learning kcp protocol
1.0.0
Dans certaines applications, la simple utilisation de TCP ne peut pas répondre aux besoins. L'utilisation directe de datagrammes UDP ne peut garantir la fiabilité des données, et il est souvent nécessaire de mettre en œuvre un protocole de transmission fiable basé sur UDP au niveau de la couche application.
L'utilisation directe du protocole KCP est une option qui implémente un protocole de retransmission automatique robuste et permet en plus un ajustement gratuit des paramètres. Adaptez-vous aux besoins de différents scénarios grâce à des paramètres de configuration et des méthodes d'appel appropriées.
Introduction à KCP :
KCP est un protocole rapide et fiable qui peut réduire le délai moyen de 30 à 40 % et réduire le délai maximum de trois fois au prix de 10 à 20 % de bande passante en plus que TCP. La mise en œuvre d'algorithmes purs n'est pas responsable de l'envoi et de la réception des protocoles sous-jacents (tels que UDP). Les utilisateurs doivent définir la méthode d'envoi des paquets de données de couche inférieure et la fournir à KCP sous forme de rappel. Même l'horloge doit être transmise en externe et il n'y aura aucun appel système en interne. L'ensemble du protocole ne comporte que deux fichiers sources, ikcp.h et ikcp.c, qui peuvent être facilement intégrés dans la propre pile de protocoles de l'utilisateur. Peut-être avez-vous implémenté un protocole P2P ou basé sur UDP mais il vous manque une implémentation complète et fiable du protocole ARQ. Copiez simplement ces deux fichiers dans le projet existant, écrivez quelques lignes de code et vous pourrez l'utiliser.
Cet article présente brièvement le processus de base d'envoi et de réception, la fenêtre d'encombrement et l'algorithme de délai d'attente du protocole KCP, et fournit également un exemple de code de référence.
La version de KCP référencée est la dernière version au moment de la rédaction. Cet article ne collera pas complètement tout le code source de KCP, mais ajoutera des liens vers les emplacements correspondants du code source à des points clés.
La structure IKCPSEG est utilisée pour stocker l'état des segments de données envoyés et reçus.
Description de tous les champs IKCPSEG :
struct IKCPSEG
{
/* 队列节点,IKCPSEG 作为一个队列元素,此结构指向了队列后前后元素 */
struct IQUEUEHEAD node;
/* 会话编号 */
IUINT32 conv;
/* 指令类型 */
IUINT32 cmd;
/* 分片号 (fragment)
发送数据大于 MSS 时将被分片,0为最后一个分片.
意味着数据可以被recv,如果是流模式,所有分片号都为0
*/
IUINT32 frg;
/* 窗口大小 */
IUINT32 wnd;
/* 时间戳 */
IUINT32 ts;
/* 序号 (sequence number) */
IUINT32 sn;
/* 未确认的序号 (unacknowledged) */
IUINT32 una;
/* 数据长度 */
IUINT32 len;
/* 重传时间 (resend timestamp) */
IUINT32 resendts;
/* 重传的超时时间 (retransmission timeout) */
IUINT32 rto;
/* 快速确认计数 (fast acknowledge) */
IUINT32 fastack;
/* 发送次数 (transmit) */
IUINT32 xmit;
/* 数据内容 */
char data[1];
};
Le champ data à la fin de la structure est utilisé pour indexer les données à la fin de la structure. La mémoire supplémentaire allouée étend la longueur réelle du tableau de champs de données au moment de l'exécution (ikcp.c:173).
La structure IKCPSEG concerne uniquement l'état de la mémoire et seuls certains champs sont codés dans le protocole de transport.
La fonction ikcp_encode_seg code l'en-tête du protocole de transport :
/* 协议头一共 24 字节 */
static char *ikcp_encode_seg(char *ptr, const IKCPSEG *seg)
{
/* 会话编号 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->conv);
/* 指令类型 (1 Bytes) */
ptr = ikcp_encode8u(ptr, (IUINT8)seg->cmd);
/* 分片号 (1 Bytes) */
ptr = ikcp_encode8u(ptr, (IUINT8)seg->frg);
/* 窗口大小 (2 Bytes) */
ptr = ikcp_encode16u(ptr, (IUINT16)seg->wnd);
/* 时间戳 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->ts);
/* 序号 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->sn);
/* 未确认的序号 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->una);
/* 数据长度 (4 Bytes) */
ptr = ikcp_encode32u(ptr, seg->len);
return ptr;
}
La structure IKCPCB stocke tout le contexte du protocole KCP et la communication du protocole est effectuée en créant deux objets IKCPCB à l'extrémité opposée.
struct IKCPCB
{
/* conv: 会话编号
mtu: 最大传输单元
mss: 最大报文长度
state: 此会话是否有效 (0: 有效 ~0:无效)
*/
IUINT32 conv, mtu, mss, state;
/* snd_una: 发送的未确认数据段序号
snd_nxt: 发送的下一个数据段序号
rcv_nxt: 期望接收到的下一个数据段的序号
*/
IUINT32 snd_una, snd_nxt, rcv_nxt;
/* ts_recent: (弃用字段?)
ts_lastack: (弃用字段?)
ssthresh: 慢启动阈值 (slow start threshold)
*/
IUINT32 ts_recent, ts_lastack, ssthresh;
/* rx_rttval: 平滑网络抖动时间
rx_srtt: 平滑往返时间
rx_rto: 重传超时时间
rx_minrto: 最小重传超时时间
*/
IINT32 rx_rttval, rx_srtt, rx_rto, rx_minrto;
/* snd_wnd: 发送窗口大小
rcv_wnd: 接收窗口大小
rmt_wnd: 远端窗口大小
cwnd: 拥塞窗口 (congestion window)
probe: 窗口探测标记位,在 flush 时发送特殊的探测包 (window probe)
*/
IUINT32 snd_wnd, rcv_wnd, rmt_wnd, cwnd, probe;
/* current: 当前时间 (ms)
interval: 内部时钟更新周期
ts_flush: 期望的下一次 update/flush 时间
xmit: 全局重传次数计数
*/
IUINT32 current, interval, ts_flush, xmit;
/* nrcv_buf: rcv_buf 接收缓冲区长度
nsnd_buf: snd_buf 发送缓冲区长度
nrcv_que: rcv_queue 接收队列长度
nsnd_que: snd_queue 发送队列长度
*/
IUINT32 nrcv_buf, nsnd_buf;
IUINT32 nrcv_que, nsnd_que;
/* nodelay: nodelay模式 (0:关闭 1:开启)
updated: 是否调用过 update 函数
*/
IUINT32 nodelay, updated;
/* ts_probe: 窗口探测标记位
probe_wait: 零窗口探测等待时间,默认 7000 (7秒)
*/
IUINT32 ts_probe, probe_wait;
/* dead_link: 死链接条件,默认为 20。
(单个数据段重传次数到达此值时 kcp->state 会被设置为 UINT_MAX)
incr: 拥塞窗口算法的一部分
*/
IUINT32 dead_link, incr;
/* 发送队列 */
struct IQUEUEHEAD snd_queue;
/* 接收队列 */
struct IQUEUEHEAD rcv_queue;
/* 发送缓冲区 */
struct IQUEUEHEAD snd_buf;
/* 接收缓冲区 */
struct IQUEUEHEAD rcv_buf;
/* 确认列表, 包含了序号和时间戳对(pair)的数组元素*/
IUINT32 *acklist;
/* 确认列表元素数量 */
IUINT32 ackcount;
/* 确认列表实际分配长度 */
IUINT32 ackblock;
/* 用户数据指针,传入到回调函数中 */
void *user;
/* 临时缓冲区 */
char *buffer;
/* 是否启用快速重传,0:不开启,1:开启 */
int fastresend;
/* 快速重传最大次数限制,默认为 5*/
int fastlimit;
/* nocwnd: 控流模式,0关闭,1不关闭
stream: 流模式, 0包模式 1流模式
*/
int nocwnd, stream;
/* 日志标记 */
int logmask;
/* 发送回调 */
int (*output)(const char *buf, int len, struct IKCPCB *kcp, void *user);
/* 日志回调 */
void (*writelog)(const char *log, struct IKCPCB *kcp, void *user);
};
typedef struct IKCPCB ikcpcb;
Il n'y a que 2 structures de file d'attente dans KCP :
IQUEUEHEAD est une simple liste doublement chaînée qui pointe vers les éléments de début (précédent) et de dernier (suivant) de la file d'attente :
struct IQUEUEHEAD {
/*
next:
作为队列时: 队列的首元素 (head)
作为元素时: 当前元素所在队列的下一个节点
prev:
作为队列时: 队列的末元素 (last)
作为元素时: 当前元素所在队列的前一个节点
*/
struct IQUEUEHEAD *next, *prev;
};
typedef struct IQUEUEHEAD iqueue_head;
Lorsque la file d'attente est vide, next/prev pointera vers la file d'attente elle-même, et non vers NULL.
