metal flash attention
v1.0.1
Ce référentiel porte l'implémentation officielle de FlashAttention sur le silicium Apple. Il s'agit d'un ensemble minimal et maintenable de fichiers sources qui reproduisent l'algorithme FlashAttention.
Attention unidirectionnelle uniquement, pour se concentrer sur les principaux goulots d'étranglement des différents algorithmes d'attention (pression de registre, parallélisme). Avec l'algorithme de base exécuté correctement, il devrait être relativement simple d'ajouter des personnalisations telles que la parcimonie des blocs.
Tout est compilé JIT au moment de l'exécution. Cela contraste avec l'implémentation précédente, qui reposait sur un exécutable intégré dans Xcode 14.2.
La passe arrière utilise moins de mémoire que Dao-AILab/flash-attention. L'implémentation officielle alloue un espace de travail pour les atomes et les sommes partielles. Le matériel Apple ne dispose pas d'atomes FP32 natifs ( metal::atomic<float> est émulé). En tentant de contourner le manque de support matériel, des goulots d'étranglement en matière de bande passante et de parallélisation dans le noyau arrière FlashAttention-2 ont été révélés. Une passe arrière alternative a été conçue avec un coût de calcul plus élevé (7 GEMM au lieu de 5 GEMM). Il atteint une efficacité de parallélisation de 100 % sur les dimensions de ligne et de colonne de la matrice d'attention. Plus important encore, il est plus facile à coder et à maintenir.
Beaucoup de choses folles ont été faites pour surmonter les goulets d’étranglement liés à la pression des registres. Pour les grandes dimensions de tête (par exemple 256), aucun des blocs matriciels ne peut rentrer dans les registres. Même l’accumulateur ne le peut pas. Par conséquent, le déversement intentionnel des registres