Chatbot Transformer avec TensorFlow 2
Créez un chatbot de bout en bout avec Transformer dans TensorFlow 2. Consultez mon tutoriel sur blog.tensorflow.org.
Mises à jour
- 16 juin 2022 :
- Mettez à jour le script
setup.sh pour installer la version Apple Silicon de TensorFlow 2.9 (utilisez-le uniquement si vous vous sentez aventureux). - Mise à jour des deux couches personnalisées,
PositionalEncoding et MultiHeadAttentionLayer , pour permettre la sauvegarde du modèle via model.save() ou tf.keras.models.save_model() . -
train.py montre comment appeler model.save() et tf.keras.models.load_model() .
- 8 décembre 2020 : mise à jour de la prise en charge de TensorFlow 2.3.1 et des ensembles de données TensorFlow 4.1.0
- 18 janvier 2020 : ajout d'un bloc-notes avec prise en charge de Google Colab TPU dans TensorFlow 2.1.
Forfaits
- TensorFlow 2.9.1
- Ensembles de données TensorFlow
Installation
- créer un nouvel environnement anaconda et initialiser
chatbot de l'environnement conda create -n chatbot python=3.8
conda activate chatbot
- exécuter le script d'installation
- Remarque : le script installerait CUDA et cuDNN via conda s'il était installé sur un système Linux, ou
tensorflow-metal pour les appareils avec Apple Silicon (notez qu'il y a des tonnes de bugs avec TensorFlow sur le GPU Apple Silicon, par exemple l'optimiseur Adam ne fonctionne pas).
Ensemble de données
- Nous utiliserons comme ensemble de données les conversations dans les films et les émissions de télévision fournies par Cornell Movie-Dialogs Corpus, qui contient plus de 220 000 échanges conversationnels entre plus de 10 000 paires de personnages de films.
- Nous prétraitons notre ensemble de données dans l'ordre suivant :
- Extrayez les paires de conversations
max_samples dans une liste de questions et answers . - Pré-traitez chaque phrase en supprimant les caractères spéciaux dans chaque phrase.
- Créez un tokenizer (mappage du texte à l'ID et de l'ID au texte) à l'aide des ensembles de données TensorFlow SubwordTextEncoder.
- Tokenisez chaque phrase et ajoutez
start_token et end_token pour indiquer le début et la fin de chaque phrase. - Filtrez la phrase contenant plus de jetons
max_length . - Compléter les phrases tokenisées jusqu'à
max_length
- Vérifiez l'implémentation de dataset.py.
Modèle
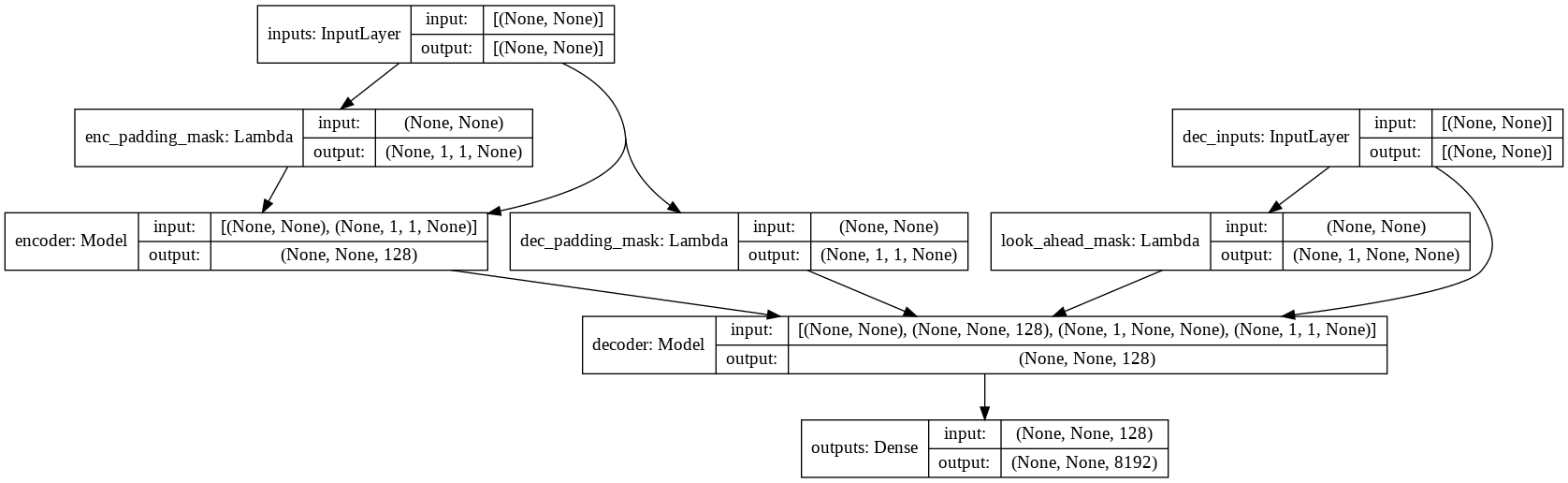
- consultez model.py pour l'implémentation de l'attention multi-têtes, de l'encodage positionnel et du transformateur.
Courir
- vérifiez tous les indicateurs et hyper-paramètres disponibles
python main.py --help
python train.py --output_dir runs/save_model --batch_size 256 --epochs 50 --max_samples 50000
- le modèle final formé sera enregistré dans
runs/save_model .
Échantillons
input: where have you been?
output: i m not talking about that .
input: it's a trap!
output: no , it s not .


