WilmerAI
1.0.0
Il s’agit d’un projet personnel en plein développement. Il peut contenir, et contient probablement, des bogues, du code incomplet ou d'autres problèmes involontaires. A ce titre, le logiciel est fourni tel quel, sans garantie d’aucune sorte.
WilmerAI reflète le travail d'un seul développeur et les efforts de son temps et de ses ressources personnels ; tous les points de vue, méthodologies, etc. qui s'y trouvent sont les siens et ne doivent pas refléter l'image de son employeur.
WilmerAI est un système middleware sophistiqué conçu pour prendre les invites entrantes et y effectuer diverses tâches avant de les envoyer aux API LLM. Ce travail comprend l'utilisation d'un grand modèle linguistique (LLM) pour catégoriser l'invite et l'acheminer vers le flux de travail approprié ou le traitement d'un contexte volumineux (plus de 200 000 jetons) pour générer une invite plus petite et plus gérable, adaptée à la plupart des modèles locaux.
WilmerAI signifie « Et si les modèles linguistiques acheminaient toutes les inférences de manière experte ? »
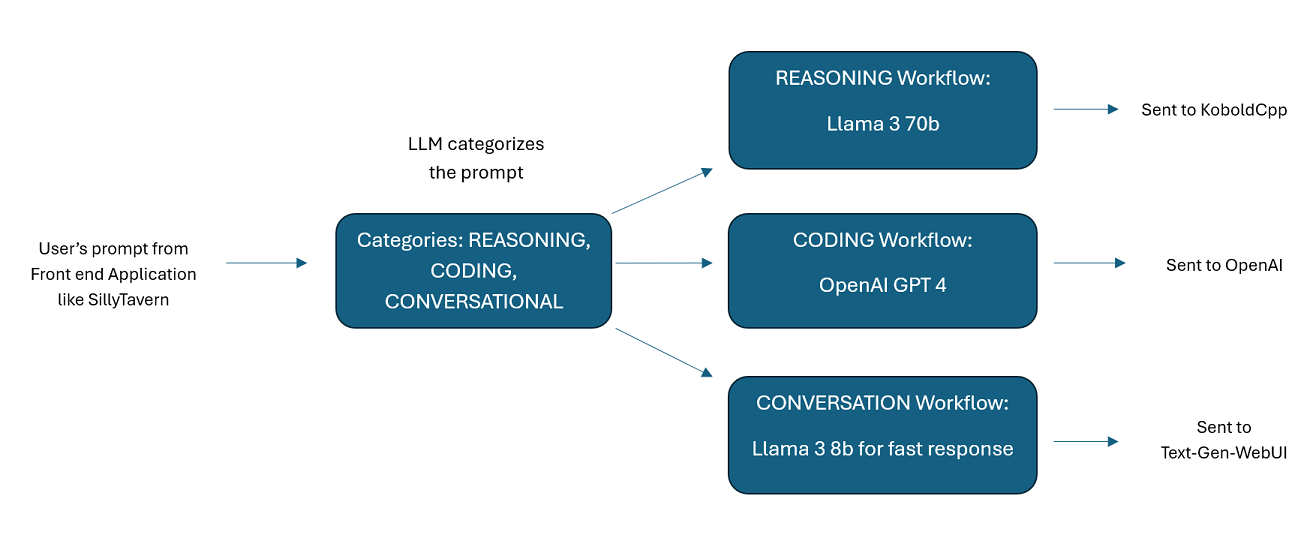
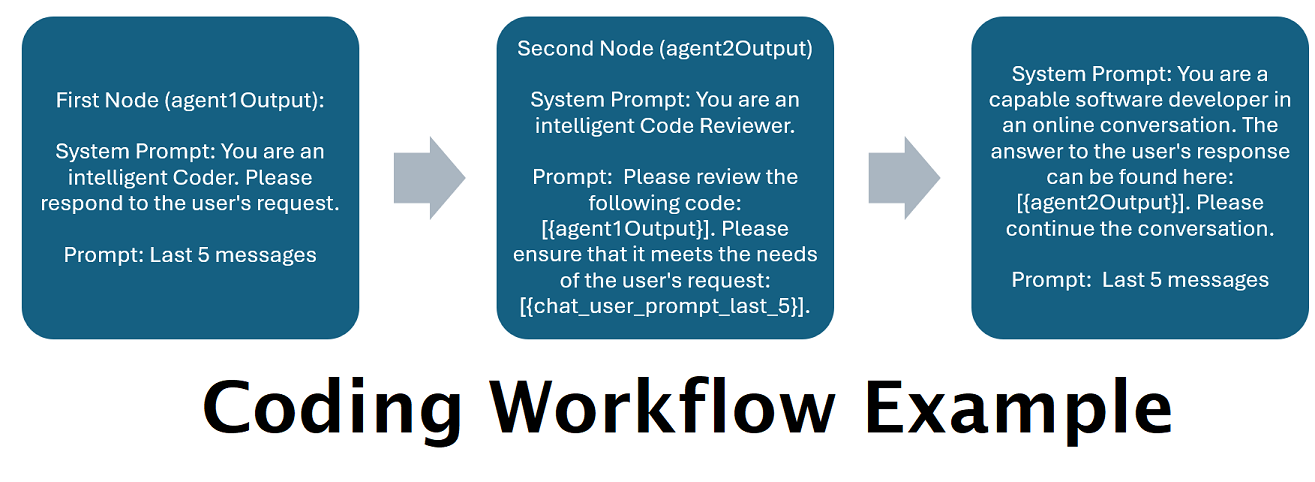
Assistants alimentés par plusieurs LLM en tandem : les invites entrantes peuvent être acheminées vers des "catégories", chaque catégorie étant alimentée par un flux de travail. Chaque workflow peut avoir autant de nœuds que vous le souhaitez, chaque nœud étant alimenté par un LLM différent. Par exemple, si vous demandez à votre assistant « Pouvez-vous m'écrire un jeu Snake en python ? », cela peut être classé dans la catégorie CODAGE et être envoyé à votre flux de