xTuring
0.1.8


xTuring permet un réglage fin rapide, efficace et simple des LLM open source, tels que Mistral, LLaMA, GPT-J, etc. En fournissant une interface facile à utiliser pour affiner les LLM en fonction de vos propres données et applications, xTuring simplifie la création, la modification et le contrôle des LLM. L’ensemble du processus peut être effectué sur votre ordinateur ou dans votre cloud privé, garantissant ainsi la confidentialité et la sécurité des données.
Avec xTuring vous pouvez,
pip install xturing from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset ( "./examples/models/llama/alpaca_data" )
# Initialize the model
model = BaseModel . create ( "llama_lora" )
# Finetune the model
model . finetune ( dataset = instruction_dataset )
# Perform inference
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( "Generated output by the model: {}" . format ( output ))Vous pouvez trouver le dossier de données ici.
Nous sommes ravis d'annoncer les dernières améliorations de notre bibliothèque xTuring :
LLaMA 2 - Vous pouvez utiliser et affiner le modèle LLaMA 2 dans différentes configurations : prêt à l'emploi , prêt à l'emploi avec précision INT8 , réglage fin LoRA , réglage fin LoRA avec précision INT8 et réglage fin LoRA. réglage avec la précision INT4 à l'aide du wrapper GenericModel et/ou vous pouvez utiliser la classe Llama2 de xturing.models pour tester et affiner le modèle. from xturing . models import Llama2
model = Llama2 ()
## or
from xturing . models import BaseModel
model = BaseModel . create ( 'llama2' )Evaluation - Vous pouvez désormais évaluer n'importe quel Causal Language Model sur n'importe quel ensemble de données. Les mesures actuellement prises en charge sont perplexity . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model
model = BaseModel . create ( 'gpt2' )
# Run the Evaluation of the model on the dataset
result = model . evaluate ( dataset )
# Print the result
print ( f"Perplexity of the evalution: { result } " )INT4 Precision - Vous pouvez désormais utiliser et affiner n'importe quel LLM avec INT4 Precision à l'aide de GenericLoraKbitModel . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Run the fine-tuning
model . finetune ( dataset ) # Make the necessary imports
from xturing . models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel . create ( "llama2_int8" )