est effectué, mais de manière plus optimisée. Une troisième dimension de bloc a été ajoutée à l'algorithme d'attention, qui bloque le long D . Le rapport hauteur/largeur des blocs de la matrice d'attention a été considérablement déformé, afin de minimiser le coût de la bande passante dû au déversement des registres. Par exemple, 16-32 le long de la dimension de parallélisation et 80-128 le long de la dimension de traversée. Il existe un gros fichier de paramètres qui prend la dimension D et détermine quels opérandes peuvent tenir dans les registres. Il attribue ensuite une taille de bloc qui équilibre de nombreux goulots d'étranglement concurrents.
Le résultat final est un débit constant de 4 400 giga-instructions par seconde sur M1 Max (83 % d'utilisation de l'ALU), avec une longueur de séquence infinie et une dimension de tête infinie. À condition que l'émulation BF16 soit utilisée pour une précision mixte ( bfloat de Metal a un arrondi conforme à la norme IEEE, une surcharge importante sur les puces plus anciennes sans matériel BF16).
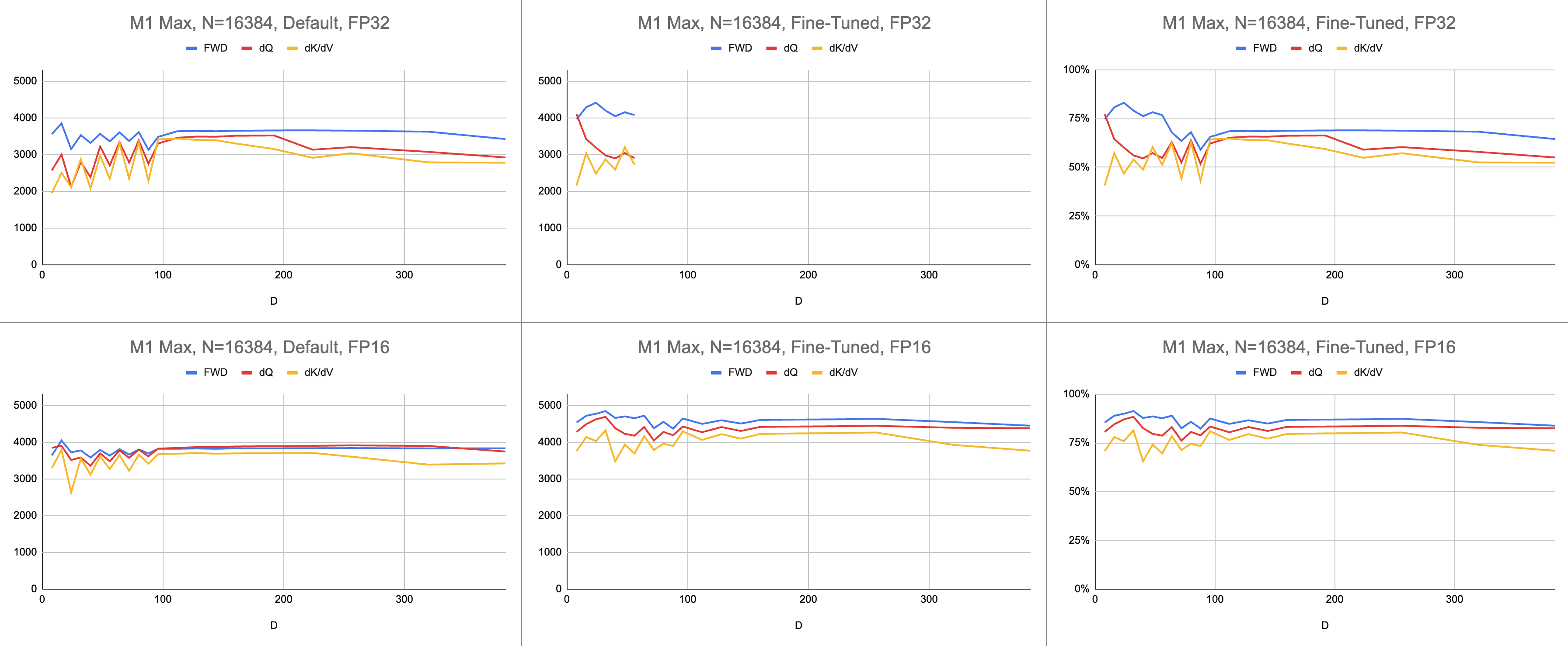
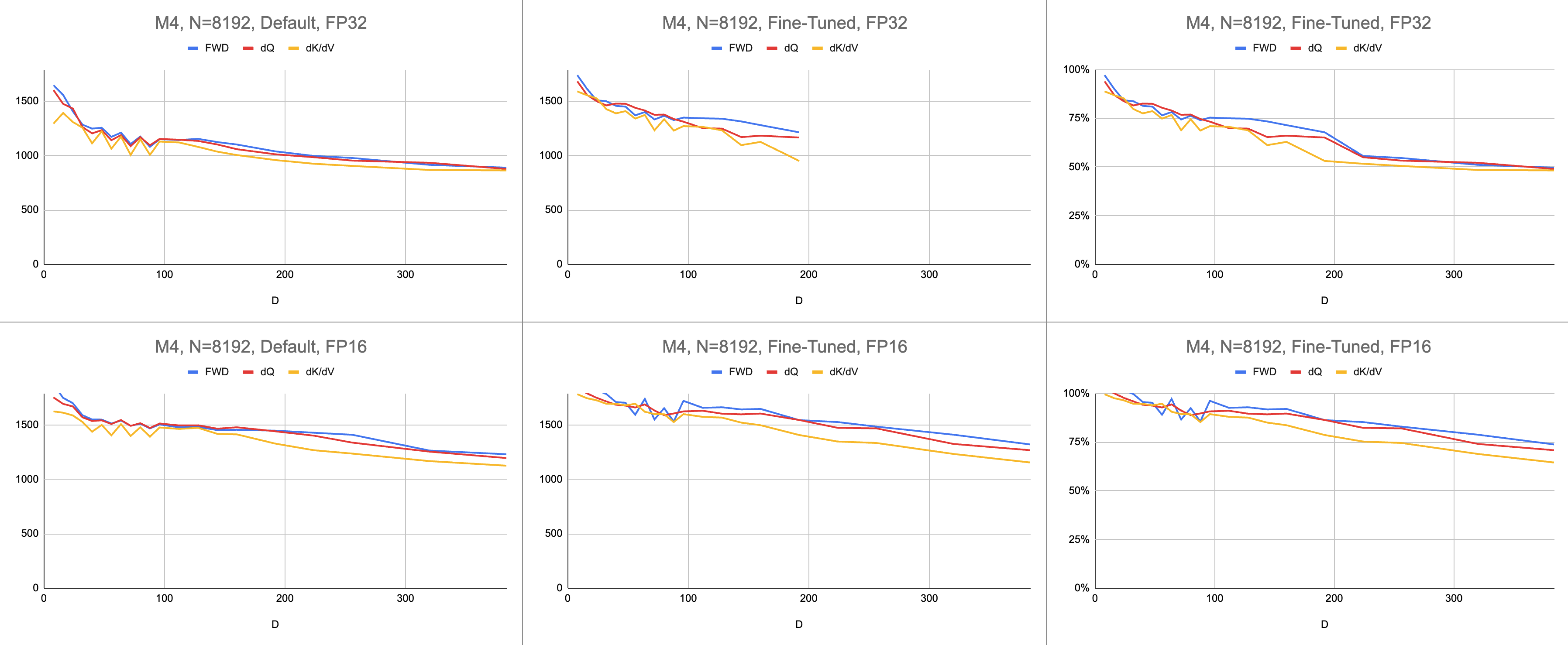
Données brutes : https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
Dans le domaine de l’IA, les performances sont le plus souvent exprimées en opérations à virgule flottante par seconde (GFLOPS). Cette métrique reflète un modèle simplifié de performances, dans lequel chaque instruction se produit dans GEMM. À mesure que le matériel a évolué depuis les premiers FPU jusqu'aux processeurs vectoriels modernes, les opérations à virgule flottante les plus courantes ont été fusionnées en une seule instruction. Multiplication-ajout fusionnée (FMA). Lorsqu'on multiplie deux matrices 100x100, 1 million d'instructions FMA sont émises. Pourquoi devons-nous traiter ce FMA comme deux instructions distinctes ?
