system design 101
1.0.0
【 ?? YouTube | ? Buletin 】
Jelaskan sistem yang kompleks menggunakan visual dan istilah sederhana.
Baik Anda sedang mempersiapkan Wawancara Desain Sistem atau sekadar ingin memahami cara kerja sistem di balik permukaan, kami harap repositori ini dapat membantu Anda mencapai hal tersebut.
Gaya arsitektur menentukan bagaimana berbagai komponen antarmuka pemrograman aplikasi (API) berinteraksi satu sama lain. Hasilnya, mereka memastikan efisiensi, keandalan, dan kemudahan integrasi dengan sistem lain dengan menyediakan pendekatan standar dalam merancang dan membangun API. Berikut adalah gaya yang paling sering digunakan:
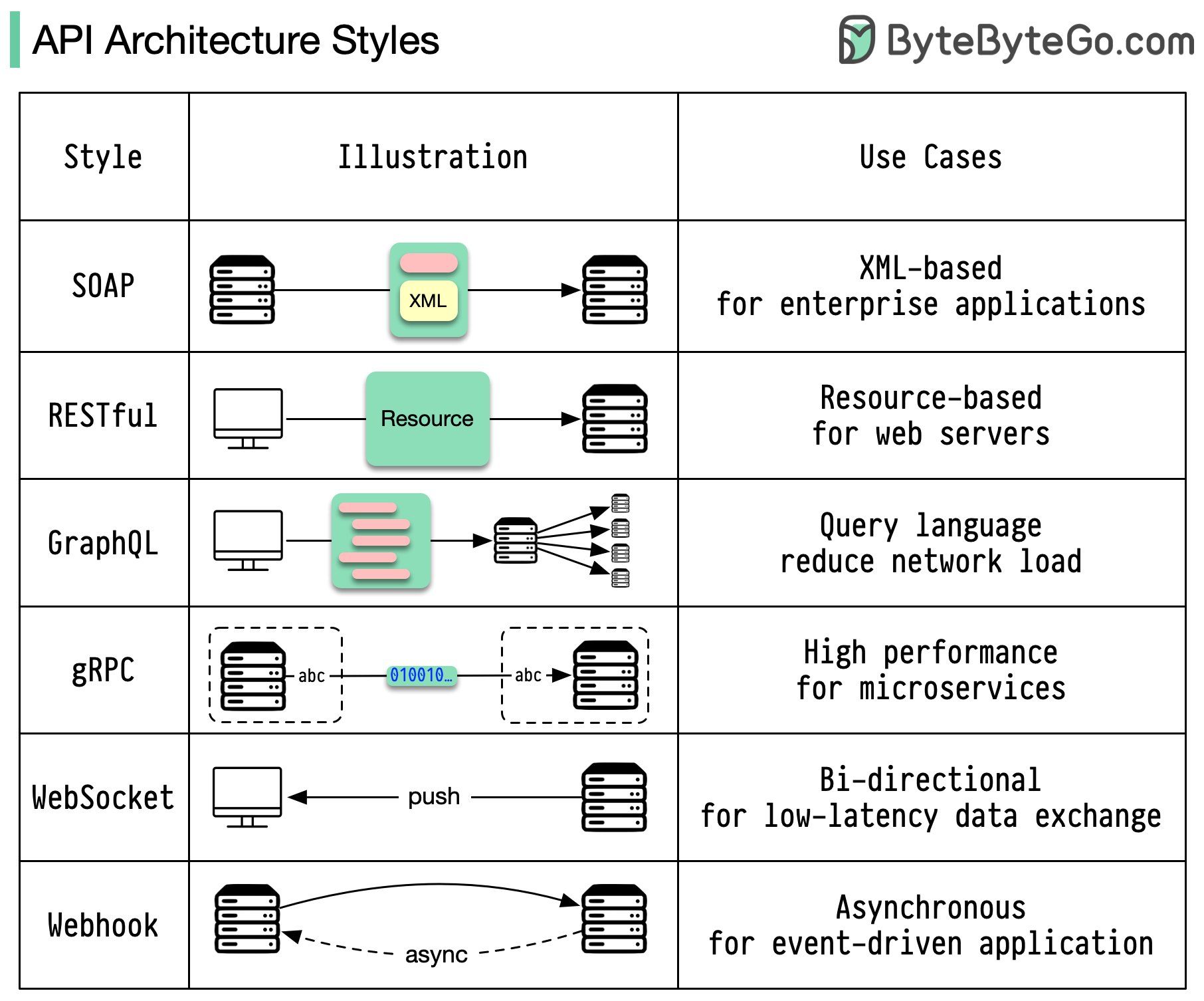
SABUN:
Matang, komprehensif, berbasis XML
Terbaik untuk aplikasi perusahaan
Tenang:
Metode HTTP yang populer dan mudah diterapkan
Ideal untuk layanan web
GrafikQL:
Bahasa kueri, meminta data tertentu
Mengurangi overhead jaringan, respons lebih cepat
gRPC:
Buffer Protokol yang modern dan berkinerja tinggi
Cocok untuk arsitektur layanan mikro
Soket Web:
Koneksi real-time, dua arah, dan persisten
Sempurna untuk pertukaran data latensi rendah
kait web:
Callback HTTP berbasis peristiwa, asinkron
Memberi tahu sistem ketika peristiwa terjadi
Dalam hal desain API, REST dan GraphQL masing-masing memiliki kekuatan dan kelemahannya masing-masing.
Diagram di bawah menunjukkan perbandingan cepat antara REST dan GraphQL.
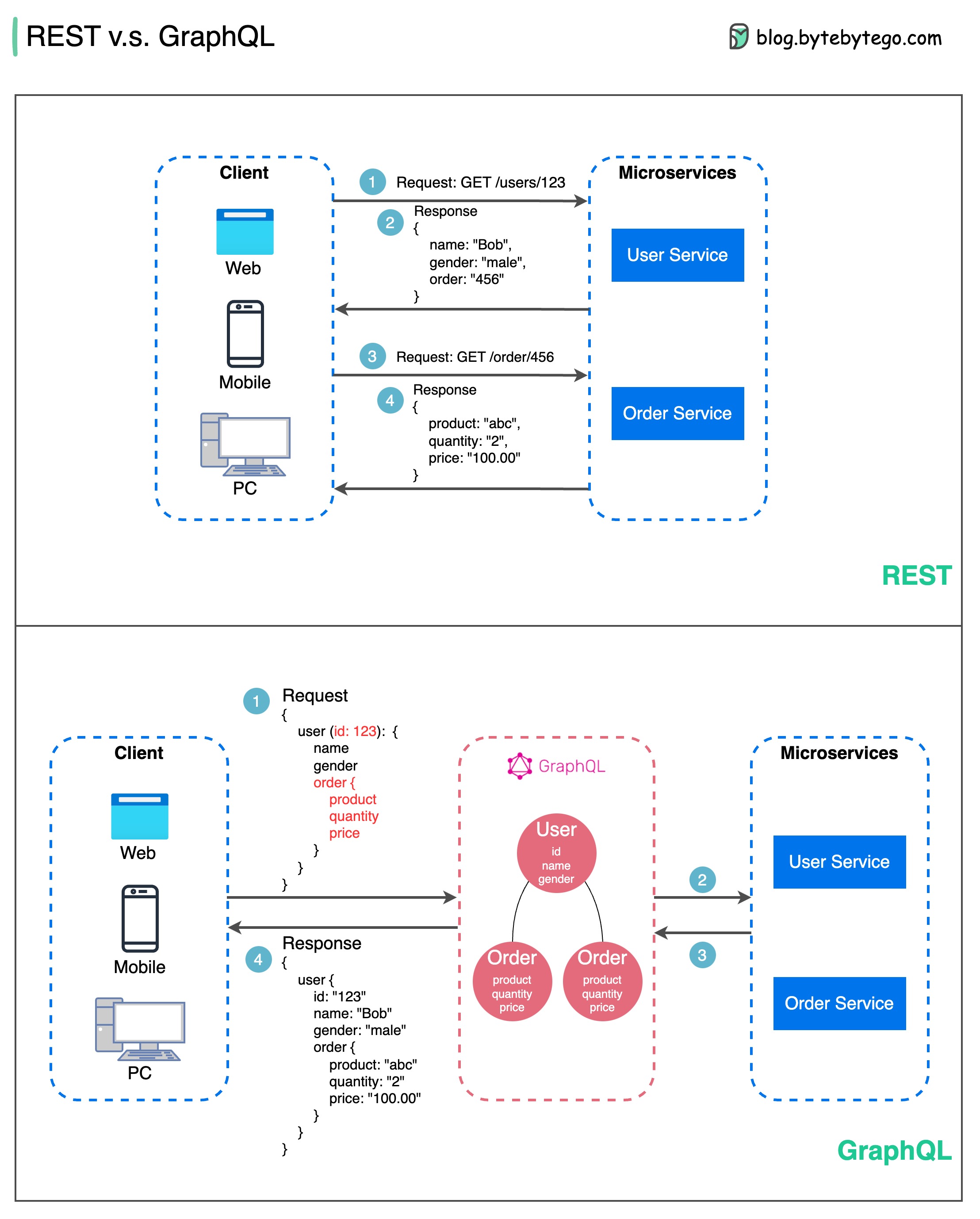
ISTIRAHAT
GrafikQL
Pilihan terbaik antara REST dan GraphQL bergantung pada persyaratan spesifik tim aplikasi dan pengembangan. GraphQL cocok untuk kebutuhan frontend yang kompleks atau sering berubah, sementara REST cocok untuk aplikasi yang lebih memilih kontrak sederhana dan konsisten.
Tidak ada pendekatan API yang merupakan solusi terbaik. Mengevaluasi persyaratan dan pengorbanan dengan cermat adalah penting untuk memilih gaya yang tepat. REST dan GraphQL merupakan opsi valid untuk mengekspos data dan mendukung aplikasi modern.
RPC (Panggilan Prosedur Jarak Jauh) disebut “ jarak jauh ” karena memungkinkan komunikasi antara layanan jarak jauh ketika layanan disebarkan ke server berbeda di bawah arsitektur layanan mikro. Dari sudut pandang pengguna, ini bertindak seperti pemanggilan fungsi lokal.
Diagram di bawah mengilustrasikan keseluruhan aliran data untuk gRPC .
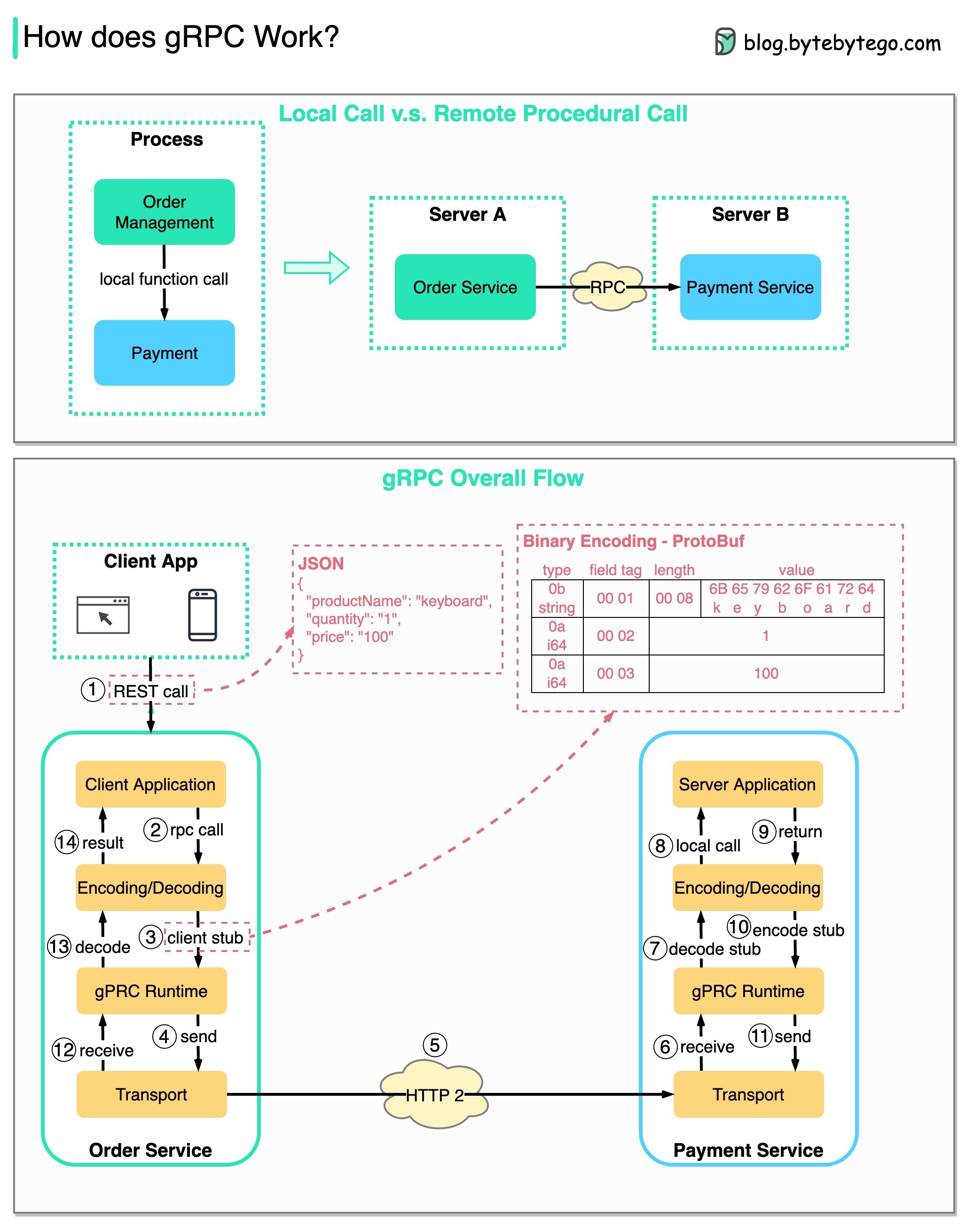
Langkah 1: Panggilan REST dilakukan dari klien. Badan permintaan biasanya dalam format JSON.
Langkah 2 - 4: Layanan pemesanan (klien gRPC) menerima panggilan REST, mengubahnya, dan melakukan panggilan RPC ke layanan pembayaran. gRPC mengkodekan stub klien ke dalam format biner dan mengirimkannya ke lapisan transport tingkat rendah.
Langkah 5: gRPC mengirimkan paket melalui jaringan melalui HTTP2. Karena pengkodean biner dan optimalisasi jaringan, gRPC dikatakan 5X lebih cepat dibandingkan JSON.
Langkah 6 - 8: Layanan pembayaran (server gRPC) menerima paket dari jaringan, mendekodekannya, dan memanggil aplikasi server.
Langkah 9 - 11: Hasilnya dikembalikan dari aplikasi server, dan dikodekan serta dikirim ke lapisan transport.
Langkah 12 - 14: Layanan pemesanan menerima paket, mendekodekannya, dan mengirimkan hasilnya ke aplikasi klien.
Diagram di bawah menunjukkan perbandingan antara polling dan Webhook.
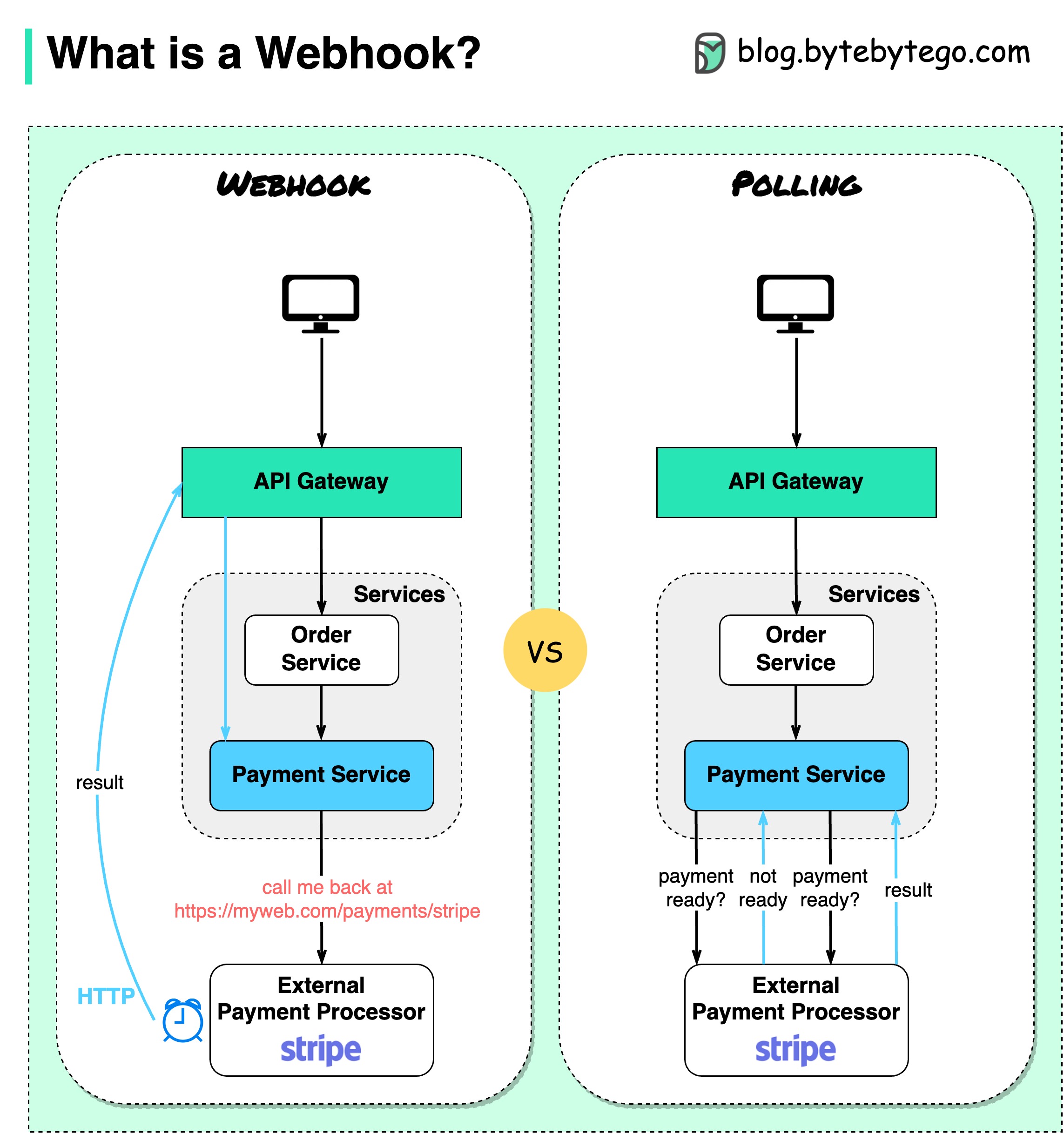
Asumsikan kita menjalankan situs web eCommerce. Klien mengirim pesanan ke layanan pemesanan melalui gateway API, yang masuk ke layanan pembayaran untuk transaksi pembayaran. Layanan pembayaran kemudian berbicara dengan penyedia layanan pembayaran eksternal (PSP) untuk menyelesaikan transaksi.
Ada dua cara untuk menangani komunikasi dengan PSP eksternal.
1. Jajak pendapat singkat
Setelah mengirimkan permintaan pembayaran ke PSP, layanan pembayaran terus menanyakan PSP tentang status pembayaran. Setelah beberapa putaran, akhirnya PSP kembali dengan statusnya.
Jajak pendapat singkat memiliki dua kelemahan:
2. kait web
Kita dapat mendaftarkan webhook dengan layanan eksternal. Artinya: hubungi saya kembali di URL tertentu ketika Anda memiliki pembaruan mengenai permintaan tersebut. Ketika PSP telah menyelesaikan pemrosesan, PSP akan meminta permintaan HTTP untuk memperbarui status pembayaran.
Dengan cara ini, paradigma pemrograman diubah, dan layanan pembayaran tidak perlu lagi membuang sumber daya untuk melakukan polling status pembayaran.
Bagaimana jika PSP tidak pernah menelepon kembali? Kami dapat mengatur pekerjaan tata graha untuk memeriksa status pembayaran setiap jam.
Webhook sering disebut sebagai API terbalik atau API push karena server mengirimkan permintaan HTTP ke klien. Kita perlu memperhatikan 3 hal saat menggunakan webhook:
Diagram di bawah menunjukkan 5 trik umum untuk meningkatkan kinerja API.
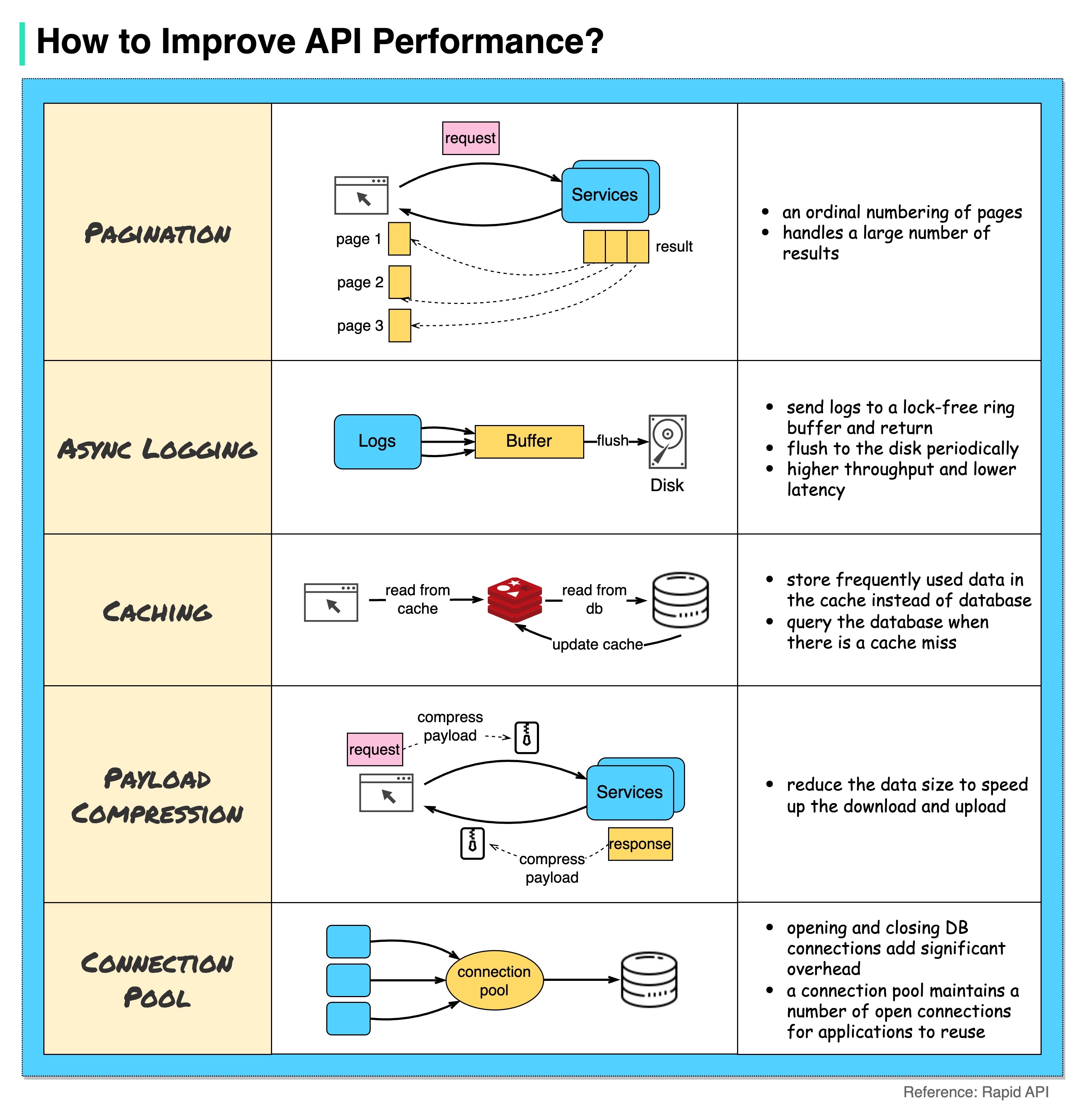
Paginasi
Ini adalah optimasi yang umum ketika ukuran hasilnya besar. Hasilnya dialirkan kembali ke klien untuk meningkatkan daya tanggap layanan.