travail de codage. Le premier nœud de ce flux de travail peut demander à Codestral-22b (ou ChatGPT 4o si vous le souhaitez) de répondre à la question. Le deuxième nœud peut demander à Deepseek V2 ou à Claude Sonnet de le réviser. Le nœud suivant pourrait demander à Codestral de donner une dernière fois sa réponse, puis de vous répondre. Que votre flux de travail soit simplement un modèle unique répondant parce qu'il s'agit de votre meilleur codeur, ou que ses nombreux nœuds de différents LLM travaillent ensemble pour générer une réponse, le choix vous appartient.
Prise en charge de l'API Wikipédia hors ligne : WilmerAI dispose d'un nœud qui peut effectuer des appels vers OfflineWikipediaTextApi. Cela signifie que vous pouvez avoir une catégorie, par exemple « FACTUEL », qui examine votre message entrant, génère une requête à partir de celui-ci, interroge l'API Wikipédia pour un article associé et utilise cet article comme injection de contexte RAG pour répondre.
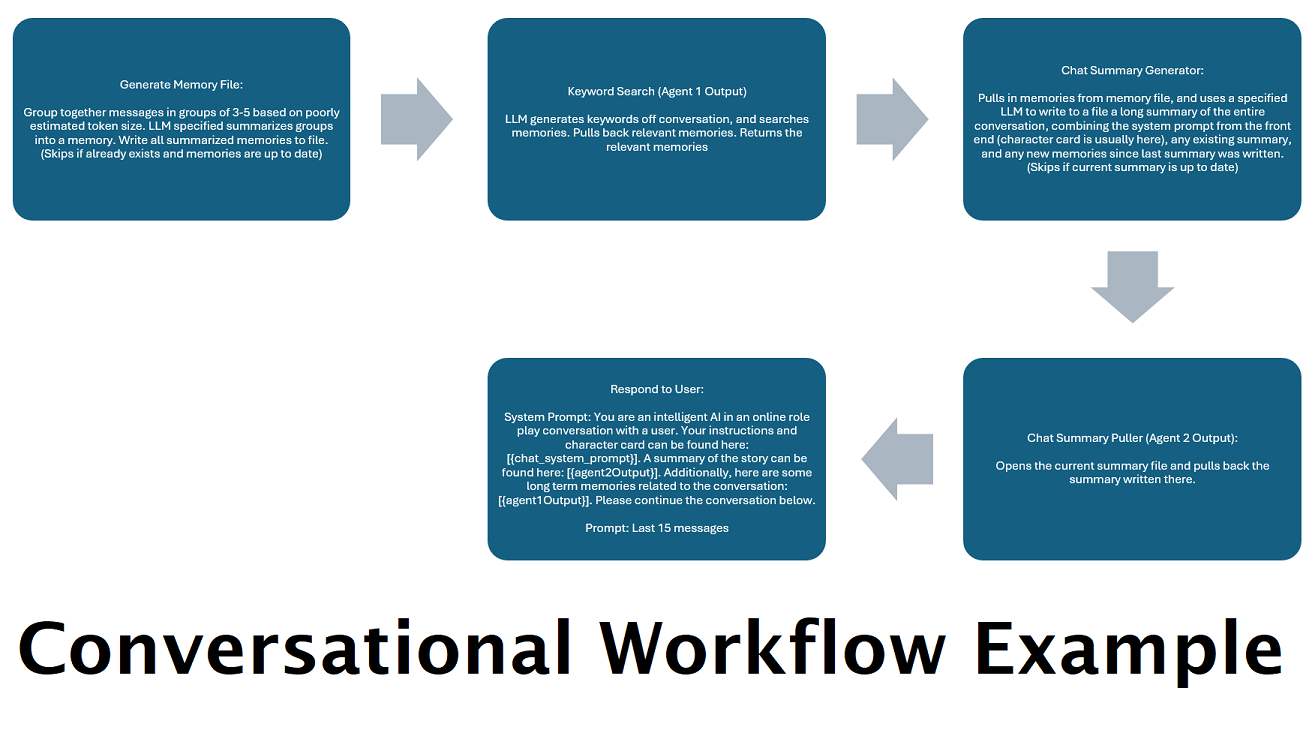
Résumés de discussion générés en continu pour simuler une « mémoire » : le nœud Résumé de discussion générera des « souvenirs », en fragmentant vos messages, puis en les résumant et en les enregistrant dans un fichier. Il prendra ensuite ces morceaux résumés et générera un résumé continu et constamment mis à jour de l'intégralité de la conversation, qui peut être extrait et utilisé dans l'invite du LLM. Les résultats vous permettent de prendre plus de 200 000 conversations contextuelles et de garder une trace relative de ce qui a été dit même en limitant les invites du LLM à 5 000 contextes ou moins.
