yoloface
1.0.0
Le YOLOv3 (You Only Look Once) est un algorithme de détection d'objets en temps réel de pointe. Le modèle publié reconnaît 80 objets différents dans les images et vidéos. Pour plus de détails, vous pouvez vous référer à cet article.
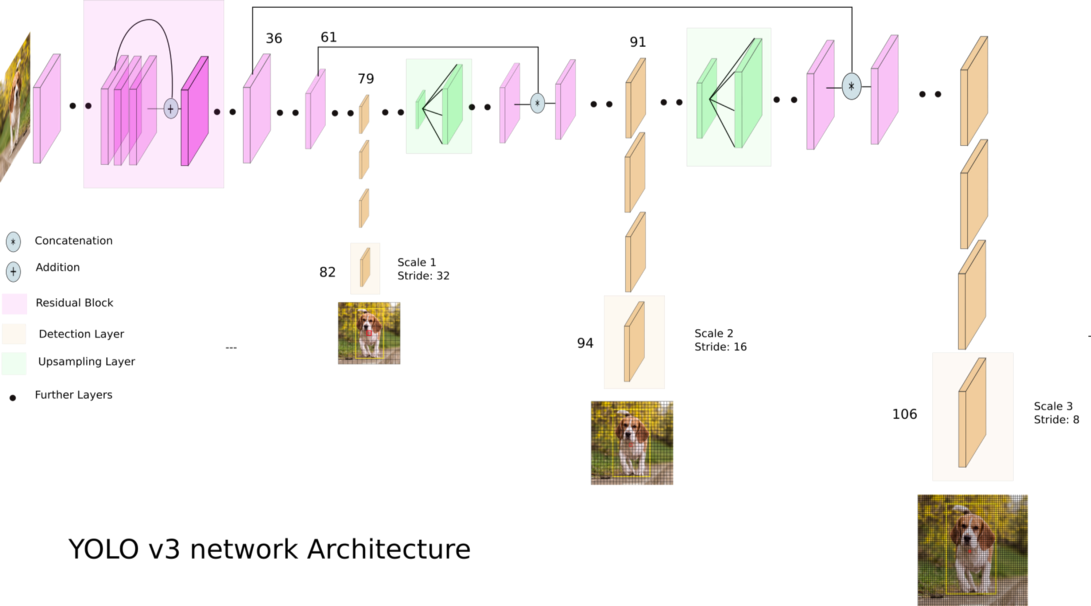
Crédit : Ayoosh Kathuria
Le module OpenCV dnn prend en charge l'exécution d'inférences sur des modèles d'apprentissage profond pré-entraînés à partir de frameworks populaires tels que TensorFlow, Torch, Darknet et Caffe.
Le développement de ce projet sera isolé dans l'environnement virtuel Python. Cela nous permet d'expérimenter différentes versions de dépendances.
Il existe de nombreuses façons d'installer virtual environment (virtualenv) , voir le guide Python Virtual Environments : A Primer pour différentes plates-formes, mais en voici quelques-unes :
$ pip install virtualenv$ pip install --upgrade virtualenvCréez un environnement virtuel Python 3.6 pour ce projet et activez le virtualenv :
$ virtualenv -p python3.6 yoloface
$ source ./yoloface/bin/activateEnsuite, installez les dépendances pour ce projet :
$ pip install -r requirements.txt$ git clone https://github.com/sthanhng/yoloface Pour la détection des visages, vous devez télécharger le fichier de pondérations YOLOv3 pré-entraîné qui a été formé sur l'ensemble de données WIDER FACE : A Face Detection Benchmark à partir de ce lien et placez-le dans le répertoire model-weights/ .
Exécutez la commande suivante :
entrée d'image
$ python yoloface.py --image samples/outside_000001.jpg --output-dir outputs/entrée vidéo
$ python yoloface.py --video samples/subway.mp4 --output-dir outputs/webcam
$ python yoloface.py --src 1 --output-dir outputs/
Ce projet est sous licence MIT - voir le fichier LICENSE.md pour plus de détails.


