azure search openai demo csharp
2024-09-16 - Enhanced Deployment and Documentation Updates
| page_type | langues | produits | urlfragment | nom | description | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
échantillon |
|
| azur-search-openai-demo-csharp | Chatgpt + Enterprise Data (CSHARP) | Un exemple de CSHARP qui discute avec vos données à l'aide de la recherche OpenAI et AI. |
Cet échantillon démontre quelques approches pour créer des expériences de type Chatgpt sur vos propres données en utilisant le modèle de génération augmenté de récupération. Il utilise le service Azure OpenAI pour accéder au modèle ChatGPT ( gpt-4o-mini ), et Azure AI recherche l'indexation et la récupération des données.
Le repo comprend des exemples de données afin qu'il soit prêt à essayer de bout en bout. Dans cet exemple de demande, nous utilisons une entreprise fictive appelée Contoso Electronics, et l'expérience permet à ses employés de poser des questions sur les avantages, les politiques internes, ainsi que les descriptions et les rôles.
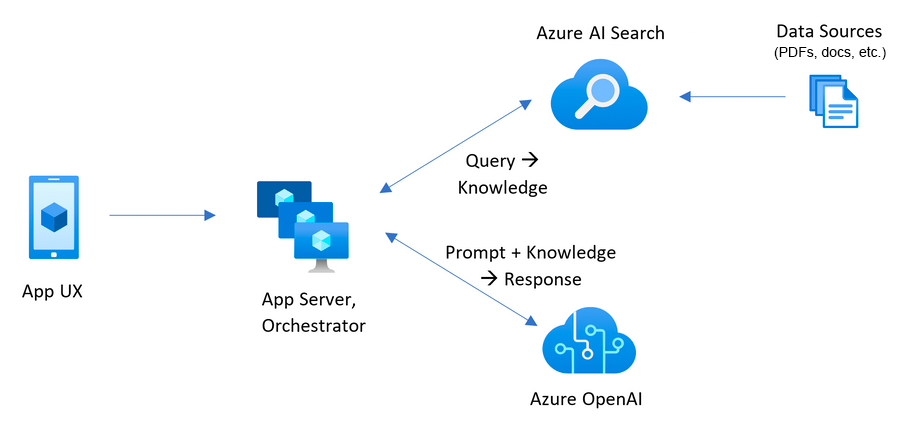
Pour plus de détails sur la façon dont cette application a été construite, consultez:
Nous voulons avoir de vos nouvelles! Êtes-vous intéressé à créer ou à construire actuellement des applications intelligentes? Prenez quelques minutes pour répondre à cette enquête.
Faire enquête
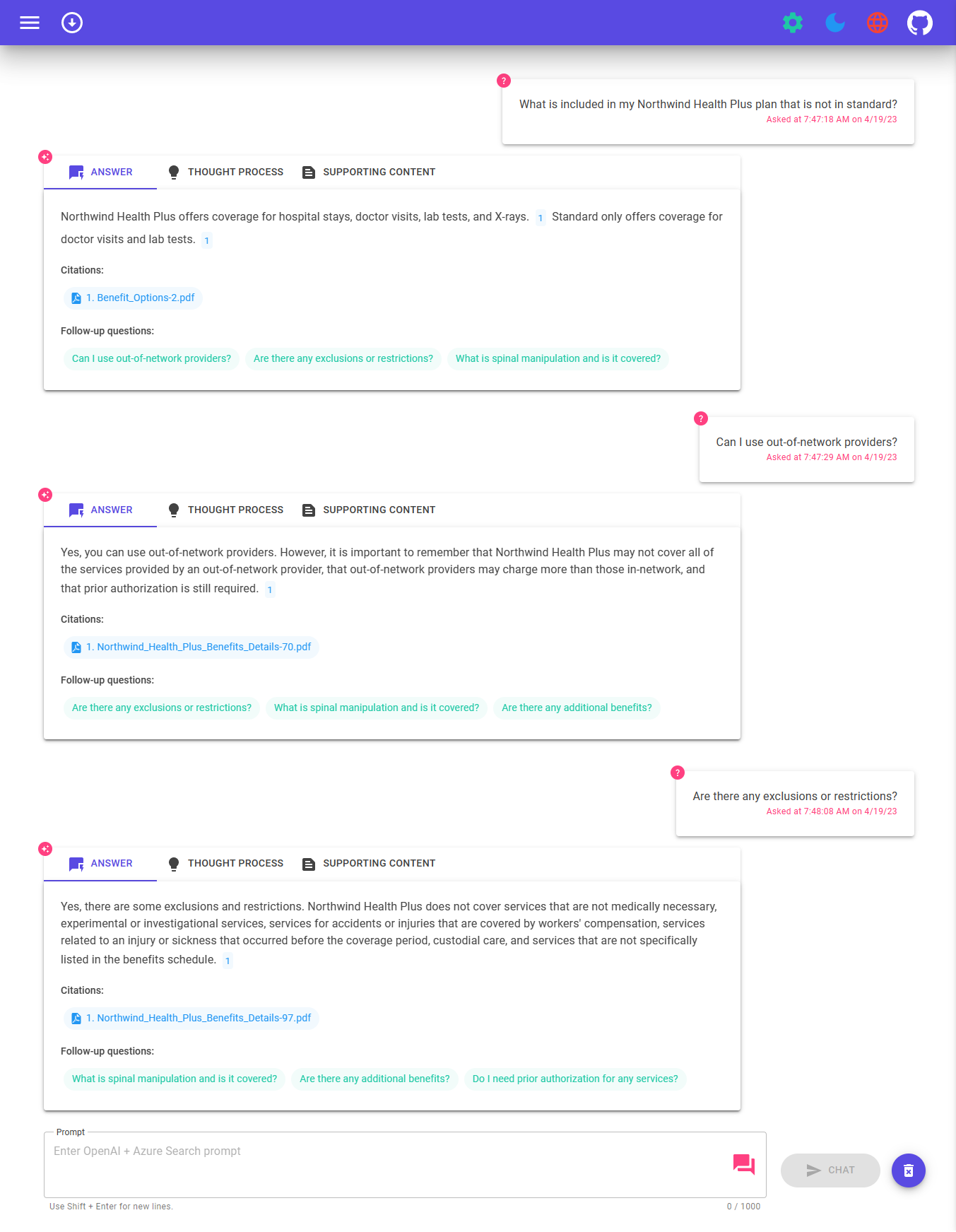
Afin de déployer et d'exécuter cet exemple, vous aurez besoin
Microsoft.Authorization/roleAssignments/write , telles que l'administrateur d'accès utilisateur ou le propriétaire. Avertissement
