synthetic data generator
0.2.3
Changer de langue : 简体中文 | Dernières documentations API | Feuille de route | Rejoignez le groupe Wechat
Exemples Colab : LLM : Synthèse de données | LLM : Inférence hors table | Prise en charge de données au niveau d'un milliard CTGAN
Le Générateur de données synthétiques (SDG) est un cadre spécialisé conçu pour générer des données tabulaires structurées de haute qualité.
Les données synthétiques ne contiennent aucune information sensible, mais elles conservent les caractéristiques essentielles des données originales, ce qui les rend exemptées des réglementations en matière de confidentialité telles que le RGPD et l'ADPPA.
Des données synthétiques de haute qualité peuvent être utilisées en toute sécurité dans divers domaines, notamment le partage de données, la formation et le débogage de modèles, le développement et les tests de systèmes, etc.
Nous sommes ravis de vous accueillir ici et attendons avec impatience vos contributions. Lancez-vous dans le projet grâce à ce guide de présentation des contributions !
Nos principales réalisations et calendriers actuels sont les suivants :
21 novembre 2024 : 1) Intégration du modèle - Nous avons intégré le modèle GaussianCopula dans notre système de traitement de données. Consultez l'exemple de code dans ce PR ; 2) Qualité synthétique - Nous avons implémenté la détection automatique des relations entre les colonnes de données et autorisé la spécification des relations, amélioré la qualité des données synthétiques (exemple de code) ; 3) Amélioration des performances - Nous avons considérablement réduit l'utilisation de la mémoire de GaussianCopula lors de la gestion de données discrètes, permettant ainsi l'entraînement sur des milliers d'entrées de données catégorielles avec une configuration 2C4G !
30 mai 2024 : Le module Processeur de données a été officiellement fusionné. Ce module : 1) aidera SDG à convertir le format de certaines colonnes de données (telles que les colonnes Datetime) avant de les intégrer au modèle (afin d'éviter d'être traité comme des types discrets) et à