# Once the model has been quantized, do inferences directly
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( output ) # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Generate outputs on desired prompts
outputs = model . generate ( dataset = dataset , batch_size = 10 )Une exploration de l’exemple de travail Llama LoRA INT4 est recommandée pour comprendre son application.
Pour un aperçu plus approfondi, envisagez d'examiner l'exemple de travail GenericModel disponible dans le référentiel.

$ xturing chat -m " <path-to-model-folder> "
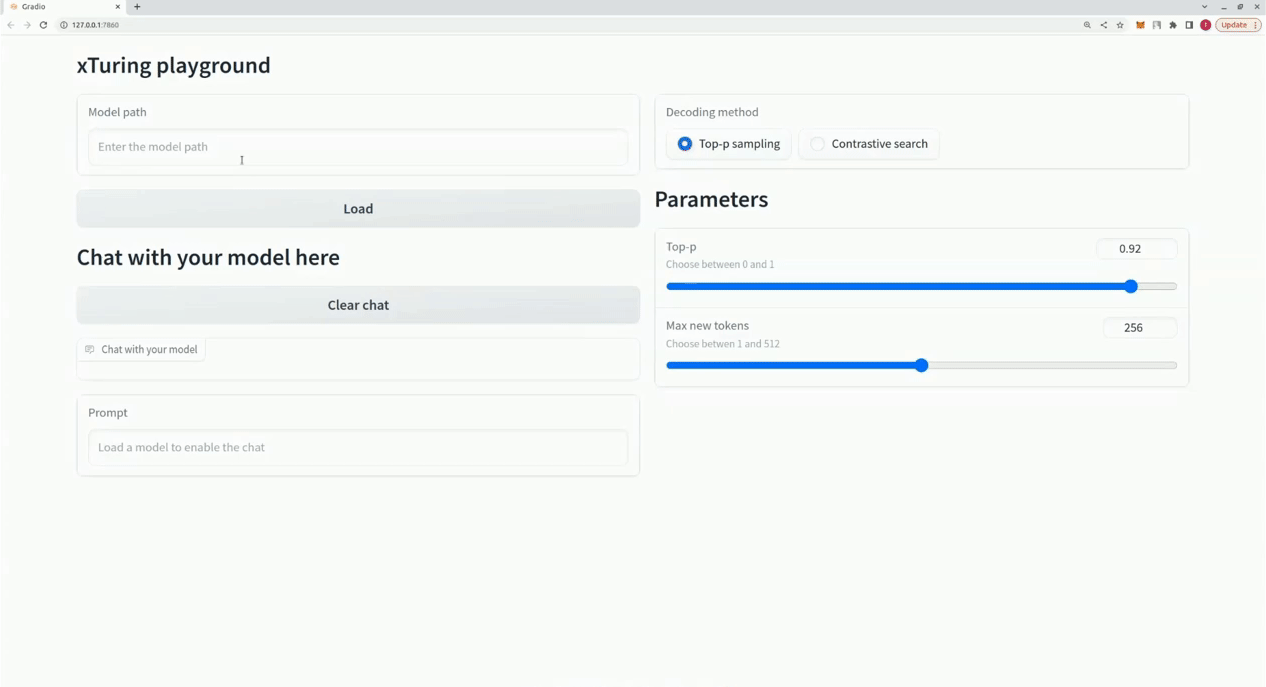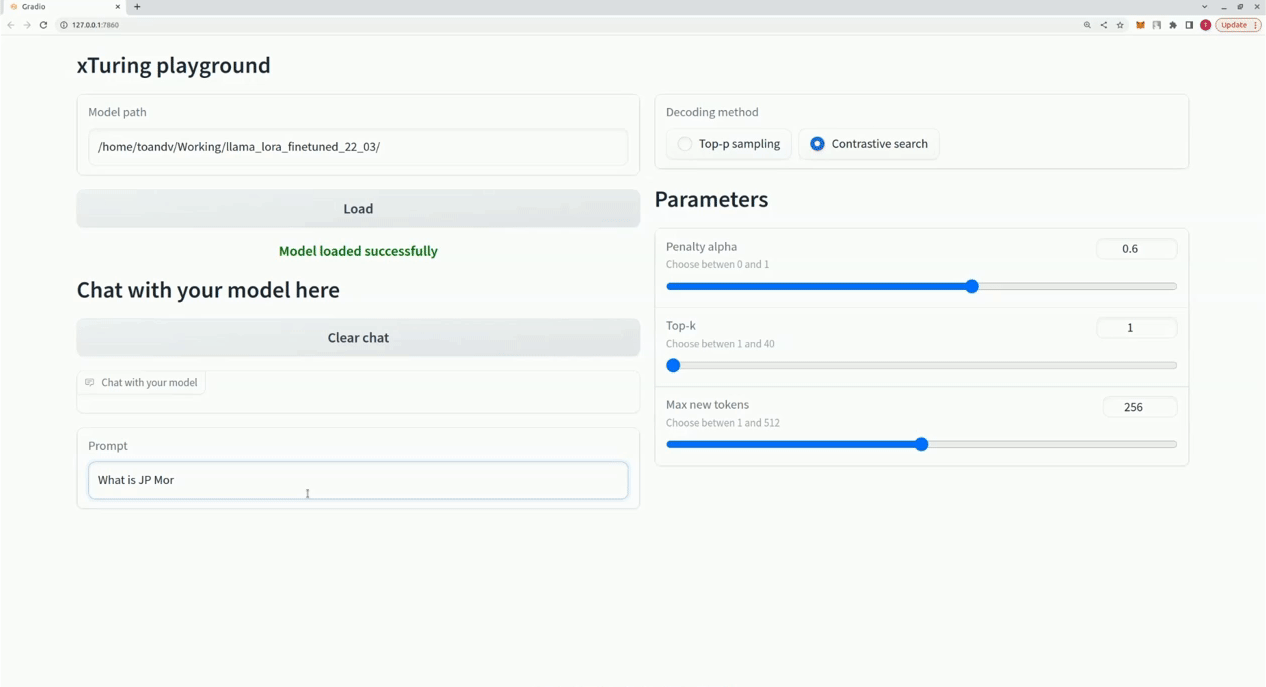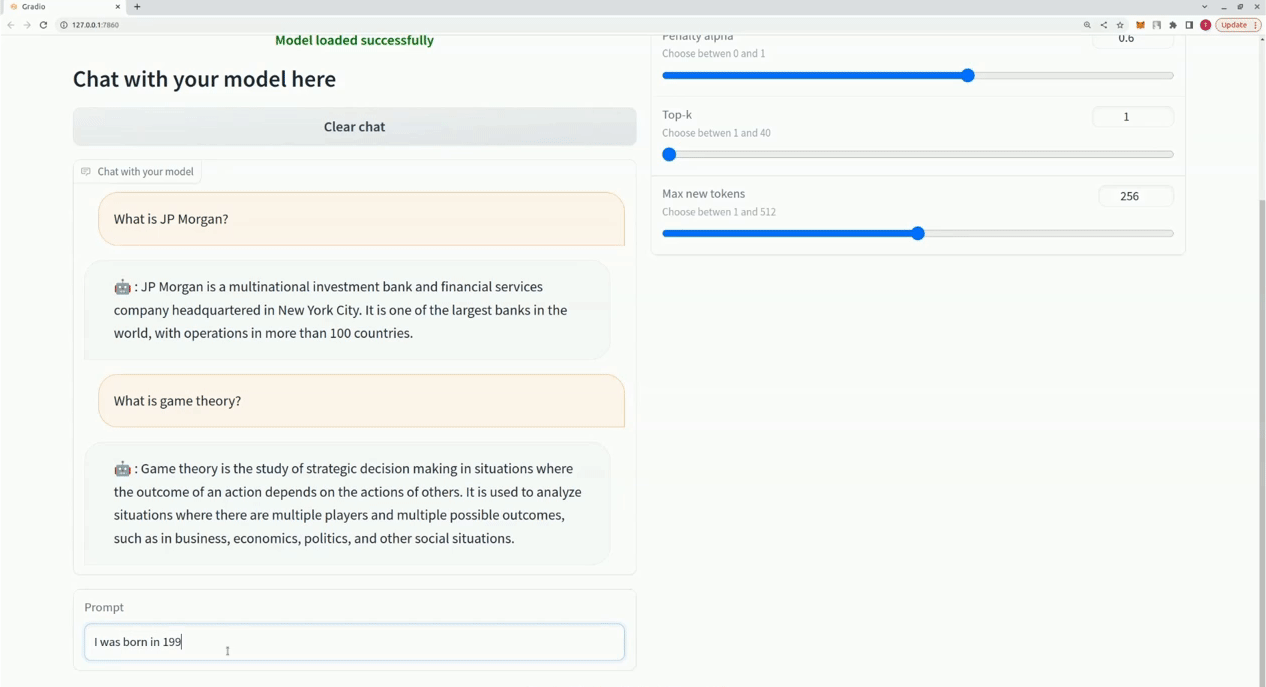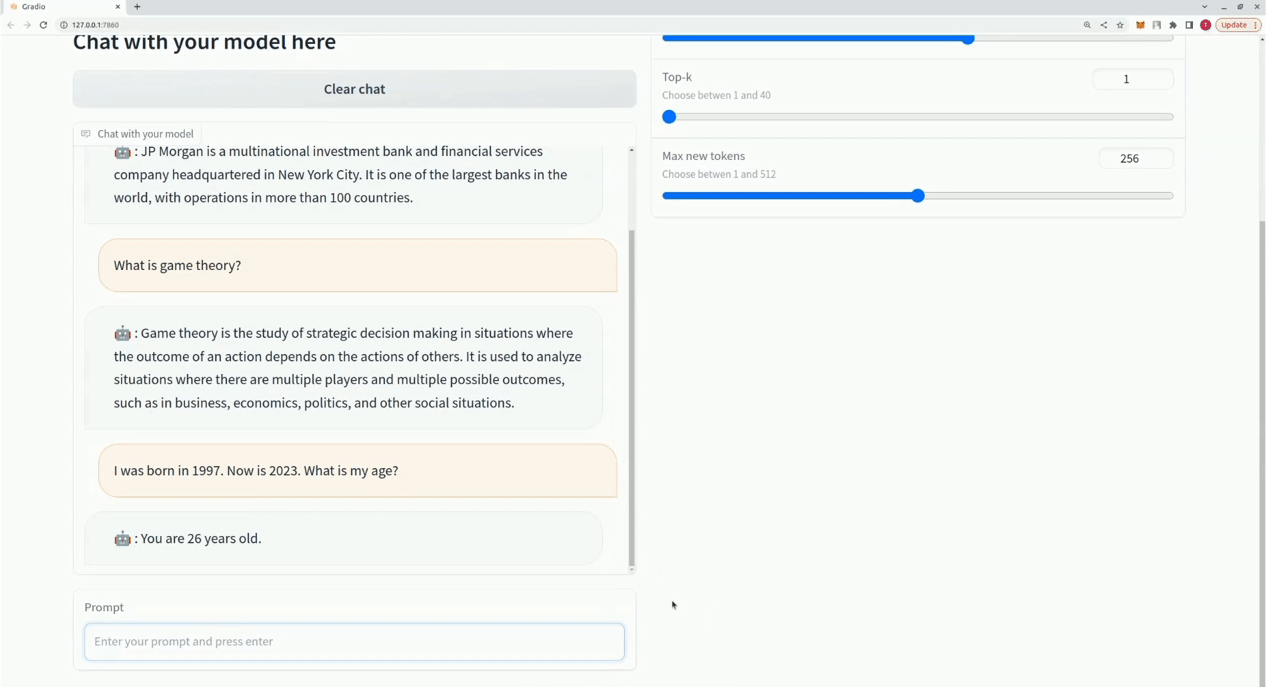
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
from xturing . ui import Playground
dataset = InstructionDataset ( "./alpaca_data" )
model = BaseModel . create ( "<model_name>" )
model . finetune ( dataset = dataset )
model . save ( "llama_lora_finetuned" )
Playground (). launch () ## launches localhost UI Voici une comparaison des performances de différentes techniques de réglage fin sur le modèle LLaMA 7B. Nous utilisons l'ensemble de données Alpaca pour un réglage fin. L'ensemble de données contient 52 000 instructions.