L'en-tête de structure IKCPSEG en tant qu'élément de file d'attente réutilise également la structure IQUEUEHEAD :
struct IKCPSEG
{
struct IQUEUEHEAD node;
/* ... */
}
Lorsqu'il est utilisé comme élément de file d'attente, l'élément précédent (prev) et l'élément suivant (next) dans la file d'attente où se trouve l'élément actuel sont enregistrés.
Lorsque prev pointe vers la file d'attente, cela signifie que l'élément actuel est au début de la file d'attente, et lorsque next pointe vers la file d'attente, cela signifie que l'élément actuel est à la fin de la file d'attente.
Toutes les opérations de file d'attente sont fournies sous forme de macros.
Les méthodes de configuration fournies par KCP sont :
Options du mode de travail :
int ikcp_nodelay(ikcpcb *kcp, int nodelay, int interval, int resend, int nc)
Options de fenêtre maximales :
int ikcp_wndsize(ikcpcb *kcp, int sndwnd, int rcvwnd);
La taille de la fenêtre d'envoi sndwnd doit être supérieure à 0 et la taille de la fenêtre de réception rcvwnd doit être supérieure à 128. L'unité est constituée de paquets et non d'octets.
Unité de transmission maximale :
KCP n'est pas responsable de la détection de MTU. La valeur par défaut est de 1 400 octets. Vous pouvez utiliser ikcp_setmtu pour définir cette valeur. Cette valeur affectera l'unité de transmission maximale lors de la combinaison et de la fragmentation des paquets de données. Une MTU plus petite affectera la priorité de routage.
Cet article fournit un code kcp_basic.c qui peut essentiellement exécuter KCP. L'exemple de code de moins de 100 lignes est un pur appel d'algorithme à KCP et n'inclut aucune planification réseau. ( Important : suivez l'article pour le déboguer et essayez-le !)
Vous pouvez l'utiliser pour avoir une compréhension préliminaire des champs de structure de base dans la structure IKCPCB :
kcp.snd_queue : file d'attente d'envoi (longueur d'enregistrement kcp.nsnd_que )kcp.snd_buf : tampon d'envoi (longueur d'enregistrement kcp.nsnd_buf )kcp.rcv_queue : file d'attente de réception (longueur d'enregistrement kcp.nrcv_que )kcp.rcv_buf : tampon de réception (longueur d'enregistrement kcp.nrcv_buf )kcp.mtu : unité de transmission maximalekcp.mss : longueur maximale du messageEt dans la structure IKCPSEG :
seg.sn : numéro de sérieseg.frg : Numéro de segmentCréez la structure de contexte KCP IKCPCB via la fonction ikcp_create.
IKCPCB crée en interne la structure IKCPSEG correspondante pour stocker les données et l'état en appelant en externe ikcp_send (entrée de l'utilisateur vers l'expéditeur) et ikcp_input (entrée de l'expéditeur vers le récepteur).
De plus, la structure IKCPSEG sera supprimée via ikcp_recv (supprimée par l'utilisateur de l'extrémité réceptrice) et les données de confirmation ikcp_input (reçues par l'extrémité émettrice depuis l'extrémité réceptrice).
Pour connaître la direction détaillée du flux de données, consultez la section File d’attente et fenêtre .
La création et la destruction d'IKCPSEG se produisent principalement dans les quatre situations ci-dessus, et d'autres sont courantes dans les mouvements entre les files d'attente internes et d'autres optimisations.
Dans les articles suivants, tous les champs de structure IKCPCB et IKCPSEG qui apparaissent seront mis en évidence par
标记(navigation markdown uniquement, les autres peuvent ne pas le voir). Tous les champs de la structure IKCPCB seront préfixés parkcp.et tous les champs de la structure IKCPSEG seront préfixés parseg.. Habituellement, le nom de variable ou le nom de paramètre de fonction correspondant dans le code source est égalementkcpouseg.
Ce code écrit simplement la longueur de données spécifiée dans l'objet KCP nommé k1 et lit les données de l'objet k2. KCP est configuré en mode par défaut.
Le processus de base peut être simplement décrit via un pseudocode comme :
/* 创建两个 KCP 对象 */
k1 = ikcp_create()
k2 = ikcp_create()
/* 向发送端 k1 写入数据 */
ikcp_send(k1, send_data)
/* 刷出数据,执行 kcp->output 回调 */
ikcp_flush(k1)
/* output 回调接收到带协议包头的分片数据,执行发送 */
k1->output(fragment_data)
/* 接收端 k2 收到输入数据 */
ikcp_input(k2, input_data)
/* 接收端刷出数据,会发送确认包到 k1 */
ikcp_flush(k2)
/* 发送端 k1 收到确认数据 */
recv_data = ikcp_recv(k1, ack_data)
/* 尝试读出数据 */
recv = ikcp_recv(k2)
/* 验证接收数据和发送数据一致 */
assert(recv_data == send_data)
Dans l'exemple de code, l'objet KCP créé est lié à la fonction kcp_user_output en plus de kcp.output qui est utilisée pour définir le comportement des données de sortie de l'objet KCP. kcp.writelog est également lié à la fonction kcp_user_writelog pour le débogage de l'impression.
De plus, étant donné que kcp.output ne peut pas appeler d'autres ikcp_input de manière récursive (car il finira par revenir à son propre kcp.output ), toutes les données de sortie doivent être stockées dans un emplacement intermédiaire, puis saisies dans k2 après avoir quitté kcp.output fonction. C'est l'objectif de la structure OUTPUT_CONTEXT définie dans l'exemple de code.
Essayez d'exécuter l'exemple de code et vous obtiendrez le résultat suivant (le contenu ajouté au signe # est une explication) :
# k1.output 被调用,输出 1400 字节
k1 [RO] 1400 bytes
# k2 被调用 ikcp_input 输入数据
k2 [RI] 1400 bytes
# psh 数据推送分支处理
k2 input psh: sn=0 ts=0
# k2.output 被调用,输出确认包,数据长度24字节
k2 [RO] 24 bytes
# k1 被调用 ikcp_input 输入数据
k1 [RI] 24 bytes
# 序号 sn=0 被确认
k1 input ack: sn=0 rtt=0 rto=100
k1 [RO] 1400 bytes
k1 [RO] 1368 bytes
k2 [RI] 1400 bytes
k2 input psh: sn=1 ts=0
k2 [RI] 1368 bytes
k2 input psh: sn=2 ts=0
k2 [RO] 48 bytes
k1 [RI] 48 bytes
k1 input ack: sn=1 rtt=0 rto=100
k1 input ack: sn=2 rtt=0 rto=100
# k2 被调用 kcp_recv 取出数据
k2 recv sn=0
k2 recv sn=1
k2 recv sn=2
Le contenu de sortie correspond aux informations de débogage imprimées dans le code KCP. Le préfixe de ligne k1/k2 est également ajouté via kcp_user_writelog à titre de distinction.