Utiliser plusieurs ordinateurs pour traiter en parallèle les mémoires et les réponses : Si vous disposez de 2 ordinateurs capables d'exécuter des LLM, vous pouvez en désigner un comme « répondeur » et un autre comme responsable de la génération des mémoires/résumés. Ce type de flux de travail vous permet de continuer à parler à votre LLM pendant la mise à jour des mémoires/résumés, tout en continuant à utiliser les mémoires existantes. Cela signifie que vous n'avez jamais besoin d'attendre la mise à jour du résumé, même si vous chargez un modèle volumineux et puissant de gérer cette tâche afin que vous disposiez de mémoires de meilleure qualité. (Voir l'exemple d'utilisateur convo-role-dual-model )
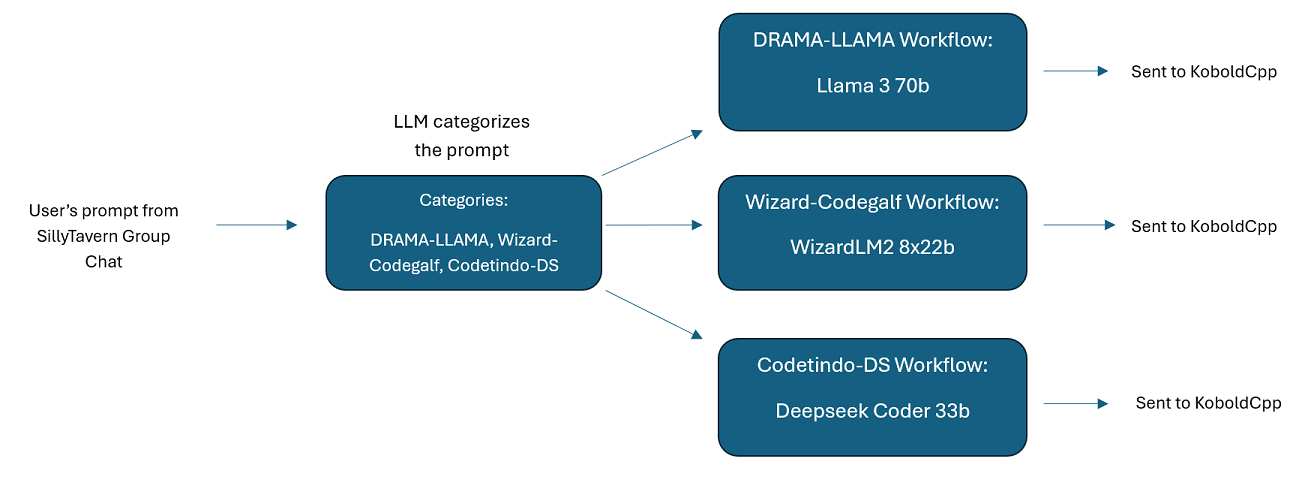
Discussions de groupe multi-LLM dans SillyTavern : il est possible d'utiliser Wilmer pour avoir une discussion de groupe dans ST où chaque personnage est un LLM différent, si vous le souhaitez (l'auteur le fait personnellement.) Il existe des exemples de personnages disponibles dans DocsSillyTavern , divisé en deux groupes. Ces exemples de personnages/groupes sont des sous-ensembles de groupes plus larges que l'auteur utilise.
Fonctionnalité middleware : WilmerAI se situe entre l'interface que vous utilisez pour communiquer avec un LLM (comme SillyTavern, OpenWebUI ou même le terminal d'un programme Python) et l'API backend au service des LLM. Il peut gérer plusieurs LLM backend simultanément.
Utilisation de plusieurs LLM à la fois : exemple de configuration : SillyTavern -> WilmerAI -> plusieurs instances de KoboldCpp. Par exemple, Wilmer pourrait être connecté à Command-R 35b, Codestral 22b, Gemma-2-27b et utiliser tous ceux-ci dans ses réponses à l'utilisateur. Tant que le LLM de votre choix est exposé via un point de terminaison v1/Completion ou chat/Completion, ou le point de terminaison Generate de KoboldCpp, vous pouvez l'utiliser.
