3DDFA
1.0.0
Par Jianzhu Guo.

[Mises à jour]
2022.5.14 : Recommander une implémentation python du profilage du visage : face_pose_augmentation.2020.8.30 : Le modèle et le code pré-entraînés d'ECCV-20 sont rendus publics sur 3DDFA_V2, le copyright est expliqué par Jianzhu Guo et le groupe CBSR.2020.8.2 : Mise à jour d'un simple portage C++ de ce projet.2020.7.3 : Le travail étendu vers un alignement dense des visages 3D rapide, précis et stable est accepté par l'ECCV 2020. Voir ma page pour plus de détails.2019.9.15 : Quelques mises à jour, voir les commits pour plus de détails.2019.6.17 : Ajout d'une démo vidéo contribuée par zjjMaiMai.2019.5.2 : Évaluation de la vitesse d'inférence sur le CPU avec PyTorch v1.1.0, voir ici et speed_cpu.py.2019.4.27 : Un pipeline de rendu simple fonctionnant à ~25 ms/image (720p), voir Rendering.py pour plus de détails.2019.4.24 : Fourniture du bâtiment de démonstration d'Obama, voir demo@obama/readme.md pour plus de détails.2019.3.28 : Quelques mises à jour.2018.12.23 : Ajout de plusieurs fonctionnalités : estimation d'image de profondeur, PNCC, fonctionnalité PAF et sérialisation obj. Voir les options dump_depth , dump_pncc , dump_paf , dump_obj pour plus de détails.2018.12.2 : Prise en charge du recadrage du visage sans repère, voir l'option dlib_landmark .2018.12.1 : Affinez le code et ajoutez une fonctionnalité d'estimation de pose, voir utils/estimate_pose.py pour plus de détails.2018.11.17 : Affiner le code et mapper le sommet 3D à l'espace image d'origine.2018.11.11 : Mise à jour du pipeline d'inférence de bout en bout : déduire/sérialiser la forme du visage 3D et 68 points de repère à partir d'une image arbitraire, veuillez consulter readme.md ci-dessous pour plus de détails.2018.10.4 : Ajouter une démo de rendu de maillage de visage Matlab dans Visualize.2018.9.9 : Ajouter un pré-processus de recadrage du visage dans le benchmark.[Faire]
Ce référentiel contient la version améliorée pytorch de l'article : Alignement du visage dans une plage de poses complète : une solution totale 3D. Plusieurs travaux au-delà de l'article original sont ajoutés, notamment la formation en temps réel et les stratégies de formation. Par conséquent, ce dépôt est une version améliorée de l’œuvre originale. Dans la mesure où ce référentiel publie les modèles pytorch de première étape pré-entraînés de la structure MobileNet-V1, l'ensemble de données de formation et de test pré-traités et la base de code. Notez que le temps d'inférence est d'environ 0,27 ms par image (lot d'entrée avec 128 images comme lot d'entrée) sur GeForce GTX TITAN X.
Ce dépôt continuera à être mis à jour pendant mon temps libre, et tous les problèmes et relations publiques importants sont les bienvenus.
