DeepMorphy
1.0.0
DeepMorphy est un analyseur morphologique basé sur un réseau neuronal pour la langue russe.
DeepMorphy est un analyseur morphologique pour la langue russe. Disponible en tant que bibliothèque .Net Standard 2.0. Peut:
La terminologie de DeepMorphy est partiellement empruntée à l'analyseur morphologique pymorphy2.
Grammeme (gramme anglais) - la signification de l'une des catégories grammaticales d'un mot (par exemple, passé, singulier, masculin).
Une catégorie grammaticale est un ensemble de grammes mutuellement exclusifs qui caractérisent une caractéristique commune (par exemple, le genre, le temps, la casse, etc.). Une liste de toutes les catégories et grammaires prises en charge dans DeepMorphy est ici.
Étiquette (étiquette anglaise) - un ensemble de grammes qui caractérisent un mot donné (par exemple, une étiquette pour le mot hérisson - nom, singulier, cas nominatif, masculin).
Le lemme (lemme anglais) est la forme normale d'un mot.
Lemmatisation (eng. lemmatisation) - amener un mot à sa forme normale.
Un lexème est un ensemble de toutes les formes d'un même mot.
L'élément central de DeepMorphy est le réseau neuronal. Pour la plupart des mots, l'analyse morphologique et la lemmatisation sont réalisées par le réseau. Certains types de mots sont traités par des préprocesseurs.
Il existe 3 préprocesseurs :
Le réseau a été construit et formé sur le framework tensorflow. Le dictionnaire Opencorpora sert de jeu de données. Intégré à .Net via TensorFlowSharp.
Le graphique de calcul pour l'analyse de mots dans DeepMorphy se compose de 11 « sous-réseaux » :
Le problème du changement de forme des mots est résolu par un réseau 1 seq2seq.
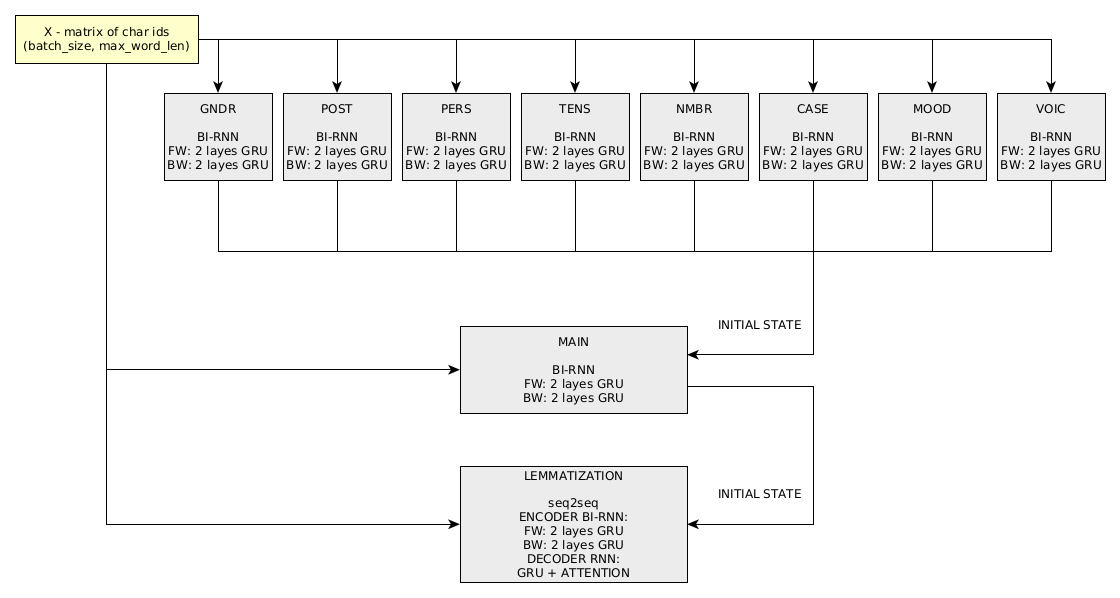
La formation s'effectue de manière séquentielle, d'abord les réseaux sont formés par catégorie (l'ordre n'a pas d'importance). Ensuite, la classification principale par balises, la lemmatisation et un réseau pour changer la forme des mots sont formés. La formation a été réalisée sur 3 GPU Titan X. Les mesures de performances réseau sur l'ensemble de données de test de la dernière version peuvent être consultées ici.
