Kerangka kerja untuk melatih model landasan multimoda apa pun.
Dapat diskalakan. Bersumber terbuka. Di puluhan modalitas dan tugas.
EPFL-Apel
Website | BibTeX | ? Demo
Implementasi resmi dan model terlatih untuk:
4M: Pemodelan Bertopeng Multimodal Besar-besaran , NeurIPS 2023 (Sorotan)
David Mizrahi*, Roman Bachmann*, Oğuzhan Fatih Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, Amir Zamir
4M-21: Model Visi Apa Pun untuk Puluhan Tugas dan Modalitas , NeurIPS 2024
Roman Bachmann*, Oğuzhan Fatih Kar*, David Mizrahi*, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir
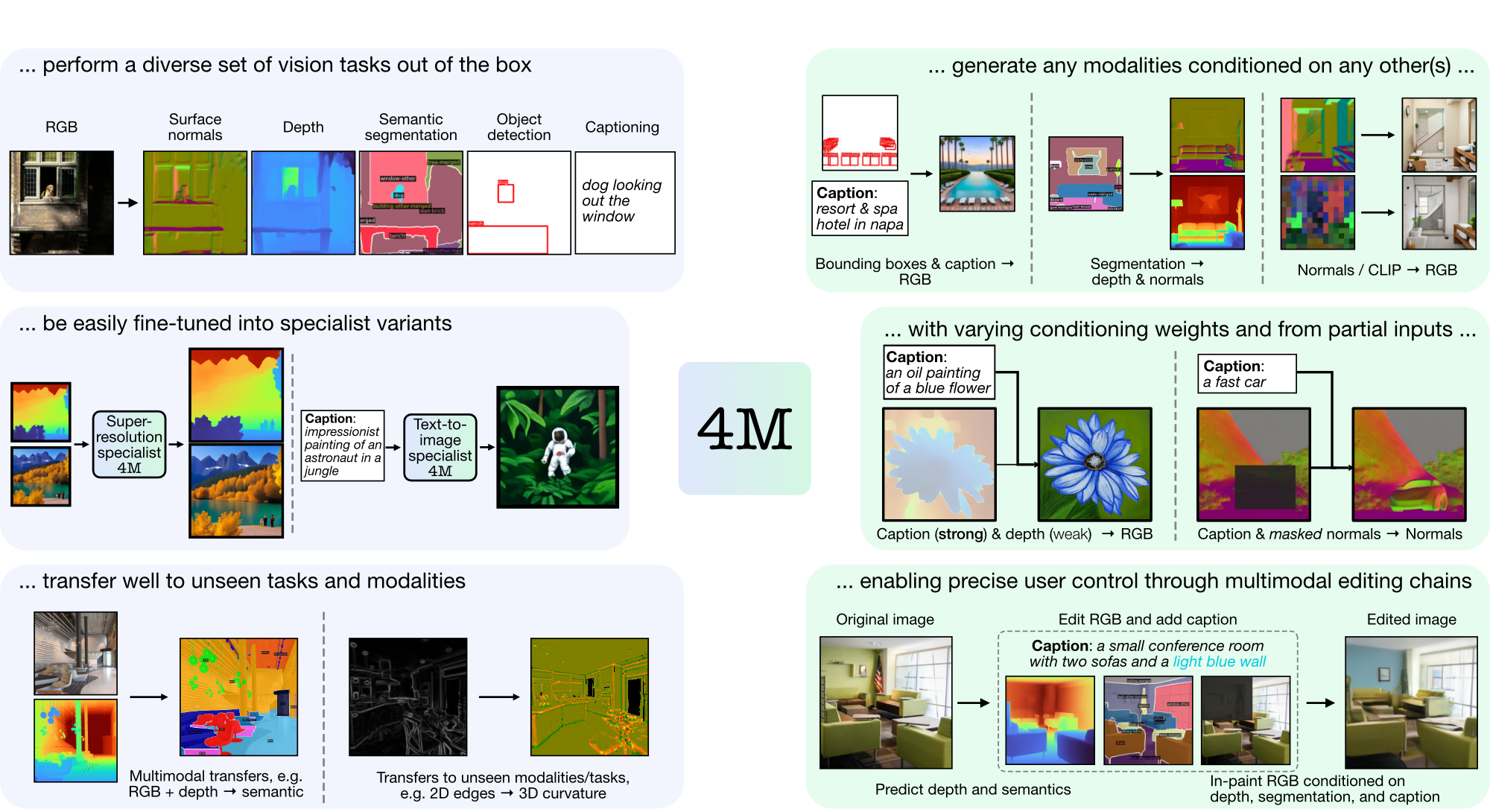
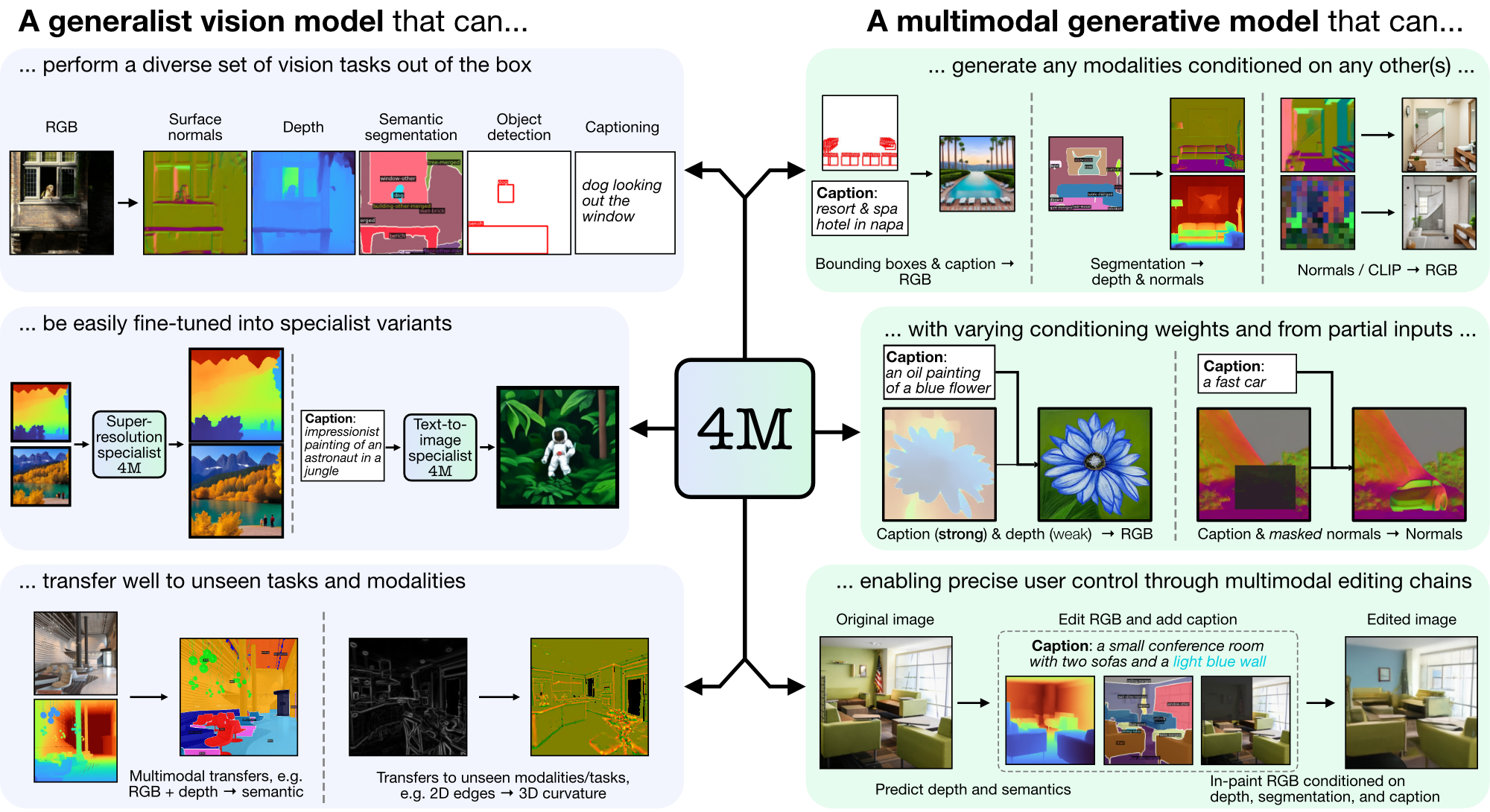
4M adalah kerangka kerja untuk melatih model dasar "any-to-any", menggunakan tokenisasi dan masking untuk menskalakan berbagai modalitas. Model yang dilatih menggunakan 4M dapat melakukan berbagai tugas penglihatan, mentransfer dengan baik tugas dan modalitas yang tidak terlihat, dan merupakan model generatif multimodal yang fleksibel dan dapat dikendalikan. Kami merilis kode dan model untuk "4M: Massively Multimodal Masked Modeling" (di sini dilambangkan dengan 4M-7), serta "4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities" (di sini dilambangkan dengan 4M -21).
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