Par défaut, cet échantillon créera une application de conteneur Azure et une ressource de recherche Azure AI qui a un coût mensuel, ainsi que la ressource Azure AI Document Intelligence qui a le coût par page de document. Vous pouvez les basculer vers des versions gratuites de chacun d'eux si vous souhaitez éviter ce coût en modifiant le fichier Paramètres dans le dossier infra (bien qu'il y ait des limites à considérer; par exemple, vous pouvez avoir jusqu'à 1 ressource de recherche AI AI gratuite par abonnement, et la ressource d'intelligence de document AI gratuit AI analyse uniquement les 2 premières pages de chaque document.)
Le prix varie par région et par utilisation, il n'est donc pas possible de prédire les coûts exacts de votre utilisation. Cependant, vous pouvez essayer la calculatrice de tarification Azure pour les ressources ci-dessous:
Pour réduire les coûts, vous pouvez passer aux SKU gratuits pour divers services, mais ces SKU ont des limitations. Voir ce guide sur le déploiement avec un minimum de coûts pour plus de détails.
azd down .
Vous avez quelques options pour configurer ce projet. Le moyen le plus simple de commencer est GitHub Codespaces, car il configurera tous les outils pour vous, mais vous pouvez également le configurer localement si vous le souhaitez.
Vous pouvez exécuter ce repo pratiquement en utilisant des codes GitHub, qui ouvriront un code VS basé sur le Web dans votre navigateur:
Une option connexe est des conteneurs distants de code vs, qui ouvriront le projet dans votre code local vs à l'aide de l'extension de détenteurs Dev:
Installez les conditions préalables suivantes:
Développeur Azure CLI
.Net 8
Git
PowerShell 7+ (PWSH) - pour les utilisateurs de Windows uniquement.
IMPORTANT : Assurez-vous que vous pouvez exécuter
pwsh.exeà partir d'une commande PowerShell. Si cela échoue, vous devez probablement mettre à niveau PowerShell.