DeepMorphy pour .NET est une bibliothèque .Net Standard 2.0. Les seules dépendances sont la bibliothèque TensorflowSharp (le réseau de neurones est lancé via elle).
La bibliothèque est publiée dans Nuget, il est donc plus simple de l'installer via elle.
S'il existe un gestionnaire de paquets :
Install-Package DeepMorphy
Si le projet prend en charge PackageReference :
<PackageReference Include="DeepMorphy"/>
Si quelqu'un souhaite construire à partir de sources, alors les sources C# sont ici. Rider est utilisé pour le développement (tout doit être assemblé en studio sans aucun problème).
Toutes les actions sont effectuées via l'objet de classe MorphAnalyzer :
var morph = new MorphAnalyzer ( ) ;Idéalement, il est préférable de l'utiliser comme singleton ; lors de la création d'un objet, un certain temps est consacré au chargement des dictionnaires et du réseau. Filetage sécurisé. Lors de la création, vous pouvez transmettre les paramètres suivants au constructeur :
Pour l'analyse, la méthode Parse est utilisée (elle prend un IEnumerable avec des mots pour l'analyse en entrée, renvoie un IEnumerable avec le résultat de l'analyse).
var results = morph . Parse ( new string [ ]
{
"королёвские" ,
"тысячу" ,
"миллионных" ,
"красотка" ,
"1-ый"
} ) . ToArray ( ) ;
var morphInfo = results [ 0 ] ;La liste des catégories grammaticales prises en charge, des grammes et de leurs clés est ici. Si vous avez besoin de connaître la combinaison la plus probable de grammèmes (tag), vous devez alors utiliser la propriété BestTag de l'objet MorphInfo.
// выводим лучшую комбинацию граммем для слова
Console . WriteLine ( morphInfo . BestTag ) ;Sur la base du mot lui-même, il n'est pas toujours possible de déterminer sans ambiguïté la signification de ses catégories grammaticales (voir homonymes), c'est pourquoi DeepMorphy vous permet de visualiser les principales balises d'un mot donné (propriété Tags).
// выводим все теги для слова + их вероятность
foreach ( var tag in morphInfo . Tags )
Console . WriteLine ( $ " { tag } : { tag . Power } " ) ;Y a-t-il une combinaison de grammes dans l'une des balises :
// есть ли в каком-нибудь из тегов прилагательные единственного числа
morphInfo . HasCombination ( "прил" , "ед" ) ;Y a-t-il une combinaison de grammes dans l'étiquette la plus probable :
// ясляется ли лучший тег прилагательным единственного числа
morphInfo . BestTag . Has ( "прил" , "ед" ) ;Récupération de catégories de grammaire spécifiques à partir de la meilleure balise :
// выводит часть речи лучшего тега и число
Console . WriteLine ( morphInfo . BestTag [ "чр" ] ) ;
Console . WriteLine ( morphInfo . BestTag [ "число" ] ) ;Les balises sont utilisées lorsque vous avez besoin d'informations sur plusieurs catégories grammaticales à la fois (par exemple, partie du discours et nombre). Si vous n'êtes intéressé que par une seule catégorie, alors vous pouvez utiliser l'interface des probabilités de signification des catégories grammaticales des objets MorphInfo.