Pencatatan Asinkron
Pencatatan log yang sinkron menangani disk untuk setiap panggilan dan dapat memperlambat sistem. Pencatatan log asinkron mengirimkan log ke buffer bebas kunci terlebih dahulu dan segera mengembalikannya. Log akan dipindahkan ke disk secara berkala. Hal ini secara signifikan mengurangi overhead I/O.
cache
Kita dapat menyimpan data yang sering diakses ke dalam cache. Klien dapat menanyakan cache terlebih dahulu daripada mengunjungi database secara langsung. Jika ada cache yang hilang, klien dapat melakukan query dari database. Cache seperti Redis menyimpan data di memori, sehingga akses datanya jauh lebih cepat dibandingkan database.
Kompresi Muatan
Permintaan dan tanggapan dapat dikompresi menggunakan gzip dll sehingga ukuran data yang dikirimkan jauh lebih kecil. Ini mempercepat pengunggahan dan pengunduhan.
Kumpulan Koneksi
Saat mengakses sumber daya, seringkali kita perlu memuat data dari database. Membuka koneksi penutupan db menambah overhead yang signifikan. Jadi kita harus terhubung ke db melalui kumpulan koneksi terbuka. Kumpulan koneksi bertanggung jawab untuk mengelola siklus hidup koneksi.
Masalah apa yang dipecahkan oleh setiap generasi HTTP?
Diagram di bawah mengilustrasikan fitur-fitur utama.
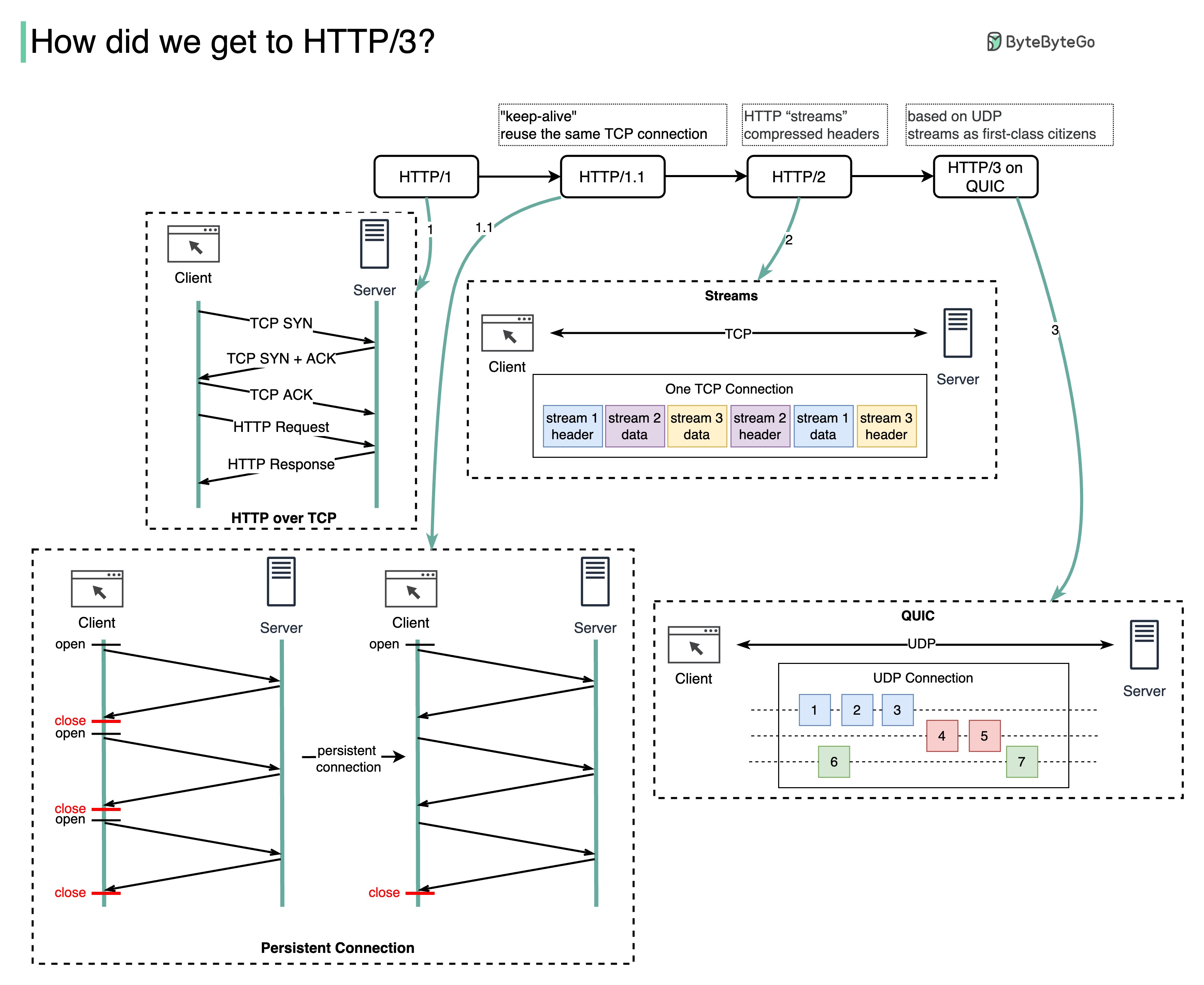
HTTP 1.0 diselesaikan dan didokumentasikan sepenuhnya pada tahun 1996. Setiap permintaan ke server yang sama memerlukan koneksi TCP terpisah.
HTTP 1.1 diterbitkan pada tahun 1997. Koneksi TCP dapat dibiarkan terbuka untuk digunakan kembali (koneksi persisten), namun tidak menyelesaikan masalah pemblokiran HOL (head-of-line).
Pemblokiran HOL - ketika jumlah permintaan paralel yang diizinkan di browser telah habis, permintaan berikutnya harus menunggu hingga permintaan sebelumnya selesai.
HTTP 2.0 diterbitkan pada tahun 2015. Ini mengatasi masalah HOL melalui multiplexing permintaan, yang menghilangkan pemblokiran HOL di lapisan aplikasi, namun HOL masih ada di lapisan transport (TCP).
Seperti yang Anda lihat pada diagram, HTTP 2.0 memperkenalkan konsep “stream” HTTP: sebuah abstraksi yang memungkinkan multiplexing pertukaran HTTP yang berbeda ke koneksi TCP yang sama. Setiap aliran tidak perlu dikirim secara berurutan.
Draf pertama HTTP 3.0 diterbitkan pada tahun 2020. Ini adalah usulan penerus HTTP 2.0. Ia menggunakan QUIC dan bukan TCP untuk protokol transport yang mendasarinya, sehingga menghilangkan pemblokiran HOL di lapisan transport.
QUIC didasarkan pada UDP. Ini memperkenalkan aliran sebagai warga kelas satu di lapisan transportasi. Aliran QUIC berbagi koneksi QUIC yang sama, sehingga tidak diperlukan jabat tangan tambahan dan permulaan yang lambat untuk membuat yang baru, namun aliran QUIC dikirimkan secara independen sehingga dalam banyak kasus kehilangan paket yang memengaruhi satu aliran tidak memengaruhi aliran lainnya.
Diagram di bawah mengilustrasikan perbandingan garis waktu API dan gaya API.
Seiring waktu, gaya arsitektur API yang berbeda dirilis. Masing-masing memiliki pola standarisasi pertukaran data tersendiri.
Anda dapat melihat kasus penggunaan setiap gaya dalam diagram.
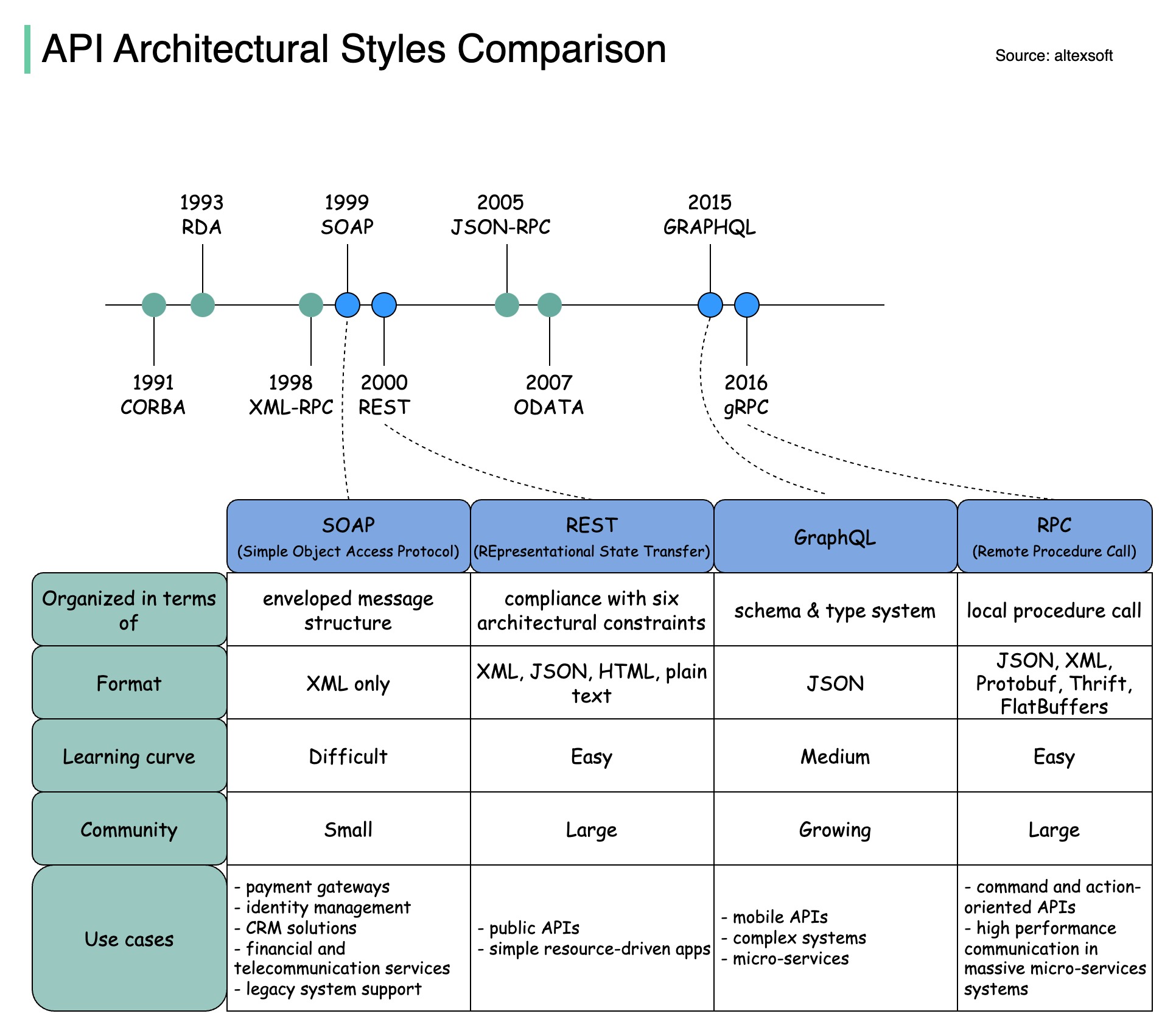
Diagram di bawah menunjukkan perbedaan antara pengembangan yang mengutamakan kode dan pengembangan yang mengutamakan API. Mengapa kami ingin mempertimbangkan desain API terlebih dahulu?
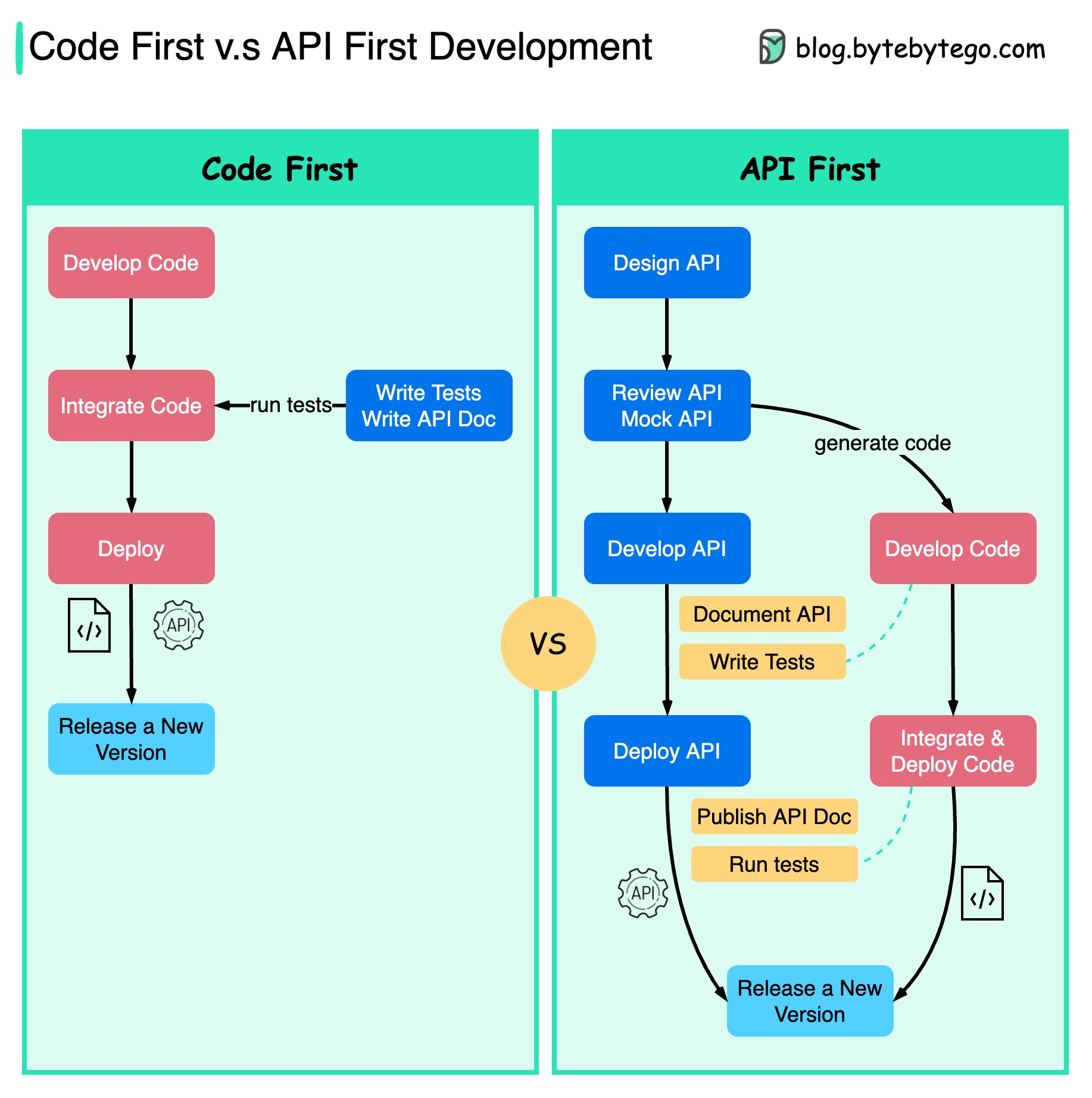
Lebih baik memikirkan kompleksitas sistem sebelum menulis kode dan dengan hati-hati menentukan batasan layanan.
Kita dapat meniru permintaan dan respons untuk memvalidasi desain API sebelum menulis kode.
Pengembang juga senang dengan proses ini karena mereka dapat fokus pada pengembangan fungsional daripada menegosiasikan perubahan mendadak.
Kemungkinan terjadinya kejutan menjelang akhir siklus hidup proyek berkurang.
Karena kami telah merancang API terlebih dahulu, pengujian dapat dirancang saat kode sedang dikembangkan. Di satu sisi, kami juga memiliki TDD (Test Driven Design) saat menggunakan pengembangan API pertama.
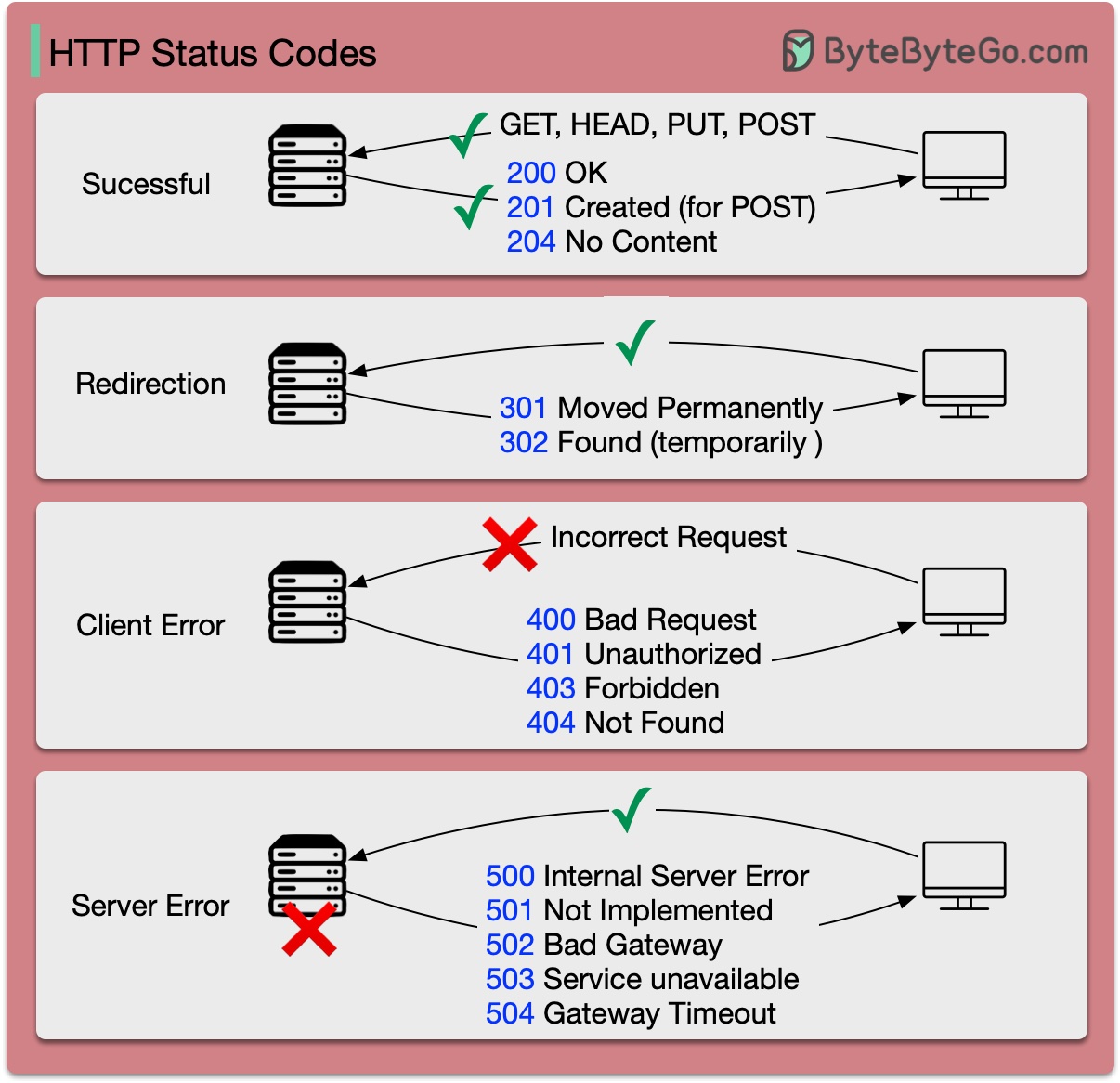
Kode respons untuk HTTP dibagi menjadi lima kategori:
Informasi (100-199) Sukses (200-299) Pengalihan (300-399) Kesalahan Klien (400-499) Kesalahan Server (500-599)
Diagram di bawah menunjukkan detailnya.
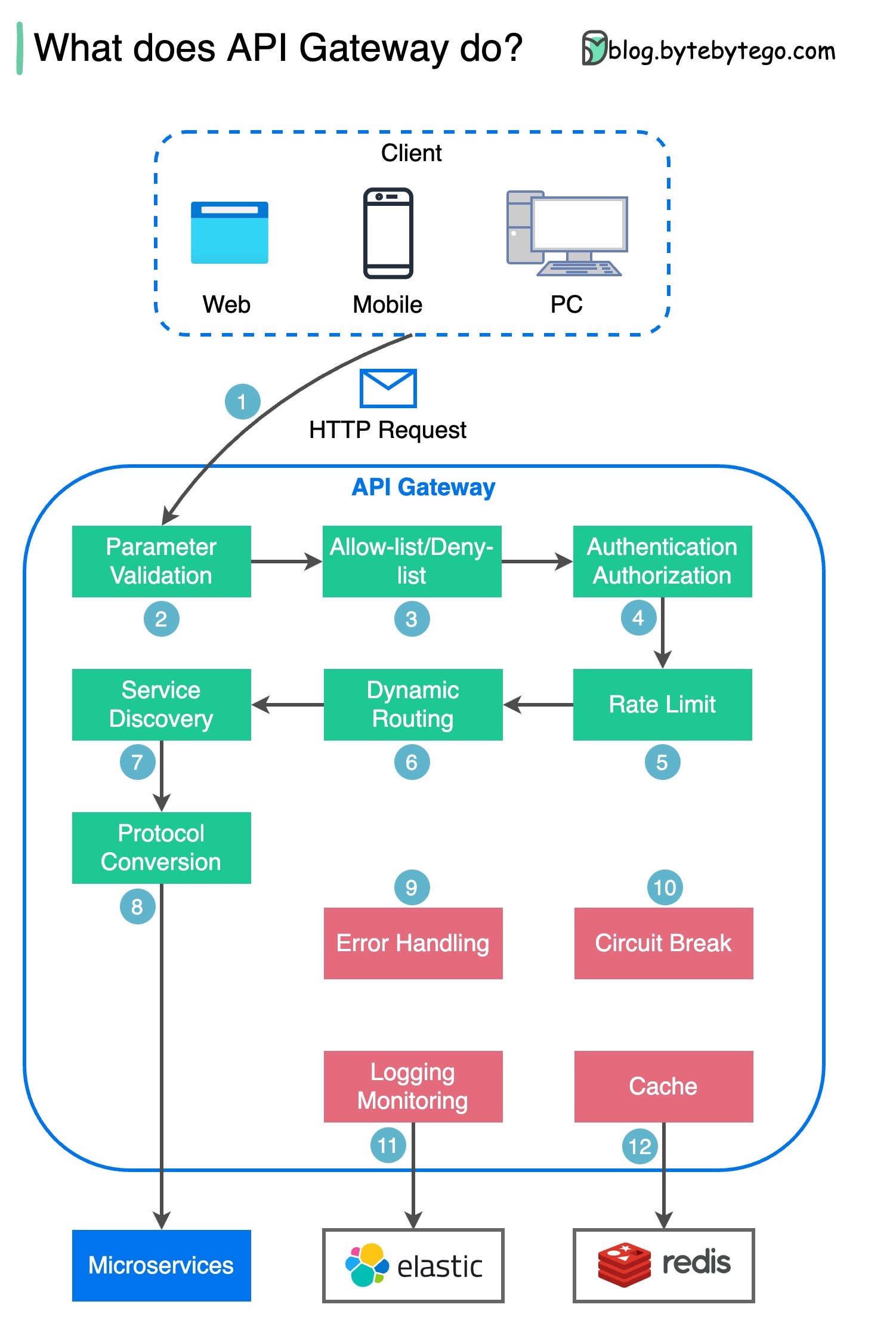
Langkah 1 - Klien mengirimkan permintaan HTTP ke gateway API.
Langkah 2 - Gateway API memilah dan memvalidasi atribut dalam permintaan HTTP.
Langkah 3 - Gateway API melakukan pemeriksaan daftar izin/daftar tolak.
Langkah 4 - Gateway API berkomunikasi dengan penyedia identitas untuk autentikasi dan otorisasi.