Docker
IMPORTANT : Assurez-vous que Docker s'exécute avant d'exécuter toutes les commandes d'approvisionnement / déploiement
azd.
Ensuite, exécutez les commandes suivantes pour obtenir le projet sur votre environnement local:
azd auth loginazd init -t azure-search-openai-demo-csharpazd env new azure-search-openai-demo-csharpStream en direct: déploiement à partir de zéro dans les codepaces en direct Stream en direct: déploiement à partir de zéro dans Windows 11
IMPORTANT : Assurez-vous que Docker s'exécute avant d'exécuter toutes les commandes d'approvisionnement / déploiement
azd.
Exécutez la commande suivante, si vous n'avez pas de services Azure préexistants et que vous souhaitez commencer à partir d'un nouveau déploiement.
Exécutez azd up - Cela provisionnera Azure Resources et déploiera cet échantillon sur ces ressources, y compris la création de l'index de recherche basé sur les fichiers trouvés dans le dossier ./data .
Remarque : Cette application utilise le modèle
gpt-4o-mini. Lors du choix de la région à déployer, assurez-vous qu'ils sont disponibles dans cette région (c'est-à-dire Eastus). Pour plus d'informations, consultez la documentation du service Azure Openai.
Une fois que l'application a été déployée avec succès, vous verrez une URL imprimée à la console. Cliquez sur cette URL pour interagir avec l'application dans votre navigateur.
Cela ressemblera à ce qui suit:
[! Remarque]: Il peut prendre quelques minutes pour que l'application soit entièrement déployée. Une fois l'application déployée, il faudra également quelques minutes pour traiter les documents à ajouter dans la base de données vectorielle.
Si vous avez des ressources existantes dans Azure que vous souhaitez utiliser, vous pouvez configurer azd pour les utiliser en définissant les variables d'environnement azd suivantes:
azd env set AZURE_OPENAI_SERVICE {Name of existing OpenAI service}azd env set AZURE_OPENAI_RESOURCE_GROUP {Name of existing resource group that OpenAI service is provisioned to}azd env set AZURE_OPENAI_CHATGPT_DEPLOYMENT {Name of existing ChatGPT deployment} . Uniquement nécessaire si votre déploiement de chatppt n'est pas le «chat» par défaut.azd env set AZURE_OPENAI_EMBEDDING_DEPLOYMENT {Name of existing embedding model deployment} . Seule nécessaire si votre déploiement de modèle d'intégration n'est pas l' embedding par défaut.azd up Note
Vous pouvez également utiliser des comptes de recherche et de stockage existants. Voir ./infra/main.parameters.json pour la liste des variables d'environnement à passer à azd env set pour configurer ces ressources existantes.
Important
Assurez-vous que Docker s'exécute avant d'exécuter toutes les commandes d'approvisionnement / déploiement azd .
azd up Note
Assurez-vous que vous disposez de fichiers BICEP pris en charge AZD dans votre référentiel et ajoutez un fichier de workflow GitHub Actions initial qui peut être déclenché manuellement (pour le déploiement initial) ou sur le changement de code (redéployer automatiquement avec les derniers modifications) pour rendre votre référentiel compatible avec les espaces d'application, vous devez apporter des modifications à votre groupe de biceps principal et à la principale fichier de paramètres appropriés.
"resourceGroupName" : {
"value" : " ${AZURE_RESOURCE_GROUP} "
} "tags" : {
"value" : " ${AZURE_TAGS} "
} param resourceGroupName string = ''
param tags string = '' var baseTags = { 'azd-env-name' : environmentName }
var updatedTags = union ( empty ( tags ) ? {} : base64ToJson ( tags ), baseTags )
Make sure to use " updatedTags " when assigning " tags " to resource group created in your bicep file and update the other resources to use " baseTags " instead of " tags ". For example -
``` json
resource rg 'Microsoft.Resources/resourceGroups@2021-04-01' = {
name : ! empty ( resourceGroupName ) ? resourceGroupName : '${ abbrs . resourcesResourceGroups }${ environmentName }'
location : location
tags : updatedTags
}Important
Assurez-vous que Docker s'exécute avant d'exécuter toutes les commandes d'approvisionnement / déploiement azd .
Exécuter azd auth login
Après les déploiement de l'application, définissez la variable d'environnement AZURE_KEY_VAULT_ENDPOINT . Vous pouvez trouver la valeur dans le fichier .azure / your-environment-name / .env ou le portail Azure.