Le diagramme schématique complet du processus de confirmation d'envoi de ce code est décrit comme (deux fois plus grand) :
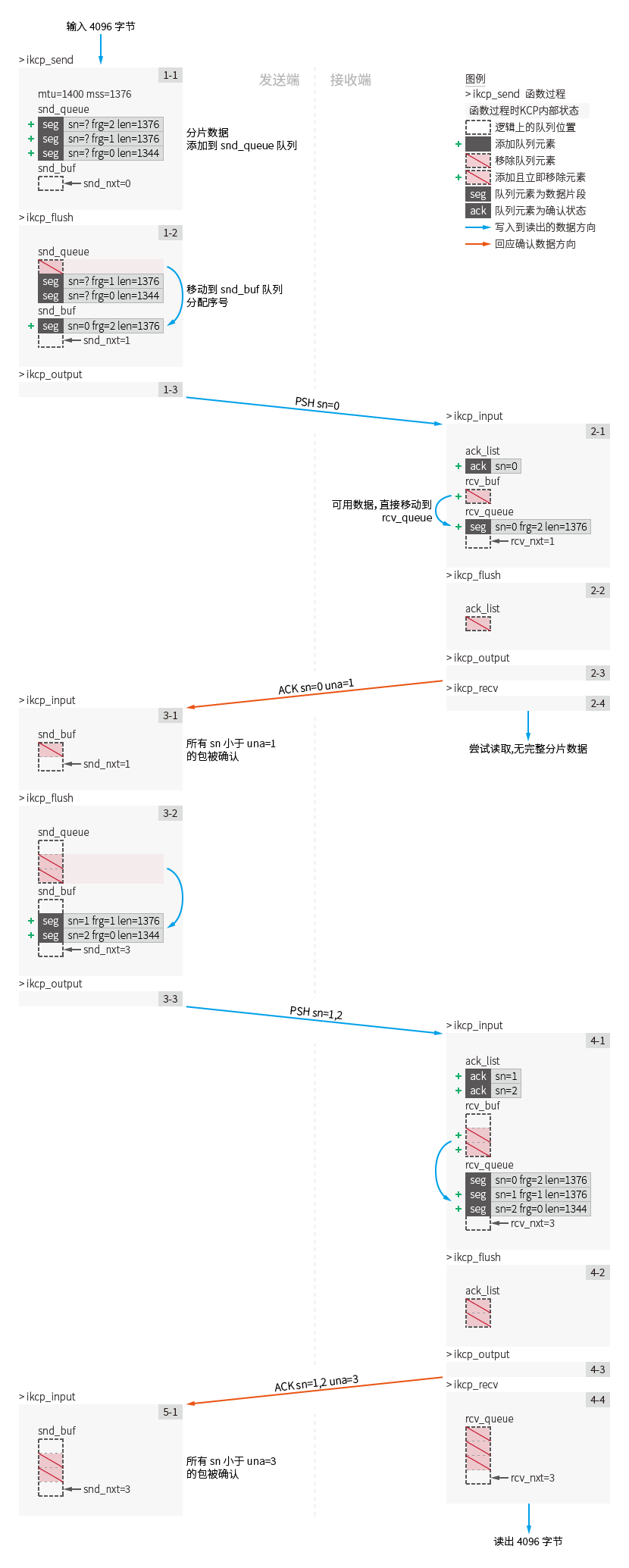
Appelez ikcp_send sur k1 : (Figure étape 1-1)
Les données d'une longueur de 4096 sont écrites vers l'expéditeur. Selon kcp.mss il est coupé en trois paquets d'une longueur de 1376/1376/1344, et seg.frg de chaque paquet sont respectivement 2/1/0.
L'unité de transmission maximale kcp.mtu définit la longueur maximale des données reçues par ikcp.output à chaque fois.
Dans le diagramme schématique, la méthode ikcp_output finira par appeler le pointeur de fonction
ikcp.output. (ikcp.c:212)
La longueur maximale du message de kcp.mss est calculée en soustrayant la surcharge de protocole (24 octets) de kcp.mtu .
Aucun rappel kcp.output ne sera exécuté pour le moment, et toutes les données de partition seront allouées et enregistrées dans la structure IKCPSEG et ajoutées à la file d' kcp.snd_queue (ikcp.c:528).
À l'heure actuelle, la longueur de la file d'attente kcp.snd_queue de k1 est de 3 et la longueur de la file d' kcp.snd_buf est de 0.
Appelez ikcp_flush sur k1 : (Figure étape 1-2)
Le processus de calcul spécifique de la fenêtre est ignoré ici. Il suffit de savoir que la valeur de la fenêtre de congestion
kcp.cwndest 1 lorsque k1 appelle ikcp_flush pour la première fois.
En raison de la limite de la fenêtre de congestion, un seul paquet peut être envoyé pour la première fois. L'objet IKCPSEG avec la première longueur de données de la file d'attente kcp.snd_queue est déplacé vers la file d'attente kcp.snd_buf (ikcp.c:1028) et la valeur du numéro de séquence seg.sn attribué selon kcp.snd_nxt est 0 (ikcp.c:1028). .c:1036) , le champ seg.cmd est IKCP_CMD_PUSH, Représente un package push de données.
À l'heure actuelle, la longueur de la file d'attente kcp.snd_queue de k1 est de 2 et kcp.snd_buf est de 1.
À l'étape 1-3, exécutez l'appel ikcp_output (ikcp.c:1113) sur les premières données envoyées pour envoyer le paquet de données [PSH sn=0 frg=2 len=1376] .
Il n'existe que quatre types de commandes de données : IKCP_CMD_PUSH (envoi de données) IKCP_CMD_ACK (confirmation) IKCP_CMD_WASK (détection de fenêtre) IKCP_CMD_WINS (réponse de fenêtre), défini dans ikcp.c:29
Appelez ikcp_input sur k2 : (Figure étape 2-1)
Saisissez le paquet de données [PSH sn=0 frg=2 len=1376] , analysez l'en-tête du paquet et vérifiez la validité. (ikcp.c:769)
Analysez le type de paquet de données et entrez dans le traitement de la branche push de données. (ikcp.c:822)
Enregistrez la valeur seq.sn et la valeur seq.ts du paquet de données dans la liste de confirmation kcp.acklist (ikcp.c:828). Attention : la valeur de seq.ts dans cet exemple est toujours 0.
Ajoutez les paquets reçus à la file d'attente kcp.rcv_buf . (ikcp:709)
Vérifiez si le premier paquet de données de kcp.rcv_buf est disponible. S'il s'agit d'un paquet de données disponible, il est déplacé vers kcp.rcv_queue . (ikcp.c:726)
Les paquets de données disponibles dans kcp.rcv_buf sont définis comme : le prochain numéro de séquence de données qui devrait être reçu (tiré de kcp.rcv_nxt , où le prochain numéro de séquence de données doit être seg.sn == 0) et la longueur du kcp.rcv_queue La file d'attente kcp.rcv_queue est inférieure à la taille de la fenêtre reçue.
Dans cette étape, le seul paquet de données de la file d'attente kcp.rcv_buf est directement déplacé vers la file d'attente kcp.rcv_queue .
À l'heure actuelle, kcp.>rcv_queue de k2 est de 1 et la longueur de la file d'attente kcp.snd_buf est de 0. La valeur du prochain numéro de séquence de données reçu kcp.rcv_nxt est mise à jour de 0 à 1.
Appelez ikcp_flush sur k2 : (Fig. Étape 2-2)
Dans le premier appel ikcp_flush de k2. Comme il y a des données dans la liste de confirmation kcp.acklist , le paquet de confirmation sera codé et envoyé (ikcp.c:958).
La valeur seg.una dans le paquet de confirmation est affectée à kcp.rcv_nxt =1.
Ce paquet est enregistré comme [ACK sn=0 una=1] : Cela signifie que dans la confirmation d'accusé de réception, le numéro de séquence de paquet 0 est confirmé. Lors d'une confirmation, tous les paquets précédant le paquet numéro 1 sont confirmés.
À l'étape 2-3, kcp.output est appelé pour envoyer le paquet de données.
Appelez ikcp_recv sur k2 : (Figure Étape 2-4)
Vérifiez si la file d'attente kcp.rcv_queue contient un paquet avec seg.frp de 0 (ikcp.c:459). Si elle contient ce paquet, enregistrez le premier paquet seg.frp == 0 et les données du paquet précédent. ce paquet. La longueur totale est renvoyée comme valeur de retour. Sinon, cette fonction renvoie une valeur d'échec de -1.
Étant donné que kcp.rcv_queue ne contient actuellement que le package [PSH sn=0 frg=2 len=1376] , la tentative de lecture a échoué.
S'il est en mode flux (kcp.stream != 0), tous les paquets seront marqués comme
seg.frg=0. À ce stade, tous les paquets de la file d'attentekcp.rcv_queueseront lus avec succès.
Appelez ikcp_input : sur k1 (Figure étape 3-1)
Paquet d'entrée [ACK sn=0 una=1] .
L'UNA confirme :
Tout colis reçu tentera d'abord la confirmation UNA (ikcp.c:789)
Confirmation et suppression de tous les paquets de la file d'attente kcp.snd_buf seg.sn est inférieure à la valeur una (ikcp:599) en confirmant la valeur seg.una du paquet.
