webui ChatTTS
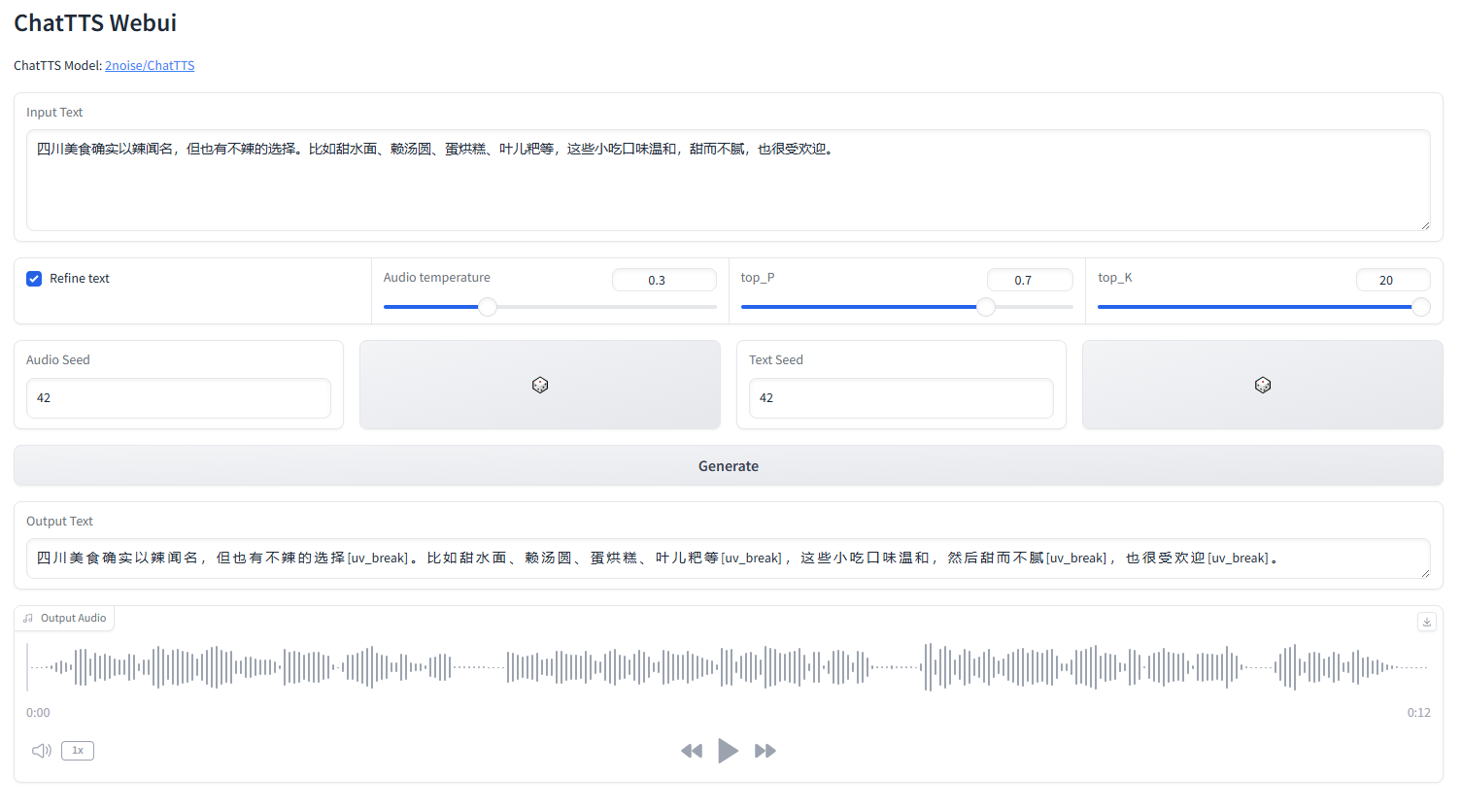
mulai webui.py
python webui.py
python webui.py --server_port=8080conda create -n chattts python=3.9
conda activate chattts
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install omegaconf vocos transformers vector-quantize-pytorchBahasa Inggris |中文简体
ChatTTS adalah model text-to-speech yang dirancang khusus untuk skenario dialog seperti asisten LLM. Ini mendukung bahasa Inggris dan Cina. Model kami dilatih dengan 100.000+ jam yang terdiri dari bahasa Mandarin dan Inggris. Versi sumber terbuka di HuggingFace adalah model terlatih 40.000 jam tanpa SFT.