Cette question mérite attention, car toutes les opérations en virgule flottante ne sont pas créées égales. L'exponentiation pendant softmax se produit en un seul cycle d'horloge, étant donné que la plupart des autres instructions vont à l'unité FMA. Certaines multiplications et ajouts pendant softmax ne peuvent pas être fusionnés avec une addition ou une multiplication à proximité. Devrions-nous les traiter de la même manière que FMA et prétendre que le matériel exécute simplement le FMA deux fois plus lentement ? On ne sait pas comment le modèle de performances GEMM peut expliquer si mon shader utilise efficacement le matériel ALU.
Au lieu de gigaflops, j'utilise des gigainstructions pour comprendre les performances du shader. Il correspond plus directement à l’algorithme. Par exemple, un GEMM est constitué N^3 instructions FMA. L'attention directe effectue deux multiplications matricielles, soit 2 * D * N^2 instructions FMA. L'attention arrière (par l'implémentation Dao-AILab/flash-attention) est constituée de 5 * D * N^2 instructions FMA. Essayez de comparer ce tableau aux modèles de ligne de toit dans les articles Flash1, Flash2 ou Flash3.
| Opération | Travail |
|---|---|
| GEMME Carré | N^3 |
| Attention directe | (2D + 5) * N^2 |
| Attention naïve en arrière | 4D * N^2 |
| FlashAttention arrière | (5D + 5) * N^2 |
| FWD + BWD combinés | (7D + 10) * N^2 |
En raison de la complexité des atomes FP32, MFA a utilisé une approche différente pour le passage en arrière. Celui-ci a un coût de calcul plus élevé. Il divise le passage en arrière en deux noyaux distincts : dQ et dK/dV . Une liste déroulante affiche le pseudocode. Comparez cela à l'un des algorithmes des articles Flash1, Flash2 ou Flash3.