Jika CUDA tidak tersedia, pertimbangkan untuk menginstal ulang PyTorch dengan mengikuti petunjuk instalasi resmi. Demikian pula, jika Anda ingin menginstal xFormers (opsional, untuk tokenizer yang lebih cepat), ikuti README mereka untuk memastikan bahwa versi CUDA sudah benar.
Kami menyediakan demo wrapper untuk segera mulai menggunakan model 4M untuk tugas pembuatan RGB-to-all atau {caption,bounding box}-to-all. Misalnya, untuk menghasilkan semua modalitas dari masukan RGB tertentu, panggil:
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )Anda akan melihat keluaran seperti berikut:


Untuk melakukan pembuatan caption-to-all, Anda dapat mengganti input sampler dengan: preds = sampler({'caption': 'A lake house with a boat in front [S_1]'}) . Untuk daftar model 4M yang tersedia, silakan lihat kebun binatang model di bawah, dan lihat README_GENERATION.md untuk petunjuk lebih lanjut tentang pembuatannya.
Lihat README_DATA.md untuk petunjuk tentang cara menyiapkan kumpulan data multimodal yang selaras.
Lihat README_TOKENIZATION.md untuk instruksi tentang cara melatih tokenizer khusus modalitas.
Lihat README_TRAINING.md untuk instruksi tentang cara melatih model 4M.
Lihat README_GENERATION.md untuk instruksi tentang cara menggunakan model 4M untuk inferensi/generasi. Kami juga menyediakan notebook generasi yang berisi contoh untuk inferensi 4M, yang secara khusus melakukan pembuatan gambar bersyarat dan tugas visi umum (yaitu RGB-to-All).
Kami menyediakan pos pemeriksaan 4M dan tokenizer sebagai safetensor, dan juga menawarkan kemudahan pemuatan melalui Hugging Face Hub.
| Model | # Mod. | Kumpulan data | #Param | Konfigurasi | beban |
|---|---|---|---|---|---|
| 4M-B | 7 | CC12M | 198M | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4M-B | 7 | COYO700M | 198M | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4M-B | 21 | CC12M+COYO700M+C4 | 198M | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4ML | 7 | CC12M | 705M | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4ML | 7 | COYO700M | 705M | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4ML | 21 | CC12M+COYO700M+C4 | 705M | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4M-XL | 7 | CC12M | 2.8B | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4M-XL | 7 | COYO700M | 2.8B | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4M-XL | 21 | CC12M+COYO700M+C4 | 2.8B | Konfigurasi | Pos Pemeriksaan / HF Hub |
Untuk memuat model dari Hugging Face Hub:
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )Untuk memuat pos pemeriksaan secara manual, pertama-tama unduh file safetensor dari tautan di atas dan hubungi:
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )Model ini diinisialisasi dengan model standar 4M-7 CC12M, namun pelatihan dilanjutkan dengan campuran modalitas yang sangat bias terhadap input teks. Mereka masih mampu melakukan semua tugas lainnya, namun berkinerja lebih baik dalam pembuatan teks-ke-gambar dibandingkan dengan model yang tidak disempurnakan.
