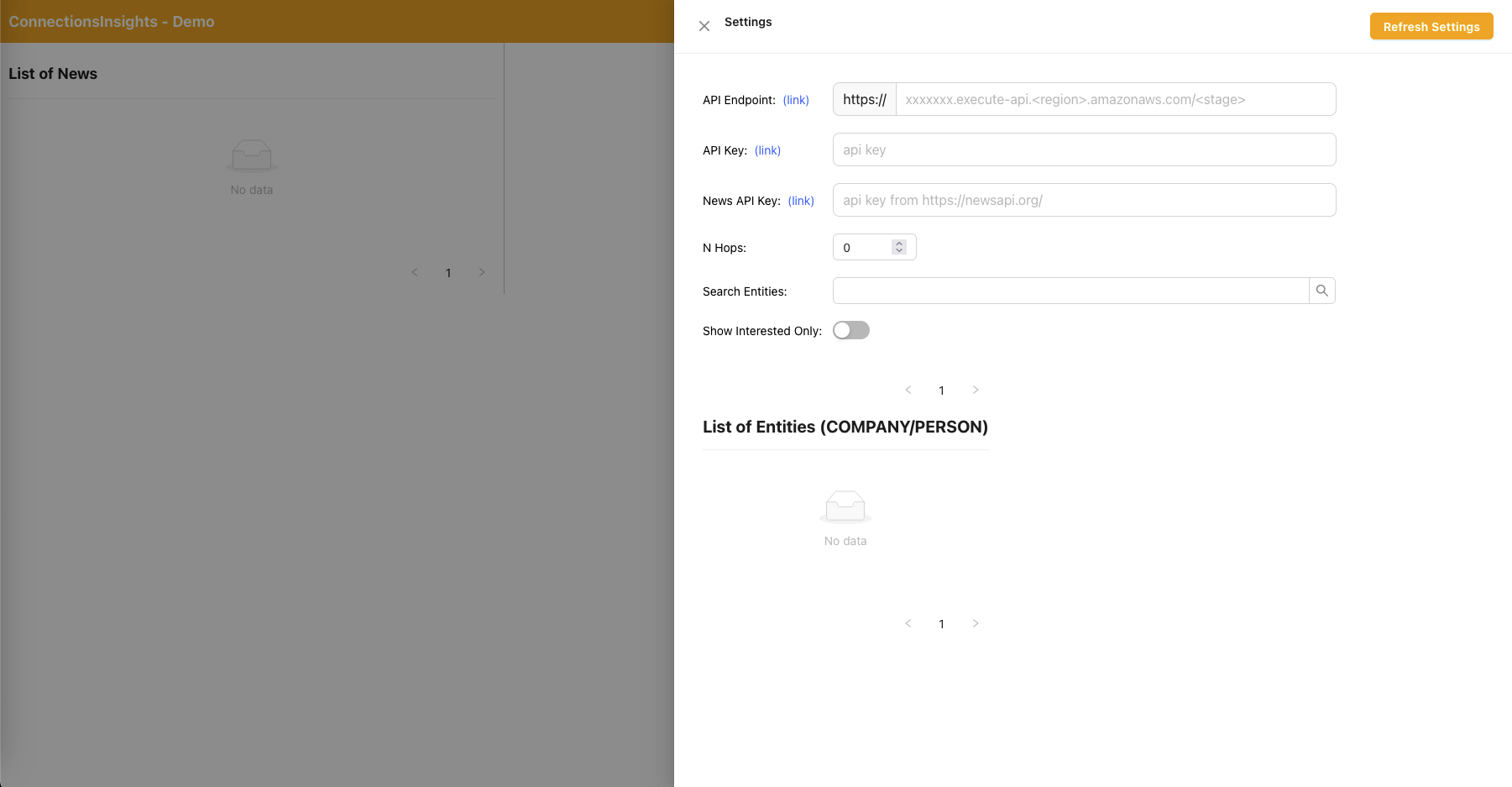
- Comme il s'agit d'un exemple de solution à des fins de démonstration, l'utilisateur spécifie le point de terminaison de l'API, la clé API et la clé API News sur l'application Web en cliquant sur l'icône en forme d'engrenage dans le coin supérieur droit.
- Le point de terminaison de l'API peut être copié depuis la console CloudFormation - sortie de la pile principale - "APIEndpoint".
- La clé API peut être copiée depuis la console API Gateway API Key - pile principale.
- La clé API News peut être obtenue auprès de NewsAPI.org après avoir créé un compte gratuitement.
- Cliquez sur le bouton "Actualiser les paramètres" après avoir renseigné les valeurs.