Langkah 5 - Aturan pembatasan tarif diterapkan pada permintaan. Jika melebihi batas maka permintaan ditolak.
Langkah 6 dan 7 - Kini setelah permintaan melewati pemeriksaan dasar, gateway API menemukan layanan yang relevan untuk dirutekan berdasarkan pencocokan jalur.
Langkah 8 - Gateway API mengubah permintaan menjadi protokol yang sesuai dan mengirimkannya ke layanan mikro backend.
Langkah 9-12: Gerbang API dapat menangani kesalahan dengan benar, dan menangani kesalahan jika kesalahan membutuhkan waktu lebih lama untuk pulih (kerusakan sirkuit). Itu juga dapat memanfaatkan tumpukan ELK (Elastic-Logstash-Kibana) untuk pencatatan dan pemantauan. Kami terkadang menyimpan data dalam cache di gateway API.
Diagram di bawah menunjukkan desain khas API dengan contoh keranjang belanja.
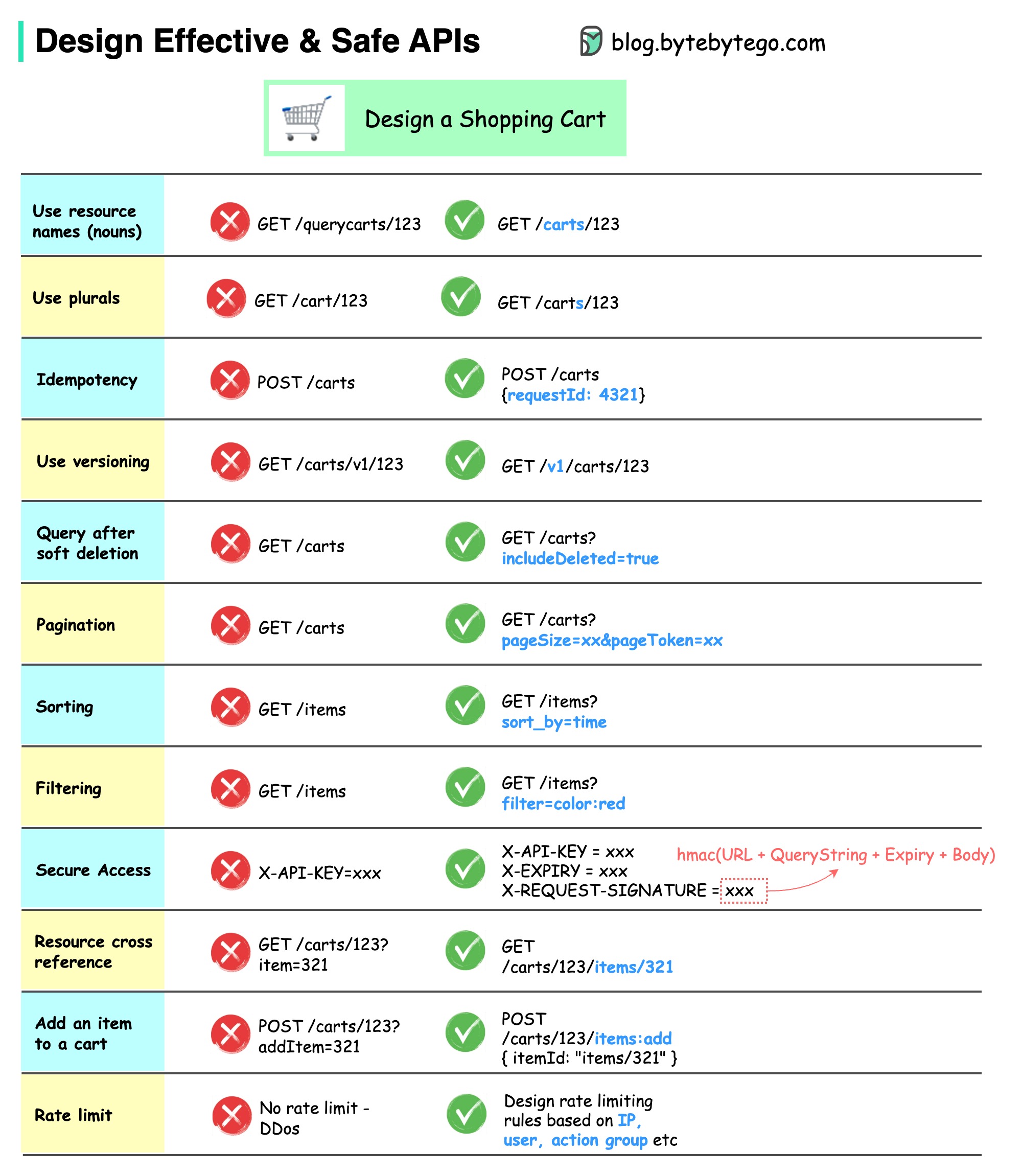
Perhatikan bahwa desain API bukan hanya desain jalur URL. Seringkali, kita perlu memilih nama sumber daya, pengidentifikasi, dan pola jalur yang tepat. Sama pentingnya untuk merancang bidang header HTTP yang tepat atau merancang aturan pembatasan kecepatan yang efektif dalam gateway API.
Bagaimana data dikirim melalui jaringan? Mengapa kita membutuhkan begitu banyak lapisan dalam model OSI?
Diagram di bawah menunjukkan bagaimana data dienkapsulasi dan dideenkapsulasi saat ditransmisikan melalui jaringan.
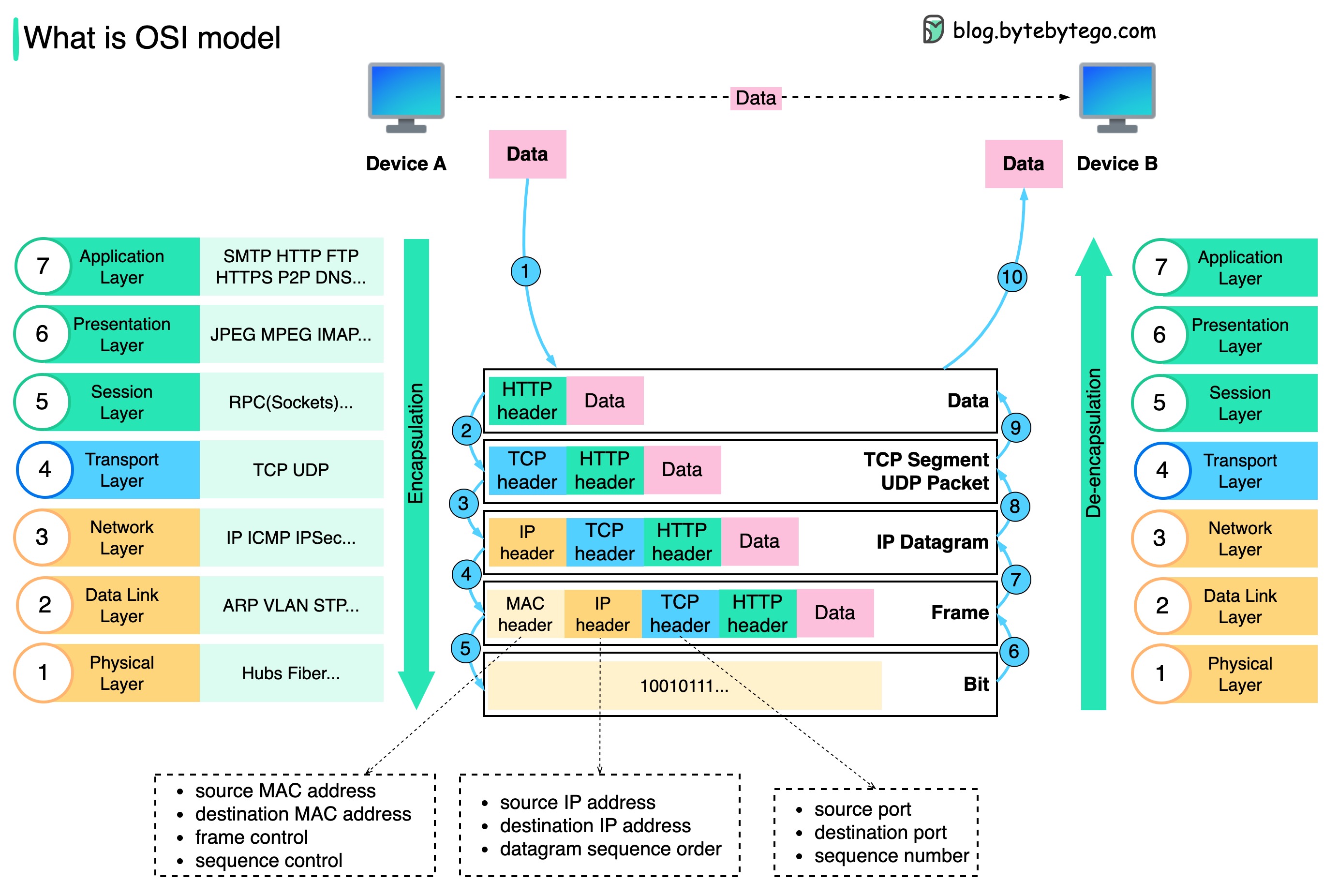
Langkah 1: Saat Perangkat A mengirim data ke Perangkat B melalui jaringan melalui protokol HTTP, header HTTP pertama kali ditambahkan pada lapisan aplikasi.
Langkah 2: Kemudian header TCP atau UDP ditambahkan ke data. Itu dienkapsulasi menjadi segmen TCP pada lapisan transport. Header berisi port sumber, port tujuan, dan nomor urut.
Langkah 3: Segmen tersebut kemudian dienkapsulasi dengan header IP pada lapisan jaringan. Header IP berisi alamat IP sumber/tujuan.
Langkah 4: Datagram IP ditambahkan header MAC pada lapisan data link, dengan alamat MAC sumber/tujuan.
Langkah 5: Bingkai yang dienkapsulasi dikirim ke lapisan fisik dan dikirim melalui jaringan dalam bit biner.
Langkah 6-10: Ketika Perangkat B menerima bit dari jaringan, ia melakukan proses de-enkapsulasi, yang merupakan proses kebalikan dari proses enkapsulasi. Header dihapus lapis demi lapis, dan pada akhirnya, Perangkat B dapat membaca data.
Kita memerlukan lapisan dalam model jaringan karena setiap lapisan berfokus pada tanggung jawabnya masing-masing. Setiap lapisan dapat mengandalkan header untuk memproses instruksi dan tidak perlu mengetahui arti data dari lapisan terakhir.
Diagram di bawah ini menunjukkan perbedaan antara ??????? ???? dan sebuah ???????? ?????.
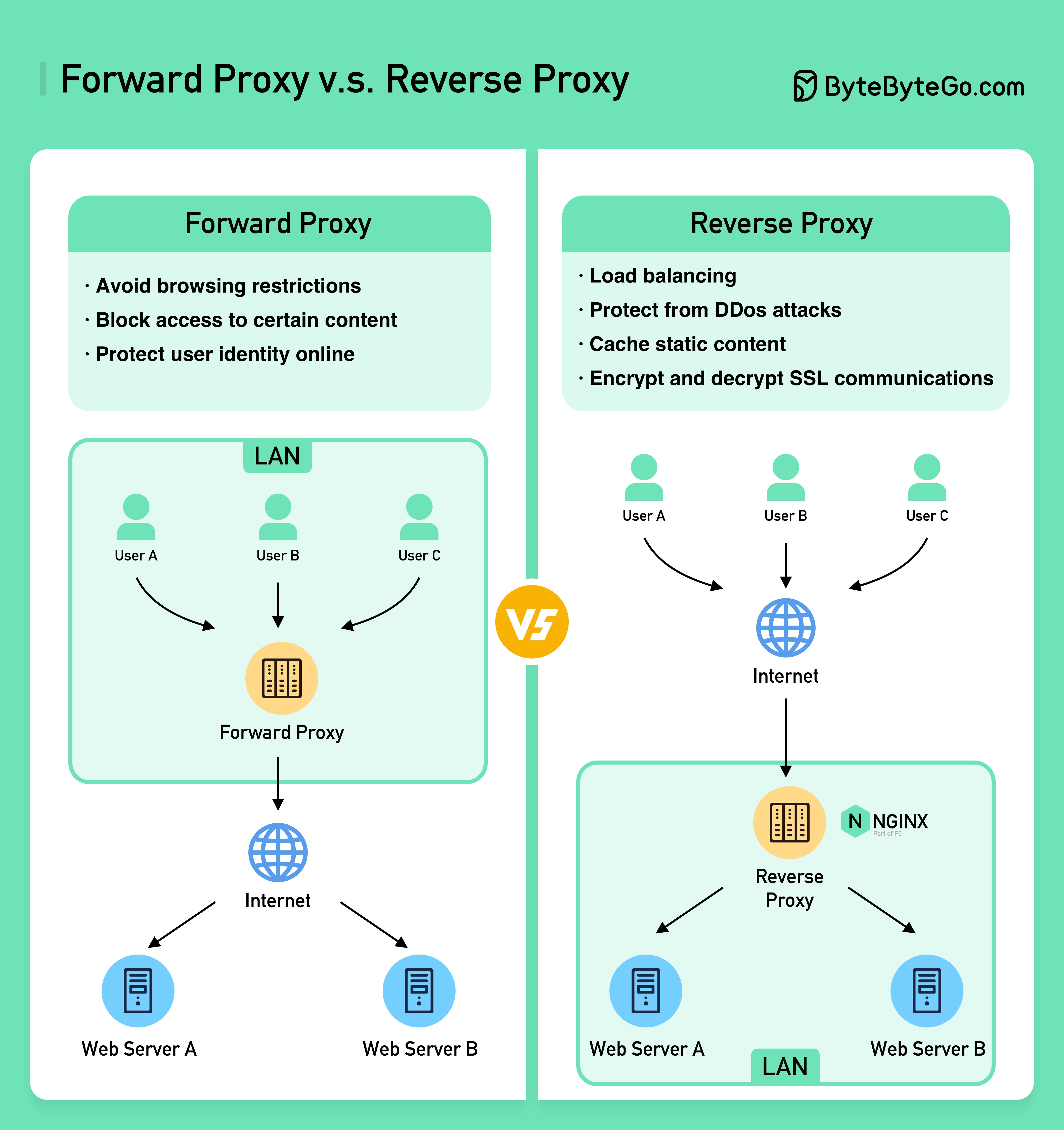
Proksi penerusan adalah server yang berada di antara perangkat pengguna dan internet.
Proksi penerusan biasanya digunakan untuk:
Proxy terbalik adalah server yang menerima permintaan dari klien, meneruskan permintaan tersebut ke server web, dan mengembalikan hasilnya ke klien seolah-olah server proxy telah memproses permintaan tersebut.
Proksi terbalik bagus untuk:
Diagram di bawah menunjukkan 6 algoritma umum.
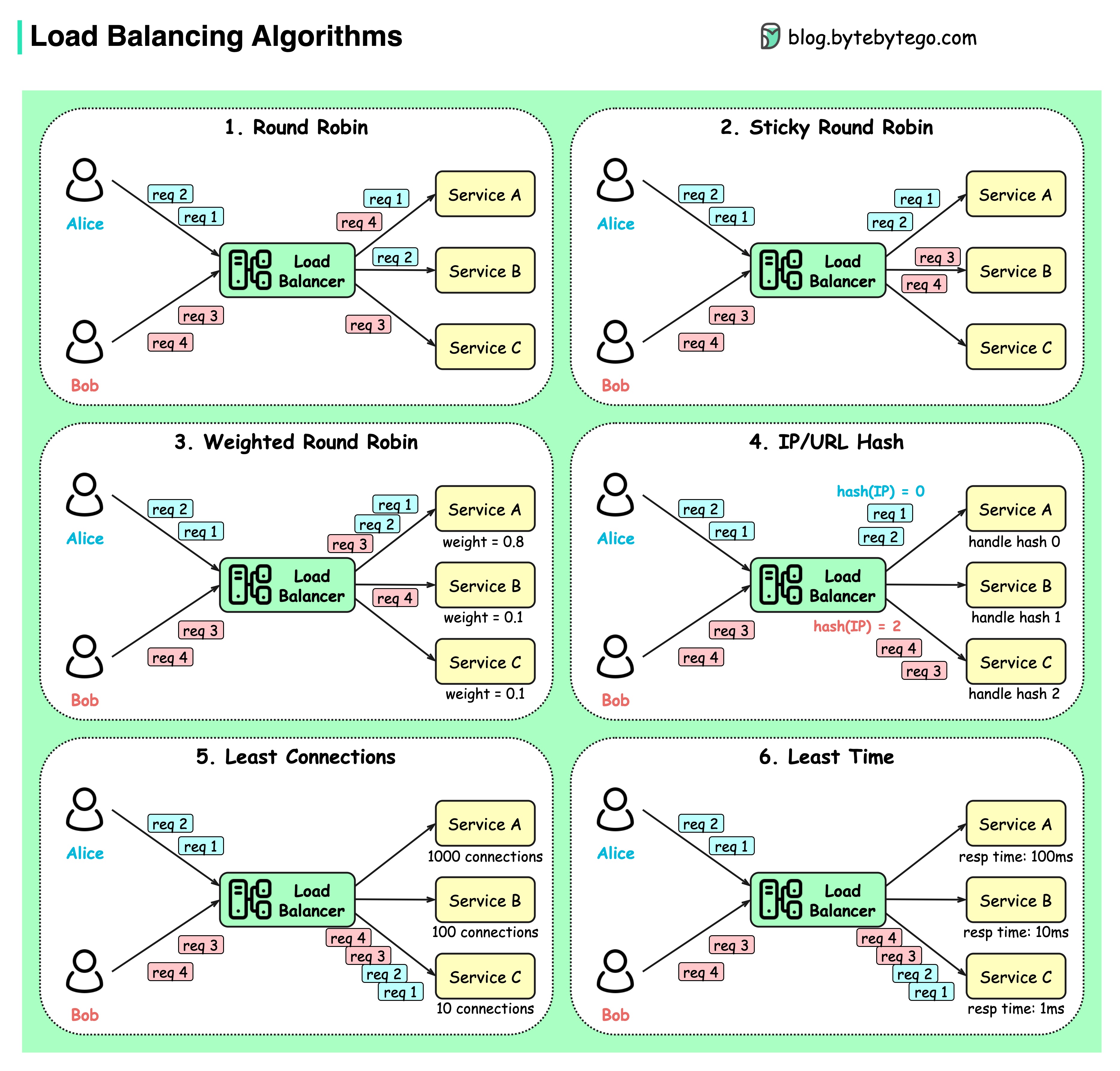
Usul
Permintaan klien dikirim ke contoh layanan yang berbeda secara berurutan. Layanan biasanya diharuskan tanpa kewarganegaraan.
Robin bundar yang lengket
Ini merupakan penyempurnaan dari algoritma round-robin. Jika permintaan pertama Alice ditujukan ke layanan A, permintaan berikutnya juga ditujukan ke layanan A.
Round-robin berbobot
Admin dapat menentukan bobot untuk setiap layanan. Yang memiliki bobot lebih tinggi menangani lebih banyak permintaan daripada yang lain.
hash
Algoritme ini menerapkan fungsi hash pada IP atau URL permintaan masuk. Permintaan dialihkan ke instance yang relevan berdasarkan hasil fungsi hash.
Koneksi paling sedikit
Permintaan baru dikirim ke instans layanan dengan koneksi serentak paling sedikit.
Waktu respons paling sedikit
Permintaan baru dikirim ke instans layanan dengan waktu respons tercepat.
Diagram di bawah menunjukkan perbandingan URL, URI, dan URN.
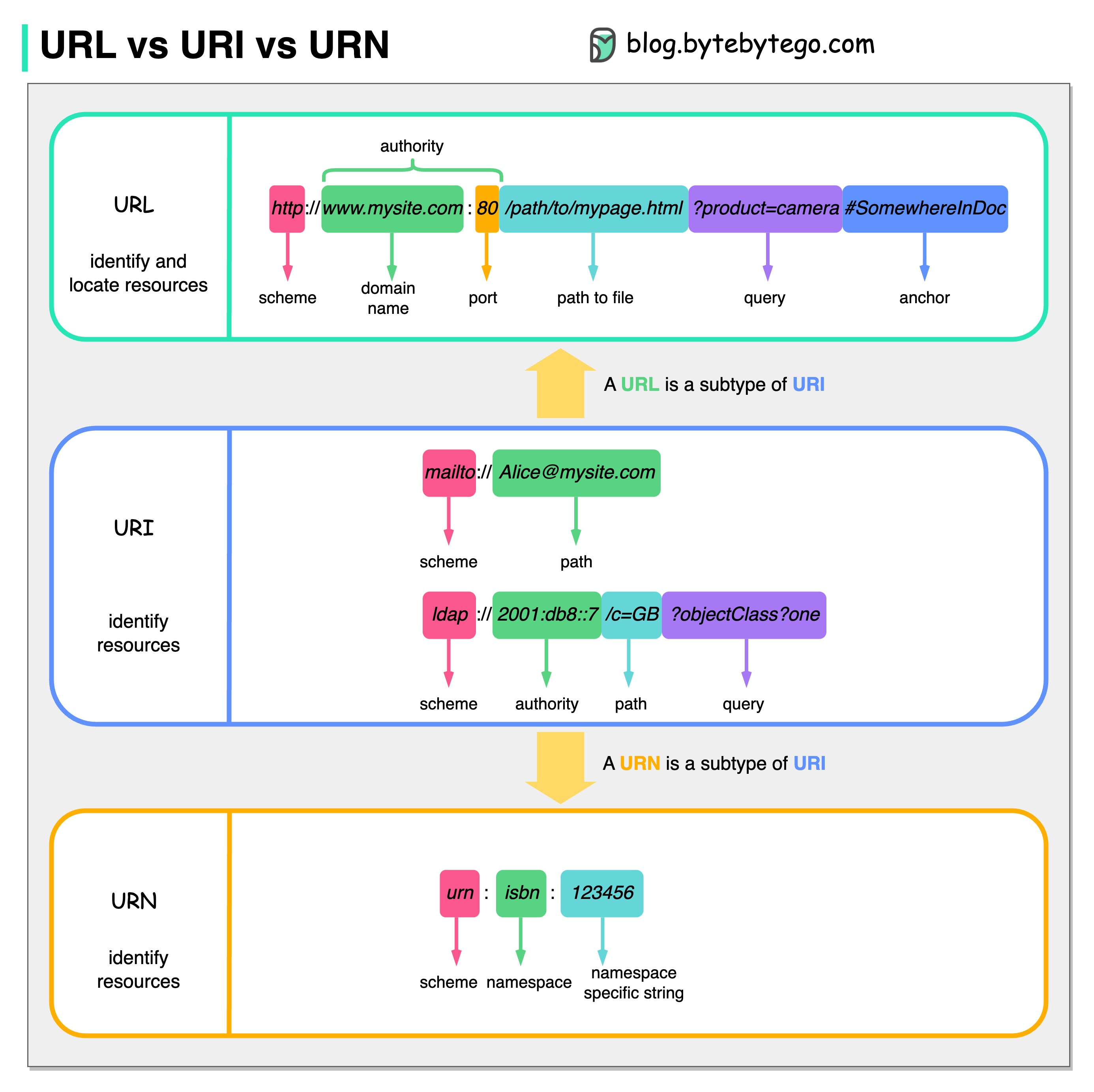
URI adalah singkatan dari Uniform Resource Identifier. Ini mengidentifikasi sumber daya logis atau fisik di web. URL dan URN adalah subtipe dari URI. URL menemukan sumber daya, sementara URN memberi nama sumber daya.
URI terdiri dari bagian-bagian berikut: skema:[//authority]path[?query][#fragment]
URL adalah singkatan dari Uniform Resource Locator, konsep utama HTTP. Ini adalah alamat sumber daya unik di web. Ini dapat digunakan dengan protokol lain seperti FTP dan JDBC.
URN adalah singkatan Nama Sumber Seragam. Ini menggunakan skema guci. URN tidak dapat digunakan untuk menemukan sumber daya. Contoh sederhana yang diberikan dalam diagram terdiri dari namespace dan string khusus namespace.
Jika Anda ingin mempelajari lebih detail tentang subjek ini, saya akan merekomendasikan klarifikasi W3C.