Préréglages personnalisables : les préréglages sont enregistrés dans un fichier json que vous pouvez facilement personnaliser. Presque tous les préréglages peuvent être gérés via le json, y compris les noms des paramètres. Cela signifie que vous n'avez pas besoin d'attendre une mise à jour de Wilmer pour utiliser quelque chose de nouveau. Par exemple, DRY est sorti récemment sur KoboldCpp. Si ce n'était pas dans le json prédéfini pour Wilmer, vous devriez pouvoir simplement l'ajouter et commencer à l'utiliser.
Points de terminaison de l'API : il fournit des points de terminaison chat/Completions et v1/Completions compatibles avec l'API OpenAI auxquels se connecter via votre front-end, et peut se connecter à l'un ou l'autre type sur le back-end. Cela permet des configurations complexes, telles que la connexion à Wilmer en tant qu'API v1/Completion, puis la connexion de Wilmer à chat/Completion, v1/Completion KoboldCpp Générer des points de terminaison en même temps.
Modèles d'invite : prend en charge les modèles d'invite pour les points de terminaison de l'API v1/Completions . WilmerAI dispose également de son propre modèle d'invite pour les connexions à partir d'un frontal via v1/Completions . Le modèle se trouve dans le dossier « Docs » et est prêt à être téléchargé sur SillyTavern.

N'oubliez pas que les workflows, de par leur nature même, peuvent effectuer de nombreux appels vers un point de terminaison d'API en fonction de la manière dont vous les configurez. WilmerAI ne suit pas l'utilisation des jetons, ne rapporte pas l'utilisation précise des jetons via son API et n'offre aucun moyen viable de surveiller l'utilisation des jetons. Ainsi, si le suivi de l'utilisation des jetons est important pour vous pour des raisons de coût, assurez-vous de suivre le nombre de jetons que vous utilisez via n'importe quel tableau de bord fourni par vos API LLM, en particulier au début lorsque vous vous habituez à ce logiciel.
Votre LLM affecte directement la qualité de WilmerAI. Il s'agit d'un projet piloté par LLM, où les flux et les résultats dépendent presque entièrement des LLM connectés et de leurs réponses. Si vous connectez Wilmer à un modèle qui produit des sorties de qualité inférieure, ou si vos préréglages ou votre modèle d'invite présentent des défauts, la qualité globale de Wilmer sera également de bien moindre qualité. De cette manière, ce n'est pas très différent des workflows agents.
Bien que l'auteur fasse de son mieux pour créer quelque chose d'utile et de haute qualité, il s'agit d'un projet solo ambitieux qui aura forcément ses problèmes (d'autant plus que l'auteur n'est pas nativement un développeur Python et s'est fortement appuyé sur l'IA pour l'aider à obtenir cela). loin). Mais il commence à le comprendre petit à petit.
Wilmer expose à la fois un point de terminaison OpenAI v1/Completions et chat/Completions, ce qui le rend compatible avec la plupart des frontaux. Bien que je l'utilise principalement avec SillyTavern, cela pourrait également fonctionner avec Open-WebUI.
Pour vous connecter en tant que complétion de texte dans SillyTavern, suivez ces étapes (la capture d'écran ci-dessous provient de SillyTavern) :
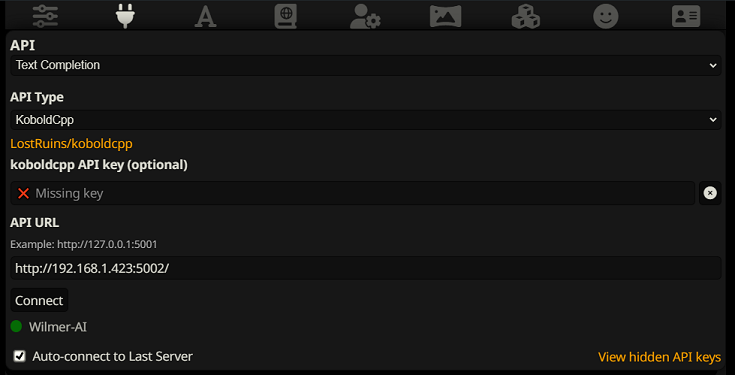
Lorsque vous utilisez des complétions de texte, vous devez utiliser un format de modèle d'invite spécifique à WilmerAI. Un fichier ST importable peut être trouvé dans Docs/SillyTavern/InstructTemplate . Le modèle de contexte est également inclus si vous souhaitez également l'utiliser.
Le modèle d'instruction ressemble à ceci :
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
De SillyTavern :
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
Il n'y a pas de nouvelles lignes ou de caractères attendus entre les balises.
