PixArt alpha
1.0.0
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txtSemua model akan diunduh secara otomatis. Anda juga dapat memilih untuk mengunduh secara manual dari url ini.
| Model | #Param | url | Unduh di OpenXLab |
|---|---|---|---|
| T5 | 4.3B | T5 | T5 |
| VAE | 80M | VAE | VAE |
| PixArt-α-SAM-256 | 0,6B | PixArt-XL-2-SAM-256x256.pth atau versi diffuser | 256-SAM |
| PixArt-α-256 | 0,6B | PixArt-XL-2-256x256.pth atau versi diffuser | 256 |
| PixArt-α-256-MSCOCO-FID7.32 | 0,6B | PixArt-XL-2-256x256.pth | 256 |
| PixArt-α-512 | 0,6B | PixArt-XL-2-512x512.pth atau versi diffuser | 512 |
| PixArt-α-1024 | 0,6B | PixArt-XL-2-1024-MS.pth atau versi diffuser | 1024 |
| PixArt-δ-1024-LCM | 0,6B | versi diffuser | |
| ControlNet-HED-Encoder | 30M | KontrolNetHED.pth | |
| PixArt-δ-512-ControlNet | 0,9B | PixArt-XL-2-512-ControlNet.pth | 512 |
| PixArt-δ-1024-ControlNet | 0,9B | PixArt-XL-2-1024-ControlNet.pth | 1024 |
JUGA temukan semua model di OpenXLab_PixArt-alpha
Pertama.
Berkat @kopyl, Anda dapat mereproduksi alur pelatihan penyempurnaan penuh pada kumpulan data Pokemon dari HugginFace dengan buku catatan:
Lalu, untuk lebih jelasnya.
Di sini kami mengambil konfigurasi pelatihan kumpulan data SAM sebagai contoh, tetapi tentu saja, Anda juga dapat menyiapkan kumpulan data Anda sendiri dengan mengikuti metode ini.
Anda HANYA perlu mengubah file konfigurasi di config dan dataloader di dataset.
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256Struktur direktori untuk dataset SAM adalah:
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
Disini kami menyiapkan data_toy untuk pemahaman yang lebih baik
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toyKemudian, Berikut adalah contoh file partisi/part0.txt.
Selain itu, untuk pelatihan terpandu file json, berikut adalah file json mainan untuk pemahaman yang lebih baik.
Mengikuti panduan pelatihan Pixart + DreamBooth
Mengikuti panduan pelatihan PixArt + LCM
Mengikuti panduan pelatihan PixArt + ControlNet
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision= " fp16 "
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column= " text "
--resolution=1024 --random_flip
--train_batch_size=16
--num_train_epochs=200 --checkpointing_steps=100
--learning_rate=1e-06 --lr_scheduler= " constant " --lr_warmup_steps=0
--seed=42
--output_dir= " pixart-pokemon-model "
--validation_prompt= " cute dragon creature " --report_to= " tensorboard "
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5
--rank=16 Inferensi memerlukan setidaknya 23GB memori GPU untuk menggunakan repo ini, sedangkan 11GB and 8GB menggunakan ? diffuser.
Saat ini dukungan:
Untuk memulai, instal dulu dependensi yang diperlukan. Pastikan Anda telah mengunduh model ke folder output/pretrained_models, lalu menjalankannya di mesin lokal Anda:
DEMO_PORT=12345 python app/app.pySebagai alternatif, contoh Dockerfile disediakan untuk membuat container runtime yang memulai aplikasi Gradio.
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v < path_to_huggingface_cache > :/root/.cache/huggingface pixartAtau gunakan komposisi buruh pelabuhan. Catatan, jika Anda ingin mengubah konteks dari aplikasi versi 1024 ke 512 atau LCM, cukup ubah variabel env APP_CONTEXT di file docker-compose.yml. Standarnya adalah 1024
docker compose build
docker compose up Mari kita lihat contoh sederhana menggunakan http://your-server-ip:12345 .
Pastikan Anda memiliki versi terbaru dari perpustakaan berikut:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4Kemudian:
import torch
from diffusers import PixArtAlphaPipeline , ConsistencyDecoderVAE , AutoencoderKL
device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline . from_pretrained ( "PixArt-alpha/PixArt-XL-2-1024-MS" , torch_dtype = torch . float16 , use_safetensors = True )
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe . to ( device )
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe ( prompt ). images [ 0 ]
image . save ( "./catcus.png" )Lihat dokumentasi untuk informasi lebih lanjut tentang SA-Solver Sampler.
Integrasi ini memungkinkan menjalankan pipeline dengan ukuran batch 4 di bawah 11 GB GPU VRAM. Lihat dokumentasi untuk mempelajari lebih lanjut.
PixArtAlphaPipeline dalam VRAM GPU di bawah 8 GBKonsumsi GPU VRAM di bawah 8 GB saat ini didukung, silakan lihat dokumentasi untuk informasi lebih lanjut.
Untuk memulai, pertama-tama instal dependensi yang diperlukan, lalu jalankan di mesin lokal Anda:
# diffusers version
DEMO_PORT=12345 python app/app.py Mari kita lihat contoh sederhana menggunakan http://your-server-ip:12345 .
