SynMeter
1.0.0

[24 novembre 2024] Nous ajoutons un nouveau synthétiseur SOTA HP REaLTabFormer à SynMeter ! Essayez-le !
[18 septembre 2024] Nous ajoutons un nouveau synthétiseur SOTA HP TabSyn à SynMeter ! Essayez-le !
Créez un nouvel environnement Conda et configurez-le :
conda create -n synmeter python==3.9
conda activate synmeter
pip install -r requirements.txt # install dependencies
pip install -e . # package the library Changez le dictionnaire de base dans ./lib/info/ROOT_DIR :
ROOT_DIR = root_to_synmeter
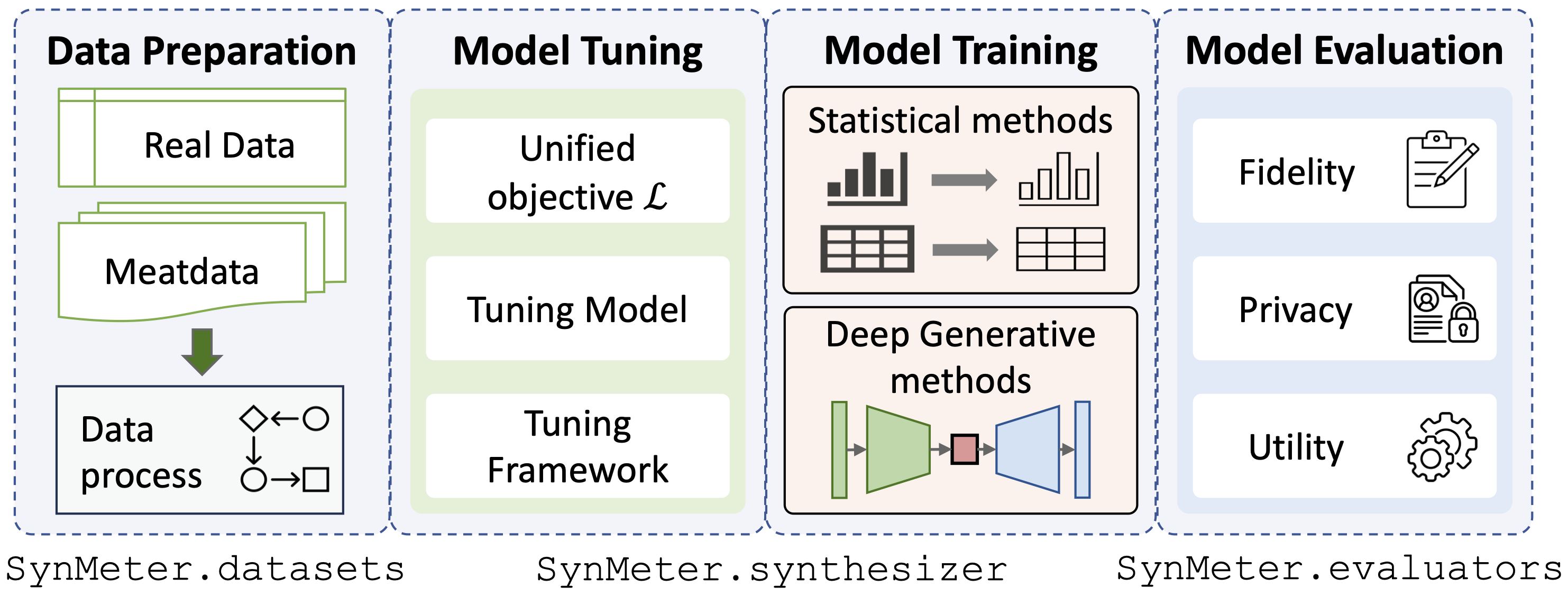
./dataset ../exp/evaluators .python scripts/tune_evaluator.py -d [dataset] -c [cuda]Nous fournissons un objectif de réglage unifié pour le réglage du modèle, ainsi, tous les types de synthétiseurs peuvent être réglés par une seule commande :
python scripts/tune_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda] Après le réglage, une configuration doit être enregistrée dans /exp/dataset/synthesizer , SynMeter peut l'utiliser pour entraîner et stocker le synthétiseur :
python scripts/train_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda]Évaluation de la fidélité des données synthétiques :
python scripts/eval_fidelity.py -d [dataset] -m [synthesizer] -s [seed] -t [target] Évaluation de la confidentialité des données synthétiques :
python scripts/eval_privacy.py -d [dataset] -m [synthesizer] -s [seed]Évaluation de l'utilité des données synthétiques :
python scripts/eval_utility.py -d [dataset] -m [synthesizer] -s [seed] Les résultats des évaluations doivent être enregistrés dans le dictionnaire correspondant /exp/dataset/synthesizer .
L'un des avantages de SynMeter est de fournir le moyen le plus simple d'ajouter de nouveaux algorithmes de synthèse, trois étapes sont nécessaires :
./synthesizer/my_synthesiszer./exp/base_config ../synthesizer , qui contient trois fonctions : train , sample et tune .Ensuite, vous êtes libre de régler, d’exécuter et de tester le nouveau synthétiseur !
| Méthode | Taper | Description | Référence |
|---|---|---|---|
| MST | DP | La méthode utilise des modèles graphiques probabilistes pour apprendre la dépendance des marginaux de faible dimension pour la synthèse des données. | Papier, Code |
| PrivSyn | DP | Un synthétiseur DP non paramétrique, qui met à jour de manière itérative l'ensemble de données synthétiques pour le faire correspondre aux marges de bruit cibles. | Papier, Code |
| Méthode | Taper | Description | Référence |
|---|---|---|---|
| CTGAN | HP | Un réseau contradictoire génératif conditionnel capable de gérer des données tabulaires. | Papier, Code |
| PATE-GAN | DP | La méthode utilise le cadre d'agrégation privée d'ensembles d'enseignants (PATE) et l'applique aux GAN. | Papier, Code |
| Méthode | Taper | Description | Référence |
|---|---|---|---|
| TVAE | HP | Un réseau VAE conditionnel pouvant gérer des données tabulaires. | Papier, Code |
| Méthode | Taper | Description | Référence |
|---|---|---|---|
| OngletDDPM | HP | Utiliser le modèle de diffusion pour la synthèse de données tabulaires | Papier, Code |
| TabSyn | HP | Utilisez le modèle de diffusion latente et le VAE pour la synthèse. | Papier, Code |
| TableDiffusion | DP | Génération d'ensembles de données tabulaires sous confidentialité différentielle. | Papier, Code |
| Méthode | Taper | Description | Référence |
|---|---|---|---|
| Super | HP | Utilisez LLM pour affiner un ensemble de données tabulaires. | Papier, Code |
| REaLTabFormer | HP | Utilisez GPT-2 pour apprendre la dépendance relationnelle des données tabulaires. | Papier, Code |
Métriques de fidélité : nous considérons la distance de Wasserstein comme une métrique de fidélité de principe, qui est calculée par toutes les marginales unidirectionnelles et bidirectionnelles.
Métriques de confidentialité : nous concevons le Membership Disclosure Score (MDS) pour mesurer les risques liés à la confidentialité des membres des synthétiseurs HP et DP.
Métriques d'utilité : nous utilisons l'affinité du machine learning et l'erreur de requête pour mesurer l'utilité des données synthétiques.
Veuillez consulter notre article pour plus de détails et d'utilisations.
De nombreux excellents algorithmes de synthèse et bibliothèques open source sont utilisés dans ce projet :