Veuillez vous assurer que le modèle de contexte est « Activé » (case à cocher au-dessus de la liste déroulante)
Pour vous connecter en tant que chat terminé dans SillyTavern, suivez ces étapes (la capture d'écran ci-dessous provient de SillyTavern) :
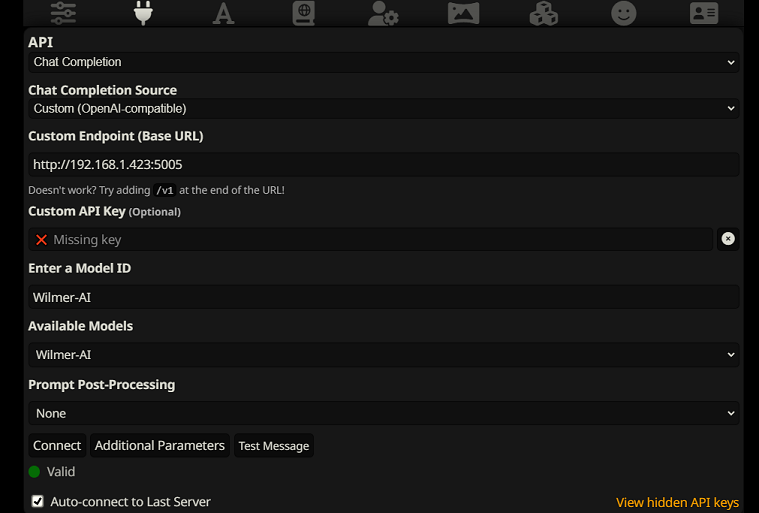
chatCompleteAddUserAssistant sur true. (Je ne recommande pas de définir les deux sur true en même temps. Faites soit les noms de personnages de SillyTavern, soit l'utilisateur/assistant de Wilmer. Sinon, l'IA pourrait être confuse.)Pour les deux types de connexion, je recommande d'aller sur l'icône "A" dans SillyTavern et de sélectionner "Inclure les noms" et "Forcer les groupes et les personnalités" en mode instruction, puis d'aller sur l'icône la plus à gauche (où se trouvent les échantillonneurs) et de cocher " stream" en haut à gauche, puis en haut à droite en cochant "déverrouiller" dans le contexte et en le faisant glisser vers 200 000+. Laissez Wilmer s'inquiéter du contexte.
Wilmer n'a actuellement aucune interface utilisateur ; tout est contrôlé via les fichiers de configuration JSON situés dans le dossier "Public". Ce dossier contient toutes les configurations essentielles. Lors de la mise à jour ou du téléchargement d'une nouvelle copie de WilmerAI, vous devez simplement copier votre dossier « Public » vers la nouvelle installation pour conserver vos paramètres.
Cette section vous guidera dans la configuration de Wilmer. J'ai divisé les sections en étapes ; Je pourrais recommander de copier chaque étape, 1 par 1, dans un LLM et de lui demander de vous aider à configurer la section. Cela pourrait rendre les choses beaucoup plus faciles.
REMARQUES IMPORTANTES
Il est important de noter trois choses concernant la configuration de Wilmer.
A) Les fichiers prédéfinis sont 100 % personnalisables. Le contenu de ce fichier va à l'API llm. En effet, les API cloud ne gèrent pas certains des différents préréglages gérés par les API LLM locales. En tant que tel, si vous utilisez l'API OpenAI ou d'autres services cloud, les appels échoueront probablement si vous utilisez l'un des préréglages d'IA locaux habituels. Veuillez consulter le préréglage « OpenAI-API » pour un exemple de ce qu'openAI accepte.
B) J'ai récemment remplacé toutes les invites dans Wilmer pour passer de la deuxième personne à la troisième personne. Cela a donné des résultats assez décents pour moi, et j'espère que ce sera également le cas pour vous.
C) Par défaut, tous les fichiers utilisateur sont configurés pour activer les réponses en continu. Vous devez soit l'activer dans votre frontal qui appelle Wilmer pour que les deux correspondent, soit accéder à Users/username.json et définir Stream sur "false". Si vous avez un décalage, où le front-end s'attend/n'attend pas le streaming et votre wilmer s'attend au contraire, rien ne s'affichera probablement sur le front-end.
L'installation de Wilmer est simple. Assurez-vous que Python est installé ; l'auteur utilise le programme avec Python 3.10 et 3.12, et les deux fonctionnent bien.
Option 1 : utilisation des scripts fournis
Pour plus de commodité, Wilmer inclut un fichier BAT pour Windows et un fichier .sh pour macOS. Ces scripts créeront un environnement virtuel, installeront les packages requis à partir de requirements.txt , puis exécuteront Wilmer. Vous pouvez utiliser ces scripts pour démarrer Wilmer à chaque fois.
.bat fourni..sh fourni.IMPORTANT : n'exécutez jamais un fichier BAT ou SH sans l'inspecter au préalable, car cela peut être risqué. Si vous n'êtes pas sûr de la sécurité d'un tel fichier, ouvrez-le dans Notepad/TextEdit, copiez le contenu, puis demandez à votre LLM de l'examiner pour déceler tout problème potentiel.