Anda juga dapat mengklik di sini untuk mendapatkan uji coba gratis di Google Colab.
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True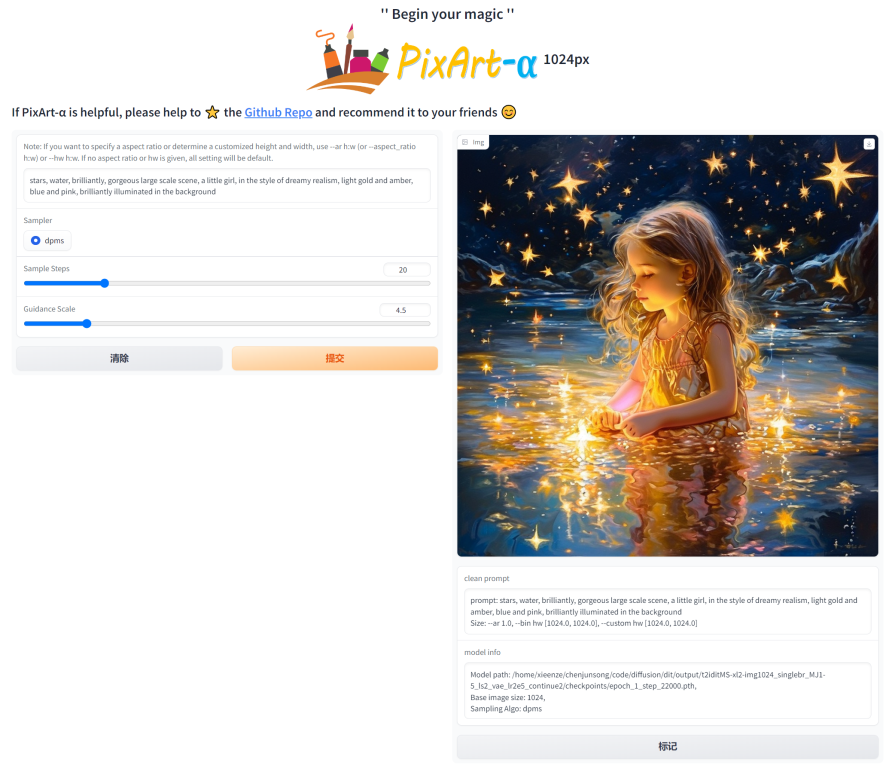
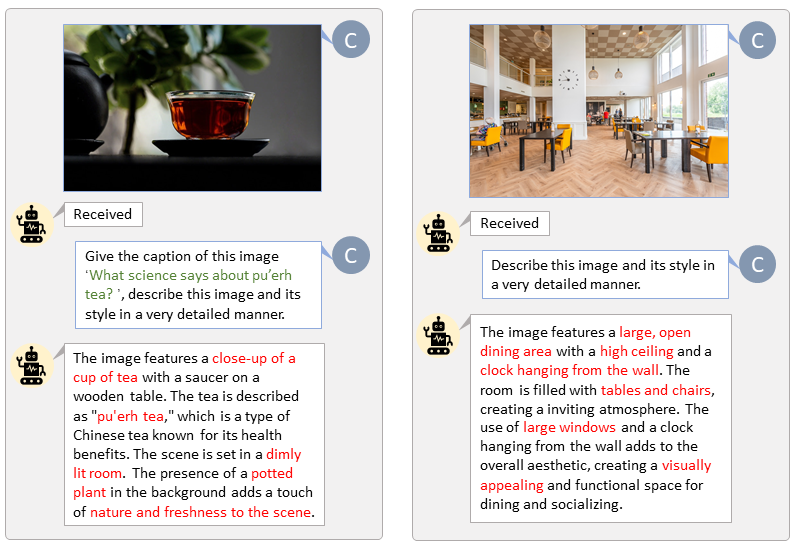
Berkat basis kode LLaVA-Lightning-MPT, kami dapat memberi teks pada kumpulan data LAION dan SAM dengan kode peluncuran berikut:
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.jsonKami menyajikan pelabelan otomatis dengan petunjuk khusus untuk LAION (kiri) dan SAM (kanan). Kata-kata yang disorot dengan warna hijau mewakili teks asli di LAION, sedangkan kata-kata yang ditandai dengan warna merah menunjukkan detail teks yang diberi label oleh LLaVA.
Mempersiapkan fitur teks T5 dan fitur gambar VAE terlebih dahulu akan mempercepat proses pelatihan dan menghemat memori GPU.
python tools/extract_features.py --img_size=1024
--json_path " data/data_info.json "
--t5_save_root " data/SA1B/caption_feature_wmask "
--vae_save_root " data/SA1B/img_vae_features "
--pretrained_models_dir " output/pretrained_models "
--dataset_root " data/SA1B/Images/ " Kami membuat video yang membandingkan PixArt dengan model Text-to-Image paling canggih saat ini.
@misc{chen2023pixartalpha,
title={PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