Matériel:
4 GPU A100 de 40 Go, processeur de 335 Go de RAM
Paramètres de réglage fin :
{
'maximum sequence length' : 512 ,
'batch size' : 1 ,
}| LLaMA-7B | DeepSpeed + déchargement du processeur | LoRA + DeepSpeed | LoRA + DeepSpeed + déchargement du processeur |
|---|---|---|---|
| GPU | 33,5 Go | 23,7 Go | 21,9 Go |
| Processeur | 190 Go | 10,2 Go | 14,9 Go |
| Temps/époque | 21 heures | 20 minutes | 20 minutes |
Contribuez à cela en soumettant vos résultats de performances sur d'autres GPU en créant un problème avec vos spécifications matérielles, votre consommation de mémoire et votre temps par époque.
Nous avons déjà peaufiné certains modèles que vous pouvez utiliser comme base ou avec lesquels commencer à jouer. Voici comment vous les chargeriez :
from xturing . models import BaseModel
model = BaseModel . load ( "x/distilgpt2_lora_finetuned_alpaca" )| modèle | ensemble de données | Chemin |
|---|---|---|
| DistilGPT-2 LoRA | alpaga | x/distilgpt2_lora_finetuned_alpaca |
| LLaMA LoRA | alpaga | x/llama_lora_finetuned_alpaca |
Vous trouverez ci-dessous une liste de tous les modèles pris en charge via la classe BaseModel de xTuring et leurs clés correspondantes pour les charger.
| Modèle | Clé |
|---|---|
| Floraison | floraison |
| Cérébraux | cerveaux |
| DistilGPT-2 | distillergpt2 |
| Faucon-7B | faucon |
| Galactique | galactique |
| GPT-J | gptj |
| GPT-2 | gpt2 |
| Lama | lama |
| LlaMA2 | lama2 |
| OPT-1.3B | opter |
Les variantes mentionnées ci-dessus sont les variantes de base des LLM. Vous trouverez ci-dessous les modèles pour obtenir leurs versions LoRA , INT8 , INT8 + LoRA et INT4 + LoRA .
| Version | Modèle |
|---|---|
| LoRA | <model_key>_lora |
| INT8 | <clé_modèle>_int8 |
| INT8 + LoRA | <model_key>_lora_int8 |
** Afin de charger la version INT4+LoRA de n'importe quel modèle, vous devrez utiliser la classe GenericLoraKbitModel de xturing.models . Voici comment l'utiliser :
model = GenericLoraKbitModel ( '<model_path>' ) Le model_path peut être remplacé par votre répertoire local ou par n'importe quel modèle de bibliothèque HuggingFace comme facebook/opt-1.3b .
LLaMA , GPT-J , GPT-2 , OPT , Cerebras-GPT , Galactica et Bloom Generic model Falcon-7B Si vous avez des questions, vous pouvez créer un ticket sur ce référentiel.
Vous pouvez également rejoindre notre serveur Discord et démarrer une discussion sur la chaîne #xturing .
Ce projet est sous licence Apache License 2.0 - voir le fichier LICENSE pour plus de détails.
En tant que projet open source dans un domaine en évolution rapide, nous apprécions les contributions de toutes sortes, y compris les nouvelles fonctionnalités et une meilleure documentation. Veuillez lire notre guide de contribution pour savoir comment vous pouvez vous impliquer.


