visual chatgpt
1.0.0
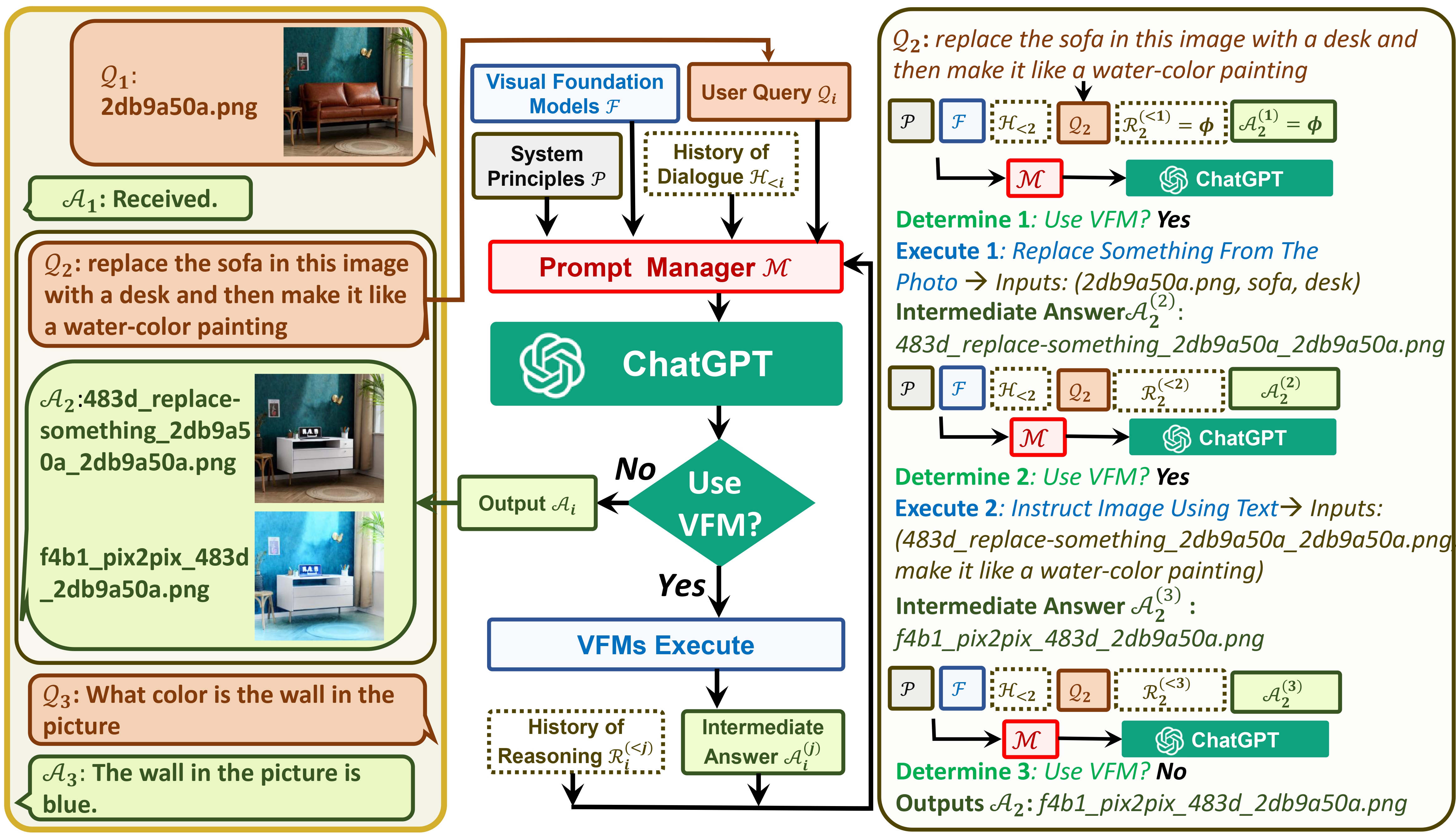
Visual ChatGPT menghubungkan ChatGPT dan serangkaian Model Visual Foundation untuk memungkinkan pengiriman dan penerimaan gambar selama mengobrol.
Lihat makalah kami: Obrolan VisualGPT: Berbicara, Menggambar, dan Mengedit dengan Model Visual Foundation
Di satu sisi, ChatGPT (atau LLM) berfungsi sebagai antarmuka umum yang memberikan pemahaman luas dan beragam tentang berbagai topik. Di sisi lain, Model Fondasi berfungsi sebagai pakar domain dengan memberikan pengetahuan mendalam pada domain tertentu. Dengan memanfaatkan pengetahuan umum dan mendalam , kami bertujuan membangun AI yang mampu menangani berbagai tugas.

# clone the repo
git clone https://github.com/microsoft/visual-chatgpt.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start Visual ChatGPT !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are sperated by underline '_', the different models are seperated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,ImageEditing_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
Di sini kami mencantumkan penggunaan memori GPU dari setiap model landasan visual, Anda dapat menentukan mana yang Anda suka:
| Model Fondasi | Memori GPU (MB) |
|---|---|
| Pengeditan Gambar | 3981 |
| InstruksikanPix2Pix | 2827 |
| Teks2Gambar | 3385 |
| Keterangan Gambar | 1209 |
| Gambar 2 Cerdik | 0 |
| CannyText2Image | 3531 |
| Gambar2Garis | 0 |
| LineText2Image | 3529 |
| Gambar2Hed | 0 |
| Gambar HedText2 | 3529 |
| Gambar2Coretan | 0 |
| ScribbleText2Image | 3531 |
| Gambar2Pose | 0 |
| PoseText2Image | 3529 |
| Gambar2Seg | 919 |
| SegText2Image | 3529 |
| Kedalaman Gambar2 | 0 |
| KedalamanTeks2Gambar | 3531 |
| Gambar2Normal | 0 |
| NormalTeks2Gambar | 3529 |
| VisualQuestionAnswering | 1495 |
Kami menghargai open source dari proyek-proyek berikut:
Memeluk Wajah LangChain Stabil Difusi ControlNet InstructPix2Pix CLIPSeg BLIP
Untuk bantuan atau masalah dalam menggunakan Visual ChatGPT, silakan kirimkan masalah GitHub.
Untuk komunikasi lainnya, silakan hubungi Chenfei WU ([email protected]) atau Nan DUAN ([email protected]).


