LipGER
Initial Release
Il s'agit de l'implémentation officielle de notre article LipGER : Correction d'erreurs génératives visuellement conditionnées pour une reconnaissance vocale automatique robuste à InterSpeech 2024 qui est sélectionné pour une présentation orale .
Vous pouvez télécharger les données LipHyp à partir d'ici !
pip install -r requirements.txt
Préparez d’abord les points de contrôle en utilisant :
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hfPour voir tous les points de contrôle disponibles, exécutez :
python scripts/download.py | grep Llama-2Pour plus de détails, vous pouvez également vous référer à ce lien, où vous pourrez également préparer d'autres points de contrôle pour d'autres modèles. Plus précisément, nous utilisons TinyLlama pour nos expériences.
Le point de contrôle est disponible ici. Après le téléchargement, modifiez le chemin du point de contrôle ici.
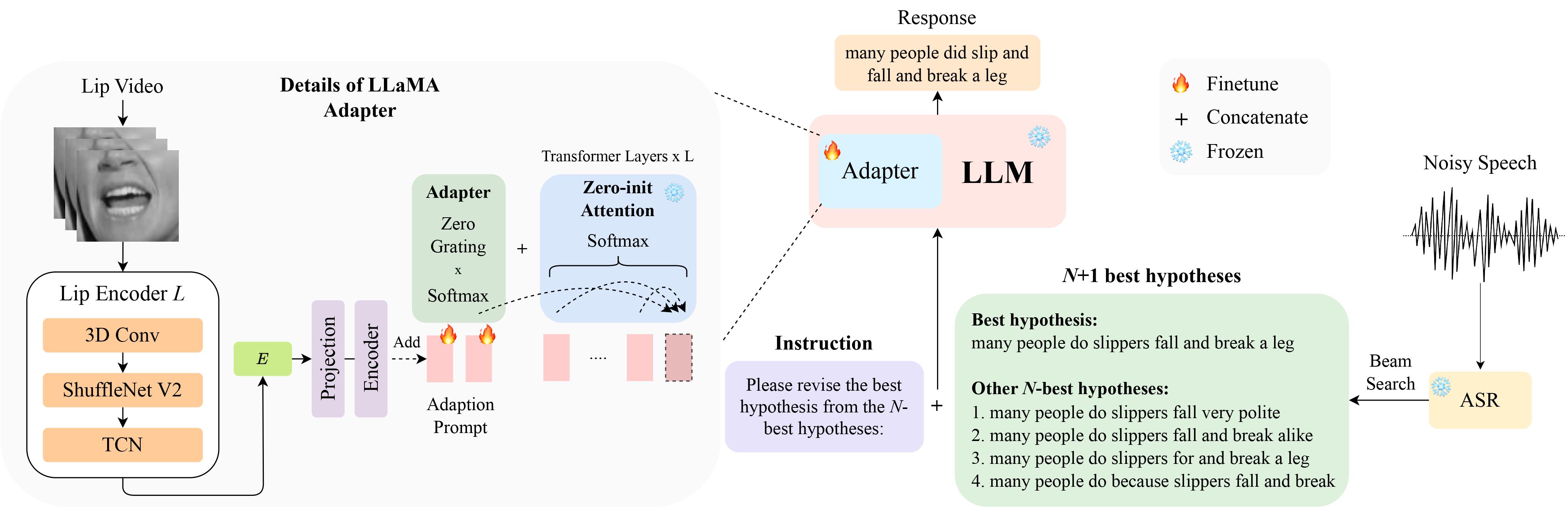
LipGER s'attend à ce que tous les fichiers train, val et test soient au format sample_data.json. Une instance dans le fichier ressemble à :
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
Vous devez transmettre les fichiers vocaux via un modèle ASR formé capable de générer les N meilleures hypothèses. Nous proposons 2 façons dans ce référentiel pour vous aider à y parvenir. N'hésitez pas à utiliser d'autres méthodes.
pip install whisper , puis exécutez nhyps.py à partir du dossier data , tout devrait bien se passer ! Notez que pour les deux méthodes, la première de la liste est la meilleure hypothèse et les autres sont les N meilleures hypothèses (elles sont transmises sous forme de champ nhyps_base de liste du JSON et utilisées pour construire une invite dans les étapes suivantes).
De plus, les méthodes fournies utilisent uniquement la parole comme entrée. Pour la génération des N-meilleures hypothèses audiovisuelles, nous avons utilisé Auto-AVSR. Si vous avez besoin d'aide avec le code, veuillez signaler un problème !
En supposant que vous disposez des vidéos correspondantes pour tous vos fichiers vocaux, suivez ces étapes pour recadrer le retour sur investissement de la bouche à partir des vidéos.
python crop_mouth_script.py
python covert_lip.py
Cela convertira le ROI mp4 en hdf5, le code changera le chemin du ROI mp4 en hdf5 ROI dans le même fichier json. Vous pouvez choisir parmi les détecteurs "mediapipe" et "retinaface" en modifiant le "détecteur" dans default.yaml
Une fois que vous avez les N meilleures hypothèses, construisez le fichier JSON au format requis. Nous ne fournissons pas de code spécifique pour cette partie car la préparation des données peut différer pour chacun, mais le code doit être simple. Encore une fois, soulevez un problème si vous avez des doutes !
Les scripts de formation LipGER n'acceptent pas JSON pour la formation ou l'évaluation. Vous devez les convertir en fichier pt. Vous pouvez exécuter convert_to_pt.py pour y parvenir ! Modifiez model_name selon votre souhait à la ligne 27 et ajoutez le chemin vers votre JSON à la ligne 58.
Pour affiner LipGER, exécutez simplement :
sh finetune.sh
où vous devez définir manuellement les valeurs pour data (avec le nom de l'ensemble de données), --train_path et --val_path (avec des chemins absolus à entraîner et des fichiers .pt valides).
À des fins d'inférence, modifiez d'abord les chemins respectifs dans lipger.py ( exp_path et checkpoint_dir ), puis exécutez (avec l'argument de chemin de données de test approprié) :
sh infer.sh
Le code pour recadrer le retour sur investissement de la bouche est inspiré de Visual_Speech_Recognition_for_Multiple_Languages.
Notre code pour LipGER est inspiré de RobustGER. Veuillez également citer leur article si vous trouvez notre article ou notre code utile.
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