convertir de manière inverse les données générées par le modèle dans le format d'origine. ; 2) effectuer un pré-traitement et un post-traitement plus personnalisés sur différents types de données ; 3) gérer facilement des problèmes tels que les valeurs nulles dans les données originales ; 4) prend en charge le système de plug-in.
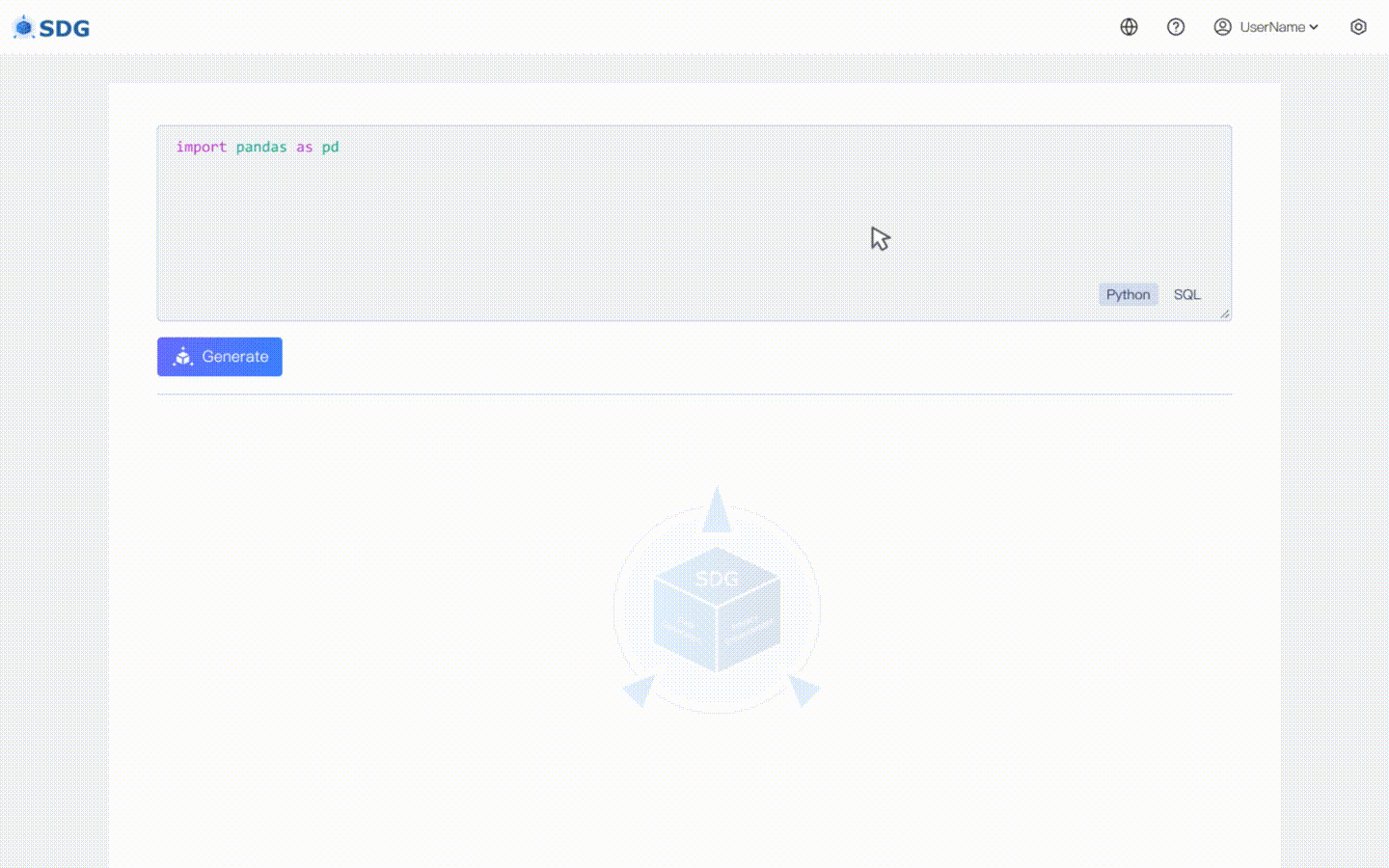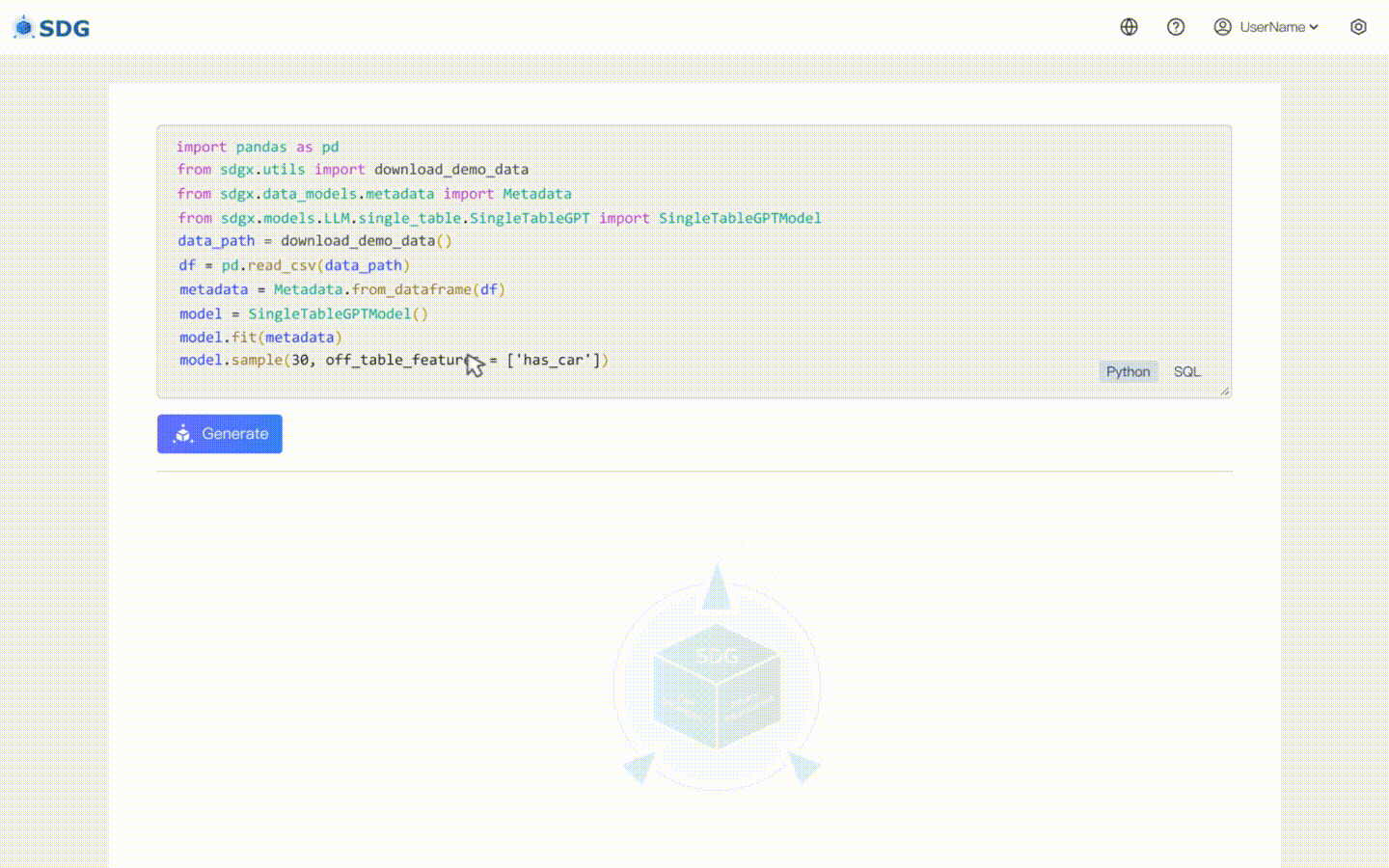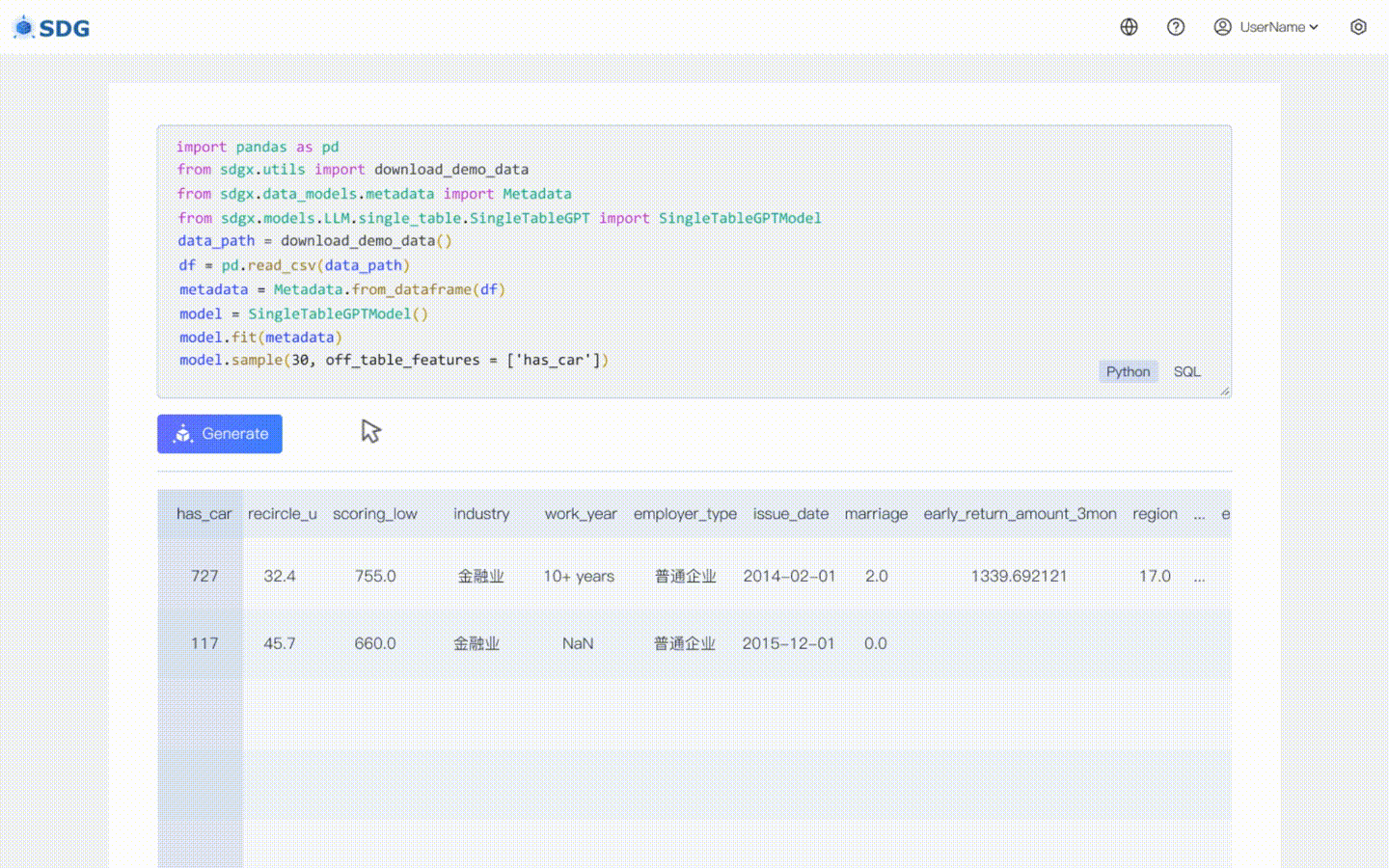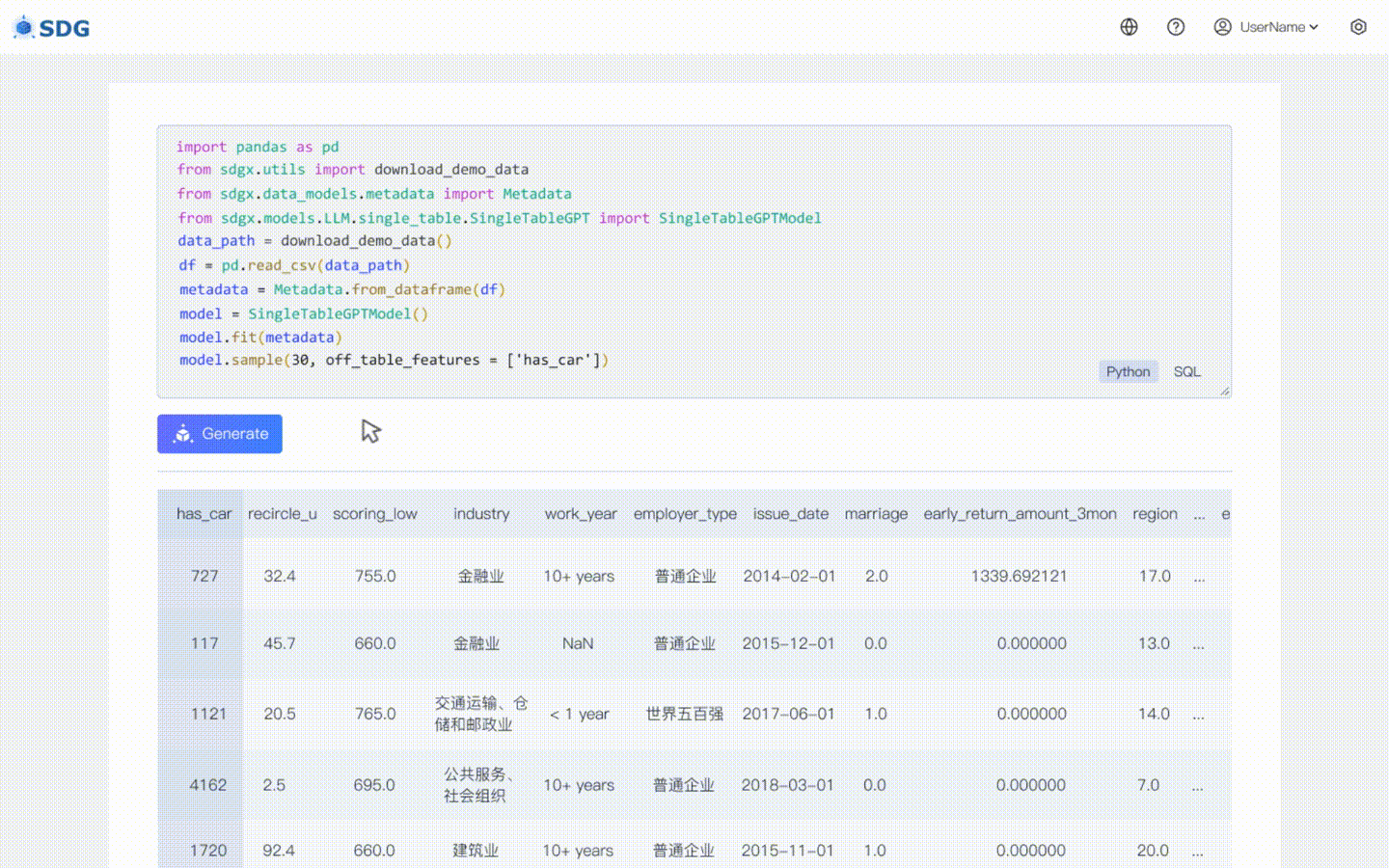
20 février 2024 : un modèle de synthèse de données à table unique basé sur LLM est inclus, voir l'exemple de Colab : LLM : synthèse de données et LLM : inférence de fonctionnalités hors table.
7 février 2024 : Nous avons amélioré sdgx.data_models.metadata pour prendre en charge les informations de métadonnées décrivant des tables uniques et plusieurs tables, prendre en charge plusieurs types de données et prendre en charge l'inférence automatique de types de données. Voir l'exemple de Colab : Métadonnées à table unique SDG.
20 décembre 2023 : sortie de la v0.1.0, un modèle CTGAN qui prend en charge des milliards de capacités de traitement de données est inclus, consultez notre référence par rapport à SDV, où SDG a réalisé moins de consommation de mémoire et a évité les plantages pendant l'entraînement. Pour une utilisation spécifique, consultez l'exemple de Colab : CTGAN pris en charge par Billion-Level-Data.
10 août 2023 : première ligne du code ODD validée.
Depuis longtemps, le LLM est utilisé pour comprendre et générer différents types de données. En fait, LLM possède également certaines capacités de génération de données tabulaires. En outre, il possède certaines capacités qui ne peuvent pas être obtenues par les méthodes traditionnelles (basées sur les méthodes GAN ou les méthodes statistiques).
Notre sdgx.models.LLM.single_table.gpt.SingleTableGPTModel implémente deux nouvelles fonctionnalités :
Aucune donnée de formation n'est requise, des données synthétiques peuvent être générées sur la base de données de métadonnées, voir dans notre exemple de collaboration.