- À l'aide de l'application Web, un utilisateur spécifie le nombre de sauts (par défaut N = 2) sur le chemin de connexion à surveiller.
- Pour ce faire, cliquez sur l'icône d'engrenage dans le coin supérieur droit, puis spécifiez la valeur de N.
- À l'aide de l'application Web, un utilisateur spécifie la liste des entités à suivre.
- Pour ce faire, cliquez sur l'icône d'engrenage dans le coin supérieur droit, puis activez le commutateur « Intéressé » qui marque l'entité correspondante comme INTÉRESSÉE = OUI/NON.
- Il s'agit d'une étape importante qui doit être effectuée avant le traitement de tout article de presse.
- Pour générer des nouvelles fictives, un utilisateur clique sur le bouton « Générer un échantillon de nouvelles » pour générer 10 exemples de nouvelles financières avec un contenu aléatoire à alimenter dans le processus d'ingestion de nouvelles.
- Le contenu est généré à l'aide d'Amazon Bedrock et est purement fictif.
- Pour télécharger les actualités actuelles, un utilisateur clique sur le bouton « Télécharger les dernières nouvelles » pour télécharger les principales nouvelles du jour (propulsé par NewsAPI.org).
- Téléchargez des actualités (.TXT) dans le compartiment S3.
- Le nom du compartiment S3 vers lequel télécharger peut être récupéré à partir de la console CloudFormation - sortie de la pile principale - "NewsBucket"
- Les étapes 8 ou 9 ont automatiquement téléchargé les actualités dans le compartiment S3, mais vous pouvez également créer des intégrations avec votre fournisseur de nouvelles préféré tel qu'AWS Data Exchange ou tout autre fournisseur de nouvelles tiers pour déposer des articles d'actualité sous forme de fichiers dans le compartiment S3.
- Le contenu du fichier de données d'actualité doit être formaté comme suit : <date>{jj mmm aaaa}</date><title>{title}</title><text>{contenu d'actualité></text>
- La notification d'événement S3 envoie le nom du compartiment/fichier S3 à SQS (standard), ce qui déclenche plusieurs fonctions lambda pour traiter les données d'actualité en parallèle.
- À l'aide d'Amazon Bedrock, la fonction lambda extrait les entités mentionnées dans l'actualité ainsi que toutes les informations, relations et sentiments associés à l'entité mentionnée.
- Il vérifie ensuite le graphe de connaissances et utilise Amazon Bedrock pour effectuer une levée d'ambiguïté en raisonnant en utilisant les informations disponibles dans les actualités et à partir du graphe de connaissances pour identifier l'entité correspondante.
- Une fois l'entité localisée, elle recherche et renvoie ensuite tous les chemins de connexion se connectant aux entités marquées INTERESTED=YES dans le graphe de connaissances qui se trouvent à N=2 sauts.
- L'application Web s'actualise automatiquement toutes les secondes pour extraire le dernier ensemble d'actualités traitées à afficher sur l'application Web.
Application Web React - Paramètres
Explorateur de graphiques
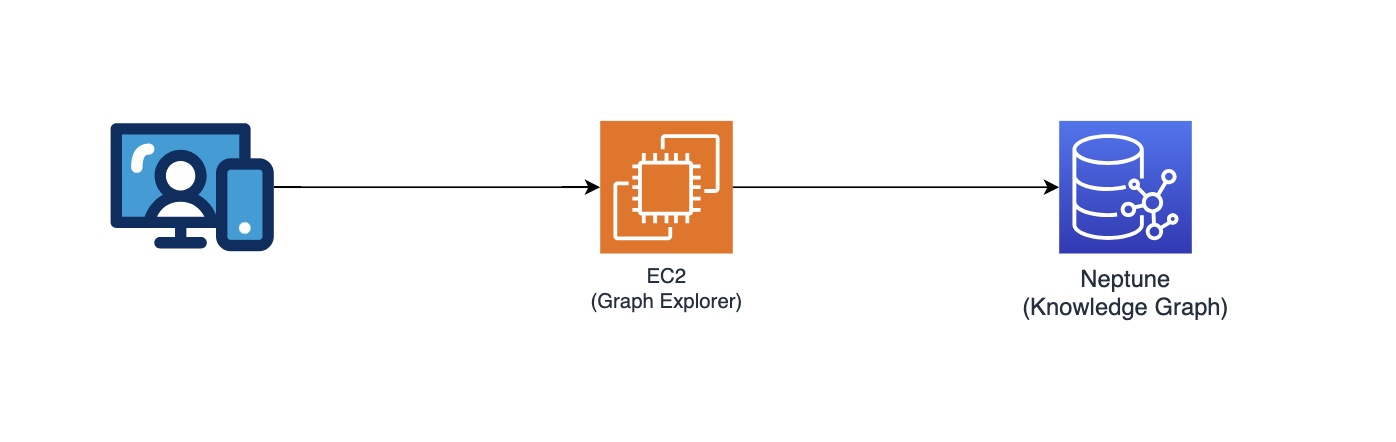
Ce référentiel déploie également Graph Explorer (github/aws/graphexplorer), qui est une application Web basée sur React qui permet aux utilisateurs de visualiser les entités et les relations extraites.