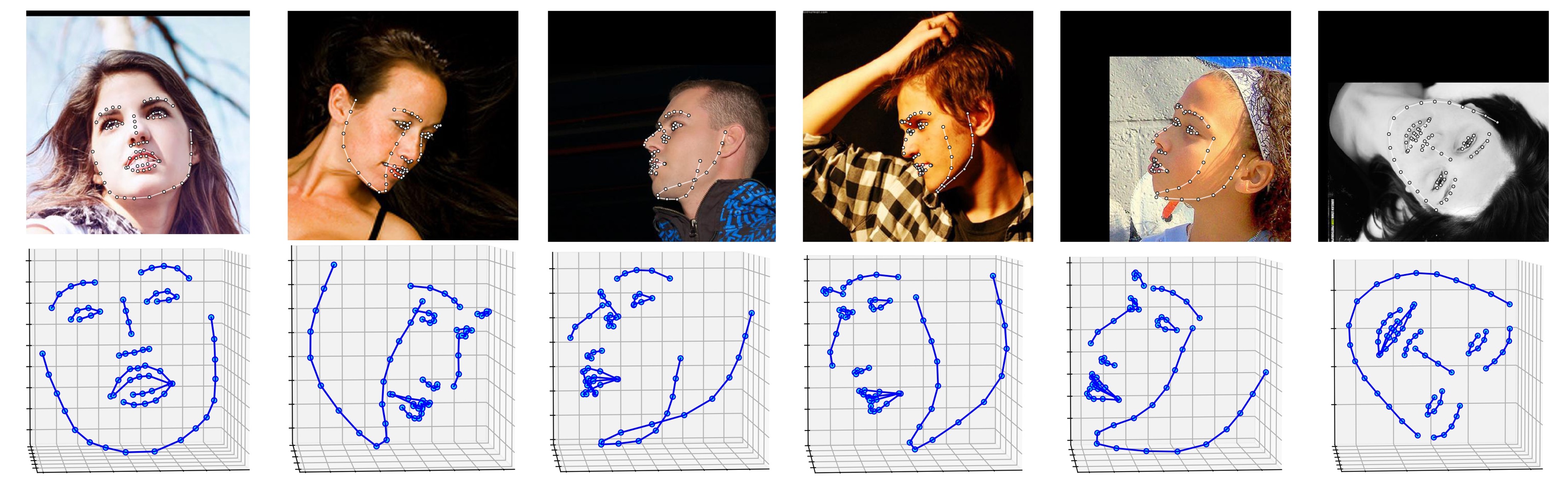
Plusieurs résultats sur l'ensemble de données ALFW-2000 (déduits du modèle phase1_wpdc_vdc.pth.tar ) sont présentés ci-dessous.





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
De plus, je recommande fortement d'utiliser Python3.6+ au lieu de l'ancienne version pour sa meilleure conception.
Cloner ce dépôt (cela peut prendre un certain temps car il est un peu gros)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
Ensuite, téléchargez le modèle pré-entraîné dlib Landmark dans Google Drive ou Baidu Yun et placez-le dans le répertoire models . (Pour réduire la taille de ce dépôt, je supprime certains fichiers binaires de grande taille, y compris ce modèle, vous devriez donc le télécharger : ) )
Construire le module cython (une seule ligne pour la construction)
cd utils/cython
python3 setup.py build_ext -i
Ceci permet d'accélérer l'estimation de la profondeur et le rendu PNCC car Python est trop lent dans la boucle for.
Exécutez le main.py avec une image arbitraire en entrée
python3 main.py -f samples/test1.jpg
Si vous pouvez voir ces journaux de sortie dans le terminal, vous l'exécutez avec succès.