[PSH sn=0 frg=2 len=1376] est confirmé et supprimé de la file d'attente kcp.snd_buf de k1.
Confirmation ACK :
Analysez le type de paquet de données et entrez dans le traitement de la branche de confirmation. (ikcp.c:792)
Faites correspondre les numéros de séquence des paquets de confirmation et supprimez les paquets correspondants. (ikcp.c:581)
Lors de la confirmation ACK à l'étape 3-1, la file d' kcp.snd_buf est déjà vide car le seul paquet [PSH sn=0 frg=2 len=1376] a été confirmé par l'UNA à l'avance.
Si kcp.snd_buf sont confirmées ( kcp.snd_una change), la valeur cwnd de la taille de la fenêtre de congestion est recalculée et mise à jour à 2 (ikcp.c:876).
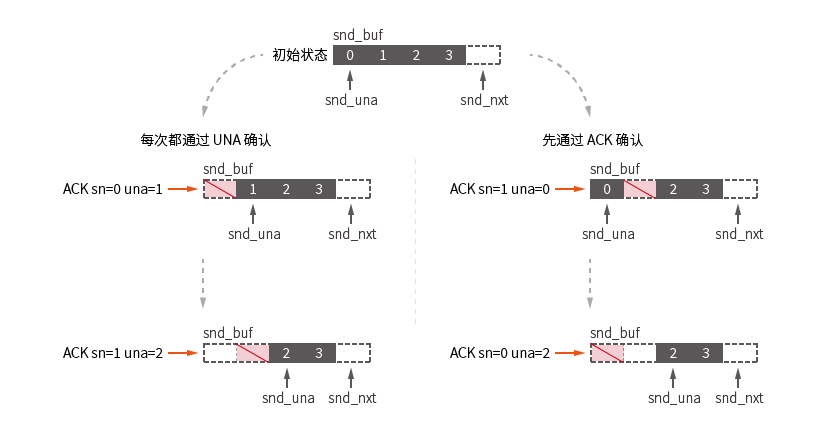
Diagramme de confirmation UNA/ACK, ce diagramme enregistre en outre l'état de kcp.snd_una non marqué dans le diagramme de processus :
L'accusé de réception ACK ne fonctionnera pas pour les paquets d'accusé de réception arrivant séquentiellement. Pour les paquets arrivant dans le désordre, le paquet est supprimé individuellement après confirmation via ACK :
Appelez ikcp_flush sur k1 : (Figure étape 3-2)
Tout comme l'étape 1-2, la valeur de la nouvelle fenêtre de congestion kcp.cwnd a été mise à jour à 2, et les deux paquets restants seront envoyés cette fois : [PSH sn=1 frg=1 len=1376] [PSH sn=2 frg=0 len=1344] .
À l'étape 3-3, kcp.output sera en fait appelé deux fois pour envoyer des paquets de données respectivement.
Appelez ikcp_input : sur k2 (Figure étape 4-1)
Paquets d'entrée [PSH sn=1 frg=1 len=1376] et [PSH sn=2 frg=0 len=1344] .
Chaque paquet est ajouté à la file d'attente kcp.rcv_buf , il est disponible et finalement tout est déplacé vers la file d' kcp.rcv_queue .
À l'heure actuelle, la longueur de la file d'attente kcp.rcv_queue de k2 est de 3 et kcp.snd_buf est de 0. La valeur de kcp.rcv_nxt pour le prochain paquet attendu est mise à jour de 1 à 3.
Appelez ikcp_flush sur k2 : (Figure étape 4-2)
Les informations d'accusé de réception dans kcp.acklist seront codées en paquets [ACK sn=1 una=3] et [ACK sn=2 una=3] et envoyées à l'étape 4-3.
En fait, ces deux paquets seront écrits dans un tampon et un appel kcp.output sera effectué.
Appelez ikcp_recv sur k2 : (Figure étape 4-4)
Il y a maintenant trois paquets non lus dans kcp.rcv_queue : [PSH sn=0 frg=2 len=1376] [PSH sn=1 frg=1 len=1376] et [PSH sn=2 frg=0 len=1344]
À ce moment, un paquet avec seg.frg de 0 est lu et la longueur totale lisible est calculée comme étant de 4096. Ensuite, toutes les données des trois paquets seront lues et écrites dans le tampon de lecture et le succès sera renvoyé.
Il faut faire attention à une autre situation : Si la file d'attente kcp.rcv_queue contient 2 paquets envoyés par l'utilisateur avec seg.frg de 2/1/0/2/1/0 et est fragmentée en 6 paquets de données, le correspondant Il est il est également nécessaire d'appeler ikcp_recv deux fois pour lire toutes les données complètes reçues.
Appelez ikcp_input : sur k1 (Figure étape 5-1)
Saisissez les paquets d'accusé de réception [ACK sn=1 una=3] et [ACK sn=2 una=3] et analysez-les en seg.una =3. Le package [PSH sn=1 frg=1 len=1376] [PSH sn=2 frg=0 len=1344] est confirmé et supprimé de la file d'attente kcp.snd_buf via una.
Toutes les données envoyées ont été accusées de réception.
La fenêtre est utilisée pour le contrôle de flux. Il marque une plage logique de la file d'attente. En raison du traitement des données réelles, la position de la file d'attente continue de se déplacer vers la position haute du numéro de séquence. Logiquement, cette fenêtre continuera à se déplacer, à s'étendre et à se contracter en même temps, c'est pourquoi on l'appelle aussi fenêtre coulissante .
Ce diagramme schématique est une autre représentation des étapes 3-1 à 4-1 de l'organigramme de la section « Processus d'envoi et de réception de données de base ». En tant qu'opérations hors du cadre des étapes, les directions des données sont indiquées par des flèches semi-transparentes.
Toutes les données sont traitées via la fonction indiquée par la flèche et déplacées vers un nouvel emplacement (deux fois la taille de l'image) :
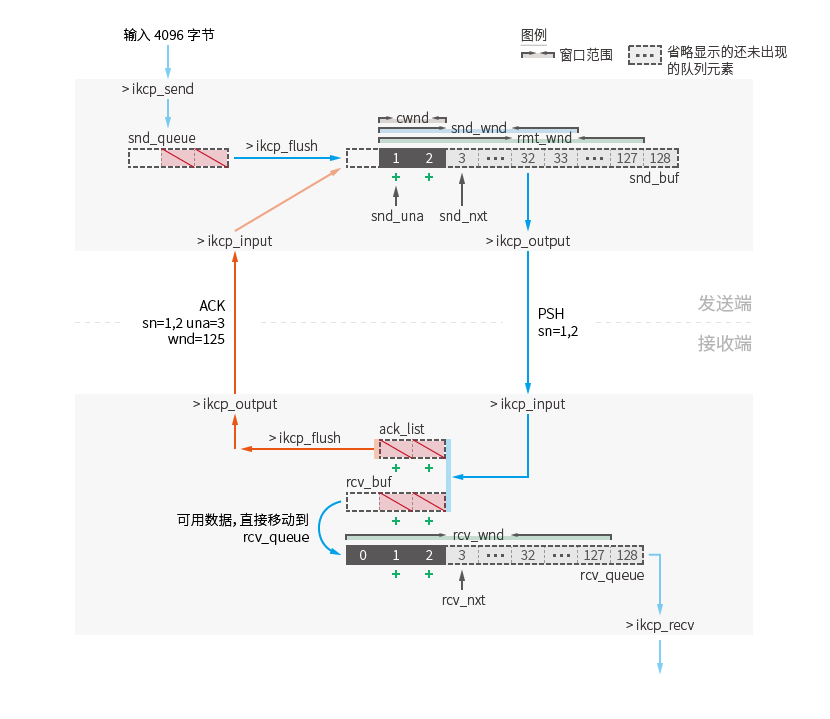
Les données transmises par la fonction ikcp_send du côté de l'envoi seront directement stockées dans la file d'attente d'envoi kcp.snd_queue après le traitement de découpage des données.
chaque fois que ikcp_flush est appelé. La taille de la fenêtre pour cette transmission sera calculée en fonction de la taille de la fenêtre d'envoi kcp.snd_wnd , de la taille de la fenêtre distante kcp.rmt_wnd et de la taille de la fenêtre de congestion kcp.cwnd La valeur est la valeur minimale des trois : min( kcp.snd_wnd , kcp.rmt_wnd , kcp.cwd ) (ikcp.c:1017).
