AttackVLM
1.0.0
[Page du projet] | [Diapositives] | [arXiv] | [Dépôt de données]
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

Dans notre travail, nous avons utilisé DALL-E, Midjourney et Stable Diffusion pour la génération et la démonstration d'images cibles. Pour les expériences à grande échelle, nous appliquons la diffusion stable pour la génération d’images cibles. Pour installer Stable Diffusion, nous initialisons notre environnement conda en suivant les modèles de diffusion latente. Un environnement conda de base approprié nommé ldm peut être créé et activé avec :
conda env create -f environment.yaml
conda activate ldm
Notez que pour différents modèles de victimes, nous suivrons leurs implémentations officielles et leurs environnements conda.
 Comme indiqué dans notre article, pour réaliser une attaque ciblée flexible, nous exploitons un modèle texte-image pré-entraîné pour générer une image ciblée avec une seule légende comme texte ciblé. Par conséquent, vous pouvez ainsi spécifier vous-même la légende ciblée pour l’attaque !
Comme indiqué dans notre article, pour réaliser une attaque ciblée flexible, nous exploitons un modèle texte-image pré-entraîné pour générer une image ciblée avec une seule légende comme texte ciblé. Par conséquent, vous pouvez ainsi spécifier vous-même la légende ciblée pour l’attaque !
Nous utilisons Stable Diffusion, DALL-E ou Midjourney comme générateurs de texte en image dans nos expériences. Ici, nous utilisons Stable Diffusion pour la démonstration (merci pour l'open source !).
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