Untuk pertanyaan formal tentang model dan peta jalan, silakan hubungi kami di [email protected]. Anda dapat bergabung dengan grup QQ kami: 808364215 untuk berdiskusi. Menambahkan masalah github selalu disambut baik.
Untuk penjelasan detail modelnya, Anda bisa merujuk ke video di Bilibili
Repo ini hanya untuk tujuan akademis. Hal ini dimaksudkan untuk penggunaan pendidikan dan penelitian, dan tidak boleh digunakan untuk tujuan komersial atau hukum apa pun. Penulis tidak menjamin keakuratan, kelengkapan, atau keandalan informasi. Informasi dan data yang digunakan dalam repo ini, adalah untuk tujuan akademis dan penelitian saja. Data diperoleh dari sumber yang tersedia untuk umum, dan penulis tidak mengklaim kepemilikan atau hak cipta apa pun atas data tersebut.
ChatTTS adalah sistem text-to-speech yang kuat. Namun, sangat penting untuk memanfaatkan teknologi ini secara bertanggung jawab dan etis. Untuk membatasi penggunaan ChatTTS, kami menambahkan sedikit kebisingan frekuensi tinggi selama pelatihan model 40.000 jam, dan mengompresi kualitas audio sebanyak mungkin menggunakan format MP3, untuk mencegah pelaku jahat berpotensi menggunakannya untuk tindakan kriminal. tujuan. Pada saat yang sama, kami telah melatih model deteksi secara internal dan berencana menjadikannya sebagai sumber terbuka di masa mendatang.
import ChatTTS
from IPython . display import Audio
chat = ChatTTS . Chat ()
chat . load_models ()
texts = [ "<PUT YOUR TEXT HERE>" ,]
wavs = chat . infer ( texts , use_decoder = True )
Audio ( wavs [ 0 ], rate = 24_000 , autoplay = True ) ###################################
# Sample a speaker from Gaussian.
import torch
std , mean = torch . load ( 'ChatTTS/asset/spk_stat.pt' ). chunk ( 2 )
rand_spk = torch . randn ( 768 ) * std + mean
params_infer_code = {
'spk_emb' : rand_spk , # add sampled speaker
'temperature' : .3 , # using custom temperature
'top_P' : 0.7 , # top P decode
'top_K' : 20 , # top K decode
}
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = {
'prompt' : '[oral_2][laugh_0][break_6]'
}
wav = chat . infer ( "<PUT YOUR TEXT HERE>" , params_refine_text = params_refine_text , params_infer_code = params_infer_code )
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wav = chat . infer ( text , skip_refine_text = True , params_infer_code = params_infer_code ) inputs_en = """
chat T T S is a text to speech model designed for dialogue applications.
[uv_break]it supports mixed language input [uv_break]and offers multi speaker
capabilities with precise control over prosodic elements [laugh]like like
[uv_break]laughter[laugh], [uv_break]pauses, [uv_break]and intonation.
[uv_break]it delivers natural and expressive speech,[uv_break]so please
[uv_break] use the project responsibly at your own risk.[uv_break]
""" . replace ( ' n ' , '' ) # English is still experimental.
params_refine_text = {
'prompt' : '[oral_2][laugh_0][break_4]'
}
audio_array_cn = chat . infer ( inputs_cn , params_refine_text = params_refine_text )
audio_array_en = chat . infer ( inputs_en , params_refine_text = params_refine_text )Untuk klip audio berdurasi 30 detik, diperlukan setidaknya 4 GB memori GPU. Untuk GPU 4090D, ini dapat menghasilkan audio yang setara dengan sekitar 7 token semantik per detik. Faktor Real-Time (RTF) adalah sekitar 0,65.
Ini adalah masalah yang biasanya terjadi pada model autoregresif (untuk kulit kayu dan valle). Biasanya sulit untuk dihindari. Seseorang dapat mencoba beberapa sampel untuk menemukan hasil yang sesuai.
Dalam model yang dirilis saat ini, satu-satunya unit kontrol level token adalah [laugh], [uv_break], dan [lbreak]. Di versi mendatang, kami mungkin menggunakan model sumber terbuka dengan kemampuan kontrol emosi tambahan.