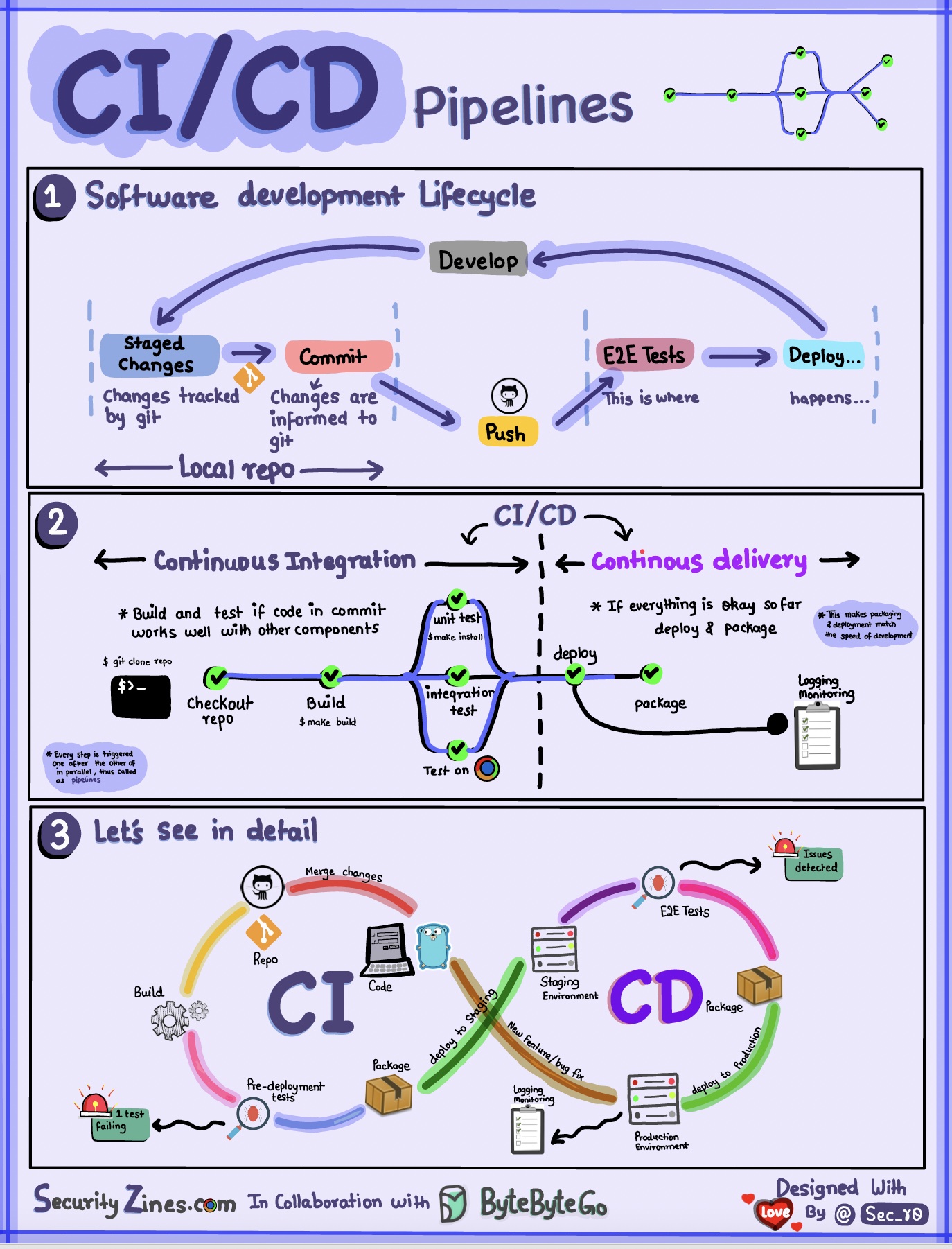
Bagian 1 - SDLC dengan CI/CD
Siklus hidup pengembangan perangkat lunak (SDLC) terdiri dari beberapa tahapan utama: pengembangan, pengujian, penerapan, dan pemeliharaan. CI/CD mengotomatiskan dan mengintegrasikan tahapan ini untuk memungkinkan rilis yang lebih cepat dan andal.
Saat kode dimasukkan ke repositori git, kode tersebut akan memicu proses pembuatan dan pengujian otomatis. Kasus uji end-to-end (e2e) dijalankan untuk memvalidasi kode. Jika pengujian berhasil, kode dapat diterapkan secara otomatis ke pementasan/produksi. Jika ditemukan masalah, kode dikirim kembali ke pengembangan untuk perbaikan bug. Otomatisasi ini memberikan umpan balik yang cepat kepada pengembang dan mengurangi risiko bug dalam produksi.
Bagian 2 - Perbedaan antara CI dan CD
Integrasi Berkelanjutan (CI) mengotomatiskan proses pembuatan, pengujian, dan penggabungan. Ini menjalankan pengujian setiap kali kode diterapkan untuk mendeteksi masalah integrasi sejak dini. Hal ini mendorong penerapan kode yang sering dan umpan balik yang cepat.
Pengiriman Berkelanjutan (CD) mengotomatiskan proses rilis seperti perubahan dan penerapan infrastruktur. Hal ini memastikan perangkat lunak dapat dirilis dengan andal kapan saja melalui alur kerja otomatis. CD juga dapat mengotomatiskan pengujian manual dan langkah-langkah persetujuan yang diperlukan sebelum penerapan produksi.
Bagian 3 - Saluran Pipa CI/CD
Pipeline CI/CD pada umumnya memiliki beberapa tahapan yang saling terhubung:
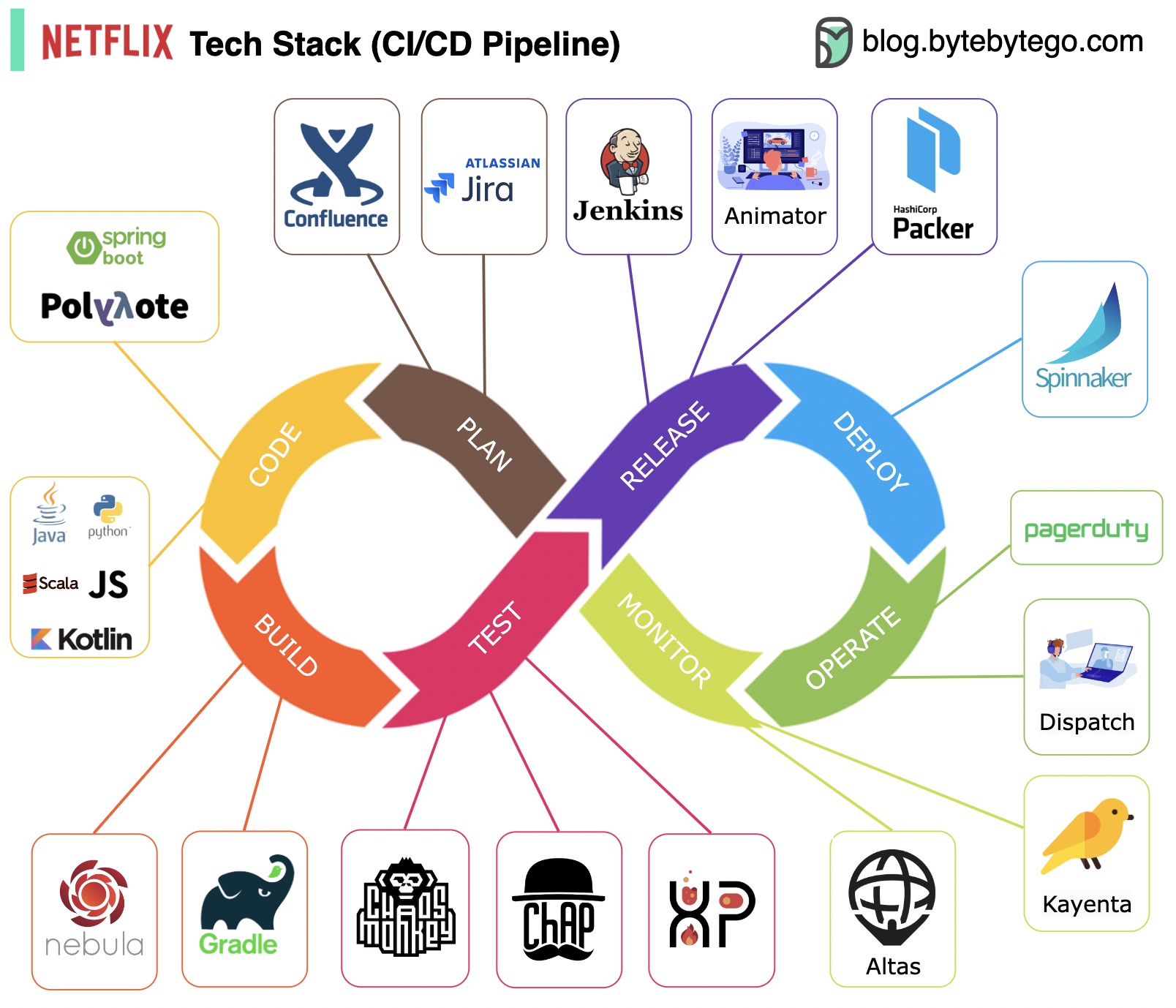
Perencanaan: Netflix Engineering menggunakan JIRA untuk perencanaan dan Confluence untuk dokumentasi.
Pengkodean: Java adalah bahasa pemrograman utama untuk layanan backend, sementara bahasa lain digunakan untuk kasus penggunaan yang berbeda.
Build: Gradle terutama digunakan untuk membangun, dan plugin Gradle dibuat untuk mendukung berbagai kasus penggunaan.
Pengemasan: Paket dan dependensi dikemas ke dalam Amazon Machine Image (AMI) untuk dirilis.
Pengujian: Pengujian menekankan fokus budaya produksi pada pembuatan alat chaos.
Penerapan: Netflix menggunakan Spinnaker buatannya sendiri untuk penerapan peluncuran kenari.
Pemantauan: Metrik pemantauan dipusatkan di Atlas, dan Kayenta digunakan untuk mendeteksi anomali.
Laporan Insiden: Insiden dikirim berdasarkan prioritas, dan PagerDuty digunakan untuk penanganan insiden.
Pola arsitektur ini termasuk yang paling umum digunakan dalam pengembangan aplikasi, baik di platform iOS atau Android. Pengembang telah memperkenalkannya untuk mengatasi keterbatasan pola sebelumnya. Jadi, apa perbedaannya?
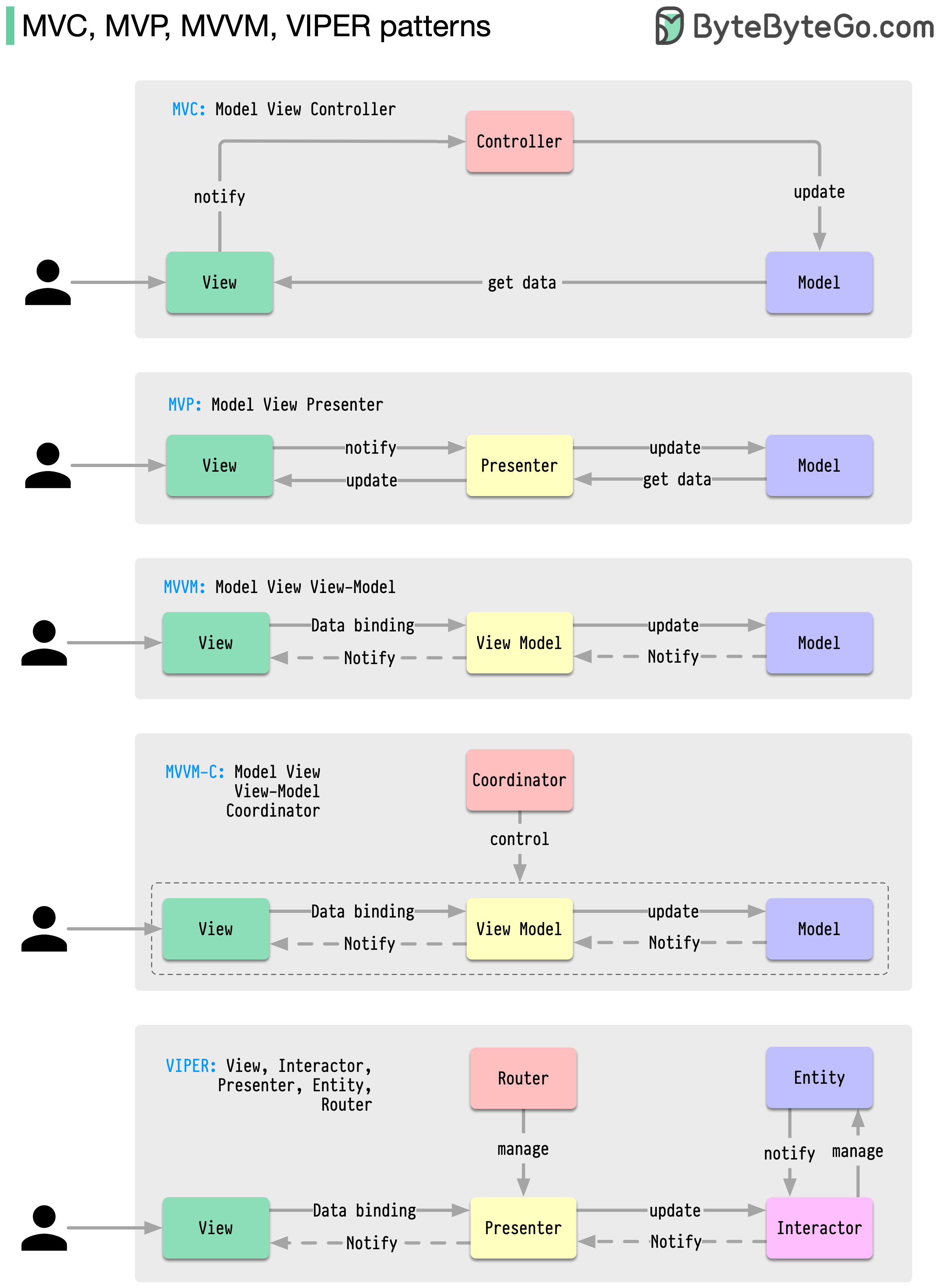
Pola adalah solusi yang dapat digunakan kembali untuk masalah desain umum, sehingga menghasilkan proses pengembangan yang lebih lancar dan efisien. Mereka berfungsi sebagai cetak biru untuk membangun struktur perangkat lunak yang lebih baik. Ini adalah beberapa pola yang paling populer:

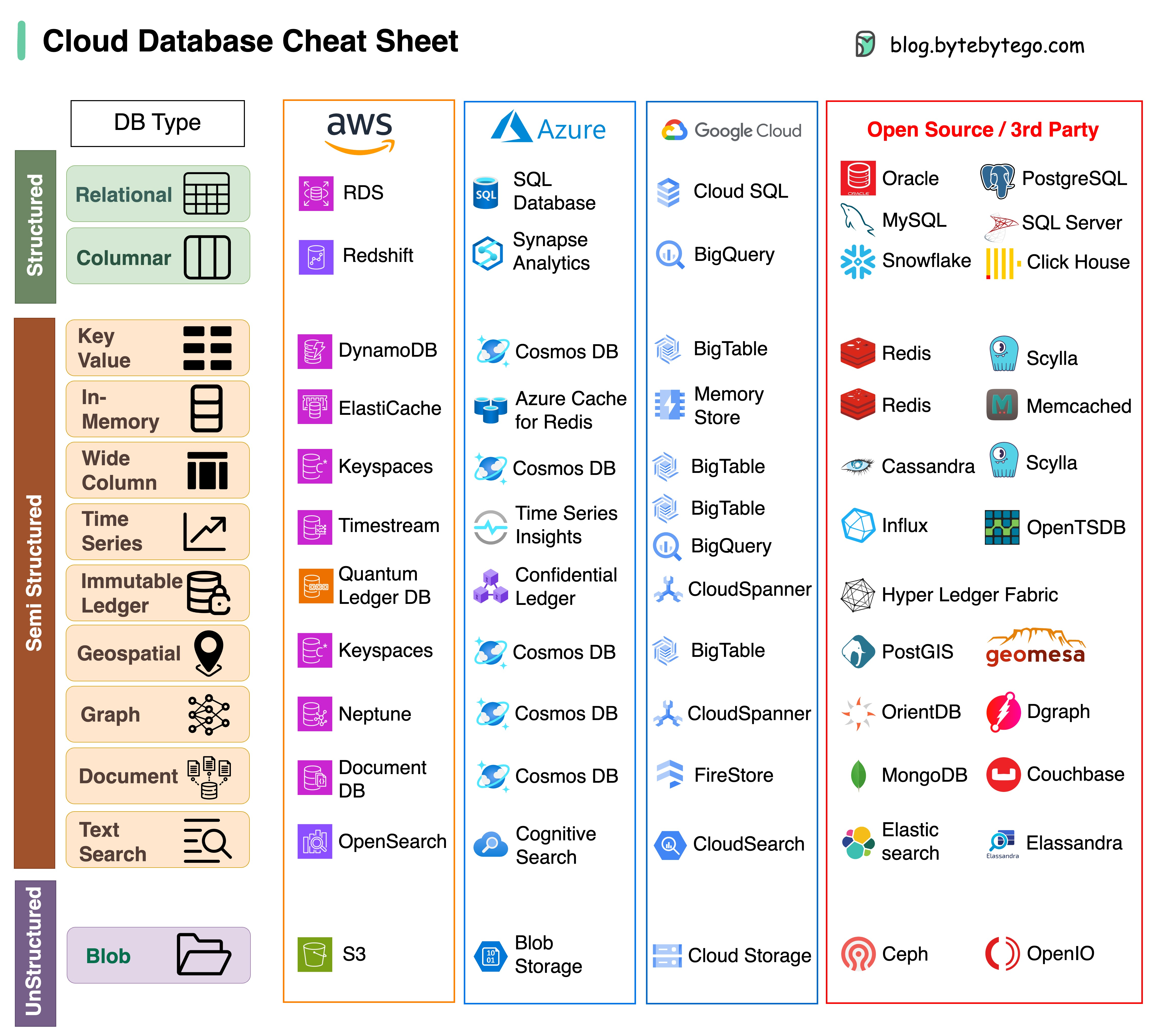
Memilih database yang tepat untuk proyek Anda adalah tugas yang rumit. Banyaknya pilihan database, masing-masing disesuaikan dengan kasus penggunaan yang berbeda, dapat dengan cepat menyebabkan kelelahan pengambilan keputusan.
Kami berharap lembar contekan ini memberikan arahan tingkat tinggi untuk menentukan layanan yang tepat yang selaras dengan kebutuhan proyek Anda dan menghindari potensi kesalahan.
Catatan: Google memiliki dokumentasi terbatas untuk kasus penggunaan basis datanya. Meskipun kami melakukan yang terbaik untuk melihat apa yang tersedia dan sampai pada pilihan terbaik, beberapa entri mungkin perlu lebih akurat.
Jawabannya akan bervariasi tergantung pada kasus penggunaan Anda. Data dapat diindeks di memori atau di disk. Demikian pula, format data bervariasi, seperti angka, string, koordinat geografis, dll. Sistem mungkin banyak menulis atau membaca. Semua faktor ini mempengaruhi pilihan format indeks database Anda.
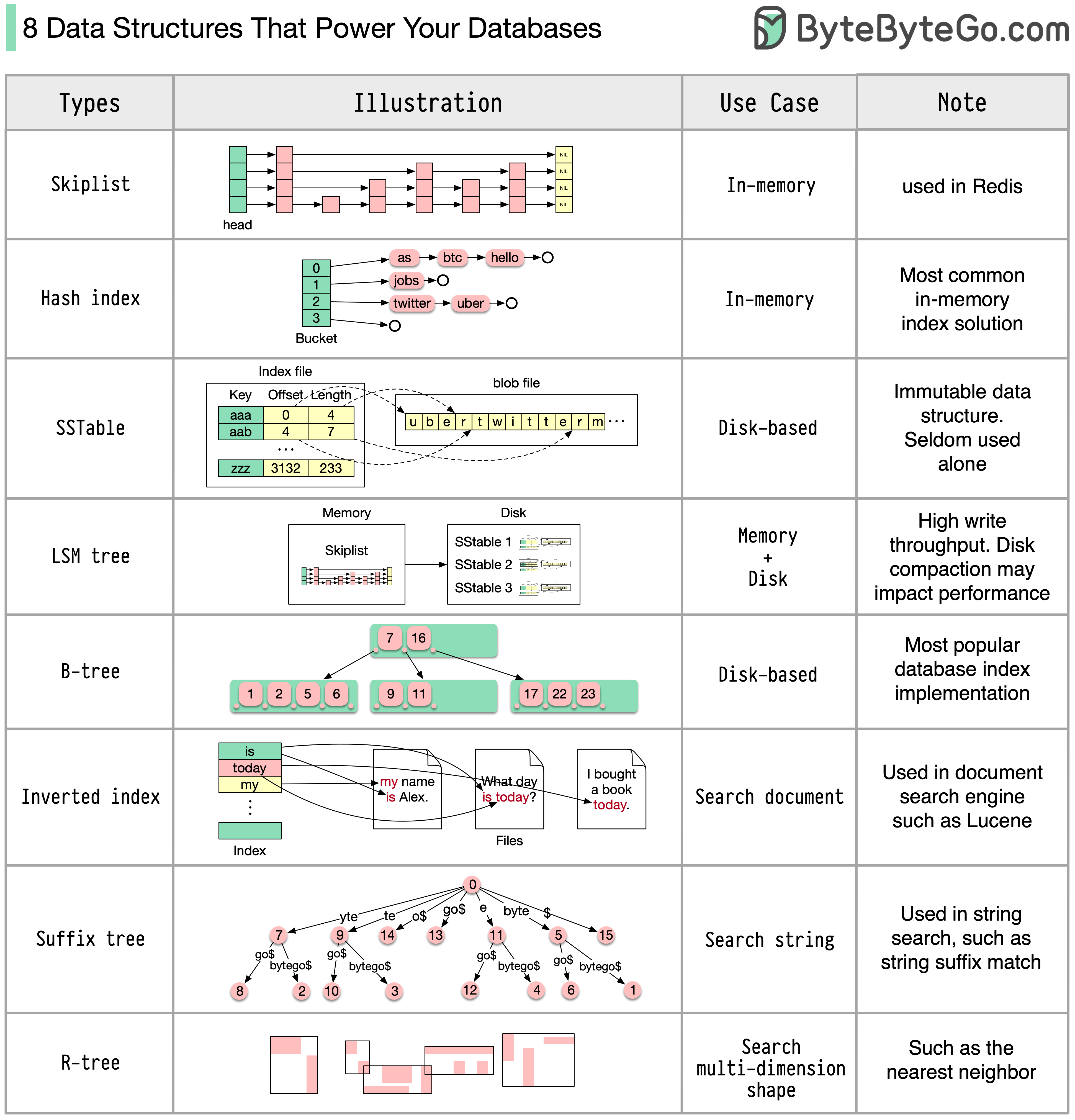
Berikut ini adalah beberapa struktur data paling populer yang digunakan untuk mengindeks data:
Diagram di bawah menunjukkan prosesnya. Perhatikan bahwa arsitektur untuk database yang berbeda berbeda, diagram menunjukkan beberapa desain umum.