Si le paramètre nc est défini sur 1 via la fonction ikcp_nodelay et que le mode de contrôle de flux est désactivé, le calcul de la valeur de la fenêtre de congestion est ignoré. Le résultat du calcul de la fenêtre d'envoi est min( kcp.snd_wnd , kcp.rmt_wnd ) (ikcp.c:1018).
Dans la configuration par défaut consistant à désactiver uniquement le mode de contrôle de flux, le nombre de paquets de données pouvant être envoyés pour la première fois correspond à la valeur de taille par défaut de kcp.snd_wnd 32. Ceci est différent de l'exemple de processus d'envoi et de réception de base, dans lequel un seul paquet peut être envoyé pour la première fois car le contrôle de flux est activé par défaut.
Les paquets de données nouvellement envoyés seront déplacés vers la file d'attente kcp.snd_buf .
Pour les données ikcp_send, il n'y a qu'une limite de tranche de 127 (c'est-à-dire 127*
kcp.mss= 174752 octets). Il n'y a aucune limite sur le nombre total de paquets dans la file d'attente d'envoi. Voir : Comment éviter les retards d'accumulation du cache
kcp.snd_buf stocke les données qui seront ou ont été envoyées.
Chaque fois que ikcp_flush est appelé, la fenêtre d'envoi est calculée et le paquet de données est déplacé de kcp.snd_queue vers la file d'attente actuelle. Tous les paquets de données dans la file d'attente actuelle seront traités dans trois situations :
1. Premier envoi de données (ikcp.c:1053)
Le nombre de fois qu'un paquet est envoyé sera enregistré dans seg.xmit . Le traitement du premier envoi est relativement simple, et certains paramètres seg.rto / seg.resendts pour le délai d'attente de retransmission seront initialisés.
2. Expiration des données (ikcp.c:1058)
Lorsque le temps kcp.current enregistré en interne dépasse le délai d'expiration seg.resendts du paquet lui-même, une retransmission hors délai se produit.
3. Confirmation du croisement de données (ikcp.c:1072)
Lorsque la fin des données est étendue et que le nombre d'étendues seg.fastack dépasse la configuration de retransmission d'étendue kcp.fastresend , la retransmission d'étendue se produit. ( kcp.fastresend a la valeur par défaut 0, et lorsqu'il est 0, il est calculé comme UINT32_MAX et la retransmission de durée n'aura jamais lieu.) Après un délai de retransmission, le paquet actuel seg.fastack sera réinitialisé à 0.
La liste d'accusé de réception est une simple liste d'enregistrements qui enregistre à l'origine les numéros de séquence et les horodatages ( seg.sn / seg.ts ) dans l'ordre dans lequel les paquets sont reçus.
Par conséquent, dans le diagramme schématique de cet article,
kcp.ack_listn'aura aucune position d'élément vide dessinée. Parce qu'il ne s'agit pas d'une file d'attente logiquement ordonnée (de même, bien que le paquet dans la file d'attentesnd_queuen'ait pas encore reçu de numéro de séquence, son numéro de séquence logique a été déterminé).
L'extrémité réceptrice met en mémoire tampon les paquets de données qui ne peuvent pas être traités temporairement.
Tous les paquets de données provenant de ikcp_input arriveront en premier dans cette file d'attente et les informations seront enregistrées dans kcp.ack_list dans l'ordre d'arrivée d'origine.
Il n'existe que deux situations dans lesquelles les données resteront dans cette file d'attente :
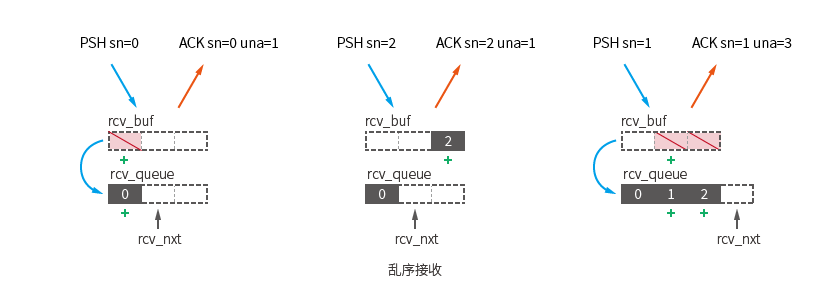
Ici, le paquet [PSH sn=0] est reçu en premier, qui répond aux conditions de paquets disponibles et se déplace vers kcp.rev_queue .
Ensuite, le paquet [PSH sn=2] a été reçu, qui n'était pas le prochain paquet attendu ( seg.sn == kcp.rcv_nxt ), ce qui a amené ce paquet à rester dans kcp.rcv_buf .
Après avoir reçu le paquet [PSH sn=1] , déplacez les deux paquets bloqués [sn=1] [sn=2] vers kcp.rcv_queue .
kcp.rcv_queue atteint la taille de la fenêtre de réception kcp.rcv_wnd (ikcp_recv n'a pas été appelé à temps).L'extrémité réceptrice stocke les données qui peuvent être lues par la couche supérieure.
En mode streaming, tous les paquets disponibles sont lus, en mode non streaming, les segments de données fragmentés sont lus et assemblés en données brutes complètes.
Une fois la lecture terminée, une tentative sera effectuée pour déplacer les données de kcp.rcv_buf vers cette file d'attente (éventuellement pour récupérer d'un état de fenêtre de réception pleine).
La valeur kcp.snd_wnd de la fenêtre d'envoi est une valeur configurée et la valeur par défaut est 32.
La fenêtre distante kcp.rmt_wnd est une valeur qui sera mise à jour lorsque l'expéditeur recevra un paquet du destinataire (pas seulement un paquet d'accusé de réception). Il enregistre la longueur disponible (ikcp.c:1086) de la file d'attente de réception kcp.rcv_queue de l'extrémité réceptrice lorsque le paquet de données actuel est envoyé par l'extrémité réceptrice. La valeur initiale est 128.
La fenêtre de congestion est une valeur calculée qui augmente de manière algorithmique à chaque fois que des données sont reçues via ikcp_input.
Si une perte de paquets et une retransmission rapide sont détectées lors du vidage des données ikcp_flush, elles seront recalculées selon l'algorithme.
La position où
kcp.cwndest initialisé à 1 se trouve dans le premier appel ikcp_update à ikcp_flush.
La valeur kcp.rcv_wnd de la fenêtre de réception est une valeur configurée et la valeur par défaut est 128. Il limite la longueur maximale de la file d'attente de réception kcp.rcv_queue .
Dans cette section, une version améliorée de kcp_optional.c basée sur l'exemple de code de la section « Envoi et réception de données de base » est fournie. Vous pouvez observer davantage le comportement du protocole en modifiant la définition de la macro.
L'exemple de code termine le processus en spécifiant d'écrire un nombre spécifié de données de longueur fixe dans k1 et de les lire entièrement dans k2.
Des macros sont fournies pour contrôler les fonctions spécifiées :
La fenêtre de congestion est enregistrée via les valeurs de kcp.cwnd et kcp.incr . Étant donné que l'unité enregistrée par kcp.cwnd est un paquet, kcp.incr supplémentaire est requis pour enregistrer la fenêtre de congestion exprimée en unités de longueur d'octet.
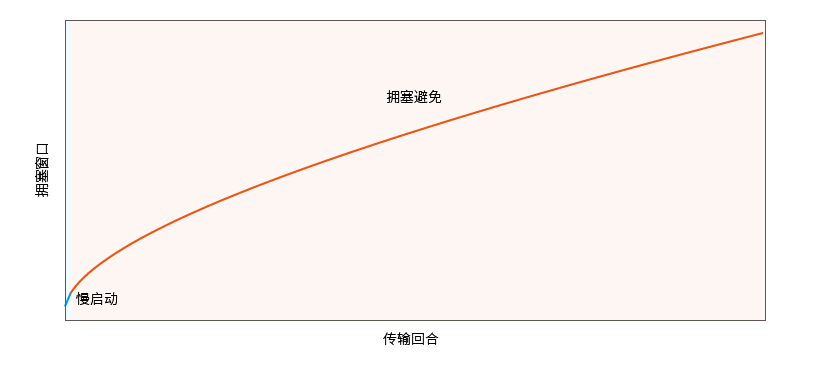
Comme TCP, le contrôle de congestion KCP est également divisé en deux étapes : démarrage lent et évitement de congestion :
La fenêtre de congestion s'agrandit ; lors du processus de confirmation du paquet de données, chaque fois que kcp.snd_buf sont confirmées (confirmation UNA effective, kcp.snd_una change). Et lorsque la fenêtre de congestion est plus petite que la fenêtre distante enregistrée kcp.rmt_wnd , la fenêtre de congestion est augmentée. (ikcp : 875)
1. Si la fenêtre de congestion est plus petite que le seuil de démarrage lent kcp.ssthresh , elle est dans la phase de démarrage lent et la croissance de la fenêtre de congestion est relativement agressive à ce moment-là. La fenêtre de congestion augmente d’une unité.
