SDV
v1.17.2 - 2024-11-18
Ce référentiel fait partie du projet Synthetic Data Vault, un projet de DataCebo.



Le Synthetic Data Vault (SDV) est une bibliothèque Python conçue pour être votre guichet unique pour la création de données synthétiques tabulaires. Le SDV utilise une variété d'algorithmes d'apprentissage automatique pour apprendre des modèles à partir de vos données réelles et les émuler dans des données synthétiques.
? Créez des données synthétiques à l’aide de l’apprentissage automatique. Le SDV propose de multiples modèles, allant des méthodes statistiques classiques (GaussianCopula) aux méthodes d'apprentissage profond (CTGAN). Générez des données pour des tables uniques, plusieurs tables connectées ou des tables séquentielles.
Évaluez et visualisez les données. Comparez les données synthétiques aux données réelles par rapport à diverses mesures. Diagnostiquez les problèmes et générez un rapport de qualité pour obtenir plus d’informations.
Prétraitez, anonymisez et définissez les contraintes. Maîtriser le traitement des données pour améliorer la qualité des données synthétiques, choisir parmi différents types d'anonymisation et définir des règles métiers sous forme de contraintes logiques.
| Liens importants | |
|---|---|
 Tutoriels Tutoriels | Obtenez une expérience pratique avec le SDV. Lancez les blocs-notes du didacticiel et exécutez le code vous-même. |
| Documents | Découvrez comment utiliser la bibliothèque SDV avec des guides d'utilisation et des références API. |
| ? Blogue | Obtenez plus d’informations sur l’utilisation du SDV, le déploiement de modèles et notre communauté de données synthétiques. |
 Communauté Communauté | Rejoignez notre espace de travail Slack pour les annonces et les discussions. |
| Site web | Consultez le site Web de SDV pour plus d'informations sur le projet. |
Le SDV est accessible au public sous la licence Business Source. Installez SDV en utilisant pip ou conda. Nous vous recommandons d'utiliser un environnement virtuel pour éviter les conflits avec d'autres logiciels sur votre appareil.
pip install sdvconda install -c pytorch -c conda-forge sdvChargez un ensemble de données de démonstration pour commencer. Cet ensemble de données est un tableau unique décrivant les clients séjournant dans un hôtel fictif.
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )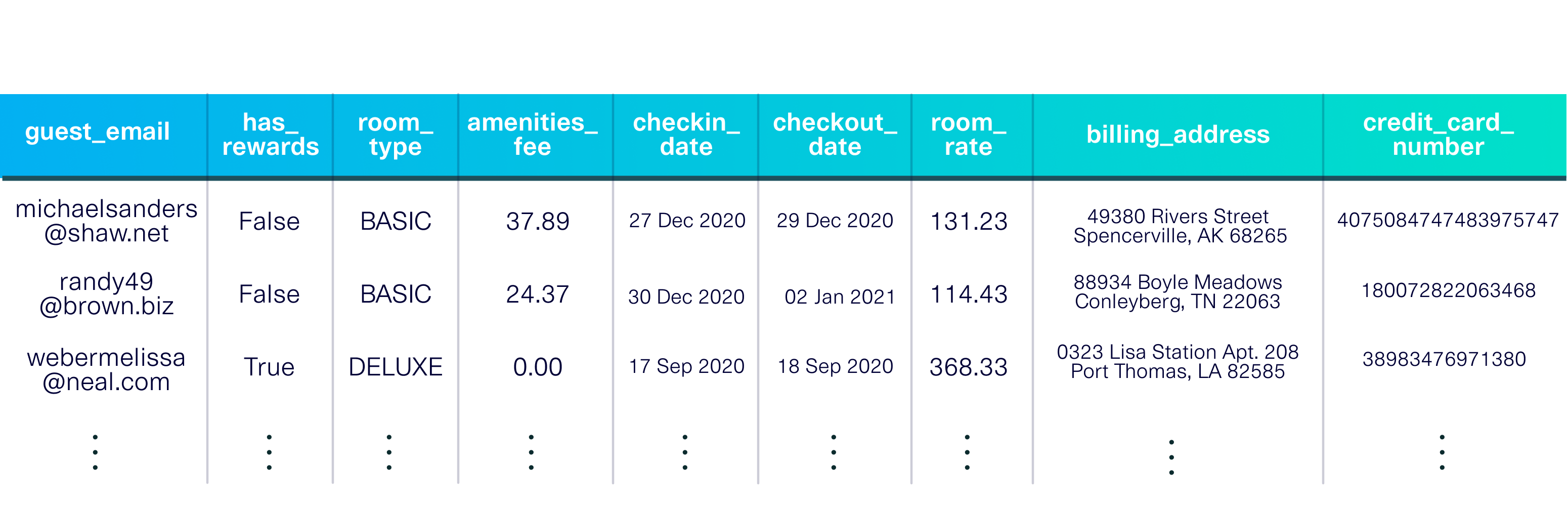
La démo comprend également des métadonnées , une description de l'ensemble de données, y compris les types de données dans chaque colonne et la clé primaire ( guest_email ).
