ssebowa
1.0.0
Ssebowa est une bibliothèque Python open source qui fournit des modèles d'IA génératifs, notamment :
ssebowa-llm: Un grand modèle de langage (LLM) pour la génération de texte,ssebowa-vllm: Un modèle de langage visuel (VLLM) pour la compréhension visuelle,ssebowa-imagen: Un modèle de génération d'images et de réglage fin personnalisé,Ssebowa-vigen: Un modèle de génération vidéo.Avec Ssebowa, vous pouvez facilement générer du texte, traduire des langues, rédiger différents types de contenu créatif, générer des images personnalisées et répondre à vos questions de manière informative.
Pour des informations d'utilisation plus détaillées, veuillez vous référer à : La documentation technique de Ssebowa
Avant d'exécuter le script, assurez-vous que les bibliothèques requises sont installées. Vous pouvez le faire en exécutant les commandes suivantes :
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .Puis installez Ssebowa
pip install ssebowaSi vous exécutez ces commandes dans Colab ou Jupyter Notebook, veuillez utiliser ceci,
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowaDésormais, vous pouvez accéder aux différents modèles en les important depuis la bibliothèque :
Ssebowa-Imagen est un modèle de synthèse d'images open source qui utilise une combinaison de diffusion modeling et generative adversarial networks (GANs) pour générer des images de haute qualité à partir de text descriptions et permet également de transformer vos quelques photos en custom model capable de générer des images époustouflantes du chosen subject . Il exploite un 100 billion dataset d'images et de descriptions textuelles, ce qui lui permet de capturer avec précision les nuances des images du monde réel et de traduire efficacement les descriptions textuelles en représentations visuelles convaincantes.
10-20 high-quality (jpg or png) comme la vôtre, un ami, un produit ou des animaux de compagnie, etc. et placez-les dans un répertoire spécifique.16GB or more . (Si vous peaufinez SDXL, vous aurez besoin de 24 Go de VRAM.) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()Comme générons "Un chat assis sur une étagère"
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm est un modèle de langage visuel en grand format (VLLM) open source développé par Ssebowa AI. C'est un outil puissant qui peut être utilisé pour comprendre les images. Ssebowa-vllm possède 11 milliards de paramètres visuels et 7 milliards de paramètres linguistiques, prenant en charge la compréhension des images à une résolution de 1120*1120.
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)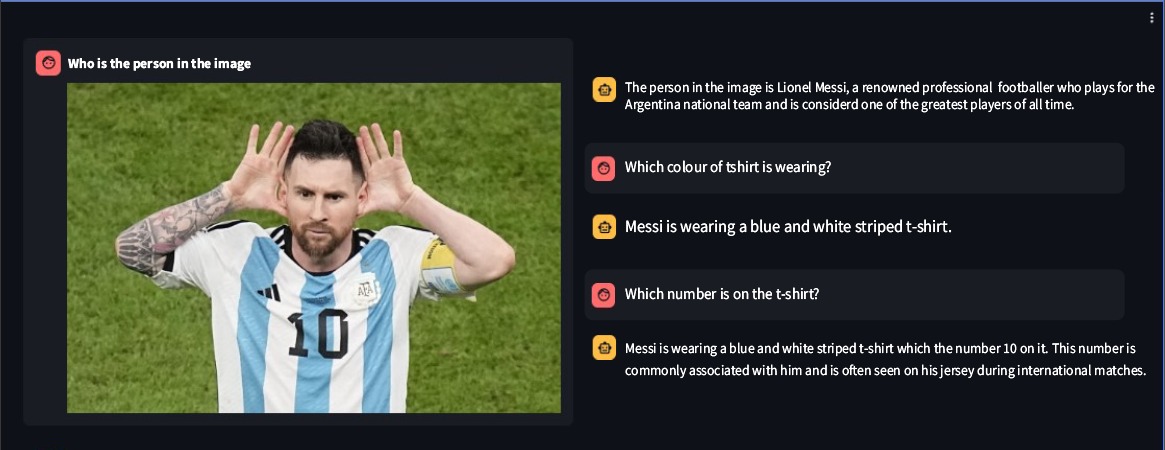
Ssebowa est ouvert aux contributions ! Directives en cours..
Ssebowa est publié sous licence Apache 2.0.
Si vous avez des questions ou des suggestions, n'hésitez pas à ouvrir un ticket sur GitHub ou à nous contacter à [email protected]