| Opération | Travail |
|---|---|
| Avant | (2D + 5) * N^2 |
| dQ en arrière | (3D + 5) * N^2 |
| En arrière dK/dV | (4D + 5) * N^2 |
| FWD + BWD combinés | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }Les performances sont mesurées en calculant la quantité de travail de calcul, puis en la divisant par secondes. Le résultat final est "gigainstructions par seconde". Ensuite, nous avons besoin d’un modèle de ligne de toit. Le tableau ci-dessous montre les lignes de toit pour GINSTRS, calculées comme la moitié des GFLOPS. L'utilisation de l'ALU est de (giga-instructions réelles par seconde) / (giga-instructions attendues par seconde). Par exemple, M1 Max atteint généralement 80 % d’utilisation de l’ALU avec une précision mitigée.
Il y a des limites à ce modèle. Il tombe en panne avec la génération M3 avec de petites dimensions de tête. Différentes unités de calcul peuvent être utilisées simultanément, ce qui rend l'utilisation apparente supérieure à 100 %. Pour l’essentiel, le benchmark fournit un modèle précis du niveau de performance restant sur la table.
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| Matériel | GFLOPS | GINSTREURS |
|---|---|---|
| M1 Max | 10616 | 5308 |
| M4 | 3580 | 1790 |
Dans quelle mesure le portage Metal se compare-t-il au référentiel officiel FlashAttention ? Imaginez que j'utilise l'algorithme "atomic dQ" et que j'obtienne des performances à 100 %. Ensuite, je suis passé au référentiel MFA actuel et j'ai constaté que la formation du modèle était 4 fois plus lente. Cela représenterait 25 % de la ligne de toit du référentiel officiel. Pour obtenir ce pourcentage, multipliez l'utilisation moyenne de l'ALU sur les trois noyaux par 7 / 9 . Un modèle plus nuancé a été utilisé pour les statistiques sur le matériel Apple, mais c'est l'essentiel.
Pour calculer l'utilisation du matériel Nvidia, j'ai utilisé GFLOPS pour les ALU FP16/BF16. J'ai divisé les GFLOPS les plus élevés de chaque graphique du document par 312 000 (A100 SXM), 989 000 (H100 SXM). Notez que, pour les dimensions de tête plus grandes et les noyaux intensifs en registre (passage arrière), aucun test de référence n'a été signalé. J'ai confirmé qu'ils n'avaient pas résolu le problème de pression du registre à des dimensions de tête infinies. Par exemple, l'accumulateur est toujours conservé dans des registres. Au moment de la rédaction de cet article, je n'avais pas vu de preuves concrètes de l'exécution d'un gradient arrière D = 256 avec des résultats corrects.
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avant | 192000 | 223000 | 0 |
| En arrière | 170000 | 196000 | 0 |
| Avant + Arrière | 176000 | 203000 | 0 |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avant | 497000 | 648000 | 756000 |
| En arrière | 474000 | 561000 | 0 |
| Avant + Arrière | 480000 | 585000 | 0 |
| H100, Flash3, FP8 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avant | 613000 | 1008000 | 1171000 |
| En arrière | 0 | 0 | 0 |
| Avant + Arrière | 0 | 0 | 0 |
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avant | 62% | 71% | 0% |
| Avant + Arrière | 56% | 65% | 0% |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avant | 50% | 66% | 76% |
| Avant + Arrière | 48% | 59% | 0% |
| M1 Architecture, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avant | 86% | 85% | 86% |
| Avant + Arrière | 62% | 63% | 64% |
| M3 Architecture, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Avant | 94% | 91% | 82% |
| Avant + Arrière | 71% | 69% | 61% |
| Matériel produit en 2020 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| Architecture M1-M2 | 62% | 63% | 64% |
| Matériel produit en 2023 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| H100 (en utilisant FP8 GFLOPS) | 24% | 30% | 0% |
| H100 (en utilisant FP16 GFLOPS) | 48% | 59% | 0% |
| Architecture M3—M4 | 71% | 69% | 61% |
Malgré davantage de calculs, le matériel Apple entraîne les transformateurs plus rapidement que le matériel Nvidia qui effectue le même travail . Normalisation de la différence de taille entre les différents GPU. Concentrez-vous simplement sur l’efficacité avec laquelle le GPU est utilisé.