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
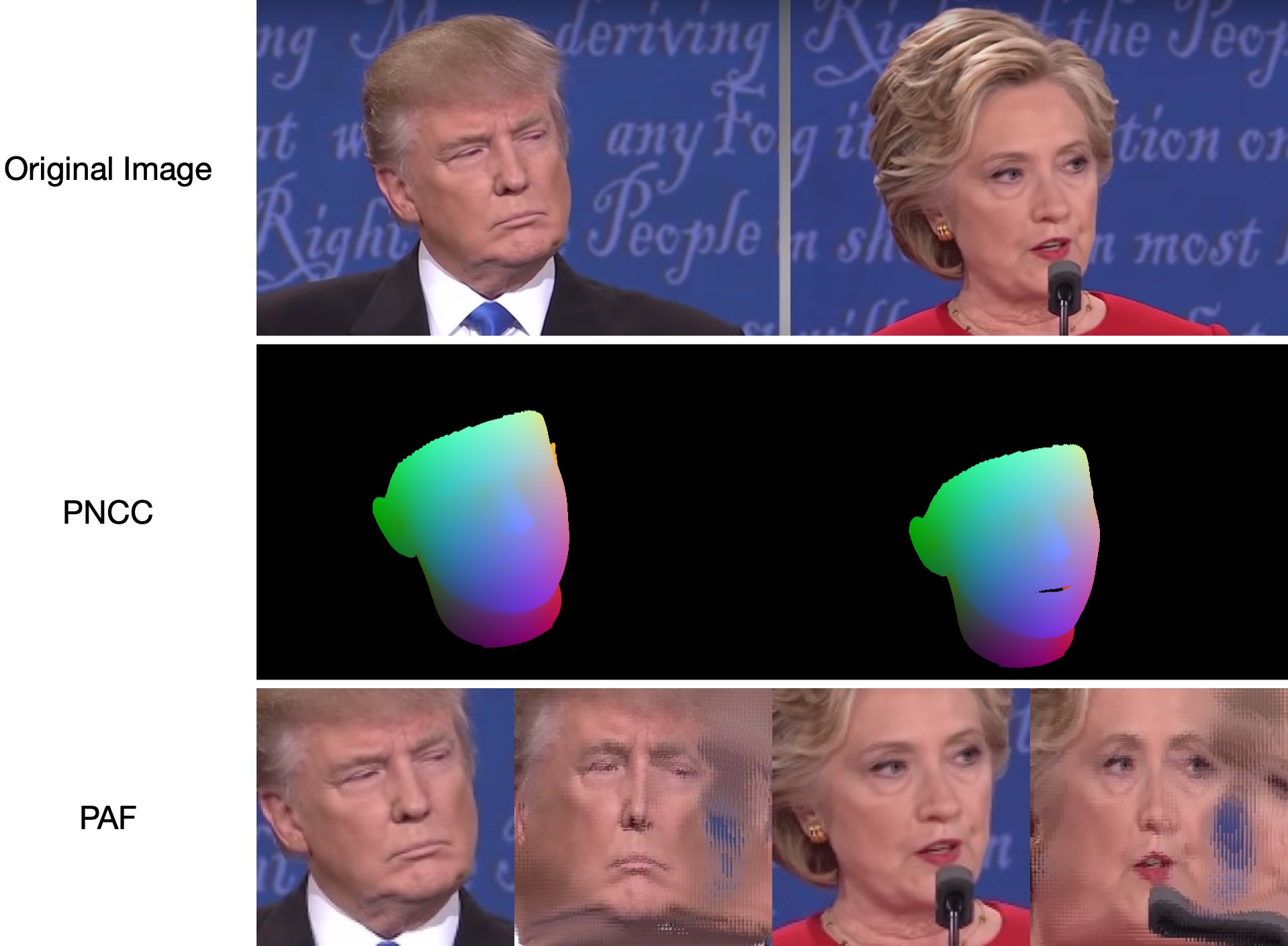
Étant donné que test1.jpg a deux faces, deux fichiers .ply et .obj (peuvent être rendus par Meshlab ou Microsoft 3D Builder) sont prédits. La profondeur, le PNCC, le PAF et l'estimation de la pose sont tous définis sur vrai par défaut. Veuillez exécuter python3 main.py -h ou consulter le code pour plus de détails.
