safe rlhf
1.0.0
Beaver adalah kerangka kerja RLHF sumber terbuka yang sangat modular yang dikembangkan oleh tim PKU-Alignment di Universitas Peking. Hal ini bertujuan untuk menyediakan data pelatihan dan saluran kode yang dapat direproduksi untuk penelitian penyelarasan, khususnya penelitian LLM penyelarasan terbatas melalui metode RLHF Aman.
Fitur utama Berang-berang adalah:
2024/06/13 : Kami dengan bangga mengumumkan sumber terbuka kumpulan data PKU-SafeRLHF versi 1.0. Rilis ini lebih maju dari versi beta awal dengan menggabungkan anotasi gabungan manusia-AI, memperluas cakupan kategori bahaya, dan memperkenalkan label tingkat keparahan yang terperinci. Untuk detail dan akses lebih lanjut, silakan kunjungi halaman kumpulan data kami di ? Memeluk Wajah: PKU-Alignment/PKU-SafeRLHF.2024/01/16 : Metode kami RLHF Aman telah diterima oleh ICLR 2024 Spotlight.2023/10/19 : Kami telah merilis makalah RLHF Aman di arXiv, yang merinci algoritma penyelarasan aman baru kami dan implementasinya.2023/07/10 : Kami dengan senang hati mengumumkan open source model Beaver-7B v1 / v2 / v3 sebagai tonggak pertama dari seri pelatihan Safe RLHF, dilengkapi dengan Model Hadiah v1 / v2 / v3 / terpadu yang sesuai dan Model Biaya v1 / v2 / v3 / pos pemeriksaan terpadu aktif? Memeluk Wajah.2023/07/10 : Kami memperluas kumpulan data preferensi keamanan sumber terbuka, PKU-Alignment/PKU-SafeRLHF , yang kini berisi lebih dari 300 ribu contoh. (Lihat juga bagian PKU-SafeRLHF-Dataset)2023/07/05 : Kami meningkatkan dukungan kami untuk model pra-pelatihan Tiongkok dan memasukkan kumpulan data sumber terbuka Tiongkok tambahan. (Lihat juga bagian Dukungan Tiongkok (中文支持) dan Kumpulan Data Khusus (自定义数据集))2023/05/15 : Rilis pertama pipeline Safe RLHF, hasil evaluasi, dan kode pelatihan.Pembelajaran Penguatan dari Umpan Balik Manusia: pemaksimalan penghargaan melalui pembelajaran preferensi
Pembelajaran Penguatan yang Aman dari Umpan Balik Manusia: pemaksimalan penghargaan yang dibatasi melalui pembelajaran preferensi
Di mana
Tujuan utamanya adalah menemukan model
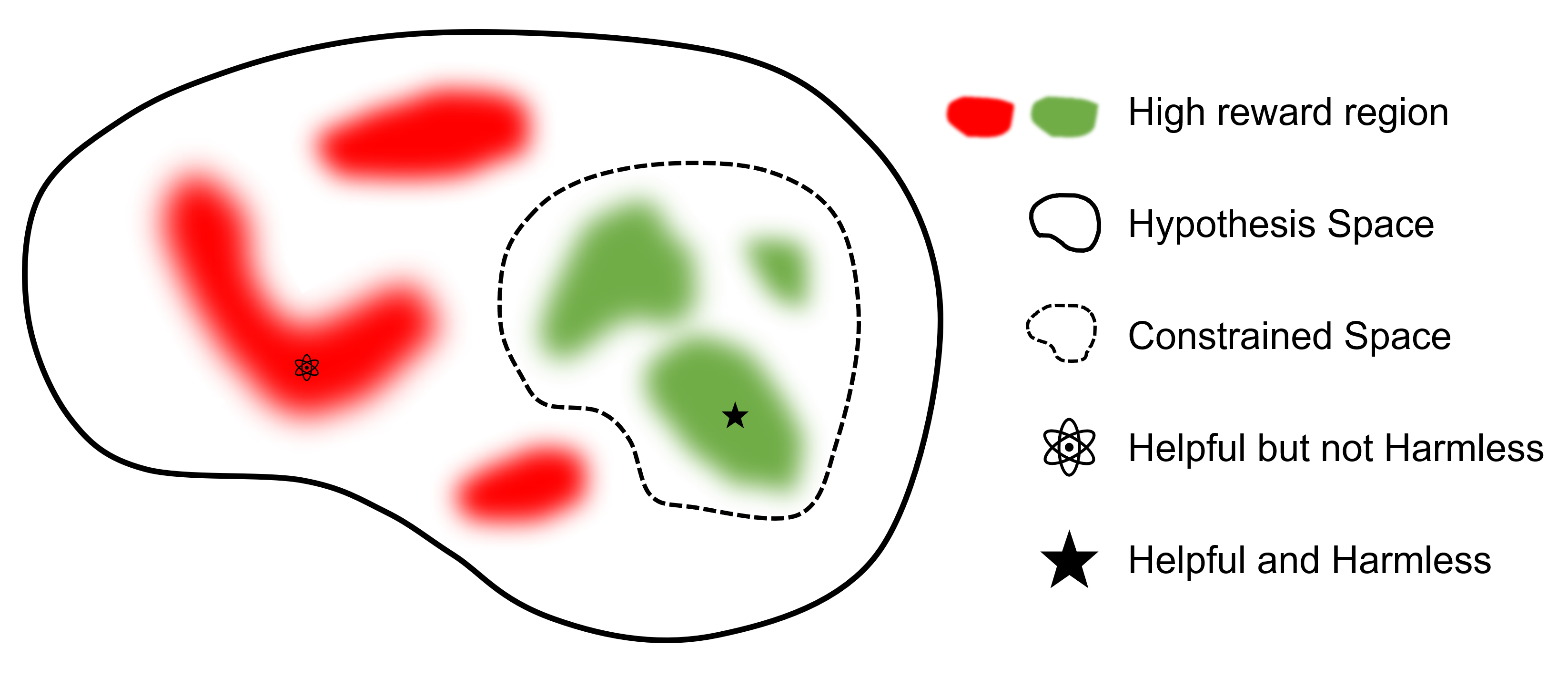