Option 2 : Installation manuelle
Vous pouvez également installer manuellement les dépendances et exécuter Wilmer en procédant comme suit :
Installez les packages requis :
pip install -r requirements.txtDémarrez le programme :
python server.pyLes scripts fournis sont conçus pour rationaliser le processus en configurant un environnement virtuel. Cependant, vous pouvez les ignorer en toute sécurité si vous préférez une installation manuelle.
REMARQUE : lors de l'exécution du fichier bat, du fichier sh ou du fichier python, tous les trois acceptent désormais les arguments FACULTATIFS suivants :
Ainsi, par exemple, considérons les exécutions possibles suivantes :
bash run_macos.sh (utilisera l'utilisateur spécifié dans _current-user.json, les configurations dans "Public", les journaux dans "logs")bash run_macos.sh --User "single-model-assistant" (par défaut, public pour les configurations et "log" pour les journaux)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (utilisera simplement la valeur par défaut pour les "logs"bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"Ces arguments facultatifs permettent aux utilisateurs de lancer plusieurs instances de WilmerAI, chaque instance utilisant un profil utilisateur différent, se connectant à un endroit différent et spécifiant des configurations à un emplacement différent, si vous le souhaitez.
Dans Public/Configs, vous trouverez une série de dossiers contenant des fichiers json. Les deux dossiers qui vous intéressent le plus sont le dossier Endpoints et le dossier Users .
REMARQUE : Les nœuds de flux de travail factuels des utilisateurs assistant-single-model , assistant-multi-model et group-chat-example tenteront d'utiliser le projet OfflineWikipediaTextApi pour extraire des articles Wikipédia complets vers RAG. Si vous ne disposez pas de cette API, le flux de travail ne devrait poser aucun problème, mais j'utilise personnellement cette API pour améliorer les réponses factuelles que je reçois. Vous pouvez spécifier l'adresse IP de votre API dans le json utilisateur de votre choix.
Tout d'abord, choisissez le modèle d'utilisateur que vous souhaitez utiliser :
assistant-single-model : ce modèle est destiné à un seul petit modèle utilisé sur tous les nœuds. Celui-ci propose également des itinéraires pour de nombreux types de catégories différents et utilise des préréglages appropriés pour chaque nœud. Si vous vous demandez pourquoi il y a des itinéraires pour différentes catégories alors qu'il n'y a qu'un seul modèle : c'est pour que vous puissiez donner à chaque catégorie ses propres préréglages, et aussi pour que vous puissiez créer des workflows personnalisés pour elles. Peut-être souhaitez-vous que le codeur fasse plusieurs itérations pour se vérifier, ou que le raisonnement réfléchisse aux choses en plusieurs étapes.
assistant-multi-model : Ce modèle permet d'utiliser de nombreux modèles en tandem. En regardant les points de terminaison de cet utilisateur, vous pouvez voir que chaque catégorie a son propre point de terminaison. Rien ne vous empêche de réutiliser la même API pour plusieurs catégories. Par exemple, vous pouvez utiliser Llama 3.1 70b pour le codage, les mathématiques et le raisonnement, et Command-R 35b 08-2024 pour la catégorisation, la conversation et les faits. N'ayez pas l'impression d'avoir BESOIN de 10 modèles différents. C'est simplement pour vous permettre d'en amener autant si vous le souhaitez. Cet utilisateur utilise les préréglages appropriés pour chaque nœud des flux de travail.
convo-roleplay-single-model : cet utilisateur utilise un modèle unique avec un flux de travail personnalisé qui est bon pour les conversations et devrait être bon pour le jeu de rôle (en attente de commentaires pour le peaufiner si nécessaire). Cela contourne tout le routage.
convo-roleplay-dual-model : cet utilisateur utilise deux modèles avec un flux de travail personnalisé qui est bon pour les conversations et devrait être bon pour le jeu de rôle (en attente de commentaires pour le peaufiner si nécessaire). Cela contourne tout le routage. REMARQUE : ce flux de travail fonctionne mieux si vous disposez de 2 ordinateurs pouvant exécuter des LLM. Avec la configuration actuelle pour cet utilisateur, lorsque vous envoyez un message à Wilmer, le modèle de répondeur (ordinateur 1) vous répondra. Ensuite, le flux de travail appliquera un « verrouillage du flux de travail » à ce stade. Le modèle de mémoire/résumé de discussion (ordinateur 2) commencera alors à mettre à jour les souvenirs et le résumé de la conversation jusqu'à présent, qui sont transmis au répondeur pour l'aider à se souvenir des éléments. Si vous deviez envoyer une autre invite pendant l'écriture des mémoires, le répondeur (ordinateur 1) récupérera le résumé existant et poursuivra et vous répondra. Le verrouillage du flux de travail vous empêchera d'accéder à nouveau à la section des nouveaux souvenirs. Cela signifie que vous pouvez continuer à parler à votre modèle de répondeur pendant que de nouveaux souvenirs sont en cours d'écriture. Il s’agit d’une ÉNORME amélioration des performances. Je l'ai essayé et pour moi, les temps de réponse ont été incroyables. Sans cela, j'obtiens des réponses en 30 secondes 3 à 5 fois, puis j'attends soudainement 2 minutes pour générer des souvenirs. Avec cela, chaque message dure 30 secondes, à chaque fois, sur Llama 3.1 70b sur mon Mac Studio.