Ensuite, nous pouvons créer un synthétiseur SDV , un objet que vous pouvez utiliser pour créer des données synthétiques. Il apprend des modèles à partir des données réelles et les réplique pour générer des données synthétiques. Utilisons le GaussianCopulaSynthesizer.
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )Et maintenant, le synthétiseur est prêt à créer des données synthétiques !
synthetic_data = synthesizer . sample ( num_rows = 500 )Les données synthétiques auront les propriétés suivantes :
La bibliothèque SDV permet d'évaluer les données synthétiques en les comparant aux données réelles. Commencez par générer un rapport de qualité.
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
Cet objet calcule une note de qualité globale sur une échelle de 0 à 100% (100 étant le meilleur) ainsi que des répartitions détaillées. Pour plus d’informations, vous pouvez également visualiser les données synthétiques et réelles.
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()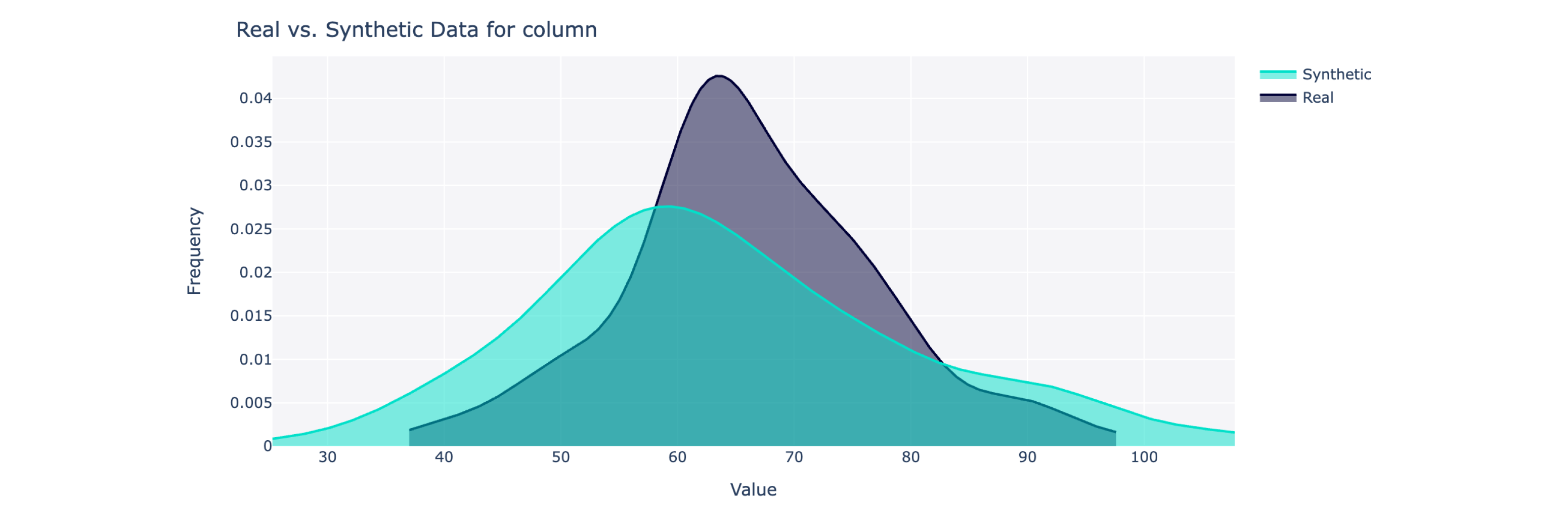
À l’aide de la bibliothèque SDV, vous pouvez synthétiser des données à table unique, multi-tables et séquentielles. Vous pouvez également personnaliser le flux de travail complet des données synthétiques, y compris le prétraitement, l'anonymisation et l'ajout de contraintes.
Pour en savoir plus, visitez la page Démo SDV.
Merci à notre équipe de contributeurs qui ont construit et entretenu l'écosystème SDV au fil des années !
Voir les contributeurs
Si vous utilisez SDV pour votre recherche, veuillez citer l'article suivant :
Neha Patki, Roy Wedge, Kalyan Veeramachaneni . Le coffre-fort de données synthétiques. IEEE DSAA 2016.
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
Le projet Synthetic Data Vault a été créé pour la première fois au Data to AI Lab du MIT en 2016. Après 4 ans de recherche et de traction avec l'entreprise, nous avons créé DataCebo en 2020 dans le but de développer le projet. Aujourd'hui, DataCebo est le fier développeur de SDV, le plus grand écosystème de génération et d'évaluation de données synthétiques. Il héberge plusieurs bibliothèques prenant en charge les données synthétiques, notamment :
Commencez à utiliser le package SDV : une solution entièrement intégrée et votre guichet unique pour les données synthétiques. Ou utilisez les bibliothèques autonomes pour des besoins spécifiques.