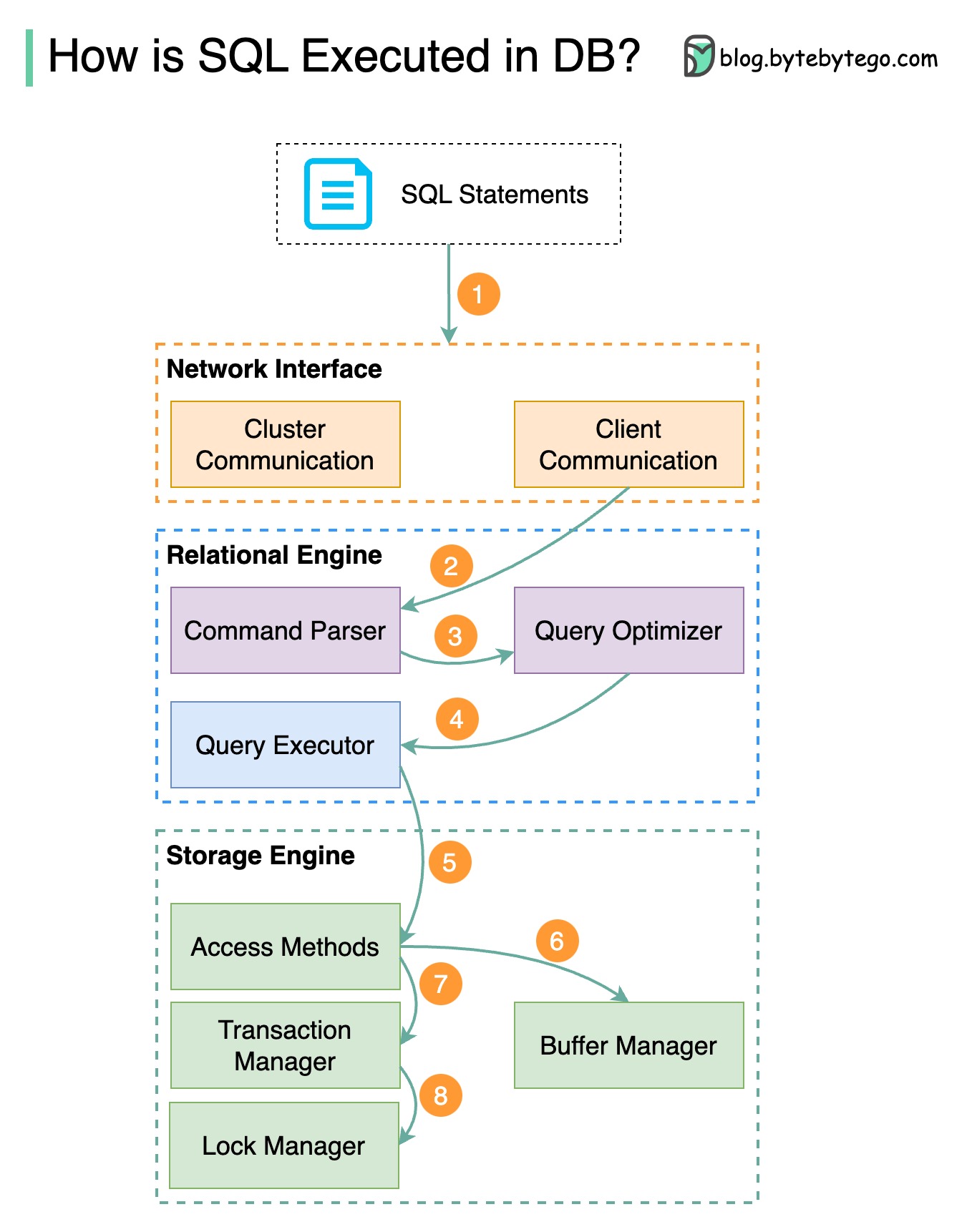
Langkah 1 - Pernyataan SQL dikirim ke database melalui protokol lapisan transport (misalnyaTCP).
Langkah 2 - Pernyataan SQL dikirim ke parser perintah, di mana pernyataan tersebut melewati analisis sintaksis dan semantik, dan pohon kueri dibuat setelahnya.
Langkah 3 - Pohon kueri dikirim ke pengoptimal. Pengoptimal membuat rencana eksekusi.
Langkah 4 - Rencana eksekusi dikirim ke pelaksana. Pelaksana mengambil data dari eksekusi.
Langkah 5 - Metode akses menyediakan logika pengambilan data yang diperlukan untuk eksekusi, mengambil data dari mesin penyimpanan.
Langkah 6 - Metode akses memutuskan apakah pernyataan SQL bersifat baca-saja. Jika kueri bersifat baca-saja (pernyataan SELECT), kueri tersebut diteruskan ke manajer buffer untuk diproses lebih lanjut. Manajer buffer mencari data di cache atau file data.
Langkah 7 - Jika pernyataannya adalah UPDATE atau INSERT, pernyataan tersebut diteruskan ke manajer transaksi untuk diproses lebih lanjut.
Langkah 8 - Selama transaksi, data berada dalam mode kunci. Ini dijamin oleh pengelola kunci. Ini juga memastikan properti ACID transaksi.
Teorema CAP adalah salah satu istilah paling terkenal dalam ilmu komputer, tapi saya yakin pengembang yang berbeda memiliki pemahaman yang berbeda. Mari kita periksa apa itu dan mengapa hal ini dapat membingungkan.
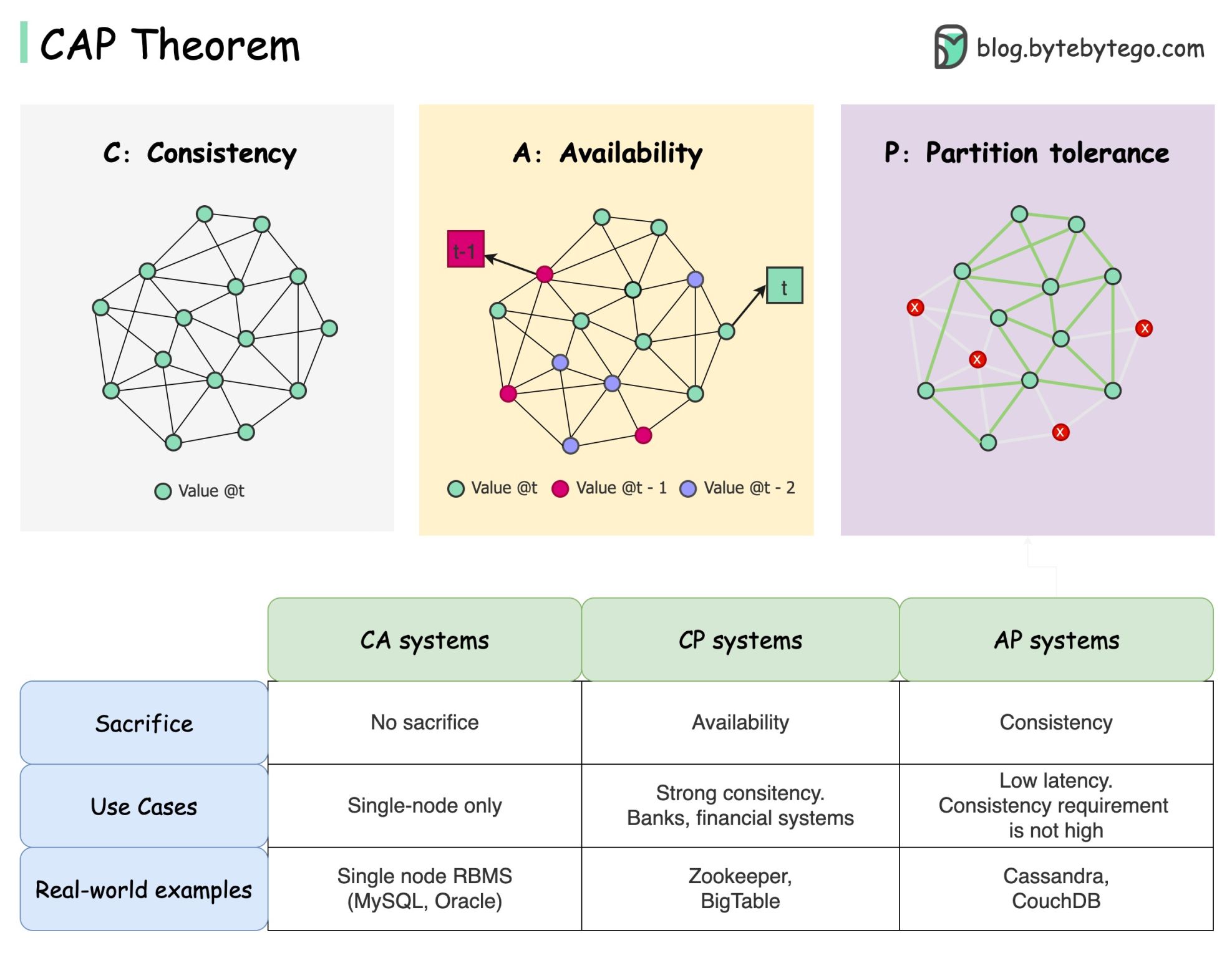
Teorema CAP menyatakan bahwa sistem terdistribusi tidak dapat memberikan lebih dari dua dari tiga jaminan ini secara bersamaan.
Konsistensi : konsistensi berarti semua klien melihat data yang sama pada waktu yang sama, tidak peduli node mana yang mereka sambungkan.
Ketersediaan : ketersediaan berarti setiap klien yang meminta data mendapat respons meskipun beberapa node sedang tidak aktif.
Toleransi Partisi : partisi menunjukkan putusnya komunikasi antara dua node. Toleransi partisi berarti sistem terus beroperasi meskipun ada partisi jaringan.
Formulasi “2 dari 3” mungkin berguna, namun penyederhanaan ini bisa menyesatkan .
Memilih database tidaklah mudah. Membenarkan pilihan kita hanya berdasarkan teorema CAP saja tidaklah cukup. Misalnya, perusahaan tidak memilih Cassandra untuk aplikasi chatting hanya karena merupakan sistem AP. Ada daftar karakteristik bagus yang menjadikan Cassandra pilihan yang diinginkan untuk menyimpan pesan obrolan. Kita perlu menggali lebih dalam.
“CAP hanya melarang sebagian kecil dari ruang desain: ketersediaan sempurna dan konsistensi dengan adanya partisi, yang jarang terjadi”. Dikutip dari makalah: CAP Dua Belas Tahun Kemudian: Bagaimana “Aturan” Berubah.
Teoremanya adalah tentang ketersediaan dan konsistensi 100%. Diskusi yang lebih realistis adalah trade-off antara latensi dan konsistensi ketika tidak ada partisi jaringan. Lihat teorema PACELC untuk lebih jelasnya.
Apakah teorema CAP benar-benar berguna?
Saya pikir ini masih berguna karena membuka pikiran kita terhadap serangkaian diskusi trade-off, namun ini hanya sebagian dari cerita. Kita perlu menggali lebih dalam ketika memilih database yang tepat.
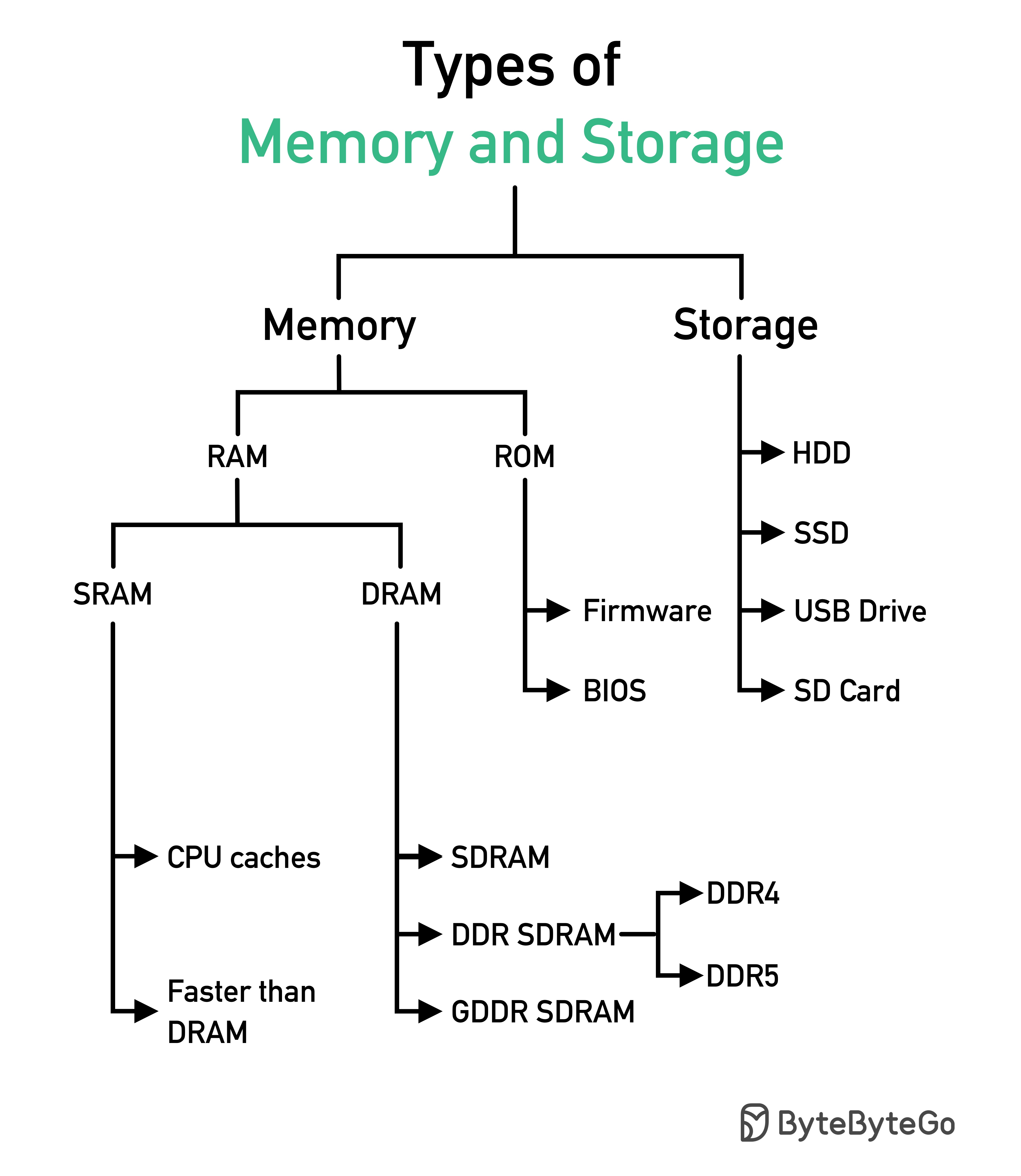
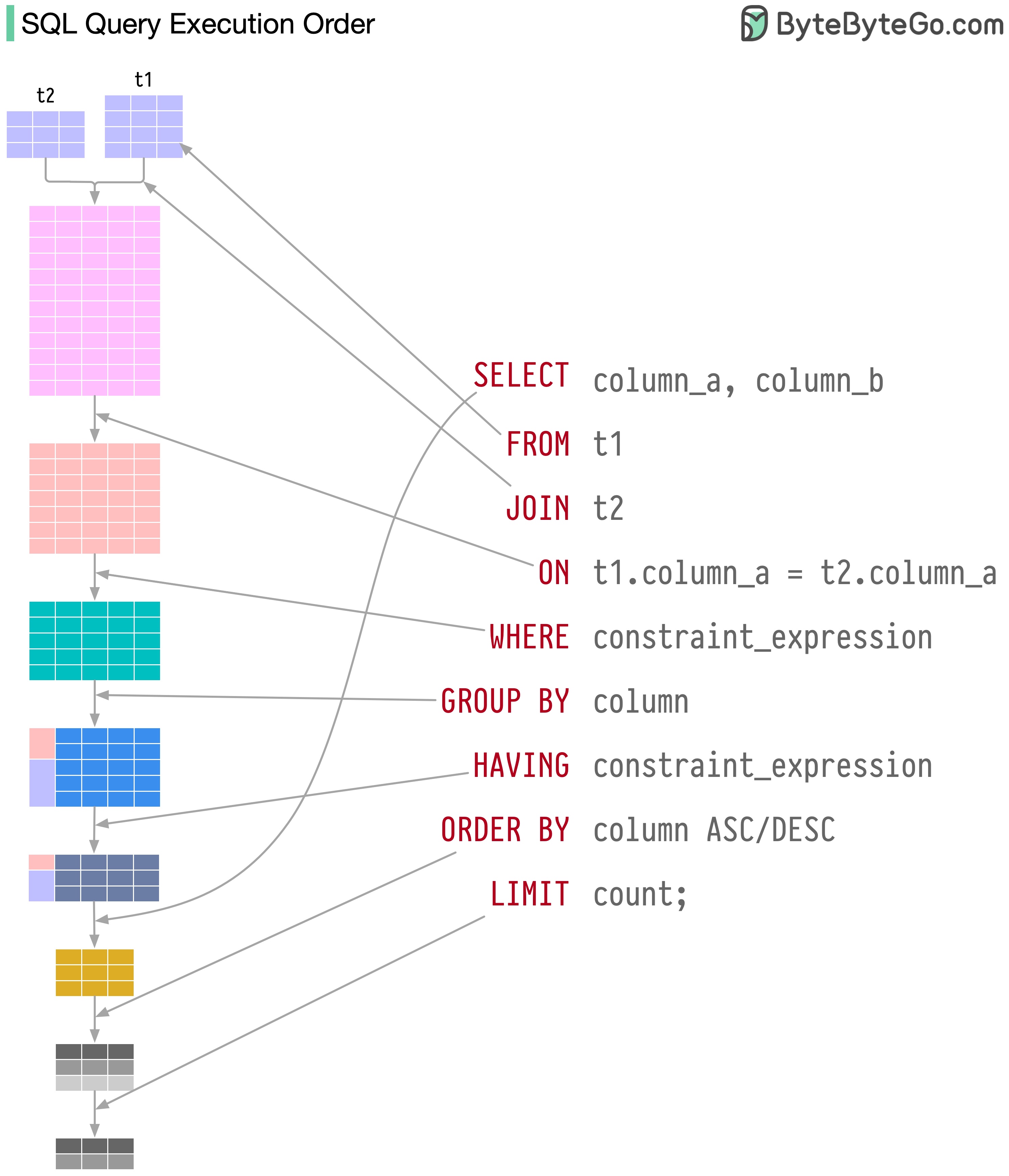
Pernyataan SQL dieksekusi oleh sistem database dalam beberapa langkah, termasuk:
Eksekusi SQL sangat kompleks dan melibatkan banyak pertimbangan, seperti:
Pada tahun 1986, SQL (Structured Query Language) menjadi standar. Selama 40 tahun berikutnya, bahasa ini menjadi bahasa dominan untuk sistem manajemen basis data relasional. Membaca standar terbaru (ANSI SQL 2016) dapat memakan waktu. Bagaimana saya bisa mempelajarinya?
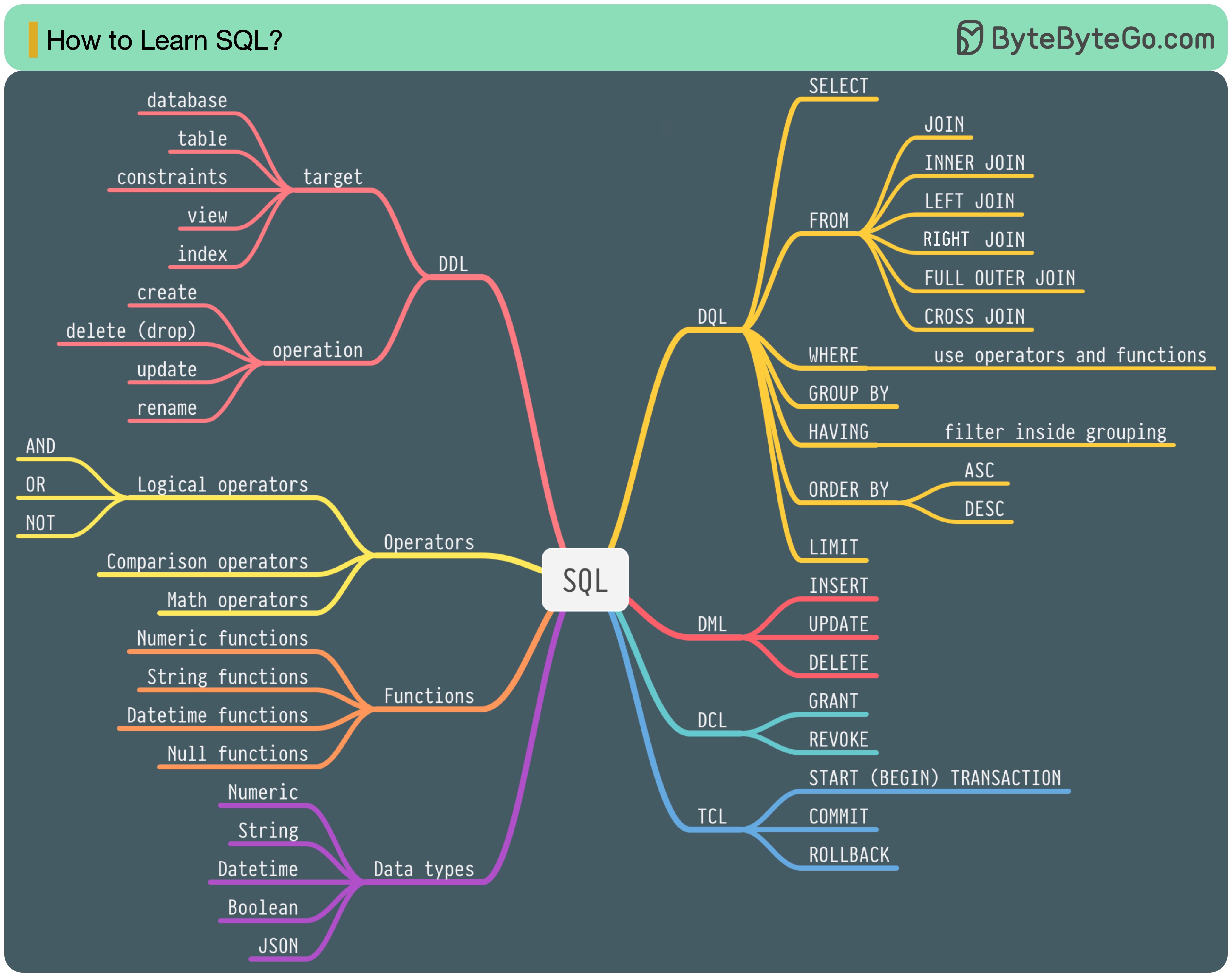
Ada 5 komponen bahasa SQL:
Untuk seorang backend engineer, Anda mungkin perlu mengetahui sebagian besarnya. Sebagai seorang analis data, Anda mungkin perlu memiliki pemahaman yang baik tentang DQL. Pilih topik yang paling relevan bagi Anda.
Diagram ini mengilustrasikan tempat kami menyimpan data dalam cache dalam arsitektur tipikal.