- Pour accéder à Graph Explorer, récupérez l'URL depuis la console CloudFormation - sortie de la pile principale - "GraphExplorer"
- Lorsque vous accédez à l'application Web, vous recevrez un avertissement de risque de sécurité potentiel sur votre navigateur car le certificat utilisé pour le site est auto-signé. Vous pouvez continuer. Pour vous débarrasser de l'avertissement, lisez ceci.
- Une fois lancée, l'application se connectera automatiquement à la base de données AWS Neptune et synchronisera ses données. Vous pouvez cliquer sur l'icône d'actualisation à tout moment pour resynchroniser les données.
- Cliquez sur « Ouvrir l'explorateur de graphiques » en haut à droite pour commencer à visualiser le graphe de connaissances.
- Accédez à github/aws/graphexplorer pour plus d'informations sur Graph Explorer.
- Notez que Graph Explorer n’est pas requis dans le cadre de la solution mais vous permet d’explorer plus facilement les relations extraites.
Démo - Premiers pas avec Graph Explorer
premiers pas avec graph-explorer.mp4
Voici une autre démo vidéo sur les fonctionnalités de Graph Explorer : lien vers la démo vidéo
Explorateur de graphiques - Knowledge Graph
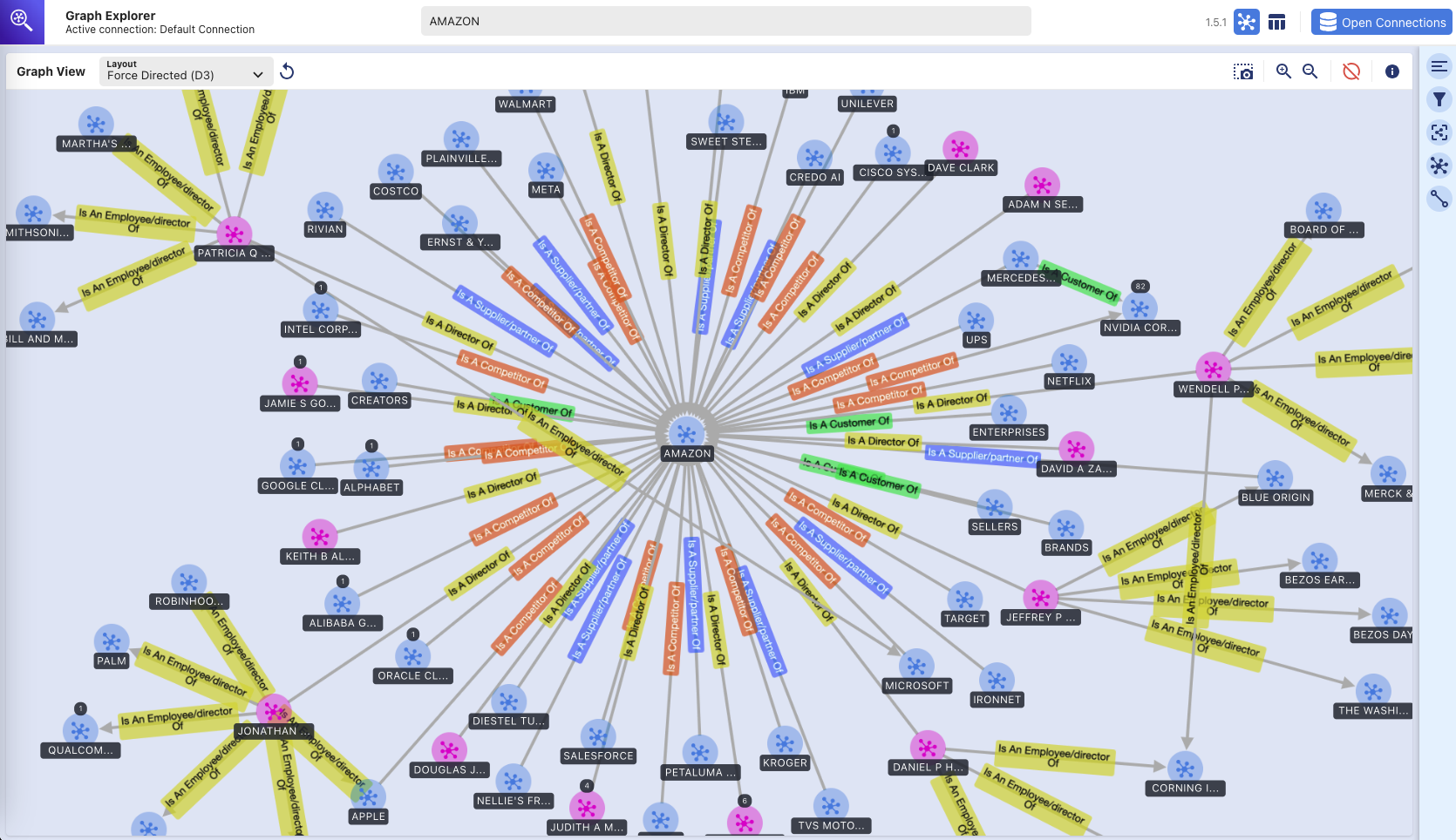
(exploration visuelle de la base de données de graphiques Amazon Neptune à l'aide de l'outil Graph Explorer)
Instructions de déploiement
Ce référentiel fournit une application CDK qui déploiera l'intégralité de la solution prototype sur deux piles CDK :
- pile d'applications principale (« pile principale ») qui peut être déployée dans n'importe quelle région (par exemple us-east-1, us-west-2) disposant des services requis et des modèles Amazon Bedrock.
- pile d'applications Web (« pile webapp ») qui ne peut être déployée que sur us-east-1 car elle nécessite AWS WAF.
Vous pouvez déployer les deux piles dans des régions différentes ou dans la même région (c'est-à-dire us-east-1).
Services AWS utilisés
- Socle amazonien
- Amazone Neptune
- Texte Amazone
- Amazon DynamoDB
- Fonction d'étape AWS
- AWS Lambda
- Service de file d'attente simple Amazon (SQS)
- Amazon EventBridge
- Service de stockage simple Amazon (S3)
- Amazon CloudFront
- AWSWAF