Dibandingkan dengan framework lain yang mendukung RLHF, safe-rlhf adalah framework pertama yang mendukung semua tahapan mulai dari SFT hingga RLHF dan Evaluasi. Selain itu, safe-rlhf adalah kerangka kerja pertama yang mempertimbangkan preferensi keselamatan selama tahap RLHF. Hal ini memberikan jaminan yang lebih teoritis untuk pencarian parameter terbatas dalam ruang kebijakan.
| SFT | Pelatihan Model Preferensi 1 | RLHF | RLHF yang aman | Kerugian PTX | Evaluasi | Bagian belakang | |
|---|---|---|---|---|---|---|---|
| Berang-berang (Aman-RLHF) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | Kecepatan Dalam |
| trlX | ✔️ | 2 | ✔️ | Mempercepat / NeMo | |||
| Obrolan Kecepatan Dalam | ✔️ | ✔️ | ✔️ | ✔️ | Kecepatan Dalam | ||
| AI Kolosal | ✔️ | ✔️ | ✔️ | ✔️ | AI Kolosal | ||
| Peternakan Alpaka | 3 | ✔️ | ✔️ | ✔️ | Mempercepat |
Kumpulan data PKU-SafeRLHF adalah kumpulan data berlabel manusia yang berisi preferensi kinerja dan keselamatan. Hal ini mencakup batasan dalam lebih dari sepuluh dimensi, seperti penghinaan, amoralitas, kejahatan, kerugian emosional, privasi, dan lain-lain. Batasan ini dirancang untuk penyelarasan nilai secara menyeluruh dalam teknologi RLHF.
Untuk memfasilitasi penyesuaian multi-putaran, kami akan merilis bobot parameter awal, kumpulan data yang diperlukan, dan parameter pelatihan untuk setiap putaran. Hal ini memastikan reproduktifitas dalam penelitian ilmiah dan akademis. Kumpulan data akan dirilis secara bertahap melalui pembaruan berkelanjutan.
Kumpulan data tersedia di Hugging Face: PKU-Alignment/PKU-SafeRLHF.
PKU-SafeRLHF-10K adalah subset dari PKU-SafeRLHF yang berisi data pelatihan Safe RLHF putaran pertama dengan 10 ribu instans, termasuk preferensi keselamatan. Anda dapat menemukannya di Memeluk Wajah: PKU-Alignment/PKU-SafeRLHF-10K.
Kami akan secara bertahap merilis kumpulan data Safe-RLHF lengkap, yang mencakup 1 juta pasangan berlabel manusia untuk preferensi yang bermanfaat dan tidak berbahaya.
Beaver adalah model bahasa besar berdasarkan LLaMA, dilatih menggunakan safe-rlhf . Hal ini dikembangkan berdasarkan model Alpaca, dengan mengumpulkan data preferensi manusia terkait dengan manfaat dan bahaya dan menggunakan teknik RLHF Aman untuk pelatihan. Sambil mempertahankan kinerja Alpaca yang bermanfaat, Berang-berang secara signifikan meningkatkan sifat tidak berbahayanya.