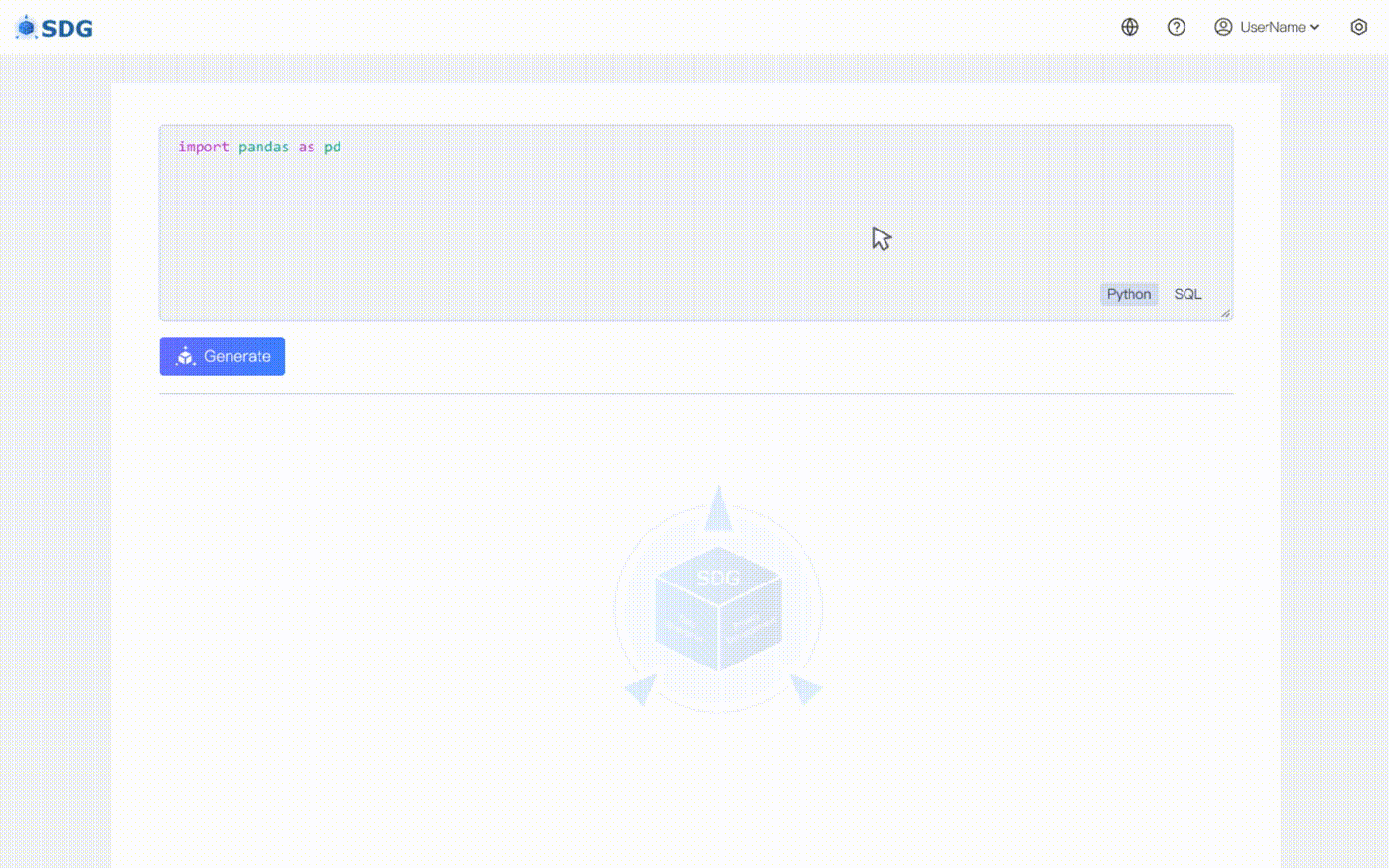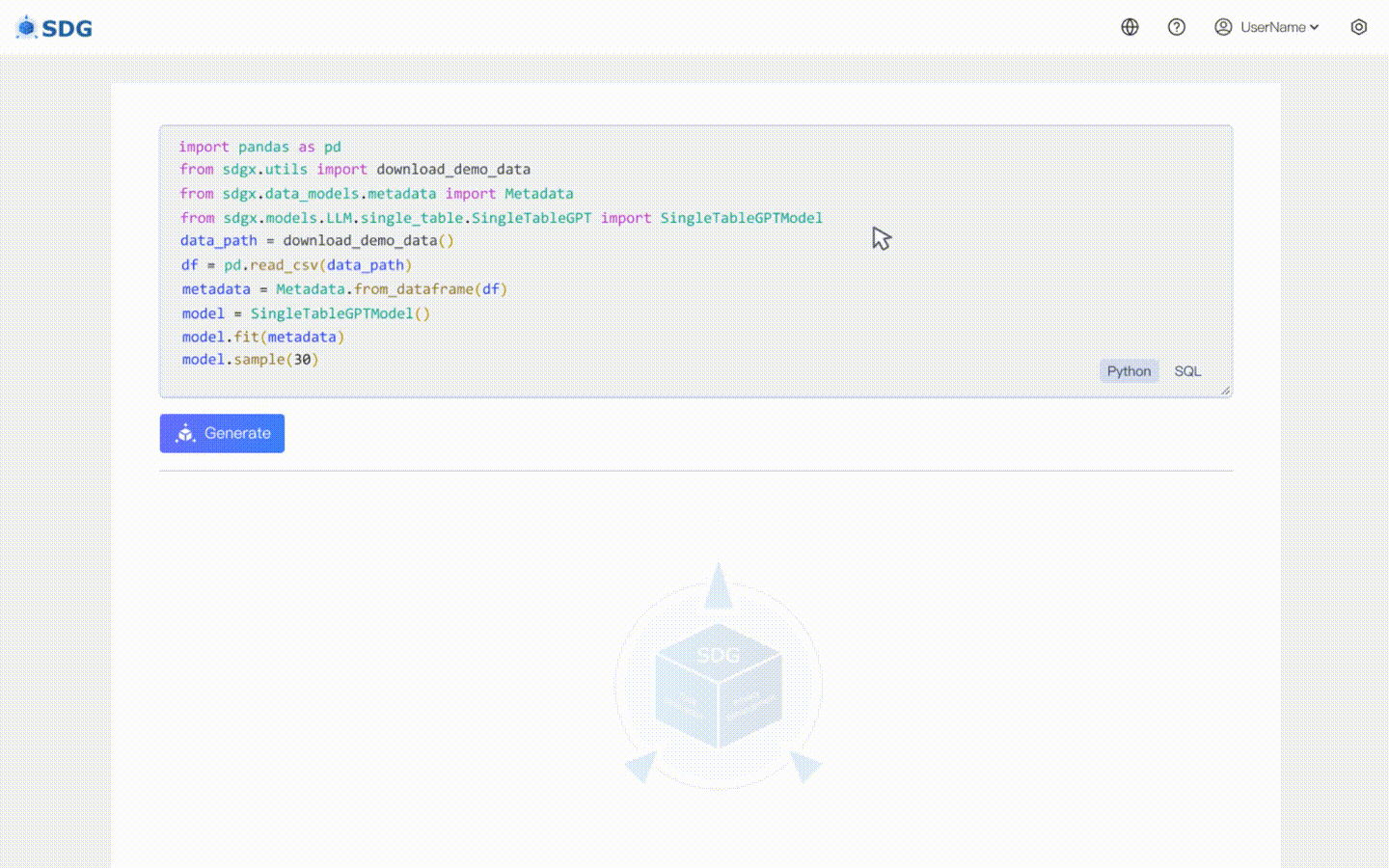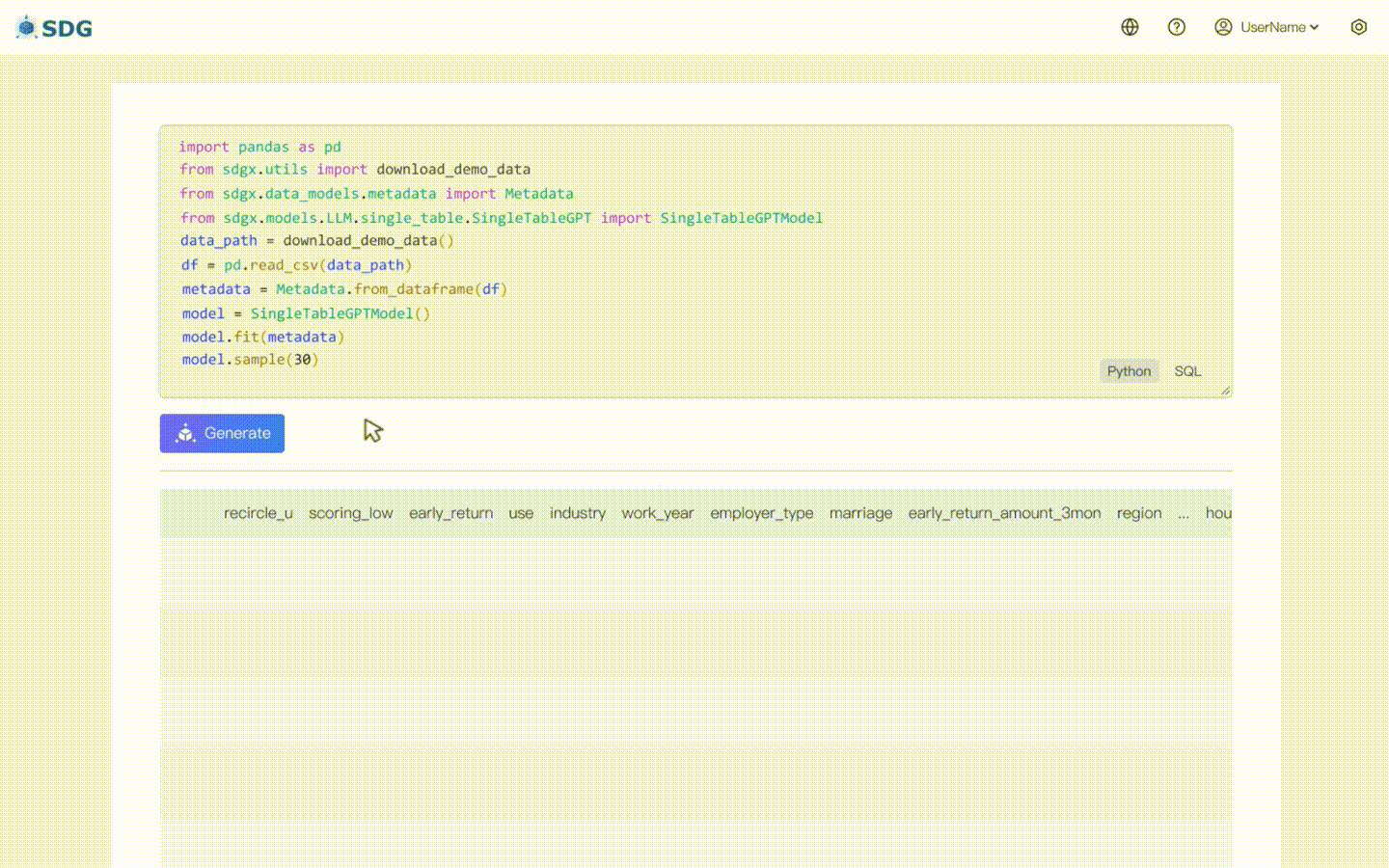