Exécutez la commande .net CLI suivante pour démarrer le serveur API minimal ASP.NET Core (Host Client):
dotnet run --project ./app/backend/MinimalApi.csproj --urls=http://localhost:7181/
Accédez à http: // localhost: 7181 et testez l'application.
Cet échantillon comprend un client Maui .NET, emballant l'expérience en tant qu'application qui peut s'exécuter sur un bureau Windows / MacOS ou sur des appareils Android et iOS. Le client Maui ici est implémenté à l'aide de Blazor Hybrid, ce qui le permet de partager la plupart du code avec le site Web Frontend.
Ouvrir l'application / app-mai.sln pour ouvrir la solution qui inclut le client Maui
EDIT APP / MAUI-BLAZOR / MAUIPROGRAM.CS , MISE À JOUR client.BaseAddress AVEC L'URL pour le backend.
S'il s'exécute en Azure, utilisez l'URL pour le backend de service à partir des étapes ci-dessus. Si vous exécutez localement, utilisez http: // localhost: 7181.
Définissez Mauiblazor comme projet de démarrage et exécutez l'application
Exécutez ce qui suit si vous souhaitez donner à quelqu'un d'autre un accès à l'environnement déployé et existant.
azd init -t azure-search-openai-demo-csharpazd env refresh -e {environment name} - Notez qu'ils auront besoin du nom d'environnement AZD, de l'ID d'abonnement et de l'emplacement pour exécuter cette commande - vous pouvez trouver ces valeurs dans votre fichier ./azure/{env name}/.env . Cela remplira le fichier .env de leur environnement AZD avec tous les paramètres nécessaires pour exécuter l'application localement.pwsh ./scripts/roles.ps1 - Cela affectera tous les rôles nécessaires à l'utilisateur afin qu'ils puissent exécuter l'application localement. S'ils n'ont pas l'autorisation nécessaire pour créer des rôles dans l'abonnement, vous devrez peut-être exécuter ce script pour eux. Assurez-vous simplement de définir la variable d'environnement AZURE_PRINCIPAL_ID dans le fichier AZD .env ou dans le shell actif sur leur ID Azure, qu'ils peuvent obtenir avec az account show . Faire couler azd down
azd . L'URL est imprimée lorsque azd se termine (en tant que «point de terminaison»), ou vous pouvez le trouver dans le portail Azure.Une fois dans l'application Web:
Pour activer les informations d'application et le traçage de chaque demande, ainsi que la journalisation des erreurs, définissez la variable AZURE_USE_APPLICATION_INSIGHTS à TRUE avant d'exécuter azd up