group-chat-example : Cet utilisateur est un exemple de mes propres discussions de groupe personnelles. Les personnages et les groupes inclus sont des personnages et des groupes réels que j'utilise. Vous pouvez trouver les exemples de caractères dans le dossier Docs/SillyTavern . Ce sont des caractères compatibles SillyTavern que vous pouvez importer directement dans ce programme ou dans tout programme prenant en charge les types d'importation de caractères .png. Les personnages de l'équipe de développement n'ont qu'un seul nœud par workflow : ils vous répondent simplement. Les personnages du groupe consultatif ont 2 nœuds par flux de travail : le premier nœud génère une réponse et le deuxième nœud applique le "persona" du personnage (le point final en charge de cela est le point final businessgroup-speaker ). Les personnages de discussion de groupe aident beaucoup à varier les réponses que vous obtenez, même si vous n'utilisez qu'un seul modèle. Cependant, mon objectif est d'utiliser des modèles différents pour chaque personnage (mais en réutilisant des modèles entre les groupes ; ainsi, par exemple, j'ai un personnage modèle Llama 3.1 70b dans chaque groupe).
Une fois que vous avez sélectionné l'utilisateur que vous souhaitez utiliser, vous devez effectuer quelques étapes :
Mettez à jour les points de terminaison de votre utilisateur sous Public/Configs/Endpoints. Les exemples de caractères sont triés dans des dossiers pour chacun. Le dossier du point de terminaison de l'utilisateur est spécifié au bas de son fichier user.json. Vous souhaiterez remplir chaque point de terminaison de manière appropriée pour les LLM que vous utilisez. Vous pouvez trouver quelques exemples de points de terminaison dans le dossier _example-endpoints .
Vous devrez définir votre utilisateur actuel. Vous pouvez le faire lors de l'exécution du fichier bat/sh/py en utilisant l'argument --User, ou vous pouvez le faire dans Public/Configs/Users/_current-user.json. Mettez simplement le nom de l'utilisateur en tant qu'utilisateur actuel et enregistrez.
Vous souhaiterez ouvrir votre fichier json utilisateur et jeter un œil aux options. Ici, vous pouvez définir si vous souhaitez ou non diffuser, définir l'adresse IP de votre API wiki hors ligne (si vous l'utilisez), spécifier où vous souhaitez que vos souvenirs/fichiers de résumé aillent pendant les flux DiscussionId, et également spécifier où vous souhaitez que la base de données sqllite disparaisse si vous utilisez des verrous de flux de travail.
C'est ça! Exécutez Wilmer, connectez-vous-y et vous devriez être prêt à partir.
Tout d’abord, nous allons configurer les points de terminaison et les modèles. Dans le dossier Public/Configs, vous devriez voir les sous-dossiers suivants. Passons en revue ce dont vous avez besoin.
Ces fichiers de configuration représentent les points de terminaison de l'API LLM auxquels vous êtes connecté. Par exemple, le fichier JSON suivant, SmallModelEndpoint.json , définit un point de terminaison :
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}Ces fichiers de configuration représentent les différents types d'API que vous pourriez utiliser lors de l'utilisation de Wilmer.
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
} Ces fichiers spécifient le modèle d'invite pour un modèle. Prenons l'exemple suivant, llama3.json :
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
} Ces modèles sont appliqués à tous les appels de point de terminaison v1/Completion. Si vous préférez ne pas utiliser de modèle, il existe un fichier appelé _chatonly.json qui divise les messages uniquement avec des nouvelles lignes.
La création et l'activation d'un utilisateur implique quatre étapes principales. Suivez les instructions ci-dessous pour configurer un nouvel utilisateur.
Tout d’abord, dans le dossier Users , créez un fichier JSON pour le nouvel utilisateur. Le moyen le plus simple de procéder consiste à copier un fichier JSON utilisateur existant, à le coller en double, puis à le renommer. Voici un exemple de fichier JSON utilisateur :
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0 , le rendant visible sur votre réseau s'il est exécuté sur un autre ordinateur. L'exécution de plusieurs instances de Wilmer sur différents ports est prise en charge.true , le routeur est désactivé et toutes les invites vont uniquement au flux de travail spécifié, ce qui en fait une instance de flux de travail unique de Wilmer.customWorkflowOverride est true .Routing , sans l'extension .json .DiscussionId .chatCompleteAddUserAssistant est true .DataFinder du groupe d'exemple. Ensuite, mettez à jour le fichier _current-user.json pour spécifier l'utilisateur que vous souhaitez utiliser. Faites correspondre le nom du fichier JSON du nouvel utilisateur, sans l'extension .json .