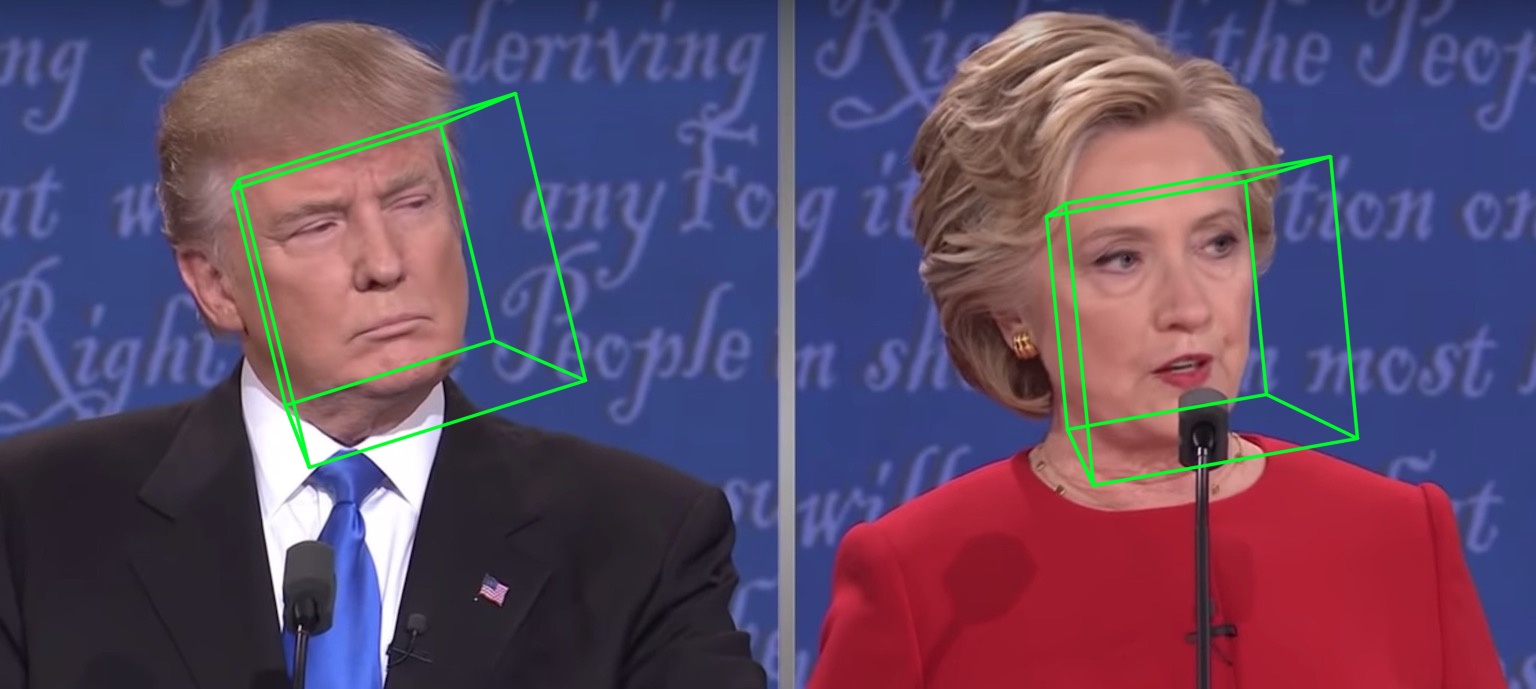
Les 68 échantillons de résultats de visualisation de points de repère samples/test1_3DDFA.jpg et samples/test1_pose.jpg sont présentés ci-dessous :

Exemple supplémentaire
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