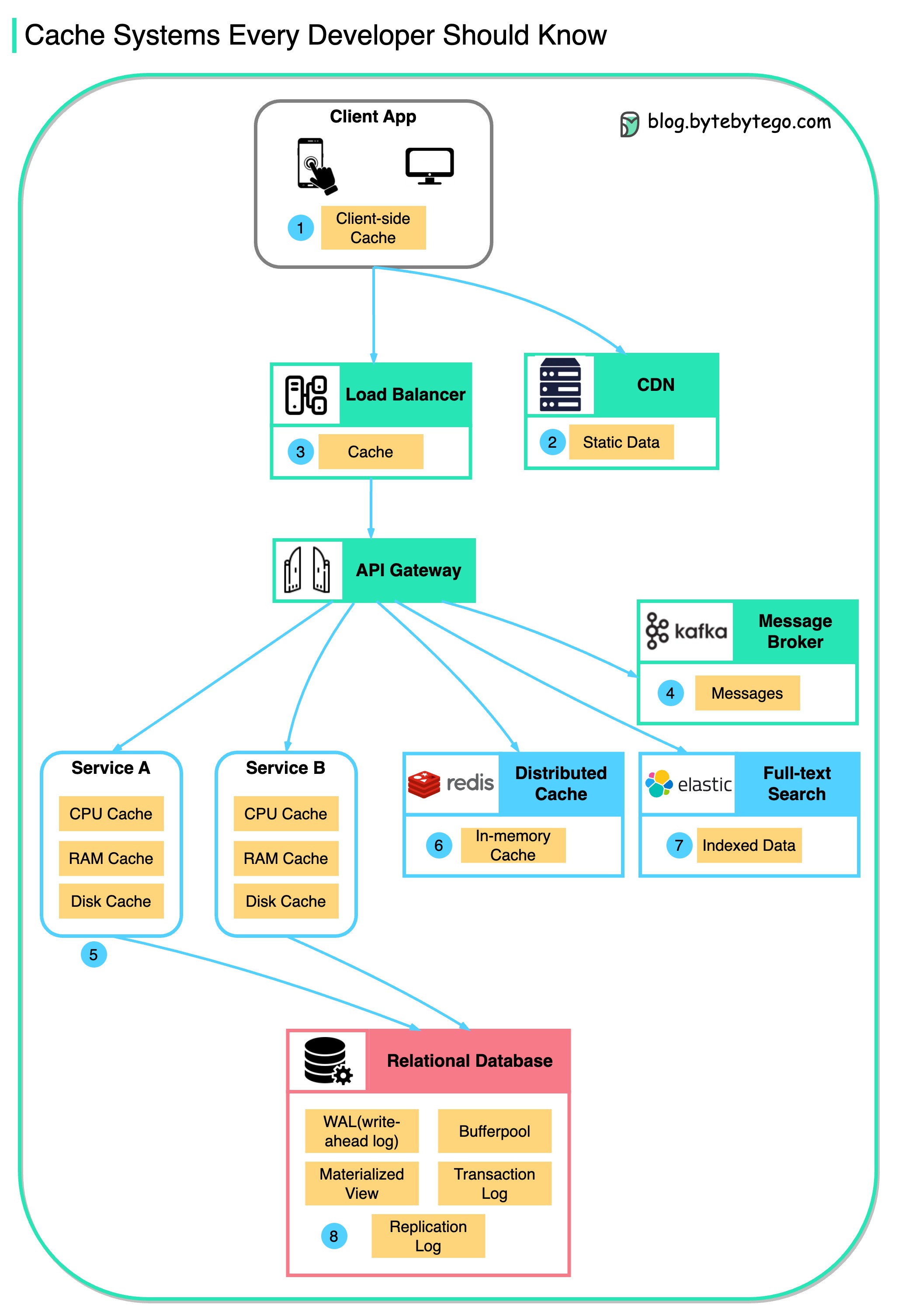
Ada banyak lapisan di sepanjang aliran.
Ada 3 alasan utama seperti yang ditunjukkan pada diagram di bawah ini.
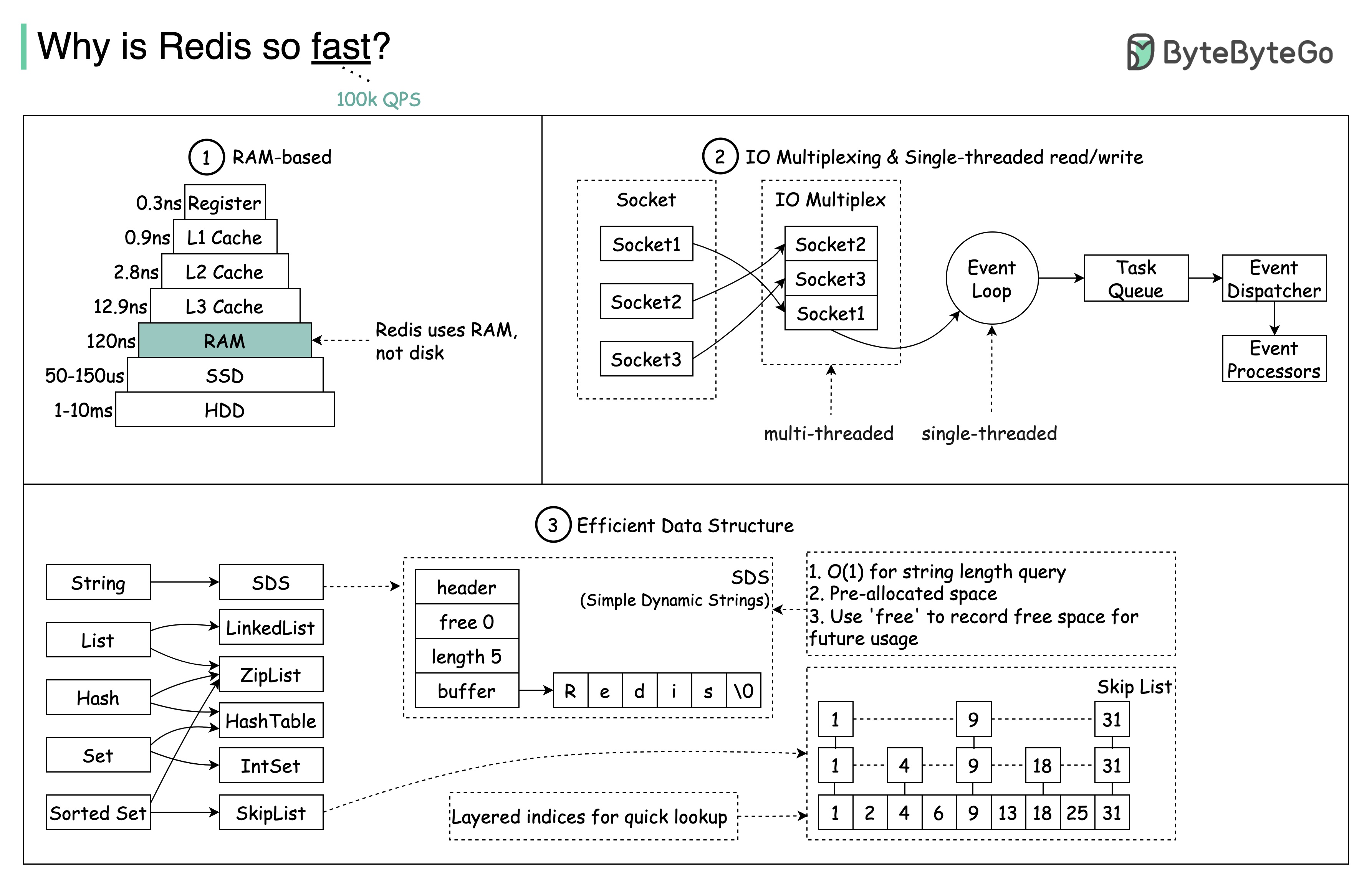
Pertanyaan: Penyimpanan dalam memori populer lainnya adalah Memcached. Tahukah Anda perbedaan antara Redis dan Memcached?
Anda mungkin memperhatikan gaya diagram ini berbeda dari posting saya sebelumnya. Tolong beri tahu saya mana yang Anda sukai.
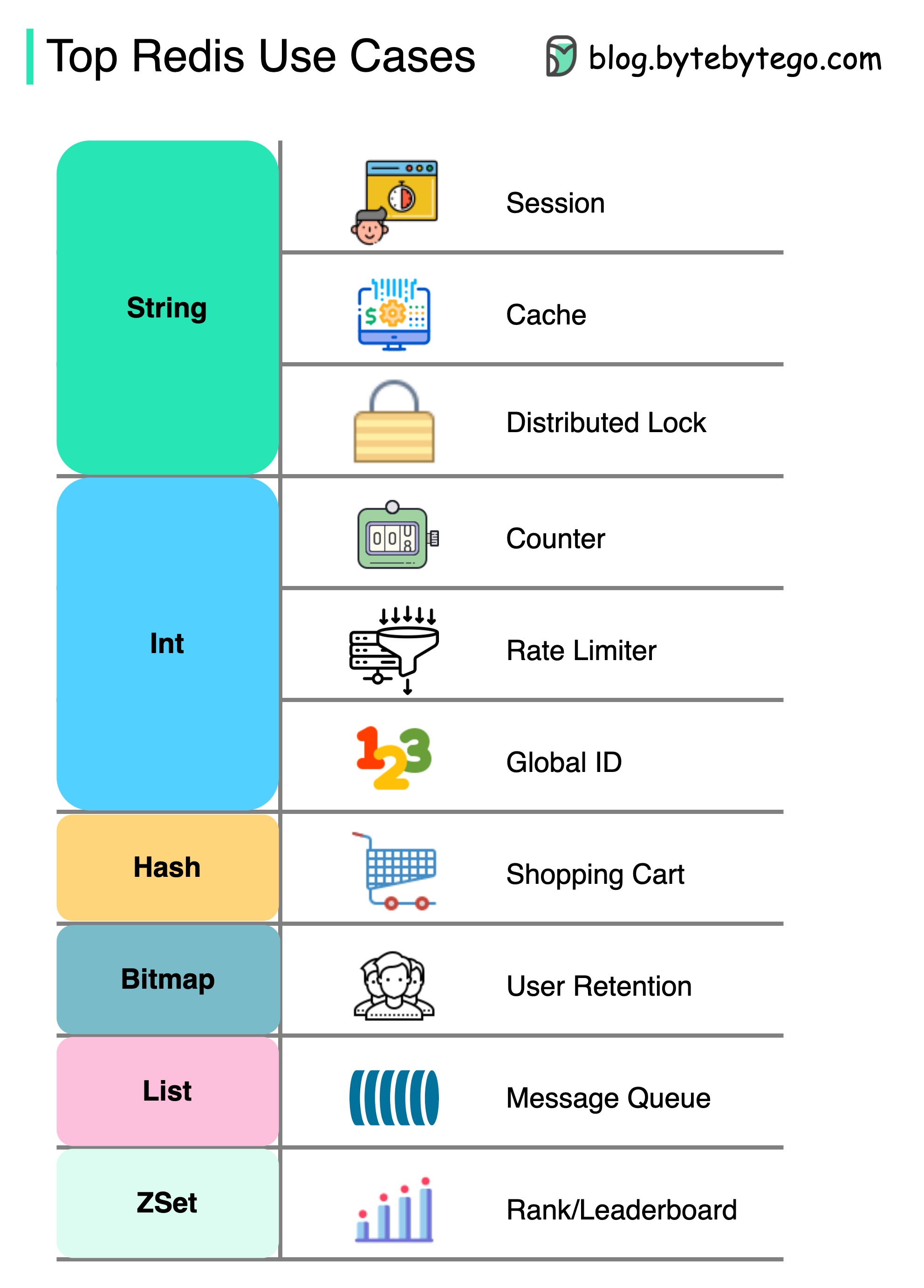
Ada lebih banyak hal untuk Redis daripada sekadar caching.
Redis dapat digunakan dalam berbagai skenario seperti yang ditunjukkan dalam diagram.
Sidang
Kami dapat menggunakan Redis untuk berbagi data sesi pengguna di antara berbagai layanan.
Cache
Kita dapat menggunakan objek atau halaman Redis untuk cache, terutama untuk data hotspot.
Kunci Terdistribusi
Kami dapat menggunakan string Redis untuk memperoleh kunci di antara layanan terdistribusi.
Menangkal
Kita dapat menghitung berapa banyak suka atau berapa banyak bacaan untuk artikel.
Tingkat pembatas
Kami dapat menerapkan limiter tingkat untuk IP pengguna tertentu.
Generator ID Global
Kita dapat menggunakan redis int untuk ID global.
Keranjang belanja
Kita dapat menggunakan hash redis untuk mewakili pasangan bernilai kunci dalam keranjang belanja.
Hitung retensi pengguna
Kami dapat menggunakan bitmap untuk mewakili login pengguna setiap hari dan menghitung retensi pengguna.
Antrian pesan
Kami dapat menggunakan daftar untuk antrian pesan.
Peringkat
Kita dapat menggunakan zset untuk mengurutkan artikel.
Merancang sistem skala besar biasanya membutuhkan pertimbangan caching yang cermat. Di bawah ini adalah lima strategi caching yang sering digunakan.
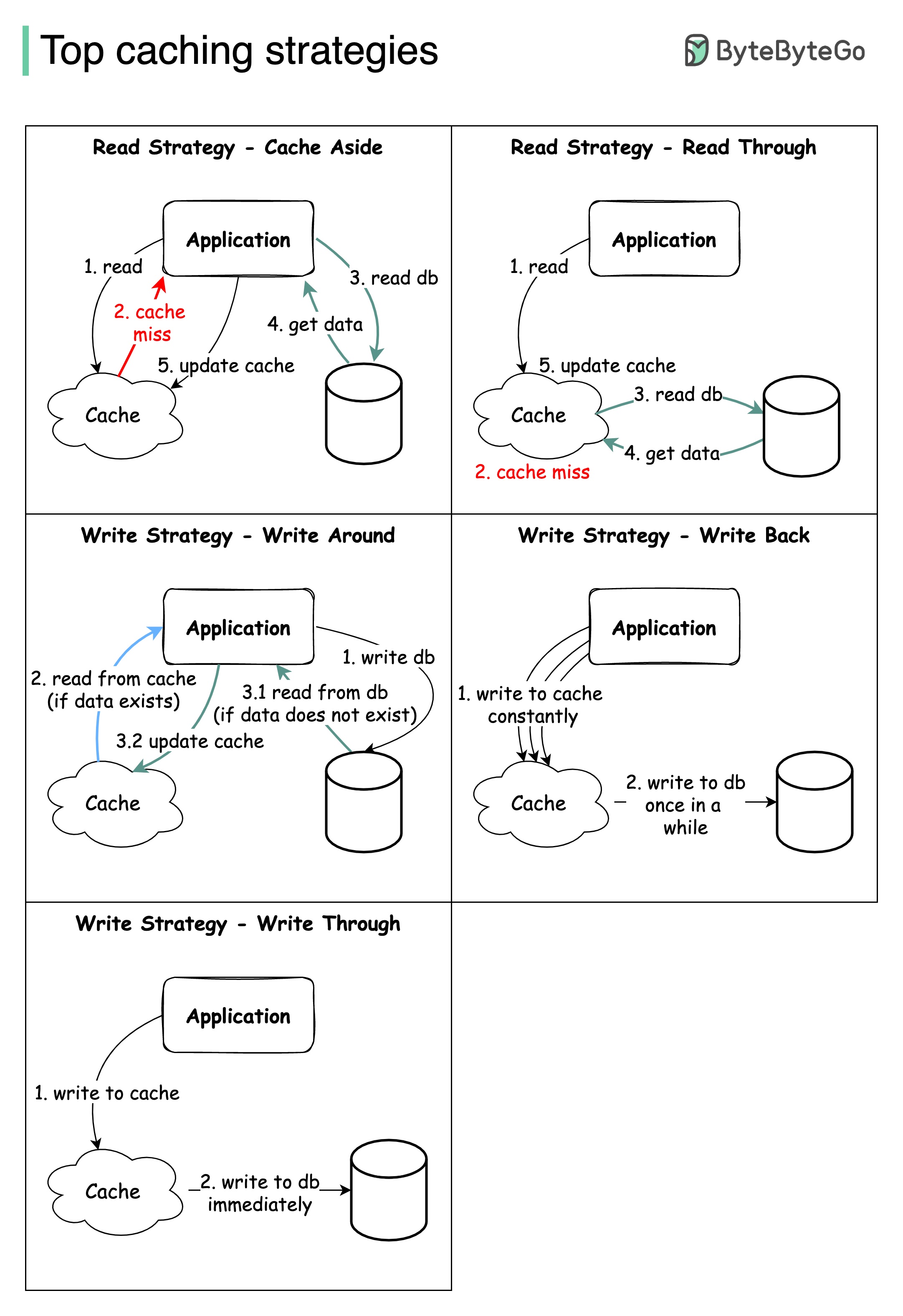
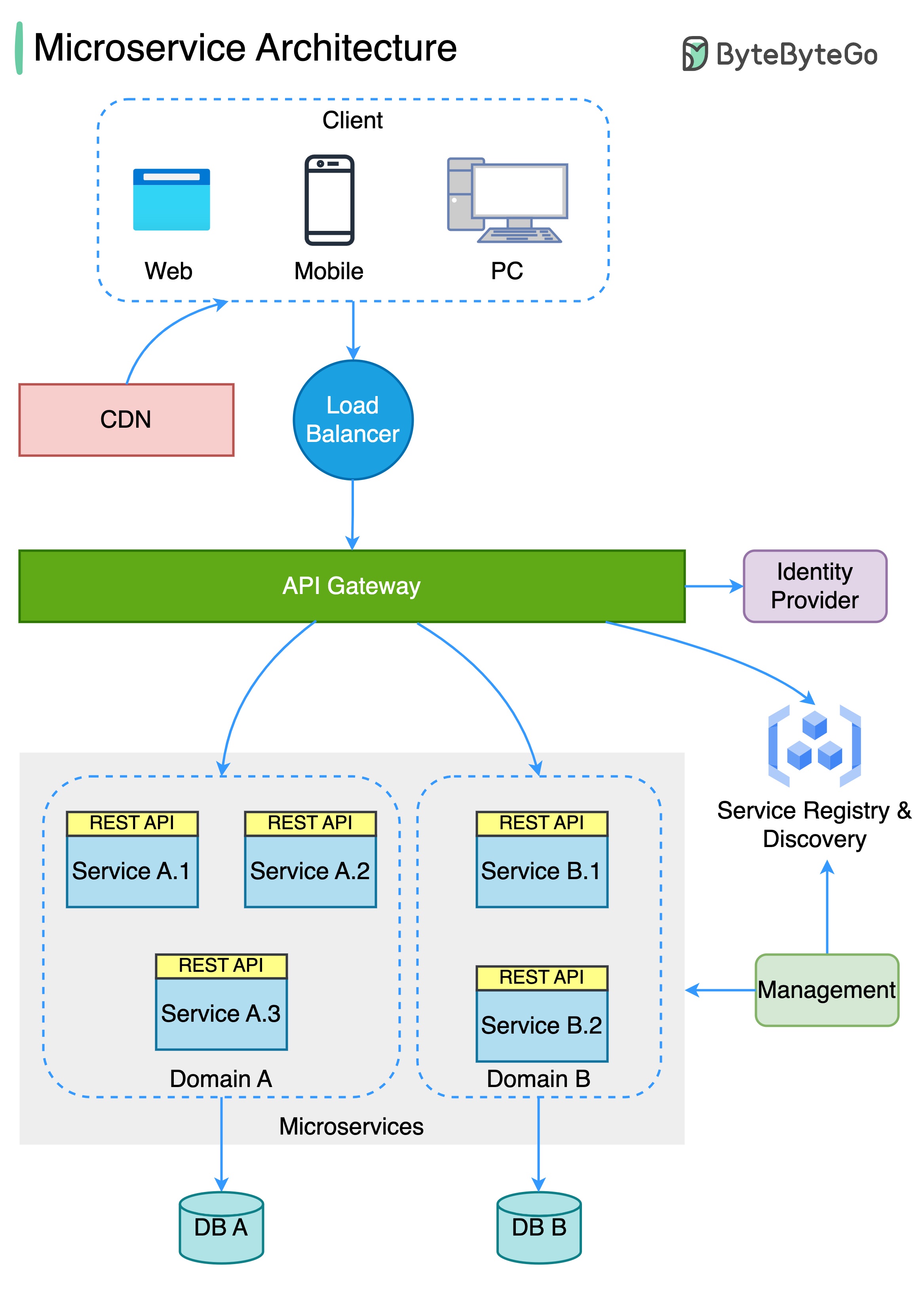
Diagram di bawah ini menunjukkan arsitektur layanan mikro yang khas.
Manfaat Layanan Mikro:
Sebuah gambar bernilai ribuan kata: 9 praktik terbaik untuk mengembangkan layanan microser.
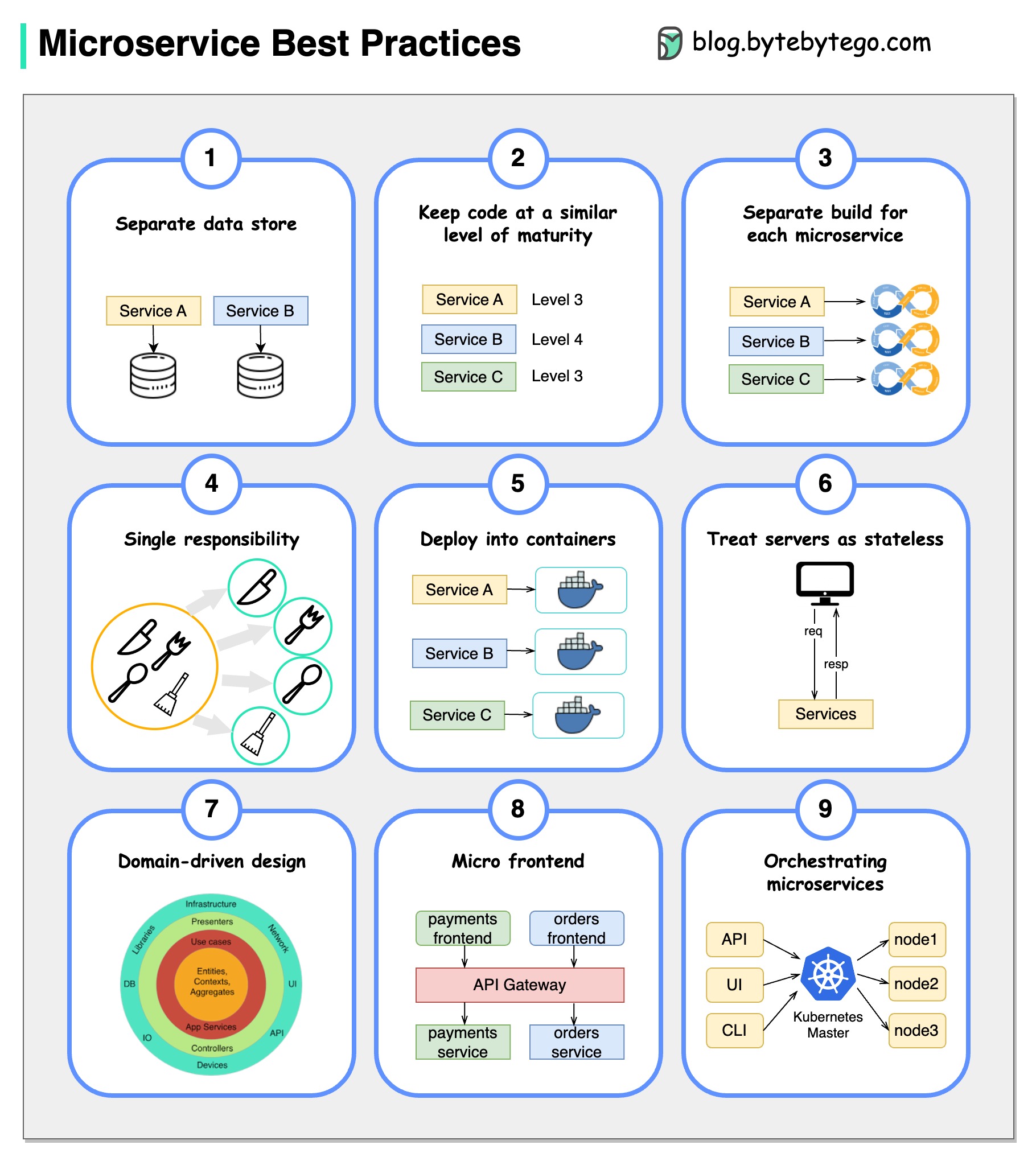
Ketika kami mengembangkan layanan microser, kami perlu mengikuti praktik terbaik berikut:
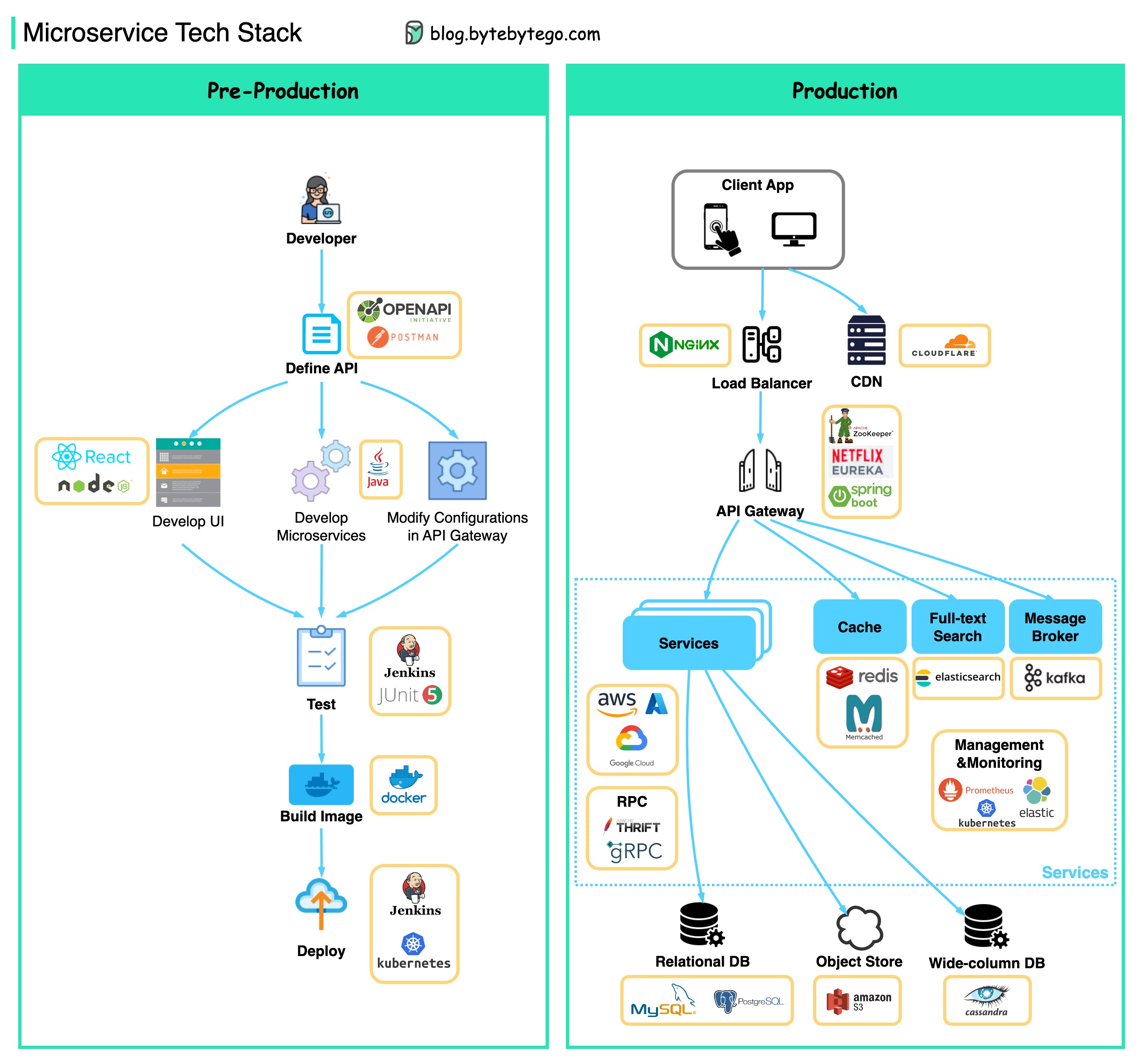
Di bawah ini Anda akan menemukan diagram yang menunjukkan tumpukan teknologi Microservice, baik untuk fase pengembangan dan untuk produksi.