REMARQUE : vous pouvez ignorer cela si vous souhaitez utiliser l'argument --User lors de l'exécution de Wilmer.
Créez un fichier JSON de routage dans le dossier Routing . Ce fichier peut être nommé comme vous le souhaitez. Mettez à jour la propriété routingConfig dans votre fichier JSON utilisateur avec ce nom, moins l'extension .json . Voici un exemple de fichier de configuration de routage :
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json , déclenché si la catégorie est choisie. Dans le dossier Workflow , créez un nouveau dossier qui correspond au nom d'utilisateur du dossier Users . Le moyen le plus rapide de procéder consiste à copier le dossier d'un utilisateur existant, à le dupliquer et à le renommer.
Si vous choisissez de n’apporter aucune autre modification, vous devrez parcourir les flux de travail et mettre à jour les points de terminaison pour qu’ils pointent vers le point de terminaison souhaité. Si vous utilisez un exemple de flux de travail ajouté avec Wilmer, tout devrait déjà bien se passer ici.
Dans le dossier « Public », vous devriez avoir :
Les workflows de ce projet sont modifiés et contrôlés dans le dossier Public/Workflows , dans le dossier workflows spécifique de votre utilisateur. Par exemple, si votre utilisateur s'appelle socg et que vous avez un fichier socg.json dans le dossier Users , alors dans les workflows, vous devriez avoir un dossier Workflows/socg .
Voici un exemple de ce à quoi pourrait ressembler un workflow JSON :
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
]Le workflow ci-dessus est composé de nœuds de conversation. Les deux nœuds font une chose simple : envoyer un message au LLM spécifié au point de terminaison.
title . Il est utile de nommer ceux-ci se terminant par « Un », « Deux », etc., pour suivre le résultat de l'agent. La sortie du premier nœud est enregistrée dans {agent1Output} , la seconde dans {agent2Output} , et ainsi de suite.Endpoints , sans l'extension .json .Presets , sans l'extension .json .false (voir le premier exemple de nœud ci-dessus). Si vous envoyez une invite, définissez-la sur true (voir le deuxième exemple de nœud ci-dessus). NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
Vous pouvez utiliser plusieurs variables dans ces invites. Ceux-ci seront remplacés de manière appropriée au moment de l'exécution:
{chat_user_prompt_last_one} : le dernier message de la conversation, sans balises de modèle invite enveloppe le message.{templated_user_prompt_last_one} : le dernier message de la conversation, enveloppé dans les balises de modèle d'invite utilisateur / assistant appropriées.{chat_system_prompt} : l'invite du système envoyé de l'avant. Contient souvent une carte de caractère et d'autres informations importantes.{templated_system_prompt} : l'invite du système de la frontale, enveloppée dans la balise de modèle d'invite système appropriée.{agent#Output} : # est remplacé par le numéro que vous souhaitez. Chaque nœud génère une sortie d'agent. Le premier nœud est toujours 1, et chaque nœud suivant incréments de 1. Par exemple, {agent1Output} pour le premier nœud, {agent2Output} pour la seconde, etc.{category_colon_descriptions} : tire les catégories et les descriptions de votre fichier JSON Routing .{categoriesSeparatedByOr} : tire les noms de catégorie, séparés par "ou".[TextChunk] : une variable spéciale unique au processeur parallèle, probablement non utilisée souvent.Remarque: Pour une compréhension plus approfondie du fonctionnement des souvenirs, veuillez consulter la section Memories Comprendre
Ce nœud tirera n nombre de souvenirs (ou messages les plus récents si aucune discussion n'est présente) et ajoutera un délimiteur personnalisé entre eux. Donc, si vous avez un fichier de mémoire avec 3 souvenirs, et choisissez un délimiteur de " n --------- n", vous pourriez obtenir ce qui suit:
This is the first memory
---------
This is the second memory
---------
This is the third memory
La combinaison de ce nœud avec le résumé du chat peut permettre au LLM de recevoir non seulement la ventilation résumée de toute la conversation dans son ensemble, mais aussi une liste de toutes les souvenirs dont le résumé a été construit, qui peut contenir des informations plus détaillées et granulaires sur il. L'envoi de ceux-ci ensemble, aux côtés des 15 à 20 derniers messages, peut créer l'impression d'une mémoire continue et persistante de l'ensemble du chat avec les messages les plus récents. Des soins particuliers pour élaborer de bonnes invites pour la génération des souvenirs peuvent aider à garantir que les détails qui vous tiennent à propos sont capturés, tandis que les détails moins pertinents sont ignorés.
Ce nœud ne générera pas de nouveaux souvenirs; C'est ainsi que les verrous du flux de travail peuvent être respectés si vous les utilisez sur une configuration multi-ordinateur. Actuellement, la meilleure façon de générer des souvenirs est le nœud FullChatsummary.


