Dans ce laboratoire, nous mettrons en pratique les formules mathématiques que nous avons vues dans la leçon précédente pour voir comment MLE fonctionne avec des distributions normales.
Vous pourrez :
Remarque : *Une dérivation détaillée de toutes les équations MLE avec preuves peut être consultée sur ce site Web. *
Voyons ci-dessous un exemple de raccords MLE et de distribution avec Python. Ici, scipy.stats.norm.fit calcule les paramètres de distribution à l'aide de l'estimation du maximum de vraisemblance.
from scipy . stats import norm # for generating sample data and fitting distributions
import matplotlib . pyplot as plt
plt . style . use ( 'seaborn' )
import numpy as np sample = Nonestats.norm.fit(data) pour ajuster une distribution aux données ci-dessus. param = None
#param[0], param[1]
# (0.08241224761452863, 1.002987490235812)x = np.linspace(-5,5,100) x = np . linspace ( - 5 , 5 , 100 )
# Generate the pdf from fitted parameters (fitted distribution)
fitted_pdf = None
# Generate the pdf without fitting (normal distribution non fitted)
normal_pdf = None # Your code here 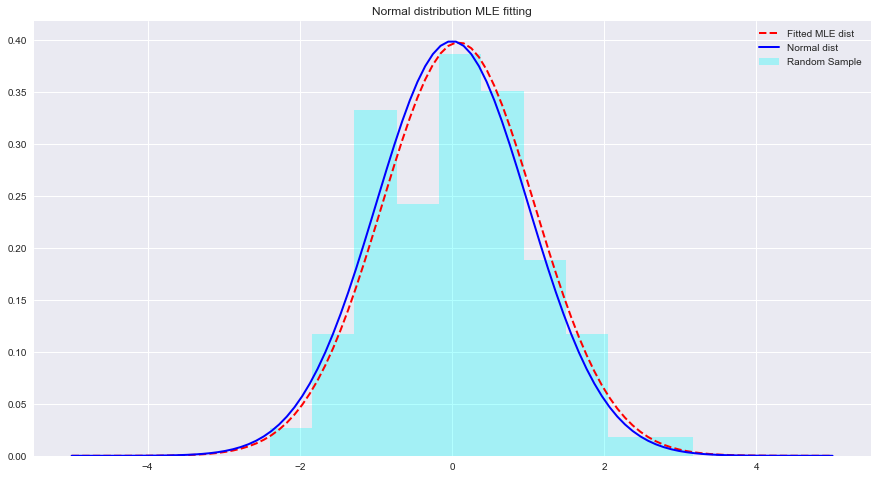
# Your comments/observations Dans ce court laboratoire, nous avons examiné le contexte bayésien dans un contexte gaussien, c'est-à-dire lorsque les variables aléatoires sous-jacentes sont normalement distribuées. Nous avons appris que MLE peut estimer les paramètres inconnus d'une distribution normale, en maximisant la probabilité de la moyenne attendue. La moyenne attendue est très proche de la moyenne d'une distribution normale non ajustée dans cet espace de paramètres. Nous allons progresser dans cette compréhension et apprendre comment de telles estimations sont effectuées pour estimer les moyennes d'un certain nombre de classes présentes dans la distribution de données à l'aide du classificateur Naive Bayes.