Ensuite, préparez les sous-titres ciblés complets à partir de MS-COCO, ou téléchargez notre version traitée et nettoyée :
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
et déplacez-le vers ./stable-diffusion/ . Dans les expériences, on peut échantillonner au hasard un sous-ensemble de légendes COCO (par exemple, 10 , 100 , 1K , 10K , 50K ) pour l'attaque adverse. Par exemple, supposons que nous ayons échantillonné au hasard 10K légendes COCO comme texte ciblé c_tar et que nous les ayons stockées dans le fichier suivant :
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
Les images ciblées h_ξ(c_tar) peuvent être obtenues via Stable Diffusion en lisant l'invite de texte à partir des légendes COCO échantillonnées, avec le script ci-dessous et txt2img_coco.py (veuillez déplacer txt2img_coco.py vers ./stable-diffusion/ , notez que les hyperparamètres peuvent être ajusté selon vos préférences) :
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
où le ckpt est fourni par Stable Diffusion v1 et peut être téléchargé ici : sd-v1-4-full-ema.ckpt.
Des détails supplémentaires sur la mise en œuvre de la génération de texte en image par Stable Diffusion peuvent être trouvés ICI.
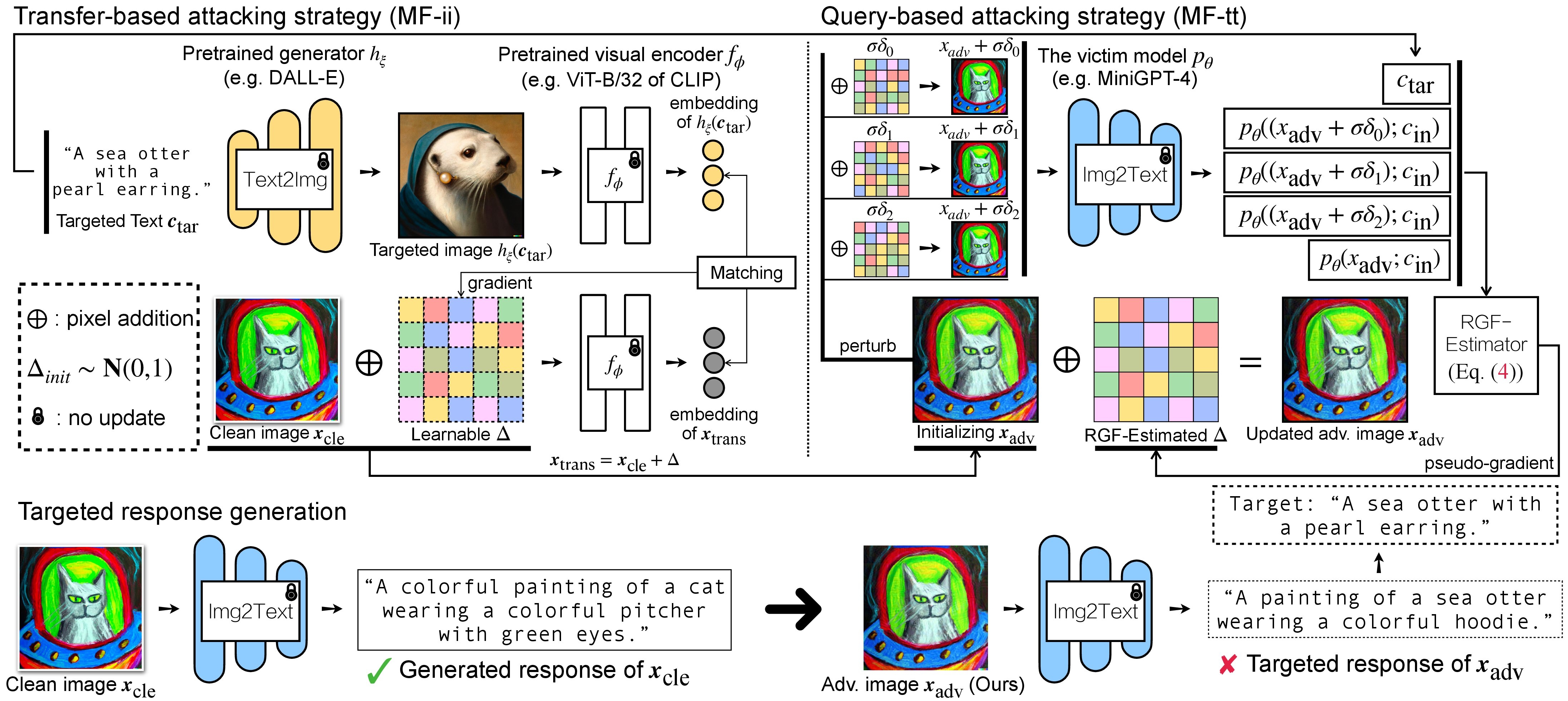
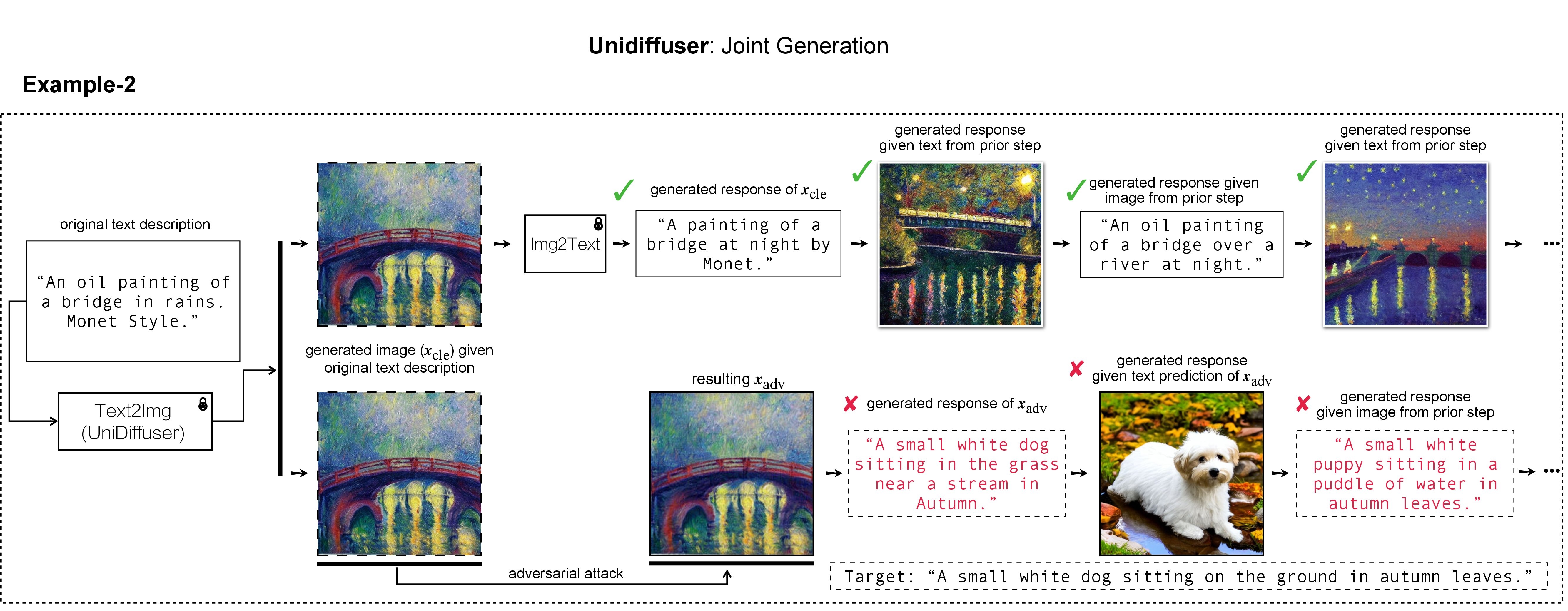
Il existe deux étapes d'attaque contradictoire pour les VLM : (1) une stratégie d'attaque basée sur le transfert et (2) une stratégie d'attaque basée sur des requêtes utilisant (1) comme initialisation. Pour les modèles BLIP/BLIP-2/Img2Prompt, veuillez vous référer à ./LAVIS_tool . Ici, nous utilisons Unidiffuser comme exemple.