Peut-être que le référentiel principal devrait essayer l'algorithme qui évite les atomes FP32 et renverse délibérément les registres lorsqu'ils ne peuvent pas tenir dans le cœur du GPU. Cela semble peu probable, car ils prennent en charge en dur un petit sous-ensemble des tailles de problèmes possibles. La motivation semble prendre en charge les modèles les plus courants, où D est une puissance de 2 et inférieure à 128. Pour tout le reste, les utilisateurs doivent s'appuyer sur des implémentations de secours alternatives (par exemple le référentiel MFA), qui peuvent utiliser un sous-jacent complètement différent. algorithme.
Sur macOS, téléchargez le package Swift et compilez avec -Xswiftc -Ounchecked . Cette option du compilateur est nécessaire pour le code CPU sensible aux performances. Le mode Release ne peut pas être utilisé car il force la recompilation complète de la base de code à partir de zéro, à chaque fois qu'il y a une seule modification. Accédez au dépôt Git dans le Finder et double-cliquez sur Package.swift . Une fenêtre Xcode devrait apparaître. Sur la gauche, il devrait y avoir une hiérarchie de fichiers. Si vous ne parvenez pas à démêler la hiérarchie, quelque chose s’est mal passé.
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
Vous pouvez également créer un nouveau projet Xcode avec le modèle SwiftUI. Remplacez le message "Hello, world!" string avec un appel à une fonction qui renvoie un String . Cette fonction exécutera le script de votre choix, puis appellera exit(0) , de sorte que l'application se bloque avant d'afficher quoi que ce soit à l'écran. Vous utiliserez la sortie dans la console Xcode comme retour sur votre code. Ce flux de travail est compatible avec macOS et iOS.
Ajoutez l'option -Xswiftc -Ounchecked via Project > your project's name > Build Settings > Swift Compiler - Code Generation > Optimization Level . La deuxième colonne du tableau répertorie le nom de votre projet. Cliquez sur Autre dans la liste déroulante et tapez -Ounchecked dans le panneau qui apparaît. Ensuite, ajoutez ce référentiel en tant que dépendance du package Swift. Parcourez certains des tests sous Tests/FlashAttention . Copiez le code source brut de l'un de ces tests dans votre projet. Invoquez le test à partir de la fonction du paragraphe précédent. Examinez ce qu'il affiche sur la console.
Pour modifier la génération de code Metal (par exemple ajouter la prise en charge de plusieurs têtes ou de masques), copiez le code Swift brut dans votre projet Xcode. Utilisez soit git clone dans un dossier séparé, soit téléchargez les fichiers bruts sur GitHub au format ZIP. Il existe également un moyen de créer un lien vers votre fork de metal-flash-attention et d'enregistrer automatiquement vos modifications dans le cloud, mais cela est plus difficile à mettre en place. Supprimez la dépendance du package Swift du paragraphe précédent. Refaites le test de votre choix. Est-ce qu'il compile et affiche quelque chose dans la console ?
Recherchez l'un des littéraux de chaîne multiligne dans l'un de ces dossiers :
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
Ajoutez du texte aléatoire à l’un d’eux. Compilez et exécutez à nouveau le projet. Quelque chose devrait terriblement mal se passer. Par exemple, le compilateur Metal peut générer une erreur. Si cela ne se produit pas, essayez de modifier une autre ligne de code ailleurs. Si le test réussit toujours, Xcode n'enregistre pas vos modifications.
Continuez à coder la rareté des blocs ou quelque chose du genre. Obtenez des commentaires pour savoir si le code fonctionne, s'il fonctionne rapidement, s'il fonctionne rapidement quelle que soit la taille du problème. Intégrez le code source brut dans votre application ou traduisez-le dans un autre langage de programmation.