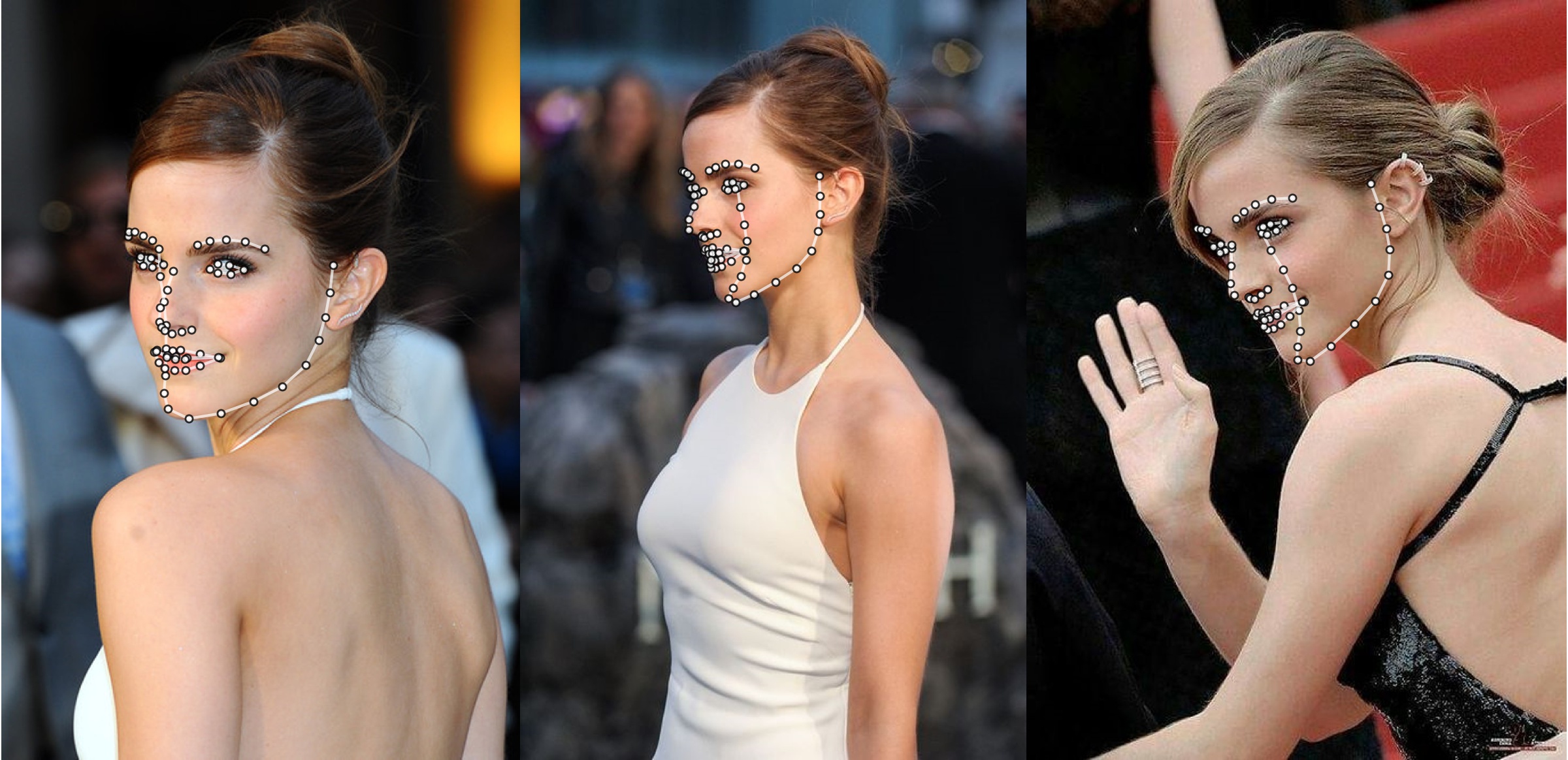
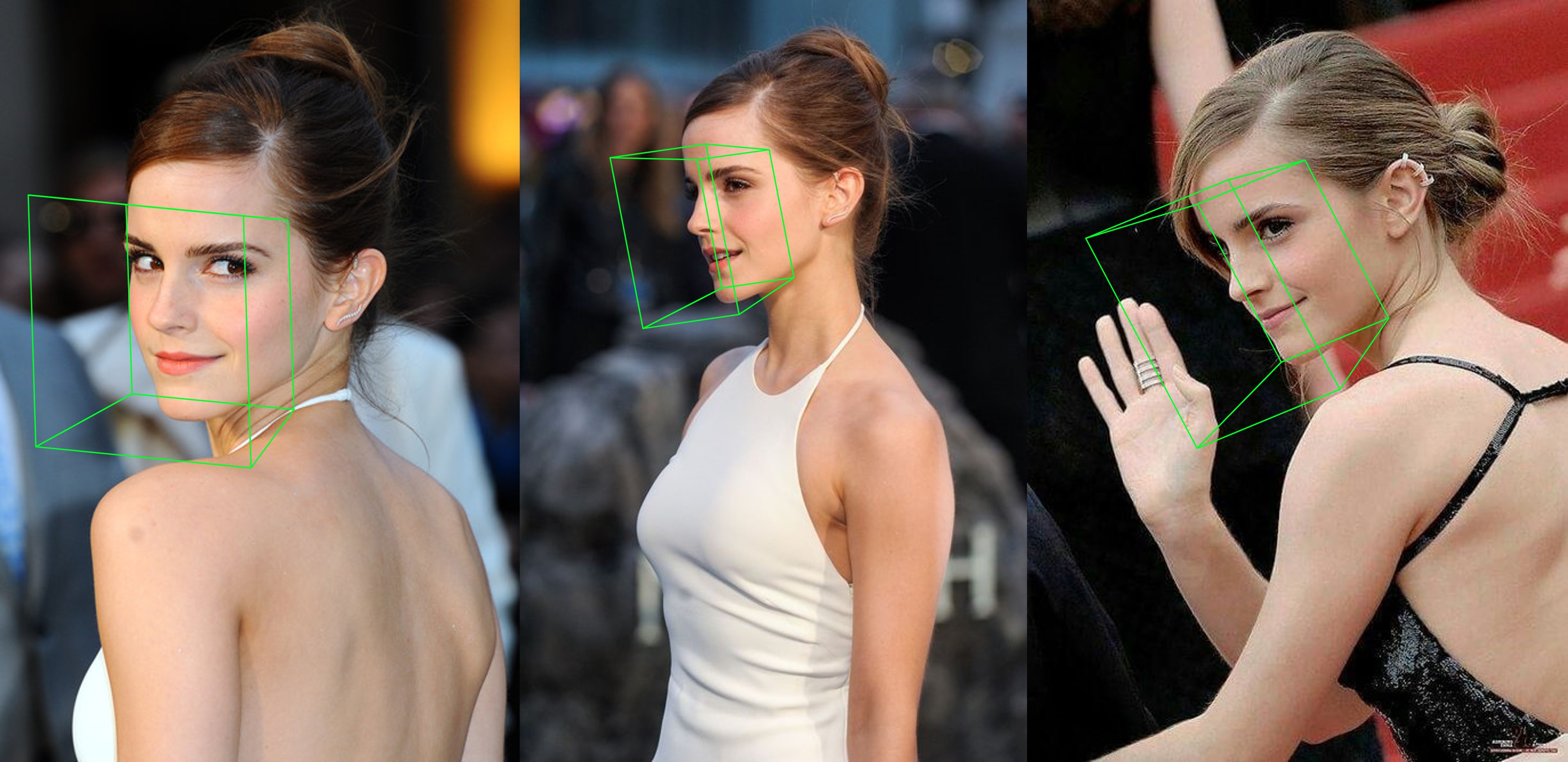
Il suffit de courir
python3 speed_cpu.py
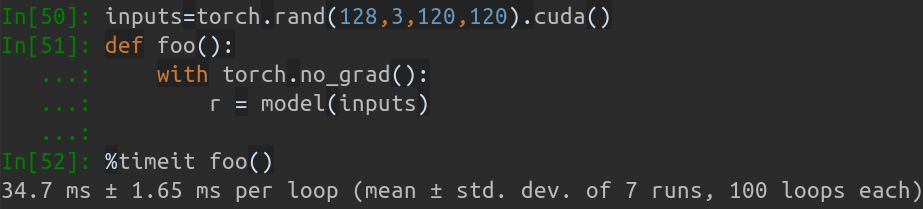
Sur mon MBP (processeur i5-8259U à 2,30 GHz sur MacBook Pro 13 pouces), basé sur PyTorch v1.1.0 , avec une seule entrée, la sortie en cours d'exécution est :
Inference speed: 14.50±0.11 ms
Lorsque la taille du lot d'entrée est de 128, le temps d'inférence total de MobileNet-V1 prend environ 34,7 ms. La vitesse moyenne est d'environ 0,27 ms/image .