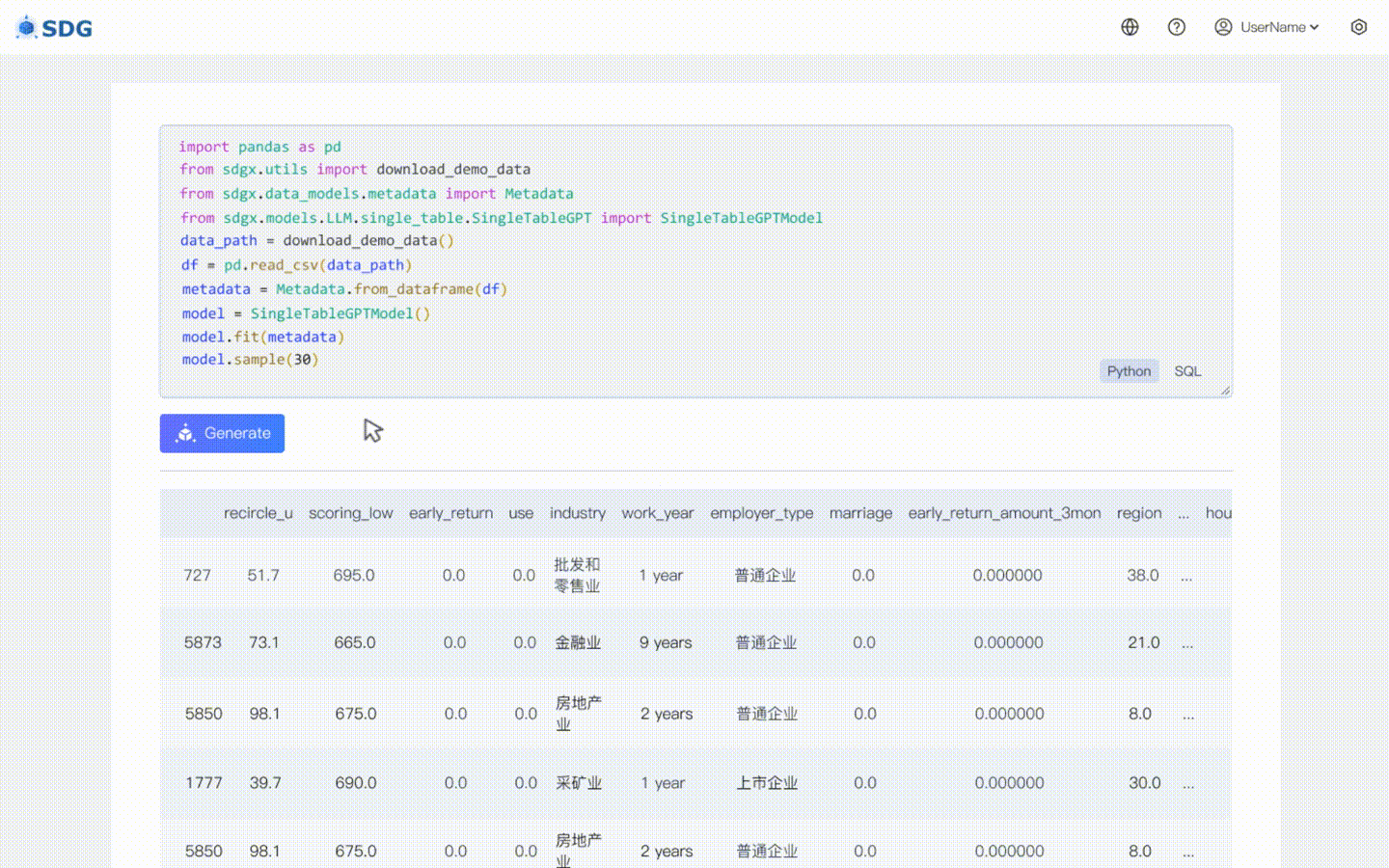
Déduisez de nouvelles données de colonne en fonction des données existantes dans le tableau et des connaissances maîtrisées par LLM, voir dans notre exemple colab.