Ada banyak keputusan desain yang berkontribusi pada kinerja Kafka. Dalam posting ini, kami akan fokus pada dua. Kami pikir keduanya paling berat.
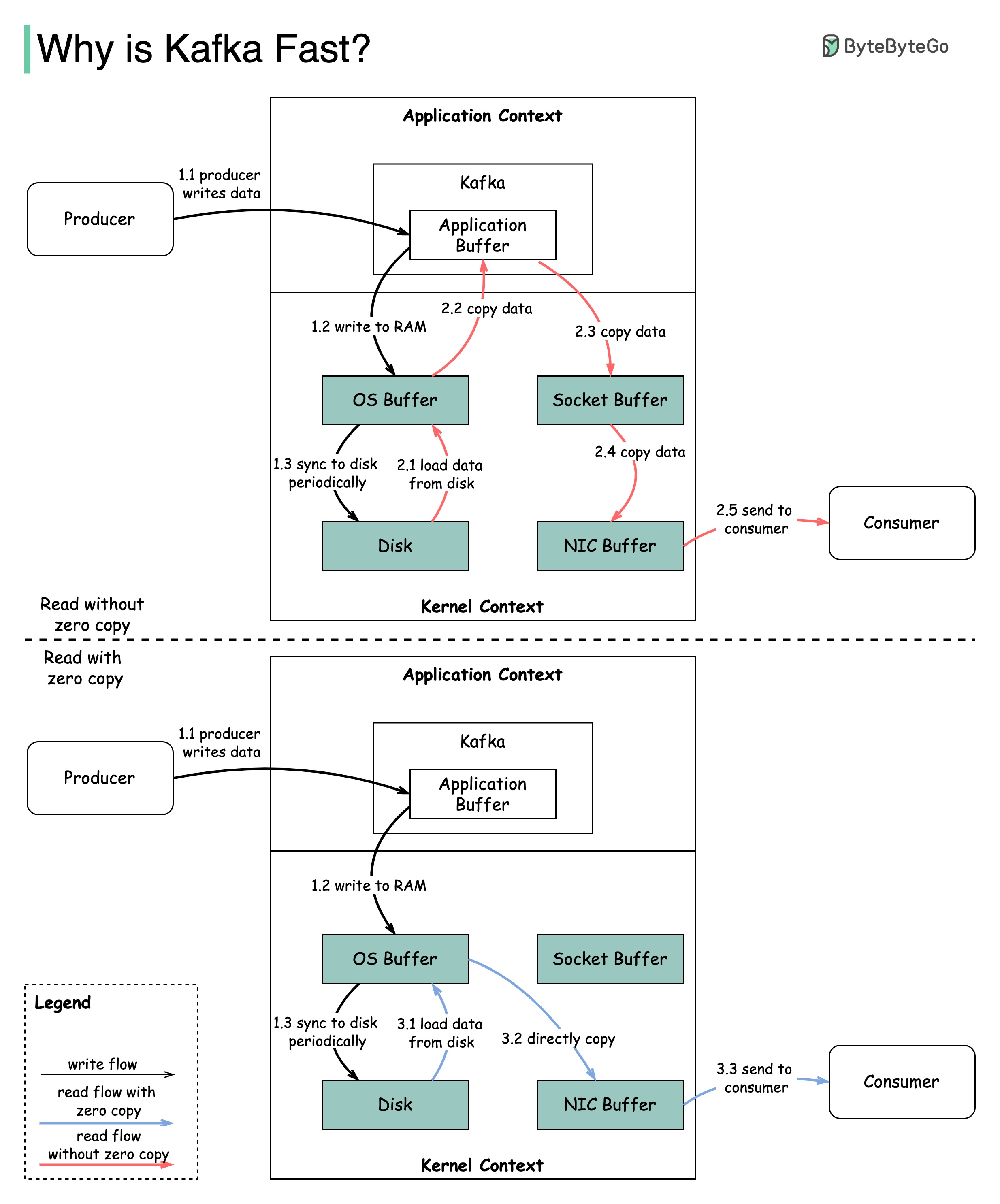
Diagram menggambarkan bagaimana data ditransmisikan antara produsen dan konsumen, dan apa arti nol-copy.
2.1 Data dimuat dari disk ke cache OS
2.2 Data disalin dari OS Cache ke Aplikasi Kafka
2.3 Aplikasi Kafka menyalin data ke dalam buffer soket
2.4 Data disalin dari buffer soket ke kartu jaringan
2.5 Kartu jaringan mengirimkan data ke konsumen
3.1: Data dimuat dari disk ke Cache 3.2 OS Cache secara langsung menyalin data ke kartu jaringan melalui perintah sendFile () 3.3 Kartu jaringan mengirimkan data ke konsumen
Salinan nol adalah jalan pintas untuk menyimpan beberapa salinan data antara konteks aplikasi dan konteks kernel.
Diagram di bawah ini menunjukkan ekonomi aliran pembayaran kartu kredit.
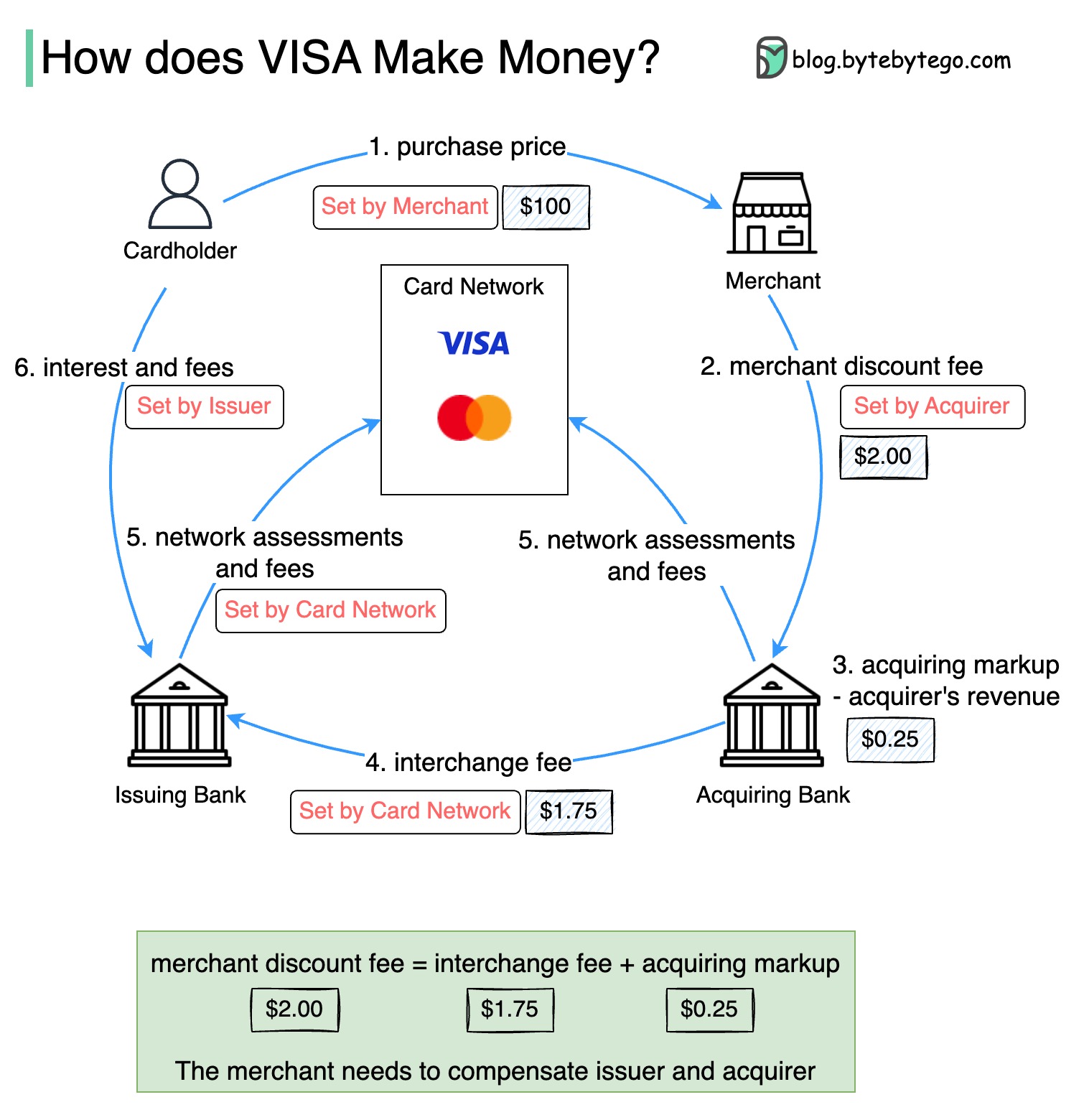
1. Pemegang kartu membayar pedagang $ 100 untuk membeli produk.
2. Pedagang mendapat manfaat dari penggunaan kartu kredit dengan volume penjualan yang lebih tinggi dan perlu mengkompensasi penerbit dan jaringan kartu untuk menyediakan layanan pembayaran. Bank yang mengakuisisi menetapkan biaya dengan pedagang, yang disebut "biaya diskon pedagang."
3 - 4. Bank yang mengakuisisi menyimpan $ 0,25 sebagai markup yang mengakuisisi, dan $ 1,75 dibayarkan kepada bank penerbit sebagai biaya pertukaran. Biaya diskon pedagang harus menutupi biaya pertukaran.
Biaya pertukaran ditetapkan oleh jaringan kartu karena kurang efisien untuk setiap bank penerbit untuk menegosiasikan biaya dengan masing -masing pedagang.
5. Jaringan kartu mengatur penilaian jaringan dan biaya dengan masing -masing bank, yang membayar jaringan kartu untuk layanannya setiap bulan. Misalnya, Visa menagih penilaian 0,11%, ditambah biaya penggunaan $ 0,0195, untuk setiap gesek.
6. Pemegang kartu membayar bank penerbit untuk layanannya.
Mengapa bank penerbit harus dikompensasi?
Visa, MasterCard, dan American Express bertindak sebagai jaringan kartu untuk kliring dan penyelesaian dana. Bank yang mengakuisisi kartu dan bank penerbit kartu dapat - dan sering kali - berbeda. Jika bank menyelesaikan transaksi satu per satu tanpa perantara, masing -masing bank harus menyelesaikan transaksi dengan semua bank lain. Ini cukup tidak efisien.
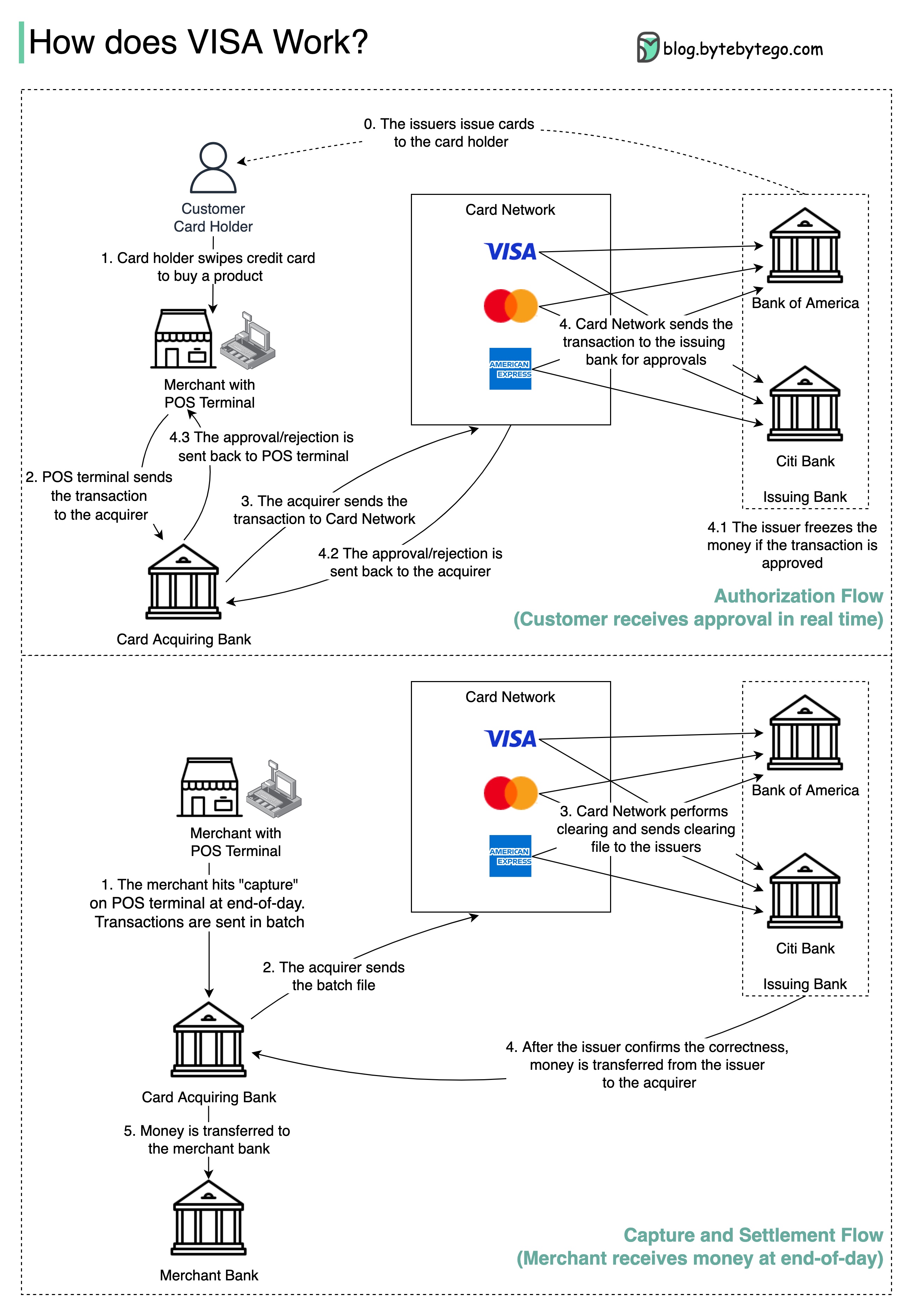
Diagram di bawah ini menunjukkan peran Visa dalam proses pembayaran kartu kredit. Ada dua aliran yang terlibat. Aliran otorisasi terjadi ketika pelanggan menggesek kartu kredit. Aliran penangkapan dan penyelesaian terjadi ketika pedagang ingin mendapatkan uang pada akhir hari.
Langkah 0: Kartu mengeluarkan kartu kredit bank kepada pelanggannya.
Langkah 1: Pemegang kartu ingin membeli produk dan menggesek kartu kredit di terminal Point of Sale (POS) di toko pedagang.
Langkah 2: Terminal POS mengirimkan transaksi ke bank yang mengakuisisi, yang telah menyediakan terminal POS.
Langkah 3 dan 4: Bank yang mengakuisisi mengirimkan transaksi ke jaringan kartu, juga disebut skema kartu. Jaringan kartu mengirimkan transaksi ke bank penerbit untuk disetujui.
Langkah 4.1, 4.2 dan 4.3: Bank penerbit membekukan uang jika transaksi disetujui. Persetujuan atau penolakan dikirim kembali ke pengakuisisi, serta terminal POS.
Langkah 1 dan 2: Pedagang ingin mengumpulkan uang pada akhir hari, jadi mereka menekan "penangkapan" di terminal POS. Transaksi dikirim ke pengakuisisi dalam batch. Acquirer mengirim file batch dengan transaksi ke jaringan kartu.
Langkah 3: Jaringan kartu melakukan kliring untuk transaksi yang dikumpulkan dari pengakuisisi yang berbeda, dan mengirimkan file kliring ke bank penerbit yang berbeda.
Langkah 4: Bank penerbit mengkonfirmasi kebenaran file kliring, dan mentransfer uang ke bank yang mengakuisisi yang relevan.
Langkah 5: Bank yang mengakuisisi kemudian mentransfer uang ke bank pedagang.
Langkah 4: Jaringan kartu menghapus transaksi dari berbagai bank yang mengakuisisi. Kliring adalah proses di mana transaksi offset timbal balik dijaring, sehingga jumlah total transaksi berkurang.
Dalam prosesnya, jaringan kartu menanggung beban berbicara dengan masing -masing bank dan menerima biaya layanan sebagai imbalan.
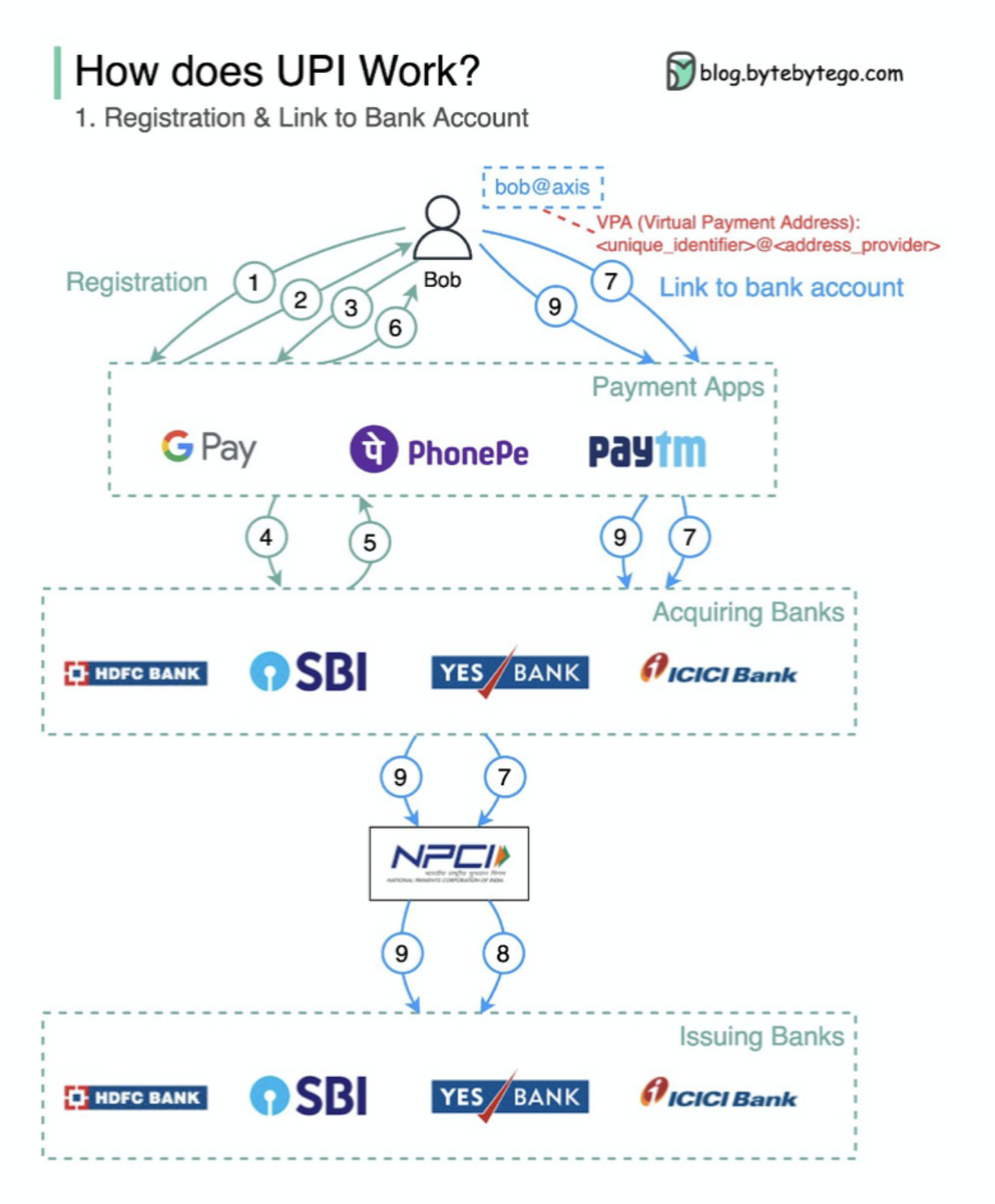
Apa Upi? UPI adalah sistem pembayaran real-time instan yang dikembangkan oleh National Payments Corporation of India.
Ini menyumbang 60% dari transaksi ritel digital di India saat ini.
UPI = Bahasa Markup Pembayaran + Standar untuk Pembayaran Interoperable
Konsep DevOps, SRE, dan Platform Engineering telah muncul pada waktu yang berbeda dan telah dikembangkan oleh berbagai individu dan organisasi.