| Model | # Mod. | Kumpulan data | #Param | Konfigurasi | beban |
|---|---|---|---|---|---|
| 4M-T2I-B | 7 | CC12M | 198M | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4M-T2I-L | 7 | CC12M | 705M | Konfigurasi | Pos Pemeriksaan / HF Hub |
| 4M-T2I-XL | 7 | CC12M | 2.8B | Konfigurasi | Pos Pemeriksaan / HF Hub |
Untuk memuat model dari Hugging Face Hub:
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )Memuat secara manual dari pos pemeriksaan dilakukan dengan cara yang sama seperti di atas untuk model dasar 4M.
| Model | # Mod. | Kumpulan data | #Param | Konfigurasi | beban |
|---|---|---|---|---|---|
| 4M-SR-L | 7 | CC12M | 198M | Konfigurasi | Pos Pemeriksaan / HF Hub |
Untuk memuat model dari Hugging Face Hub:
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )Memuat secara manual dari pos pemeriksaan dilakukan dengan cara yang sama seperti di atas untuk model dasar 4M.
| Pengandaian | Resolusi | Jumlah token | Ukuran buku kode | Dekoder difusi | beban |
|---|---|---|---|---|---|
| RGB | 224-448 | 196-784 | 16k | ✓ | Pos Pemeriksaan / HF Hub |
| Kedalaman | 224-448 | 196-784 | 8k | ✓ | Pos Pemeriksaan / HF Hub |
| Normal | 224-448 | 196-784 | 8k | ✓ | Pos Pemeriksaan / HF Hub |
| Tepi (Canny, SAM) | 224-512 | 196-1024 | 8k | ✓ | Pos Pemeriksaan / HF Hub |
| Segmentasi semantik COCO | 224-448 | 196-784 | 4k | ✗ | Pos Pemeriksaan / HF Hub |
| KLIP-B/16 | 224-448 | 196-784 | 8k | ✗ | Pos Pemeriksaan / HF Hub |
| DINOv2-B/14 | 224-448 | 256-1024 | 8k | ✗ | Pos Pemeriksaan / HF Hub |
| DINOv2-B/14 (global) | 224 | 16 | 8k | ✗ | Pos Pemeriksaan / HF Hub |
| ImageBind-H/14 | 224-448 | 256-1024 | 8k | ✗ | Pos Pemeriksaan / HF Hub |
| ImageBind-H/14 (global) | 224 | 16 | 8k | ✗ | Pos Pemeriksaan / HF Hub |
| contoh SAM | - | 64 | 1k | ✗ | Pos Pemeriksaan / HF Hub |
| Pose Manusia 3D | - | 8 | 1k | ✗ | Pos Pemeriksaan / HF Hub |
Untuk memuat model dari Hugging Face Hub:
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )Untuk memuat pos pemeriksaan secara manual, pertama-tama unduh file safetensor dari tautan di atas dan hubungi:
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )Kode dalam repositori ini dirilis di bawah lisensi Apache 2.0 seperti yang ditemukan dalam file LICENSE.
Bobot model dalam repositori ini dirilis di bawah lisensi Kode Contoh seperti yang ditemukan dalam file LICENSE_WEIGHTS.
Jika Anda merasa repositori ini bermanfaat, mohon pertimbangkan untuk mengutip karya kami:
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