2. Si la fenêtre de congestion est supérieure ou égale au seuil de démarrage lent, on est dans la phase d'évitement de la congestion et la croissance de la fenêtre de congestion est relativement conservatrice. Si kcp.incr augmente mss/16 à chaque fois, 16 confirmations UNA valides sont requises avant qu'une fenêtre de congestion d'unité ne soit augmentée. La croissance réelle de la fenêtre de phase d’évitement des embouteillages est :
(mss * mss) / incr + (mss / 16)
Puisque incr=cwnd*mss vaut :
((mss * mss) / (cwnd * mss)) + (mss / 16)
Équivalent à :
(mss / cwnd) + (mss / 16)
La fenêtre de congestion augmente progressivement pour chaque cwnd et tous les 16 accusés de réception UNA valides.
Réduction de la fenêtre de congestion : lorsque la fonction ikcp_flush détecte une perte de paquets lors des retransmissions ou des délais d'attente, la fenêtre de congestion est réduite.
1. Lorsque la retransmission du span se produit, le seuil de démarrage lent kcp.ssthresh est défini sur la moitié du span du numéro de séquence non reconnu. La taille de la fenêtre de congestion correspond au seuil de démarrage lent plus la valeur de configuration de retransmission rapide kcp.resend (ikcp:1117) :
ssthresh = (snd_nxt - snd_una) / 2
cwnd = ssthresh + resend
2. Lorsqu'un délai d'expiration de perte de paquets est détecté, le seuil de démarrage lent est défini sur la moitié de la fenêtre de congestion actuelle. Fenêtre de congestion définie sur 1 (ikcp:1126) :
ssthresh = cwnd / 2
cwnd = 1
Observez le démarrage lent 1 : exécutez l'exemple de code avec la configuration par défaut et vous observerez que le processus de démarrage lent est rapidement ignoré. En effet, le seuil de démarrage lent par défaut est 2 :
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
# 收到一个确认包且拥塞窗口小于慢启动阈值,incr 增加一个 mss
t=100 n=1 una=1 nxt=2 cwnd=2|2 ssthresh=2 incr=2752
# 开始拥塞避免
t=200 n=1 una=2 nxt=3 cwnd=2|2 ssthresh=2 incr=3526
t=300 n=1 una=3 nxt=4 cwnd=4|4 ssthresh=2 incr=4148
t=400 n=1 una=4 nxt=5 cwnd=4|4 ssthresh=2 incr=4690
...
t dans le contenu de sortie est l'heure logique, n est le nombre de fois que k1 envoie des données dans le cycle, la valeur de cwnd=1|1 indique que le 1 devant le symbole de la barre verticale est la fenêtre calculée lorsque ikcp_flush, que est, min(kcp. en mode contrôle de flux. snd_wnd, kcp.rmt_wnd, kcp.cwnd), la valeur du 1 suivant est kcp.cwnd .
Observez graphiquement la croissance de la fenêtre de congestion sous la configuration par défaut : en phase d'évitement de congestion, plus la fenêtre de congestion est grande, plus la croissance de la fenêtre de congestion est douce.
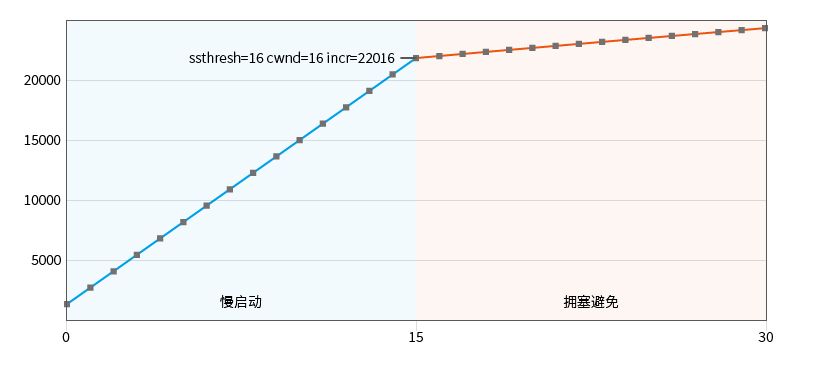
Observez le démarrage lent 2 : Ajustez la valeur initiale du seuil de démarrage lent de la configuration exemple KCP_THRESH_INIT à 16 :
#define KCP_THRESH_INIT 16
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=16 incr=1376
t=100 n=1 una=1 nxt=2 cwnd=2|2 ssthresh=16 incr=2752
t=200 n=1 una=2 nxt=3 cwnd=3|3 ssthresh=16 incr=4128
t=300 n=1 una=3 nxt=4 cwnd=4|4 ssthresh=16 incr=5504
...
t=1300 n=1 una=13 nxt=14 cwnd=14|14 ssthresh=16 incr=19264
t=1400 n=1 una=14 nxt=15 cwnd=15|15 ssthresh=16 incr=20640
t=1500 n=1 una=15 nxt=16 cwnd=16|16 ssthresh=16 incr=22016
# 开始拥塞避免
t=1600 n=1 una=16 nxt=17 cwnd=16|16 ssthresh=16 incr=22188
t=1700 n=1 una=17 nxt=18 cwnd=16|16 ssthresh=16 incr=22359
...
En interceptant seulement une courte période avant le cycle de transmission, on peut observer que le démarrage lent augmente également de manière linéaire par défaut.
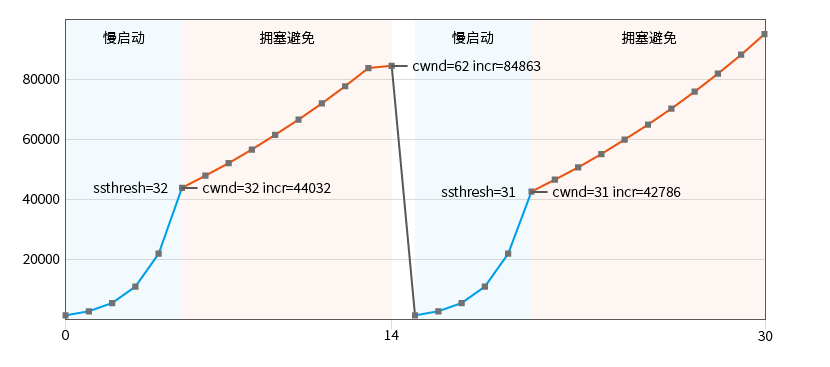
Observez la désactivation de l'accusé de réception différé : envoyez autant de données que possible, désactivez l'option d'envoi différé ACK_DELAY_FLUSH et simulez une perte de paquet :
#define KCP_WND 256, 256
#define KCP_THRESH_INIT 32
#define SEND_DATA_SIZE (KCP_MSS*64)
#define SEND_STEP 16
#define K1_DROP_SN 384
//#define ACK_DELAY_FLUSH
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=32 incr=1376
t=100 n=2 una=1 nxt=3 cwnd=2|2 ssthresh=32 incr=2752
t=200 n=4 una=3 nxt=7 cwnd=4|4 ssthresh=32 incr=5504
t=300 n=8 una=7 nxt=15 cwnd=8|8 ssthresh=32 incr=11008
t=400 n=16 una=15 nxt=31 cwnd=16|16 ssthresh=32 incr=22016
...
t=1100 n=52 una=269 nxt=321 cwnd=52|52 ssthresh=32 incr=72252
t=1200 n=56 una=321 nxt=377 cwnd=56|56 ssthresh=32 incr=78010
t=1300 n=62 una=377 nxt=439 cwnd=62|62 ssthresh=32 incr=84107
t=1400 n=7 una=384 nxt=446 cwnd=62|62 ssthresh=32 incr=84863
t=1500 n=1 una=384 nxt=446 cwnd=1|1 ssthresh=31 incr=1376
t=1600 n=2 una=446 nxt=448 cwnd=2|2 ssthresh=31 incr=2752
t=1700 n=4 una=448 nxt=452 cwnd=4|4 ssthresh=31 incr=5504
t=1800 n=8 una=452 nxt=460 cwnd=8|8 ssthresh=31 incr=11008
t=1900 n=16 una=460 nxt=476 cwnd=16|16 ssthresh=31 incr=22016
...