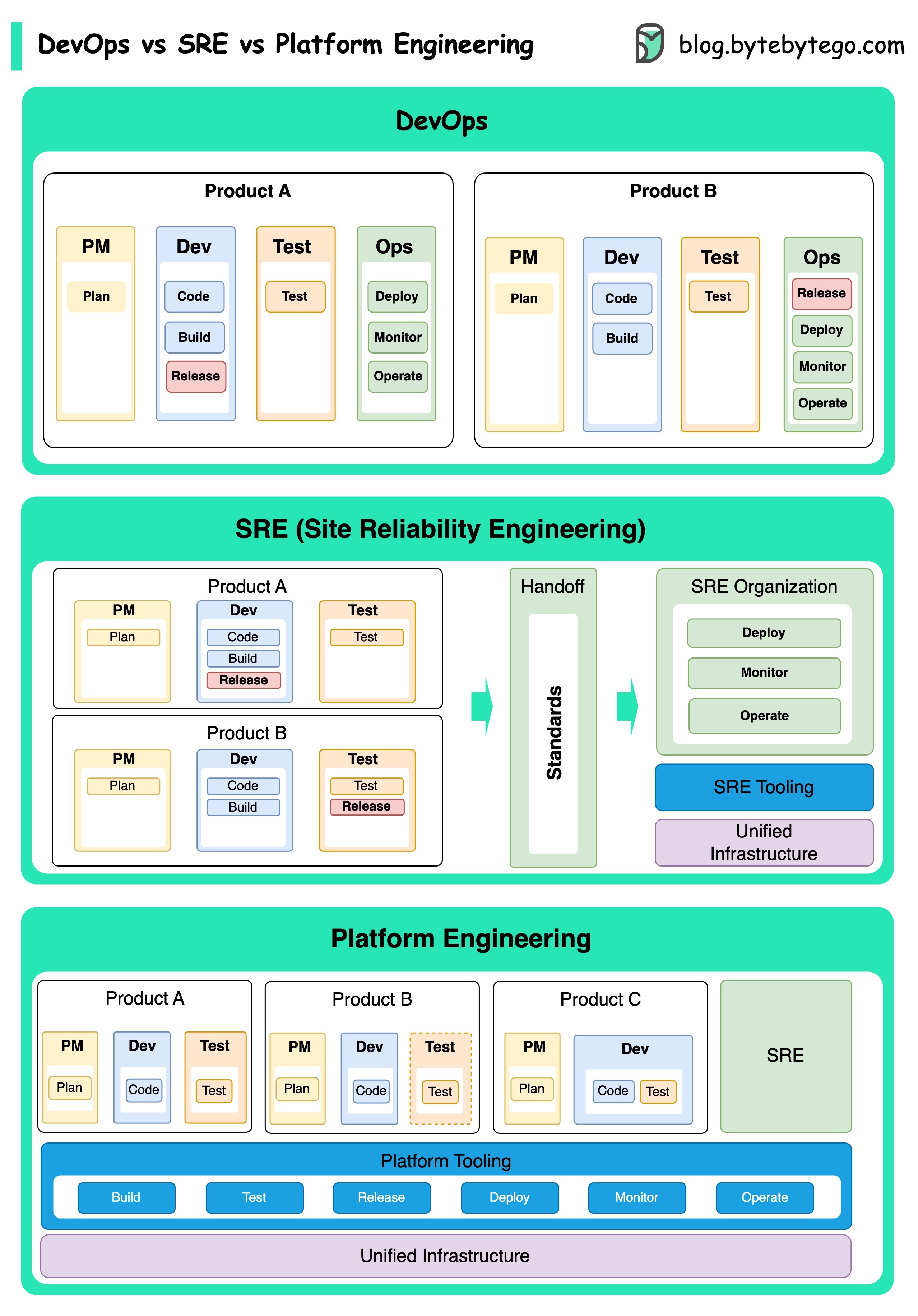
DevOps sebagai sebuah konsep diperkenalkan pada tahun 2009 oleh Patrick DeBois dan Andrew Shafer di The Agile Conference. Mereka berusaha menjembatani kesenjangan antara pengembangan perangkat lunak dan operasi dengan mempromosikan budaya kolaboratif dan berbagi tanggung jawab untuk seluruh siklus pengembangan perangkat lunak.
SRE, atau rekayasa reliabilitas situs, dipelopori oleh Google pada awal 2000-an untuk mengatasi tantangan operasional dalam mengelola sistem skala besar dan kompleks. Google mengembangkan praktik dan alat SRE, seperti Sistem Manajemen Cluster Borg dan Sistem Pemantauan Monarch, untuk meningkatkan keandalan dan efisiensi layanan mereka.
Platform Engineering adalah konsep yang lebih baru, membangun fondasi rekayasa SRE. Asal usul rekayasa platform yang tepat kurang jelas, tetapi umumnya dipahami sebagai perpanjangan dari praktik DevOps dan SRE, dengan fokus pada memberikan platform komprehensif untuk pengembangan produk yang mendukung seluruh perspektif bisnis.
Perlu dicatat bahwa sementara konsep -konsep ini muncul pada waktu yang berbeda. Mereka semua terkait dengan tren yang lebih luas dalam meningkatkan kolaborasi, otomatisasi, dan efisiensi dalam pengembangan dan operasi perangkat lunak.
K8S adalah sistem orkestrasi kontainer. Ini digunakan untuk penyebaran dan manajemen kontainer. Desainnya sangat dipengaruhi oleh sistem internal Google Borg.
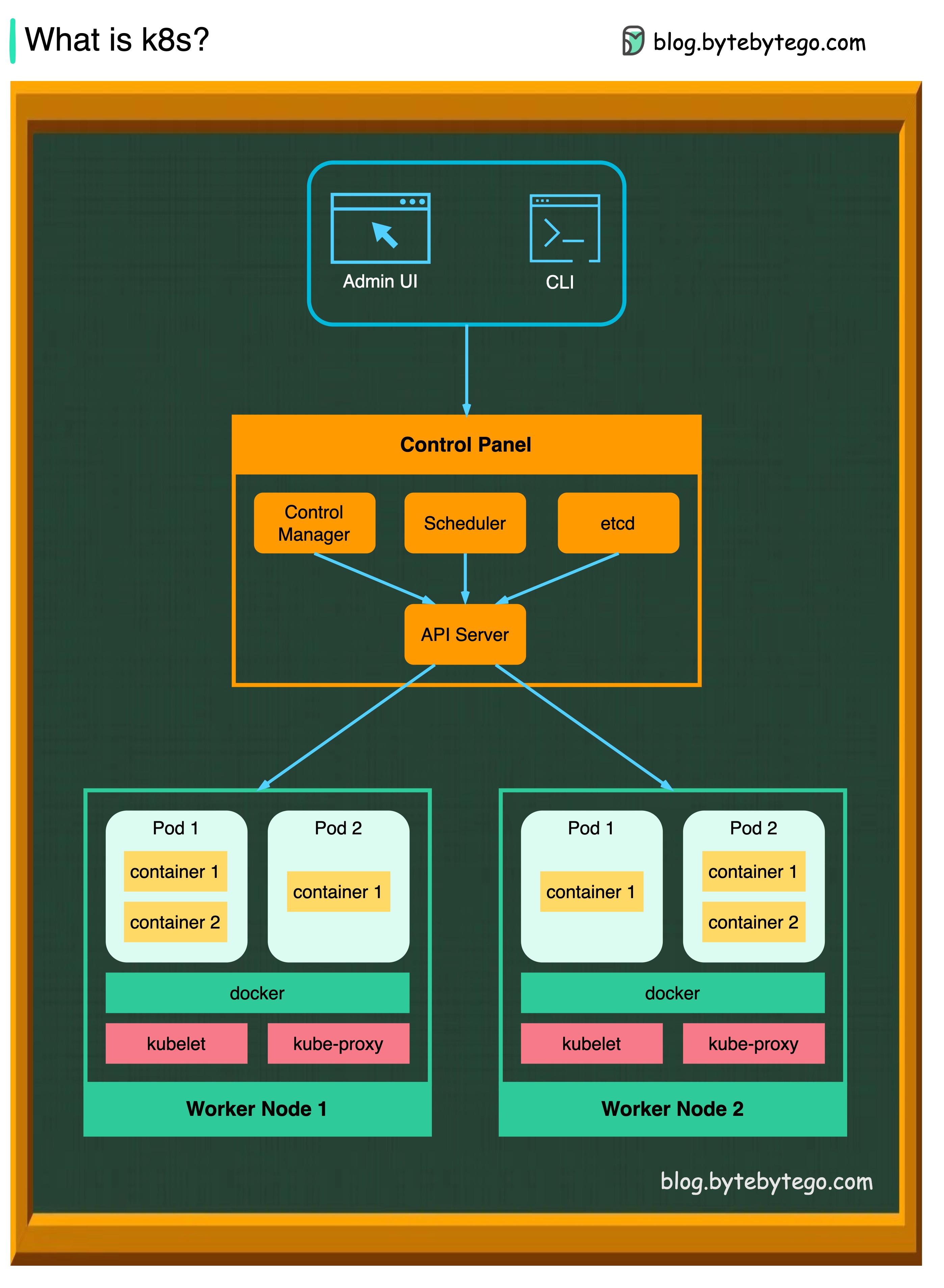
Cluster K8S terdiri dari satu set mesin pekerja, yang disebut node, yang menjalankan aplikasi yang dikemas. Setiap cluster memiliki setidaknya satu simpul pekerja.
Node pekerja meng -host pod yang merupakan komponen dari beban kerja aplikasi. Pesawat kontrol mengelola node pekerja dan polong di cluster. Di lingkungan produksi, bidang kontrol biasanya berjalan di beberapa komputer, dan cluster biasanya menjalankan banyak node, memberikan toleransi kesalahan dan ketersediaan tinggi.
Server API
Server API berbicara dengan semua komponen di kluster K8S. Semua operasi pada pod dieksekusi dengan berbicara dengan server API.
Penjadwal
Penjadwal mengawasi beban kerja pod dan memberikan muatan pada pod yang baru dibuat.
Manajer Pengontrol
Manajer pengontrol menjalankan pengontrol, termasuk pengontrol simpul, pengontrol pekerjaan, pengontrol endpointslice, dan pengontrol serviceaccount.
Dll
ETCD adalah toko nilai kunci yang digunakan sebagai toko dukungan Kubernetes untuk semua data cluster.
Polong
Pod adalah sekelompok wadah dan merupakan unit terkecil yang dikelola K8S. POD memiliki alamat IP tunggal yang diterapkan pada setiap wadah di dalam pod.
Kubelet
Agen yang berjalan pada setiap node di cluster. Ini memastikan wadah berjalan di pod.
Proxy Kube
Kube-Proxy adalah proxy jaringan yang berjalan pada setiap node di cluster Anda. Rute lalu lintas masuk ke simpul dari layanan. Ini meneruskan permintaan kerja ke wadah yang benar.

Apa itu Docker?
Docker adalah platform open-source yang memungkinkan Anda untuk mengemas, mendistribusikan, dan menjalankan aplikasi dalam wadah yang terisolasi. Ini berfokus pada kontainerisasi, menyediakan lingkungan ringan yang merangkum aplikasi dan ketergantungannya.
Apa itu Kubernetes?
Kubernetes, sering disebut sebagai K8s, adalah platform orkestrasi kontainer open-source. Ini menyediakan kerangka kerja untuk mengotomatisasi penyebaran, penskalaan, dan pengelolaan aplikasi yang dimasukkan di seluruh sekelompok node.
Apa bedanya keduanya satu sama lain?
Docker: Docker beroperasi di tingkat kontainer individu pada host sistem operasi tunggal.
Anda harus mengelola setiap host secara manual dan menyiapkan jaringan, kebijakan keamanan, dan penyimpanan untuk berbagai wadah terkait bisa rumit.
Kubernetes: Kubernetes beroperasi di level cluster. Ia mengelola beberapa aplikasi yang dikemas di beberapa host, menyediakan otomatisasi untuk tugas -tugas seperti penyeimbangan beban, penskalaan, dan memastikan keadaan aplikasi yang diinginkan.
Singkatnya, Docker berfokus pada kontainerisasi dan menjalankan kontainer pada host individual, sementara Kubernetes mengkhususkan diri dalam mengelola dan mengatur kontainer pada skala di seluruh sekelompok host.
Diagram di bawah ini menunjukkan arsitektur Docker dan cara kerjanya ketika kita menjalankan "Docker Build", "Docker Pull" dan "Docker Run".
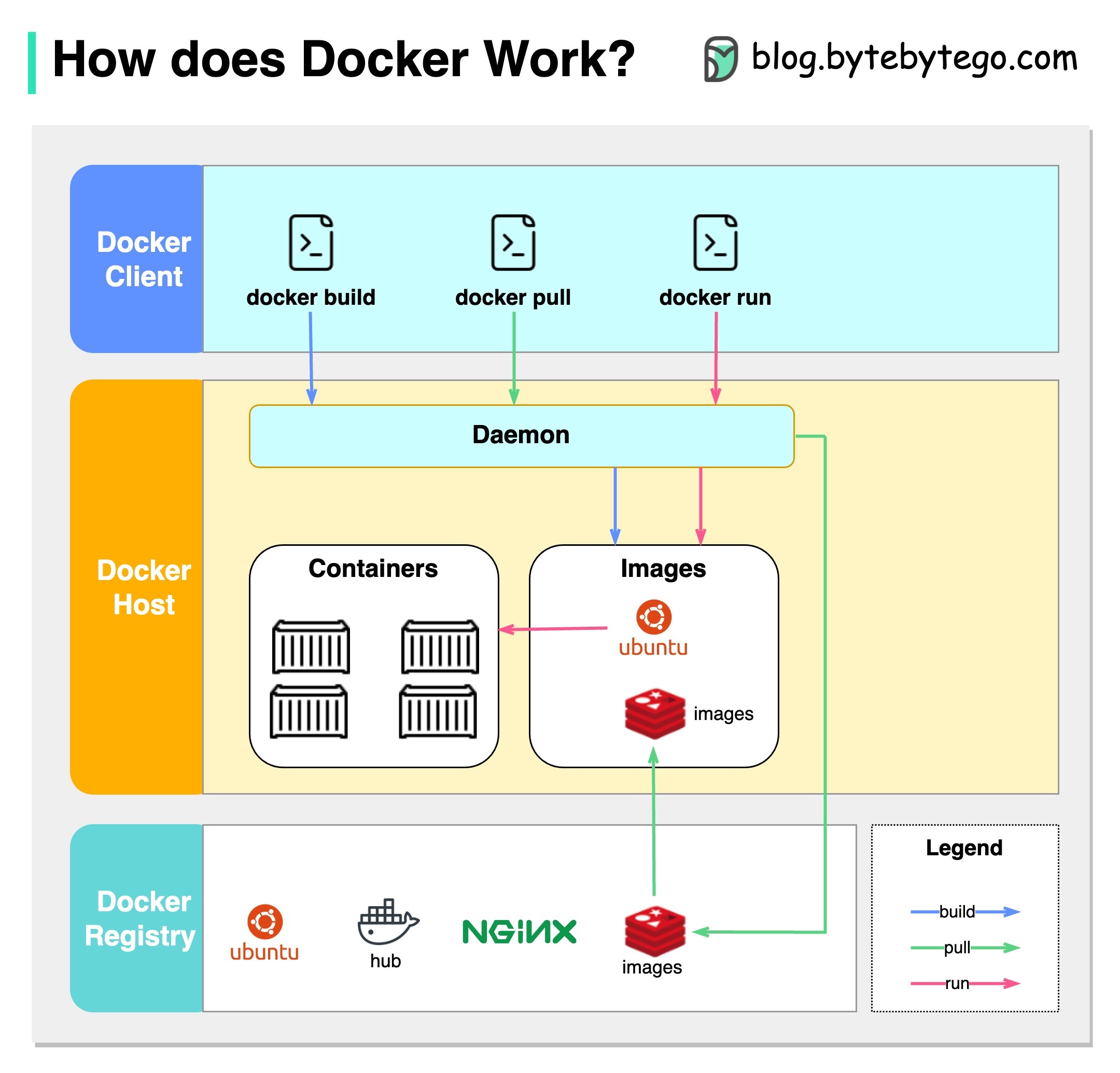
Ada 3 komponen dalam arsitektur Docker:
Klien Docker
Klien Docker berbicara dengan Docker Daemon.
Host Docker
Docker Daemon mendengarkan permintaan Docker API dan mengelola objek Docker seperti gambar, wadah, jaringan, dan volume.
Docker Registry
Registry Docker menyimpan gambar Docker. Docker Hub adalah pendaftaran publik yang dapat digunakan siapa pun.
Mari kita ambil perintah "Docker Run" sebagai contoh.
Untuk mulai dengan, penting untuk mengidentifikasi di mana kode kami disimpan. Asumsi umum adalah bahwa hanya ada dua lokasi - satu di server jarak jauh seperti GitHub dan yang lainnya di mesin lokal kami. Namun, ini tidak sepenuhnya akurat. Git memelihara tiga penyimpanan lokal di mesin kami, yang berarti bahwa kode kami dapat ditemukan di empat tempat:
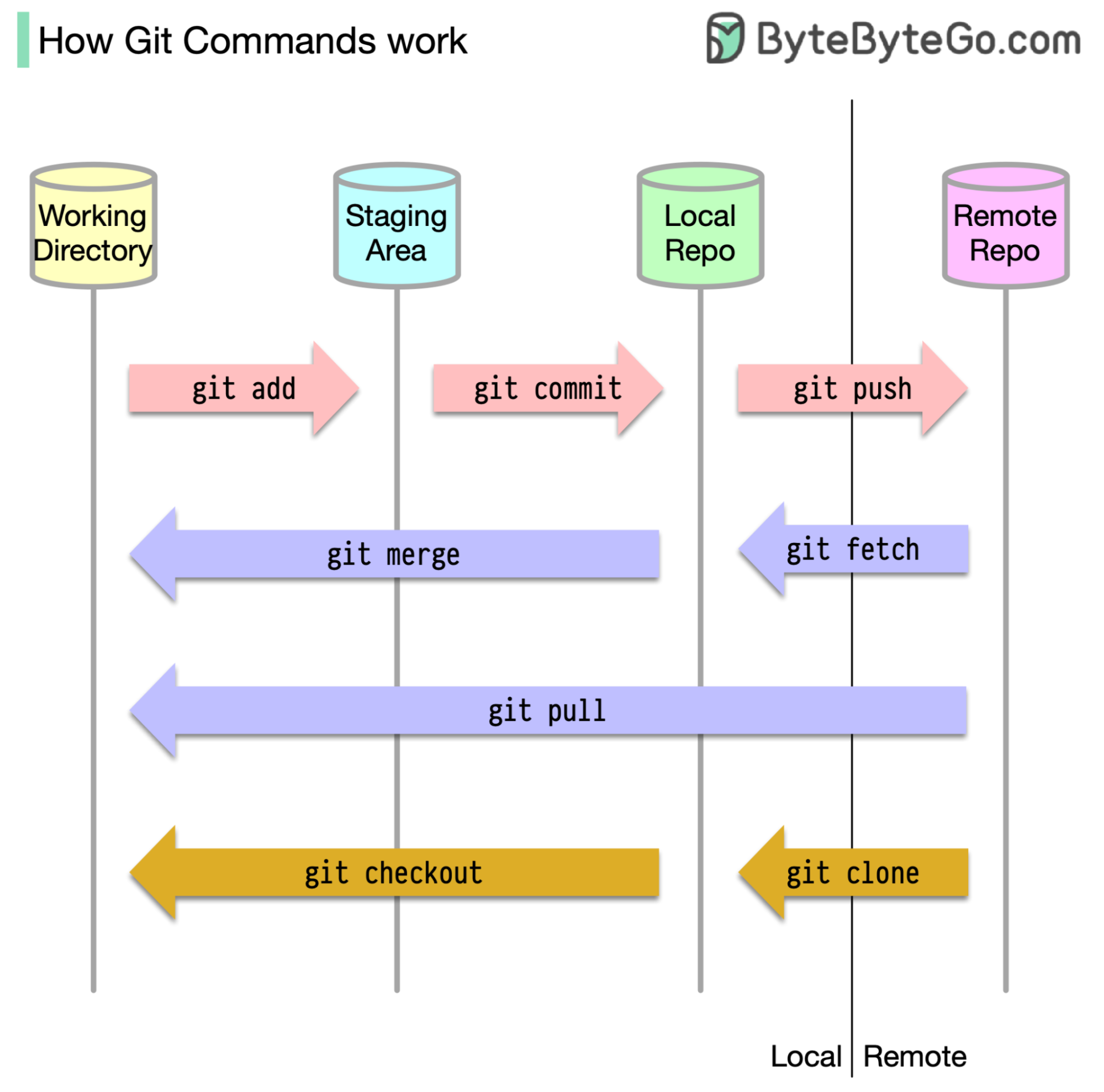
Sebagian besar perintah Git terutama memindahkan file antara keempat lokasi ini.
Diagram di bawah ini menunjukkan alur kerja Git.
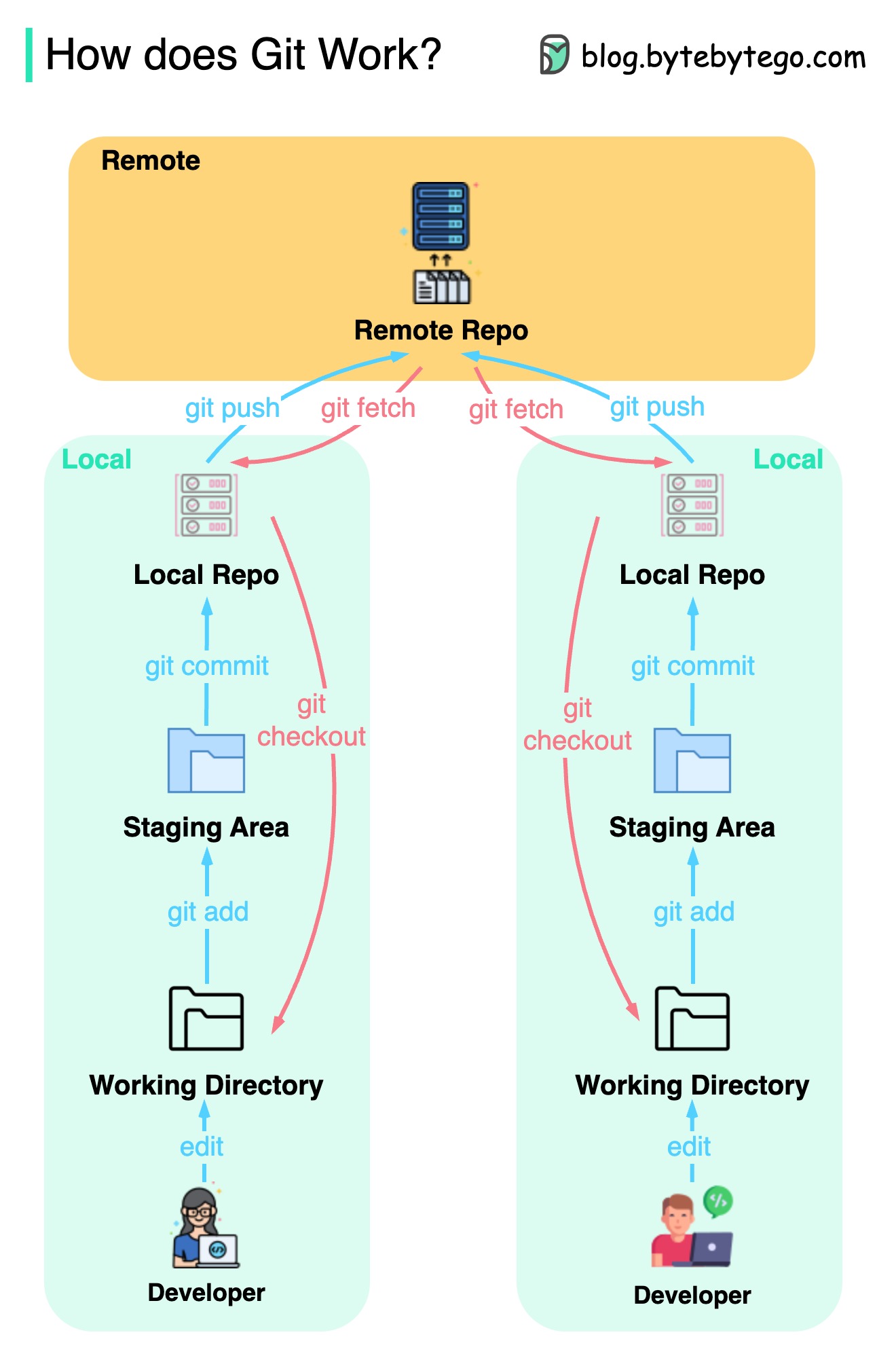
Git adalah sistem kontrol versi terdistribusi.
Setiap pengembang memelihara salinan lokal dari repositori utama dan mengedit serta berkomitmen pada salinan lokal.
Komit ini sangat cepat karena operasi tidak berinteraksi dengan repositori jarak jauh.
Jika repositori jarak jauh macet, file dapat dipulihkan dari repositori lokal.
Apa perbedaannya?