azd env set AZURE_USE_APPLICATION_INSIGHTS trueazd upPour voir les données de performance, accédez à la ressource de l'application Insights dans votre groupe de ressources, cliquez sur la lame "Enquêter -> Performance" et accédez à toute demande HTTP pour voir les données de synchronisation. Pour inspecter les performances des demandes de chat, utilisez le bouton "Derf in Samples" pour voir des traces de bout en bout de tous les appels d'API effectués pour toute demande de chat:
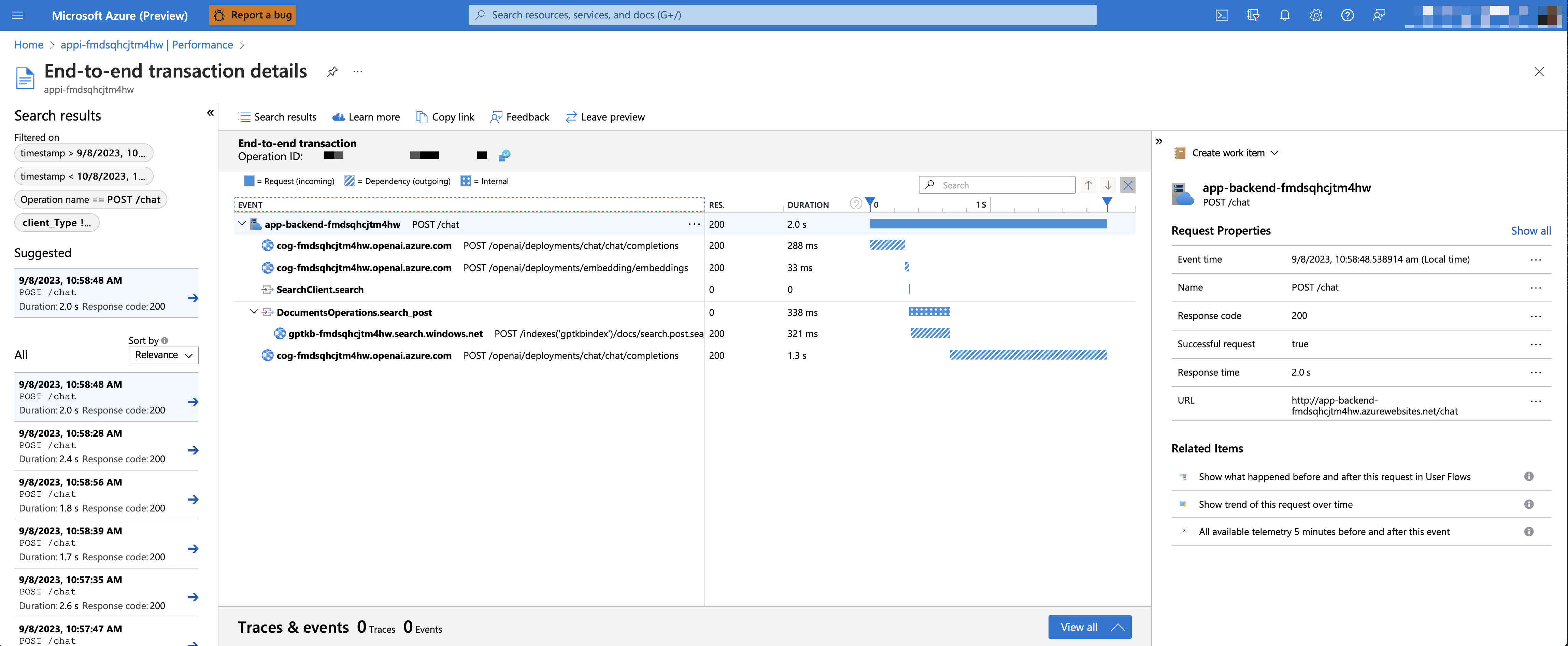
Pour voir des exceptions et des erreurs de serveur, accédez à la lame "Investigate -> défaillance" et utilisez les outils de filtrage pour localiser une exception spécifique. Vous pouvez voir des traces de pile Python sur le côté droit.
Par défaut, l'application Azure Container déployée n'aura aucune restriction d'authentification ou d'accès activée, ce qui signifie que toute personne ayant un accès réseau routable à l'application Container peut discuter avec vos données indexées. Vous pouvez nécessiter une authentification à votre Azure Active Directory en suivant le didacticiel Add Container App Authentication et le définir par rapport à l'application Container déployée.
Pour limiter ensuite l'accès à un ensemble spécifique d'utilisateurs ou de groupes, vous pouvez suivre les étapes de restreindre votre application Azure AD à un ensemble d'utilisateurs en modifiant "l'attribution requise?" Option sous l'application Enterprise, puis attribuer des utilisateurs / groupes à accès. Les utilisateurs non accordés à l'accès explicite recevront le message d'erreur -aadsts50105: votre administrateur a configuré l'application <app_name> pour bloquer les utilisateurs à moins qu'ils ne soient spécifiquement accordés («attribué») accès à l'application.
Avec GPT-4o-mini , il est possible de prendre en charge une génération augmentée enrichmentée en fournissant à la fois du texte et de l'image en tant que contenu source. Pour activer le support Vision, vous devez activer USE_VISION et utiliser le modèle GPT-4o ou GPT-4o-mini lors de la provisioning.
Note
Vous devrez réindexer le matériel de support et redémarrer l'application après l'activation de la prise en charge GPT-4O si vous avez déjà déployé l'application auparavant. En effet, l'activation de la prise en charge GPT-4O nécessite de nouveaux champs à ajouter à l'index de recherche.