Dans ce cas, un graphique classique de démarrage lent et d’évitement de congestion est obtenu. Une perte de paquets a été détectée au 15ème cycle de transmission (t=1500) :
La désactivation de l'option d'envoi différé signifie que la partie réceptrice des données appellera ikcp_flush immédiatement après chaque exécution de ikcp_input pour renvoyer un paquet de confirmation.
Le processus de démarrage lent à ce moment augmente de façon exponentielle à chaque RTT (Round-Trip Time, temps d'aller-retour), car chaque paquet d'accusé de réception sera envoyé indépendamment, ce qui entraînera une augmentation de la fenêtre de congestion de l'expéditeur, et parce que la fenêtre de congestion augmente, le nombre de paquets envoyés dans chaque RTT augmentera.
Si la confirmation est retardée, un dossier de confirmation sera envoyé ensemble. Le processus d'augmentation de la fenêtre de congestion ne sera exécuté qu'une fois à chaque appel de la fonction ikcp_input, donc la fusion de plusieurs paquets d'accusé de réception reçus n'aura pas pour effet d'augmenter la fenêtre de congestion plusieurs fois.
Si l'intervalle de cycle d'horloge est supérieur à RTT, il augmentera de façon exponentielle à chaque intervalle. Le diagramme schématique montre une situation possible :
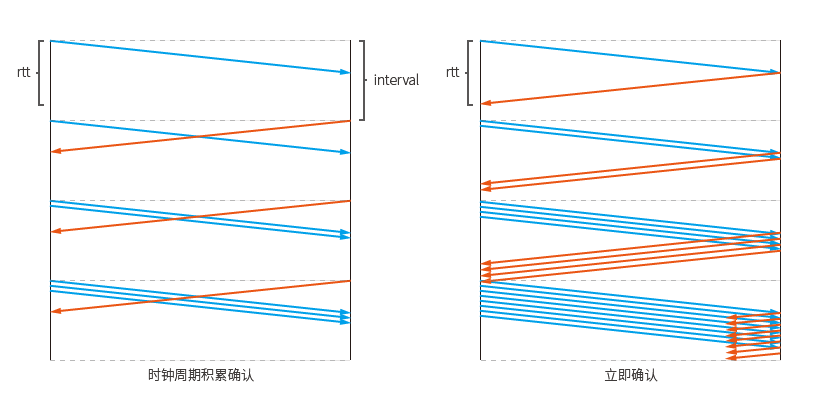
Le principe de la croissance exponentielle est que les données envoyées la prochaine fois peuvent satisfaire deux fois le nombre de paquets de données la dernière fois. Si les données écrites à l'extrémité émettrice sont insuffisantes, une croissance exponentielle ne sera pas obtenue.
Il convient de noter que même si l’exemple de code envoie une confirmation immédiate, cela n’affecte que la manière dont le destinataire envoie une confirmation. L'expéditeur doit également attendre le cycle suivant avant de traiter ces paquets de confirmation. Par conséquent, l'heure t est ici uniquement à titre de référence. À moins que le paquet reçu ne soit pas traité et stocké immédiatement dans le code réel de l'émetteur-récepteur du réseau, il doit attendre le cycle de mise à jour avant de répondre.
Sur la base des caractéristiques de KCP, il doit exister un moyen plus direct d'agrandir la fenêtre de congestion et de désactiver directement le contrôle de flux pour obtenir un envoi plus agressif :
#define KCP_NODELAY 0, 100, 0, 1
#define SEND_DATA_SIZE (KCP_MSS*127)
#define SEND_STEP 1
t=0 n=32 una=0 nxt=32 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=32 una=32 nxt=64 cwnd=32|2 ssthresh=2 incr=2752
t=200 n=32 una=64 nxt=96 cwnd=32|2 ssthresh=2 incr=3526
t=300 n=31 una=96 nxt=127 cwnd=32|4 ssthresh=2 incr=4148
Vous pouvez également modifier directement la valeur de la fenêtre de congestion selon vos besoins.
Observez que la fenêtre distante est pleine : Si la longueur des données envoyées est proche de la taille par défaut de la fenêtre distante et que l'extrémité réceptrice ne la lit pas à temps, vous trouverez une période pendant laquelle aucune donnée ne pourra être envoyée (notez que dans l'exemple de code, l'extrémité réceptrice envoie d'abord le paquet de confirmation, puis lit à nouveau le contenu) :
#define KCP_NODELAY 0, 100, 0, 1
#define SEND_DATA_SIZE (KCP_MSS*127)
#define SEND_STEP 2
t=0 n=32 una=0 nxt=32 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=32 una=32 nxt=64 cwnd=32|2 ssthresh=2 incr=2752
t=200 n=32 una=64 nxt=96 cwnd=32|2 ssthresh=2 incr=3526
t=300 n=32 una=96 nxt=128 cwnd=32|4 ssthresh=2 incr=4148
t=400 n=0 una=128 nxt=128 cwnd=0|4 ssthresh=2 incr=4148
t=500 n=32 una=128 nxt=160 cwnd=32|4 ssthresh=2 incr=4148
t=600 n=32 una=160 nxt=192 cwnd=32|4 ssthresh=2 incr=4690
t=700 n=32 una=192 nxt=224 cwnd=32|4 ssthresh=2 incr=5179
t=800 n=30 una=224 nxt=254 cwnd=31|4 ssthresh=2 incr=5630
Lorsque la taille de la fenêtre distante kcp.rmt_wnd enregistrée dans le récepteur est égale à 0, la phase d'attente de sonde (attente de sonde, ikcp.c:973) sera démarrée dans ikcp_flush. kcp.ts_probe enregistrera une durée initiale de 7 000 millisecondes (enregistrée dans kcp->probe_wait ).
Le moment venu, codez en plus un paquet de type IKCP_CMD_WASK et envoyez-le à l'extrémité réceptrice (ikcp.c:994) pour demander à l'extrémité distante de renvoyer un paquet de type IKCP_CMD_WINS pour mettre à jour kcp.rmt_wnd
Si la taille de la fenêtre distante est toujours 0, kcp->probe_wait augmente de moitié par rapport à la valeur actuelle à chaque fois, puis met à jour le temps d'attente. Le temps d'attente maximum est de 120 000 millisecondes (120 secondes).
Lorsque la taille de la fenêtre distante n'est pas 0, l'état de détection ci-dessus est effacé.
Dans cet exemple, nous n'attendons pas les 7 premières secondes avant de restaurer la taille de la fenêtre distante enregistrée. Parce que lors du fonctionnement de ikcp_recv à la réception pour lire les données, lorsque la longueur de kcp.rcv_queue est supérieure ou égale à la fenêtre de réception kcp.rcv_wnd avant de lire les données (la fenêtre de lecture est pleine), un bit d'indicateur (ikcp .c:431) et envoyer un paquet de type IKCP_CMD_WINS (ikcp.c:1005) la prochaine fois que ikcp_flush Pour demander à l'expéditeur de mettre à jour la dernière taille de fenêtre distante.
Pour éviter ce problème, les données doivent être lues à temps au niveau du destinataire. Cependant, même si la fenêtre distante devient plus petite, la fenêtre d'envoi de l'expéditeur deviendra plus petite, ce qui entraînera des retards supplémentaires. Dans le même temps, il est également nécessaire d'augmenter la fenêtre de réception de l'extrémité réceptrice.
Essayez de modifier la valeur RECV_TIME à une valeur relativement élevée (par exemple, 300 secondes), puis observez l'envoi du paquet IKCP_CMD_WASK.
Comme décrit dans la description de la file d'attente kcp.snd_buf , lors de l'appel de ikcp_flush, tous les paquets de la file d'attente seront parcourus si le paquet n'est pas envoyé pour la première fois. Ensuite, il vérifiera si le paquet a été franchi avec accusé de réception le nombre de fois spécifié ou si le délai d'attente a été atteint.