- Amazon Elastic Compute Cloud (EC2)
- AmazonVPC
- Passerelle API Amazon
- Gestion des identités et des accès AWS
Pré-requis
- Amazon Bedrock - Vous aurez besoin d'accéder à Anthropic Claude v3 Sonnet. Pour configurer l'accès au modèle dans Amazon Bedrock, lisez ceci.
- Python - Vous aurez besoin de Python 3 et supérieur.
- Nœud - Vous aurez besoin de la version 18.0.0 et supérieure.
- Docker - Vous aurez besoin de la version 24.0.0 et supérieure avec Docker Buildx et du démon Docker en cours d'exécution.
Configurer VirtualEnv
Pour créer manuellement un virtualenv sur MacOS et Linux :
Une fois le processus d'initialisation terminé et le virtualenv créé, vous pouvez utiliser l'étape suivante pour activer votre virtualenv.
$ source .venv/bin/activate
Si vous êtes une plateforme Windows, vous activeriez le virtualenv comme ceci :
% .venvScriptsactivate.bat
Une fois le virtualenv activé, vous pouvez installer les dépendances requises.
$ pip install -r requirements.txt
Pré-déploiement
Si c'est la première fois que vous déployez votre code via CDK sur votre compte AWS, vous devrez d'abord amorcer votre compte AWS à la fois dans us-east-1 et également dans la région dans laquelle vous déployez. Sinon, vous pouvez ignorer cette étape.
$ cdk bootstrap aws://<account no>/us-east-1 aws://<account no>/<aws region to deploy main application stack>
Ensuite, exécutez la commande ci-dessous pour :
- créer l'application Web basée sur React
- télécharger les dépendances Python requises pour la création de la couche AWS Lambda
- copier la bibliothèque personnalisée (connectionsinsights)
Déployer
Pour déployer la solution (cela prend environ 30 minutes) :
$ ./deploy.sh <aws region to deploy main application stack>
Nettoyer
Pour détruire la solution :
$ ./destroy.sh <aws region where main application stack was deployed>
Si vous rencontrez un échec de suppression en raison du fait que les compartiments S3 ne sont pas vides, cela peut être dû aux fichiers journaux d'accès écrits dans les compartiments S3 après qu'ils ont été vidés dans le cadre du processus de destruction du cdk. Si cela se produit, videz simplement ces compartiments et réexécutez la commande de nettoyage.