Pour activer la prise en charge GPT-4V avec Azure Openai Service, exécutez les commandes suivantes:
azd env set USE_VISION true
azd env set USE_AOAI true
azd env set AZURE_OPENAI_CHATGPT_MODEL_NAME gpt-4o-mini
azd env set AZURE_OPENAI_RESOURCE_LOCATION eastus # Please check the gpt model availability for more details.
azd upPour activer la prise en charge de la vision avec OpenAI, exécutez les commandes suivantes:
azd env set USE_VISION true
azd env set USE_AOAI false
azd env set OPENAI_CHATGPT_DEPLOYMENT gpt-4o
azd upPour nettoyer les ressources déployées précédemment, exécutez la commande suivante:
azd down --purge
azd env set AZD_PREPDOCS_RAN false # This is to ensure that the documents are re-indexed with the new fields. Outre les conseils ci-dessous, vous pouvez trouver une documentation approfondie dans le dossier DOCS.
Cet échantillon est conçu pour être un point de départ pour votre propre application de production, mais vous devez faire un examen approfondi de la sécurité et des performances avant de se déployer en production. Voici quelques choses à considérer:
Capacité OpenAI : le TPM par défaut (jetons par minute) est défini sur 30k. Cela équivaut à environ 30 conversations par minute (en supposant 1k par message / réponse utilisateur). Vous pouvez augmenter la capacité en modifiant les paramètres de chatGptDeploymentCapacity et embeddingDeploymentCapacity dans infra/main.bicep à la capacité maximale de votre compte. Vous pouvez également afficher l'onglet quotas dans Azure Openai Studio pour comprendre la capacité que vous avez.
Azure Storage : le compte de stockage par défaut utilise le Standard_LRS SKU. Pour améliorer votre résilience, nous vous recommandons d'utiliser Standard_ZRS pour les déploiements de production, que vous pouvez spécifier à l'aide de la propriété sku sous le module storage dans infra/main.bicep .
Azure AI Search : Si vous voyez des erreurs sur la capacité de service de recherche dépassée, vous pouvez trouver utile d'augmenter le nombre de répliques en modifiant replicaCount dans infra/core/search/search-services.bicep
Azure Container Apps : Par défaut, cette application déploie des conteneurs avec 0,5 cœurs de CPU et 1 Go de mémoire. Les répliques minimales sont 1 et maximum 10. Pour cette application, vous pouvez définir des valeurs telles que containerCpuCoreCount , containerMaxReplicas , containerMemory , containerMinReplicas dans le fichier infra/core/host/container-app.bicep pour répondre à vos besoins. Vous pouvez utiliser des règles de mise à l'échelle automatique ou des règles de mise à l'échelle planifiées et augmenter le maximum / minimum en fonction de la charge.
Authentification : par défaut, l'application déployée est accessible au public. Nous recommandons de restreindre l'accès aux utilisateurs authentifiés. Voir Activation de l'authentification ci-dessus pour activer l'authentification.
Réseautage : Nous recommandons le déploiement dans un réseau virtuel. Si l'application est uniquement pour une utilisation interne d'entreprise, utilisez une zone DNS privée. Pensez également à utiliser Azure API Management (APIM) pour les pare-feu et autres formes de protection. Pour plus de détails, lisez l'architecture de référence de la zone d'atterrissage Azure Openai.
LoadTestting : nous vous recommandons d'exécuter un test de charge pour votre nombre attendu d'utilisateurs.
Azure.AI.OpenAI Nuget PackageNote
Les documents PDF utilisés dans cette démo contiennent des informations générées à l'aide d'un modèle de langue (service Azure OpenAI). Les informations contenues dans ces documents sont uniquement à des fins de démonstration et ne reflètent pas les opinions ou les croyances de Microsoft. Microsoft ne fait aucune représentation ou garantie d'aucune sorte, expresse ou implicite, sur l'exhaustivité, l'exactitude, la fiabilité, la pertinence ou la disponibilité en ce qui concerne les informations contenues dans ce document. Tous droits réservés à Microsoft.
Question : Pourquoi devons-nous diviser les PDF en morceaux lorsque la recherche Azure AI prend en charge la recherche de grands documents?
Réponse : Le groupe nous permet de limiter la quantité d'informations que nous envoyons à OpenAI en raison de limites de jetons. En cassant le contenu, il nous permet de trouver facilement des morceaux de texte potentiels que nous pouvons injecter dans OpenAI. La méthode de section que nous utilisons exploite une fenêtre de texte coulissante telle que les phrases qui terminent un morceau commencera la suivante. Cela nous permet de réduire les chances de perdre le contexte du texte.