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
Ensuite, créez un environnement conda approprié nommé unidiffuser en suivant les étapes ICI et préparez les poids de modèle correspondants (nous utilisons uvit_v1.pth comme poids de U-ViT).
conda activate unidiffuser
bash _train_adv_img_trans.sh
les images adv contrefaites x_trans seront stockées dans dir of white-box transfer images spécifiées dans --output . Ensuite, nous effectuons une conversion image-texte et stockons la réponse générée de x_trans. Ceci peut être réalisé par :
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
où les réponses générées seront stockées dans dir of white-box transfer captions au format .txt . Nous les utiliserons pour l'estimation de pseudo-gradient via l'estimateur RGF.
MF-ii + MF-tt (par exemple, 8 px) bash _train_trans_and_query_fixed_budget.sh
D'un autre côté, si vous souhaitez mener une attaque basée sur un transfert + une requête avec un budget de perturbation séparé , nous fournissons en plus un script :
bash _train_trans_and_query_more_budget.sh
Ici, nous utilisons wandb pour surveiller dynamiquement la moyenne mobile du score CLIP (par exemple, RN50, ViT-B/32, ViT-L/14, etc.) afin d'évaluer la similarité entre (a) la réponse générée (de trans/ images de requête) et (b) le texte ciblé prédéfini c_tar .
Un exemple présenté ci-dessous, où la ligne pointillée indique la moyenne mobile du score CLIP (des légendes d'image) après requête : 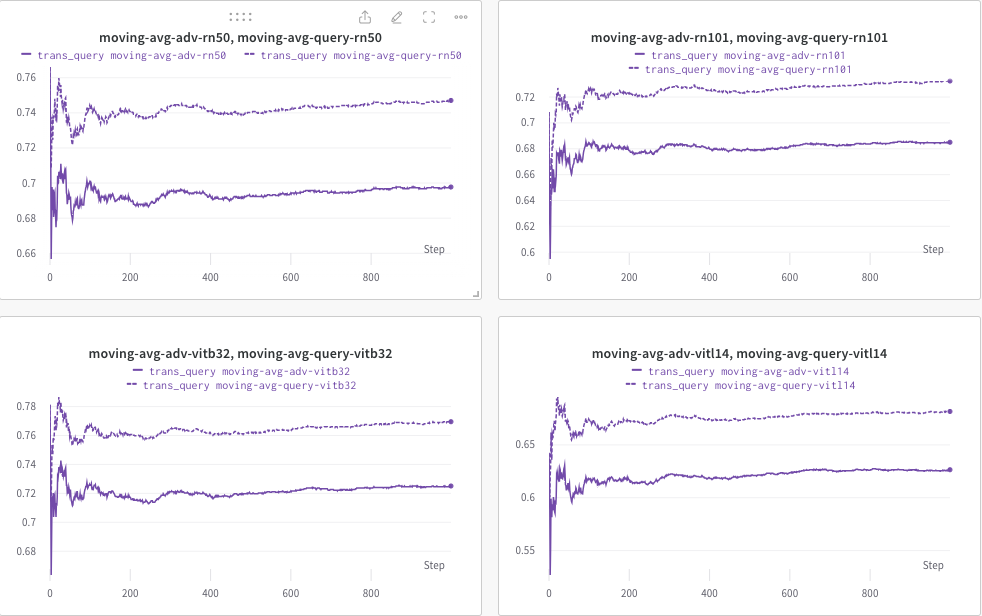
Pendant ce temps, la légende de l'image après la requête sera stockée et le répertoire pourra être spécifié par --output .
Si vous trouvez ce projet utile dans votre recherche, pensez à citer notre article :
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
Parallèlement, une recherche pertinente vise à intégrer un filigrane dans des modèles de diffusion (multimodaux) :
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
Nous apprécions la merveilleuse implémentation de base de MiniGPT-4, LLaVA, Unidiffuser, LAVIS et CLIP. Nous remercions également @MetaAI pour l'open source de ses ponts de contrôle LLaMA. Nous remercions SiSi d'avoir fourni des images agréables et visuellement agréables générées par @Midjourney dans notre recherche.


