SOLIDER
1.0.0

Selamat datang di SOLIDER ! SOLIDER adalah Kerangka Pembelajaran Pengawasan Mandiri Terkendali Semantik untuk mempelajari representasi umum manusia dari gambar manusia besar yang tidak diberi label yang dapat memberikan manfaat maksimal pada tugas-tugas hilir yang berpusat pada manusia. Berbeda dengan metode pembelajaran mandiri yang ada, pengetahuan sebelumnya dari gambar manusia digunakan di SOLIDER untuk membangun label semantik semu dan mengimpor lebih banyak informasi semantik ke dalam representasi yang dipelajari. Sementara itu, tugas hilir yang berbeda selalu memerlukan rasio informasi semantik dan informasi tampilan yang berbeda, dan satu representasi yang dipelajari tidak dapat memenuhi semua persyaratan. Untuk mengatasi masalah ini, SOLIDER memperkenalkan jaringan bersyarat dengan pengontrol semantik, yang dapat memenuhi berbagai kebutuhan tugas hilir. Untuk lebih jelasnya, silakan lihat makalah kami Beyond Appearance: Kerangka Pembelajaran yang Diawasi Sendiri yang Dapat Dikendalikan Semantik untuk Tugas Visual yang Berpusat pada Manusia.
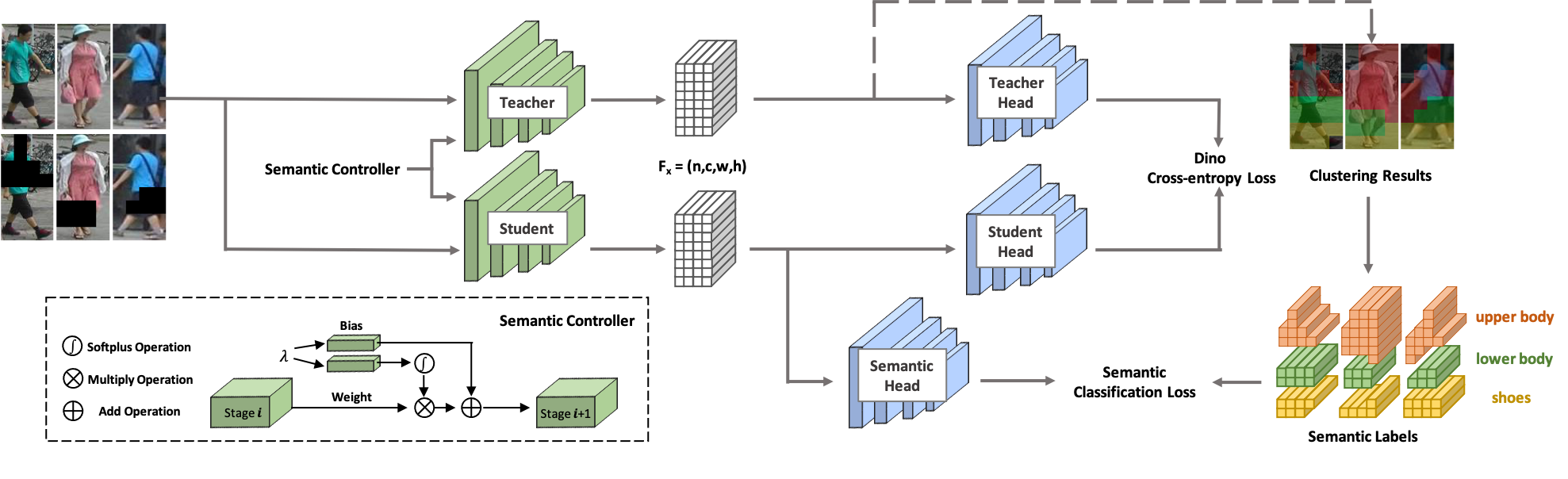
Basis kode ini telah dikembangkan dengan python versi 3.7, PyTorch versi 1.7.1, CUDA 10.1 dan torchvision 0.8.2.
Kami menggunakan LUPerson sebagai data pelatihan kami, yang terdiri dari gambar manusia tanpa label. Unduh LUPerson dari tautan resminya dan unzip.
sh run_solider.shsh run_dino.sh
sh resume_solider.shTerdapat demo untuk menjalankan model SOLIDER terlatih, yang dapat disematkan ke dalam inferensi atau penyempurnaan tugas hilir.
python demo.pyKami menggunakan Swin-Transformer sebagai tulang punggung kami, yang menunjukkan keuntungan besar pada banyak tugas CV.
| Tugas | Kumpulan data | Babi Kecil (Link) | Berputar Kecil (Link) | Pangkalan Babi (Link) |
|---|---|---|---|---|
| Identifikasi Ulang Orang (mAP/R1) tanpa melakukan pemeringkatan ulang | Pasar1501 | 91.6/96.1 | 93.3/96.6 | 93.9/96.9 |
| MSMT17 | 67.4/85.9 | 76.9/90.8 | 77.1/90.7 | |
| Identifikasi Ulang Orang (mAP/R1) dengan pemeringkatan ulang | Pasar1501 | 95.3/96.6 | 95.4/96.4 | 95.6/96.7 |
| MSMT17 | 81.5/89.2 | 86.5/91.7 | 86.5/91.7 | |
| Pengenalan Atribut (mA) | PETA_ZS | 74.37 | 76.21 | 76.43 |
| RAP_ZS | 74.23 | 75,95 | 76.42 | |
| PA100K | 84.14 | 86.25 | 86.37 | |
| Pencarian Orang (mAP/R1) | CUHK-SYSU | 94.9/95.7 | 95,5/95,8 | 94.9/95.5 |
| PRW | 56.8/86.8 | 59.8/86.7 | 59.7/86.8 | |
| Deteksi Pejalan Kaki (MR-2) | Orang Kota | 10.3/40.8 | 10.0/39.2 | 9.7/39.4 |
| Penguraian Manusia (mIOU) | BIBIR | 57.52 | 60.21 | 60,50 |
| Estimasi Pose (AP/AR) | KELAPA | 74.4/79.6 | 76.3/81.3 | 76.6/81.5 |
Implementasi kami terutama didasarkan pada basis kode berikut. Kami berterima kasih kepada para penulis atas karya luar biasa mereka.
Jika Anda menggunakan SOLIDER dalam penelitian Anda, harap mengutip karya kami dengan menggunakan entri BibTeX berikut:
@inproceedings{chen2023beyond,
title={Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks},
author={Weihua Chen and Xianzhe Xu and Jian Jia and Hao Luo and Yaohua Wang and Fan Wang and Rong Jin and Xiuyu Sun},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023},
}