Les scripts de formation se trouvent dans le répertoire training . Les ressources associées se trouvent dans le tableau ci-dessous.
| Données | Lien de téléchargement | Description |
|---|---|---|
| train.configs | BaiduYun ou Google Drive, 217 Mo | Le répertoire contenant les paramètres 3DMM et les listes de fichiers de l'ensemble de données d'entraînement |
| train_aug_120x120.zip | BaiduYun ou Google Drive, 2,15G | Les images recadrées de l'ensemble de données de formation d'augmentation |
| test.data.zip | BaiduYun ou Google Drive, 151 Mo | Les images recadrées de l'ensemble de tests AFLW et ALFW-2000-3D |
Après avoir préparé l'ensemble de données de formation et les fichiers de configuration, accédez au répertoire training et exécutez les scripts bash pour vous entraîner. train_wpdc.sh , train_vdc.sh et train_pdc.sh sont des exemples de scripts de formation. Après avoir configuré les ensembles de formation et de test, exécutez-les simplement pour la formation. Prenez train_wpdc.sh par exemple comme ci-dessous :
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
Les paramètres de formation spécifiques sont tous présentés dans des scripts bash, notamment le taux d'apprentissage, la taille du mini-lot, les époques, etc.
Tout d'abord, vous devez télécharger l'ensemble de tests recadré ALFW et ALFW-2000-3D dans test.data.zip, puis le décompresser et le placer dans le répertoire racine. Ensuite, exécutez le code de référence en fournissant un chemin de modèle entraîné. J'ai déjà fourni cinq modèles pré-entraînés dans le répertoire models (voir le tableau ci-dessous). Ces modèles sont formés en utilisant différentes pertes dans la première étape. La taille du modèle est d'environ 13 M en raison de la haute efficacité de la structure MobileNet-V1.
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
Les performances des modèles pré-entraînés sont présentées ci-dessous. Dans la première étape, l'efficacité des différentes pertes est en ordre : WPDC > VDC > PDC. Alors que la stratégie utilisant VDC pour affiner WPDC obtient le meilleur résultat.
| Modèle | AFLW (21 pts) | AFLW 2000-3D (68 pts) | Lien de téléchargement |
|---|---|---|---|
| phase1_pdc.pth.tar | 6,956 ± 0,981 | 5,644 ± 1,323 | Baidu Yun ou Google Drive |
| phase1_vdc.pth.tar | 6,717 ± 0,924 | 5,030 ± 1,044 | Baidu Yun ou Google Drive |
| phase1_wpdc.pth.tar | 6,348 ± 0,929 | 4,759 ± 0,996 | Baidu Yun ou Google Drive |
| phase1_wpdc_vdc.pth.tar | 5,401 ± 0,754 | 4,252 ± 0,976 | Dans ce dépôt. |
Croyez-moi, le cadre de ce dépôt peut atteindre de meilleures performances que PRNet sans augmenter le budget de calcul. Les travaux connexes sont en cours d'examen et le code sera publié dès acceptation.
