FLASH pytorch
0.1.9
Implémentation de la variante Transformer proposée dans l'article Transformer Quality in Linear Time
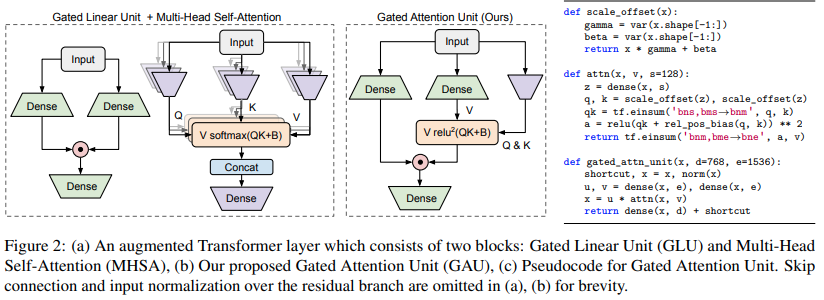
$ pip install FLASH-pytorchLe principal nouveau circuit présenté dans cet article est la « Gated Attention Unit », qui, selon eux, peut remplacer l'attention à plusieurs têtes tout en la réduisant à une seule tête.
Il utilise une activation relu au carré à la place du softmax, dont l'activation a été vue pour la première fois dans l'article Primer, et l'utilisation de ReLU dans ReLA Transformer. Le style de gating semble principalement inspiré des gMLP.
import torch
from flash_pytorch import GAU
gau = GAU (
dim = 512 ,
query_key_dim = 128 , # query / key dimension
causal = True , # autoregressive or not
expansion_factor = 2 , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1024 , 512 )
out = gau ( x ) # (1, 1024, 512) Les auteurs combinent ensuite GAU avec l'attention linéaire de Katharopoulos, en utilisant le regroupement des séquences pour surmonter un problème connu avec l'attention linéaire autorégressive.
Cette combinaison de l'unité d'attention quadratique fermée avec une attention linéaire groupée qu'ils ont nommée FLASH
Vous pouvez également l'utiliser assez facilement
import torch
from flash_pytorch import FLASH
flash = FLASH (
dim = 512 ,
group_size = 256 , # group size
causal = True , # autoregressive or not
query_key_dim = 128 , # query / key dimension
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1111 , 512 ) # sequence will be auto-padded to nearest group size
out = flash ( x ) # (1, 1111, 512)Enfin, vous pouvez utiliser le transformateur FLASH complet comme mentionné dans le document. Celui-ci contient tous les intégrations positionnelles mentionnées dans l'article. L'intégration positionnelle absolue utilise une sinusoïdale mise à l'échelle. L'attention quadratique de GAU obtiendra un biais de position relatif T5 à une tête. En plus de tout cela, l'attention GAU ainsi que l'attention linéaire seront intégrées de manière rotative (RoPE).
import torch
from flash_pytorch import FLASHTransformer
model = FLASHTransformer (
num_tokens = 20000 , # number of tokens
dim = 512 , # model dimension
depth = 12 , # depth
causal = True , # autoregressive or not
group_size = 256 , # size of the groups
query_key_dim = 128 , # dimension of queries / keys
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
norm_type = 'scalenorm' , # in the paper, they claimed scalenorm led to faster training at no performance hit. the other option is 'layernorm' (also default)
shift_tokens = True # discovered by an independent researcher in Shenzhen @BlinkDL, this simply shifts half of the feature space forward one step along the sequence dimension - greatly improved convergence even more in my local experiments
)
x = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
logits = model ( x ) # (1, 1024, 20000) $ python train.py @article { Hua2022TransformerQI ,
title = { Transformer Quality in Linear Time } ,
author = { Weizhe Hua and Zihang Dai and Hanxiao Liu and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.10447 }
} @software { peng_bo_2021_5196578 ,
author = { PENG Bo } ,
title = { BlinkDL/RWKV-LM: 0.01 } ,
month = { aug } ,
year = { 2021 } ,
publisher = { Zenodo } ,
version = { 0.01 } ,
doi = { 10.5281/zenodo.5196578 } ,
url = { https://doi.org/10.5281/zenodo.5196578 }
} @inproceedings { Ma2022MegaMA ,
title = { Mega: Moving Average Equipped Gated Attention } ,
author = { Xuezhe Ma and Chunting Zhou and Xiang Kong and Junxian He and Liangke Gui and Graham Neubig and Jonathan May and Luke Zettlemoyer } ,
year = { 2022 }
}