// выводит самую вероятную часть речи
Console . WriteLine ( morphInfo [ "чр" ] . BestGramKey ) ;Vous pouvez également obtenir la distribution de probabilité par catégorie grammaticale :
// выводит распределение вероятностей для падежа
foreach ( var gram in morphInfo [ "падеж" ] . Grams )
{
Console . WriteLine ( $ " { gram . Key } : { gram . Power } " ) ;
}Si, en plus de l'analyse morphologique, vous devez obtenir des lemmes de mots, alors l'analyseur doit être créé comme suit :
var morph = new MorphAnalyzer ( withLemmatization : true ) ;Les lemmes peuvent être obtenus à partir de balises de mots :
Console . WriteLine ( morphInfo . BestTag . Lemma ) ;Vérifier si un mot donné a un lemme :
morphInfo . HasLemma ( "королевский" ) ;La méthode CanBeSameLexeme peut être utilisée pour rechercher les mots d'un seul lexème :
// выводим все слова, которые могут быть формой слова королевский
var words = new string [ ]
{
"королевский" ,
"королевские" ,
"корабли" ,
"пересказывают" ,
"королевского"
} ;
var results = morph . Parse ( words ) . ToArray ( ) ;
var mainWord = results [ 0 ] ;
foreach ( var morphInfo in results )
{
if ( mainWord . CanBeSameLexeme ( morphInfo ) )
Console . WriteLine ( morphInfo . Text ) ;
}Si vous n'avez besoin que d'une lemmatisation sans analyse morphologique, alors vous devez utiliser la méthode Lemmatize :
var tasks = new [ ]
{
new LemTask ( "синяя" , morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ) ,
new LemTask ( "гуляя" , morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var lemmas = morph . Lemmatize ( tasks ) . ToArray ( ) ;
foreach ( var lemma in lemmas )
Console . WriteLine ( lemma ) ;DeepMorphy peut changer la forme d'un mot dans un lexème ; la liste des inflexions prises en charge est ici. Les mots du dictionnaire ne peuvent être modifiés que dans les formulaires disponibles dans le dictionnaire. Pour changer la forme des mots, la méthode Inflect est utilisée ; elle prend en entrée une énumération d'objets InflectTask (contient le mot source, la balise du mot source et la balise dans laquelle le mot doit être placé). Le résultat est une énumération avec les formulaires requis (si le formulaire n'a pas pu être traité, alors nul).
var tasks = new [ ]
{
new InflectTask ( "синяя" ,
morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ,
morph . TagHelper . CreateTag ( "прил" , gndr : "муж" , nmbr : "ед" , @case : "им" ) ) ,
new InflectTask ( "гулять" ,
morph . TagHelper . CreateTag ( "инф_гл" ) ,
morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var results = morph . Inflect ( tasks ) ;
foreach ( var result in results )
Console . WriteLine ( result ) ;Il est également possible d'obtenir toutes ses formes pour un mot en utilisant la méthode Lexeme (pour les mots du dictionnaire, elle renvoie tout ce qui vient du dictionnaire, pour d'autres toutes les formes à partir des flexions prises en charge).
var word = "лемматизировать" ;
var tag = m . TagHelper . CreateTag ( "инф_гл" ) ;
var results = m . Lexeme ( word , tag ) . ToArray ( ) ;L'une des caractéristiques de l'algorithme est qu'en changeant la forme ou en générant un lexème, le réseau peut « inventer » une forme inexistante (hypothétique) du mot, une forme qui n'est pas utilisée dans la langue. Par exemple, ci-dessous, vous obtenez le mot « va courir », bien que pour le moment il ne soit pas particulièrement utilisé dans la langue.
var tasks = new [ ]
{
new InflectTask ( "победить" ,
m . TagHelper . CreateTag ( "инф_гл" ) ,
m . TagHelper . CreateTag ( "гл" , nmbr : "ед" , tens : "буд" , pers : "1л" , mood : "изъяв" ) )
} ;
Console . WriteLine ( m . Inflect ( tasks ) . First ( ) ) ; 