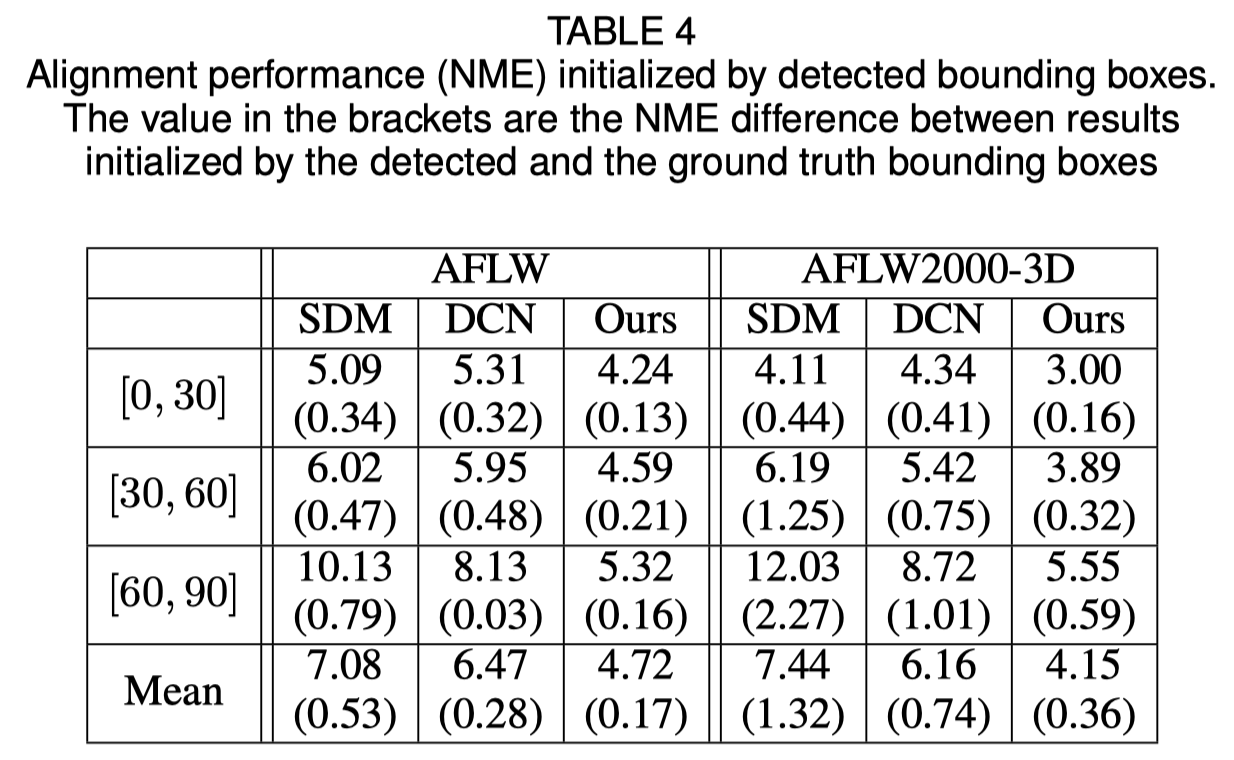
Initialisation du cadre de délimitation du visage
L'article original montre que l'utilisation d'un cadre de délimitation détecté au lieu d'un cadre de vérité terrain entraînera une légère baisse des performances. Ainsi, la méthode actuelle de recadrage du visage est la plus robuste. Les résultats quantitatifs sont présentés dans le tableau ci-dessous.
Reconstruction du visage
La texture de la zone non visible est déformée en raison de l'auto-occlusion, donc la région non visible du visage peut paraître étrange (un peu horrible).
À propos du découpage des paramètres de forme et d’expression
Le découpage des paramètres accélère l'entraînement et la reconstruction, mais dégrade la précision, notamment les détails comme la fermeture des yeux. Ci-dessous une image, avec les paramètres dimension 40+10, 60+29 et 199+29 (celle d'origine). Par rapport à la forme, le détourage d’expression a plus d’effet sur la précision de la reconstruction lorsque l’émotion est impliquée. Par conséquent, vous pouvez choisir un compromis entre la vitesse/taille du paramètre et la précision. Une recommandation de compromis d’écrêtage est 60+29.

Merci de votre intérêt pour ce dépôt. Si votre travail ou votre recherche bénéficie de ce repo, mettez-le en vedette ?
Bienvenue pour vous concentrer sur mes travaux liés au visage 3D : MeGlass et Face Anti-Spoofing.
Si votre travail bénéficie de ce dépôt, veuillez citer trois bibs ci-dessous.
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Jianzhu Guo (郭建珠) [Page d'accueil, Google Scholar] : [email protected] ou [email protected] .