Les champs liés au temps d'aller-retour et au calcul du délai d'attente sont :
kcp.rx_rttval : temps de gigue réseau fluidekcp.rx_srtt : Temps d'aller-retour fluidekcp.rx_rto (Receive Retransmission Timeout) : délai d'attente de retransmission, valeur initiale 200kcp.rx_minrto : Délai d'expiration minimum de retransmission, valeur initiale 100kcp.xmit : nombre global de retransmissionsseg.resendts : horodatage de retransmissionseg.rto : délai d'attente de retransmissionseg.xmit : nombre de retransmissionsAvant d'aborder la façon dont le package calcule les délais d'attente, examinons d'abord comment les champs associés de temps d'aller-retour et de délai d'attente sont calculés :
Enregistrement de l'heure aller-retour : chaque fois qu'un paquet de confirmation ACK est traité, le paquet de confirmation portera le numéro de séquence et l'heure à laquelle le numéro de séquence a été envoyé à l'expéditeur ( seg.sn / seg.ts ). le processus de mise à jour de l'heure est exécuté.
La valeur de RTT est le temps aller-retour d'un seul paquet, c'est-à-dire RTT = kcp.current - seg.ts
Si le temps aller-retour lissé kcp.rx_srtt est 0, cela signifie que l'initialisation est effectuée: kcp.rx_srtt est directement enregistré comme RTT, kcp.rx_rttval est enregistré comme la moitié de RTT.
Dans le processus de non-initialisation, une valeur delta est calculée, ce qui représente la valeur de fluctuation de ce RTT et du kcp.rx_srtt enregistré (IKCP.C: 550):
delta = abs(rtt - rx_srtt)
Le nouveau kcp.rx_rttval est mis à jour par la valeur pondérée de l'ancien kcp.rx_rttval et Delta:
rx_rttval = (3 * rx_rttval + delta) / 4
Le nouveau kcp.rx_srtt est mis à jour par la valeur pondérée de l'ancien kcp.rx_srtt et RTT, et ne peut pas être inférieur à 1:
rx_srtt = (7 * rx_srtt + rtt) / 8
rx_srtt = max(1, rx_srtt)
Le nouveau rx_rto est mis à jour par la valeur minimale du temps aller-retour lissé kcp.rx_srtt plus le cycle d'horloge kcp.interval et 4 fois rx_rttval , et la plage est limitée à [ kcp.rx_minrto , 60000]:
rto = rx_srtt + max(interval, 4 * rttval)
rx_rto = min(max(`kcp.rx_minrto`, rto), 60000)
Idéalement, lorsque le réseau n'a qu'un délai fixe et aucune gigue, la valeur de kcp.rx_rttval s'approche de 0, et la valeur de kcp.rx_rto est déterminée par le temps aller-retour et le cycle d'horloge lisse.
Diagramme de calcul du temps aller-retour lisse:
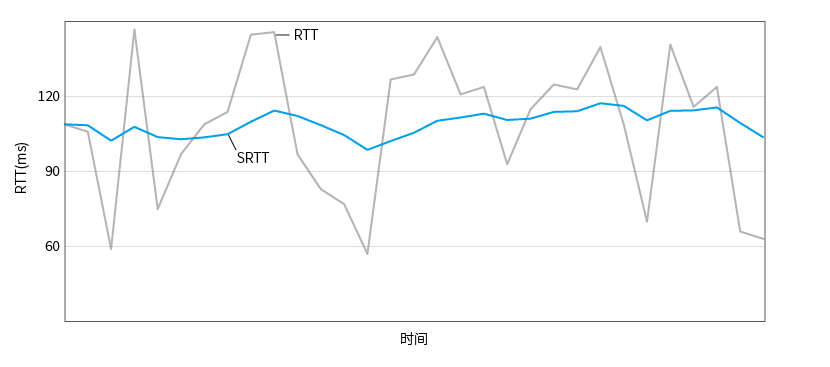
Premier délai de livraison du contrat (IKCP.C: 1052):
seg.rto enregistrera l'état kcp.rx_rto , et le premier temps d'attente du paquet de données est seg.rto + Rtomin millisecondes.
Rtomin est calculé par kcp.rx_rto , si le mode NodeLay est activé. Rtomin est 0, sinon kcp.rx_rto / 8.
Délai d'expiration pour nodelay non activé:
resendts = current + rx_rto + rx_rto / 8
Activer le délai d'expiration de Nodelay:
resendts = current + rx_rto
Rétransmission du délai d'attente (IKCP.C: 1058):
Lorsque le temps interne atteint le temps d'attente seg.resendts du paquet de données, le paquet avec ce numéro de séquence est retransmis.
Lorsque le mode Nodelay n'est pas activé, l'incrément de seg.rto est max ( seg.rto , kcp.rx_rto ) (double croissance):
rto += max(rto, rx_rto)
Lorsque Nodelay est activé et que Nodelay est 1, augmentez seg.rto de moitié à chaque fois (1,5 fois l'augmentation):
rto += rto / 2
Lorsque Nodelay est activé et que Nodelay est 2, kcp.rx_rto est augmenté de moitié à chaque fois (1,5 fois l'augmentation):
rto += rx_rto / 2
Le nouveau délai d'attente est après les millisecondes seg.rto :
resendts = current + rx_rto
Retransmission à travers le temps (IKCP.C: 1072):
Lorsqu'un paquet de données est traversé un nombre spécifié de fois, une retransmission de croisement est déclenchée.
seg.rto n'est pas mis à jour lors de la retransmission dans le temps, et le temps de retransmission à la prochaine saison est directement recalculé:
resendts = current + rto
Observer le délai d'expiration par défaut
Envoyez un seul paquet, déposez-le quatre fois et observez le temps mort et le temps de retransmission.
Pour la configuration par défaut, la valeur initiale de kcp.rx_rto est de 200 millisecondes, et le premier temps de délai est de 225 millisecondes. .
#define SEND_STEP 1
#define K1_DROP_SN 0,0,0,0
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=300 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=700 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1500 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=3100 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
Observez une augmentation de 1,5x de RTO en fonction de l'emballage lui-même
#define KCP_NODELAY 1, 100, 0, 0
#define SEND_STEP 1
#define K1_DROP_SN 0,0,0,0
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=200 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=500 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1000 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1700 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
Regarder une croissance 1,5x basée sur RTO
#define KCP_NODELAY 2, 100, 0, 0
#define SEND_STEP 1
#define K1_DROP_SN 0,0,0,0
t=0 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=200 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=500 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=900 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
...
t=1400 n=1 una=0 nxt=1 cwnd=1|1 ssthresh=2 incr=1376
Observer les retransmissions Span
Les paquets [sn=1] reconnaissance traités en fusion ne déclenchent [sn=0] la retransmission Span [sn=2] En fin de compte, il a été retransmis par le délai d'attente.
#define KCP_NODELAY 0, 100, 2, 1
#define SEND_DATA_SIZE (KCP_MSS*3)
#define SEND_STEP 1
#define K1_DROP_SN 0
t=0 n=3 una=0 nxt=3 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=0 una=0 nxt=3 cwnd=32|1 ssthresh=2 incr=1376
t=200 n=0 una=0 nxt=3 cwnd=32|1 ssthresh=2 incr=1376
t=300 n=1 una=0 nxt=3 cwnd=32|1 ssthresh=16 incr=1376
Lors de l'envoi de paquets de données en deux étapes, le deuxième groupe de paquets sera traversé deux fois lors de la confirmation de la confirmation IKCP_Input, et [sn=0] sera accumulé et retransmis lors du prochain IKCP_FLOSH.
#define KCP_NODELAY 0, 100, 2, 1
#define SEND_DATA_SIZE (KCP_MSS*2)
#define SEND_STEP 2
#define K1_DROP_SN 0
t=0 n=2 una=0 nxt=2 cwnd=32|1 ssthresh=2 incr=1376
t=100 n=2 una=0 nxt=4 cwnd=32|1 ssthresh=2 incr=1376
t=200 n=1 una=0 nxt=4 cwnd=32|4 ssthresh=2 incr=5504
t=300 n=0 una=4 nxt=4 cwnd=32|4 ssthresh=2 incr=5934
L'article est autorisé sous une licence internationale Creative Commons Attribution-NonCommercial-Noderivs 4.0.
Le code du projet est open source à l'aide de la licence MIT.
À propos de la police d'image: noto sans sc