Avancées technologiques :
Prend en charge un large éventail d'algorithmes de synthèse de données statistiques, un modèle de génération de données synthétiques basé sur LLM est également intégré ;
Optimisé pour le Big Data, réduisant efficacement la consommation de mémoire ;
Suivre en permanence les dernières avancées dans le monde universitaire et industriel, et introduire en temps opportun la prise en charge d'excellents algorithmes et modèles.
Améliorations de la confidentialité :
SDG prend en charge la confidentialité différentielle, l'anonymisation et d'autres méthodes pour améliorer la sécurité des données synthétiques.
Facile à étendre :
Prend en charge l'extension des modèles, le traitement des données, les connecteurs de données, etc. sous la forme de packages de plug-ins.
Vous pouvez utiliser des images prédéfinies pour découvrir rapidement les dernières fonctionnalités.
docker pull idsteam/sdgx:dernier
pip installer sdgx
Utilisez SDG en l'installant via le code source.
git clone [email protected]:hitsz-ids/synthetic-data-generator.git pip install .# Ou installer depuis gitpip install git+https://github.com/hitsz-ids/synthetic-data-generator.git
from sdgx.data_connectors.csv_connector import CsvConnectorfrom sdgx.models.ml.single_table.ctgan import CTGANSynthesizerModelfrom sdgx.synthesizer import Synthesizerfrom sdgx.utils import download_demo_data# Cela téléchargera les données de démonstration vers ./datasetdataset_csv = download_demo_data()# Créer un connecteur de données pour csv filedata_connector = CsvConnector(path=dataset_csv)# Initialisez le synthétiseur, utilisez CTGAN modelsynthesizer = Synthesizer(model=CTGANSynthesizerModel(epochs=1), # Pour un demodata_connector=data_connector rapide, )# Ajuster les modèlesynthesizer.fit()# Samplesampled_data = synthétiseur.sample(1000)print(sampled_data)
Les données réelles sont les suivantes :
>>> data_connector.read() âge classe de travail fnlwgt éducation ... perte de capital heures par semaine classe du pays d'origine0 2 State-gov 77516 Bachelors ... 0 2 États-Unis <=50K1 3 Self-emp-not-inc 83311 Bachelors .. 0 0 États-Unis <=50K2 2 Privé 215646 HS-grad ... 0 2 États-Unis <=50K3 3 Privé 234721 11e ... 0 2 États-Unis <=50K4 1 Privé 338409 Célibataires ... 0 2 Cuba <=50K... ... ... ... ... ... . .. ... ... ...48837 2 Privé 215419 Licences ... 0 2 États-Unis <=50K48838 4 NaN 321403 HS-grad ... 0 2 États-Unis <=50K48839 2 Privé 374983 Bachelors ... 0 3 États-Unis <=50K48840 2 Privé 83891 Bachelors ... 0 2 États-Unis <=50K48841 1 Self-emp-inc 182148 Bachelors . .. 0 3 États-Unis >50K[48842 lignes x 15 colonnes]
Les données synthétiques sont les suivantes :
>>> sampled_data âge classe de travail fnlwgt éducation ... perte de capital heures par semaine classe du pays d'origine0 1 NaN 28219 Certains étudiants ... 0 2 Porto-Rico <=50K1 2 Privé 250166 HS-grad ... 0 2 États-Unis >50K2 2 Privé 50304 HS-grad ... 0 2 États-Unis <=50K3 4 Privé 89318 Bachelors ... 0 2 Porto-Rico >50K4 1 Privé 172149 Bachelors ... 0 3 Etats-Unis <=50K.. ... ... ... ... ... ... ... ... ...995 2 NaN 208938 Licences ... 0 1 États-Unis <=50K996 2 Privé 166416 Licences ... 2 2 États-Unis <=50K997 2 NaN 336022 HS-grad ... 0 1 États-Unis <=50K998 3 Privé 198051 Masters ... 0 2 États-Unis >50K999 1 NaN 41973 HS-grad ... 0 2 États-Unis <= 50 000 [1 000 lignes x 15 colonnes]
CTGAN:Modélisation de données tabulaires à l'aide du GAN conditionnel
C3-TGAN : C3-TGAN - Synthèse de données tabulaires contrôlables avec corrélations explicites et contraintes de propriété
TVAE:Modélisation de données tabulaires à l'aide du GAN conditionnel
table-GAN:Synthèse de données basée sur des réseaux contradictoires génératifs
CTAB-GAN:CTAB-GAN : synthèse efficace des données de table
OCT-GAN : OCT-GAN : GAN tabulaires conditionnels basés sur l'ODE neuronale
Le projet SDG a été lancé par l'Institute of Data Security du Harbin Institute of Technology . Si votre projet vous intéresse, n'hésitez pas à rejoindre notre communauté. Nous accueillons les organisations, les équipes et les individus qui partagent notre engagement en faveur de la protection et de la sécurité des données grâce à l'open source :
Lisez CONTRIBUER avant de rédiger une pull request.
Soumettez un problème en consultant View Good First Issue ou soumettez une Pull Request.
Rejoignez notre groupe Wechat via le code QR.