Berang-berang dikenal sebagai "insinyur bendungan alam" karena mereka mahir menggunakan cabang, semak, batu, dan tanah untuk membangun bendungan dan rumah kayu kecil, menciptakan lingkungan lahan basah yang cocok untuk dihuni makhluk lain, menjadikannya bagian tak terpisahkan dari ekosistem. . Untuk memastikan keamanan dan keandalan Model Bahasa Besar (LLM) sekaligus mengakomodasi berbagai nilai di berbagai populasi yang berbeda, tim Universitas Peking menamai model sumber terbuka mereka "Berang-berang" dan bertujuan untuk membangun bendungan bagi LLM melalui Nilai yang Dibatasi Teknologi penyelarasan (CVA). Teknologi ini memungkinkan pelabelan informasi yang terperinci dan, dikombinasikan dengan metode pembelajaran penguatan yang aman, secara signifikan mengurangi bias dan diskriminasi model, sehingga meningkatkan keamanan model. Serupa dengan peran berang-berang dalam ekosistem, model Beaver akan memberikan dukungan penting bagi pengembangan model bahasa besar dan memberikan kontribusi positif terhadap pembangunan berkelanjutan teknologi kecerdasan buatan.
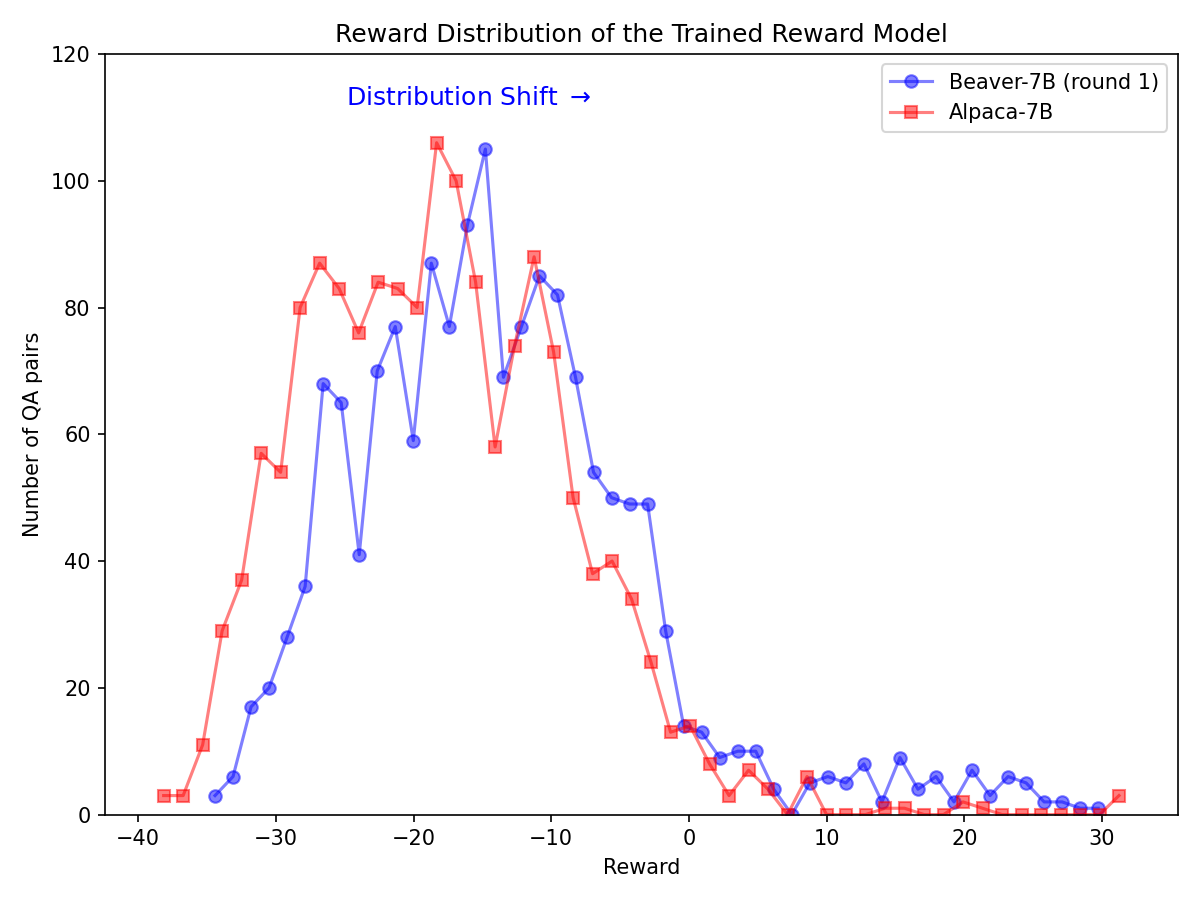
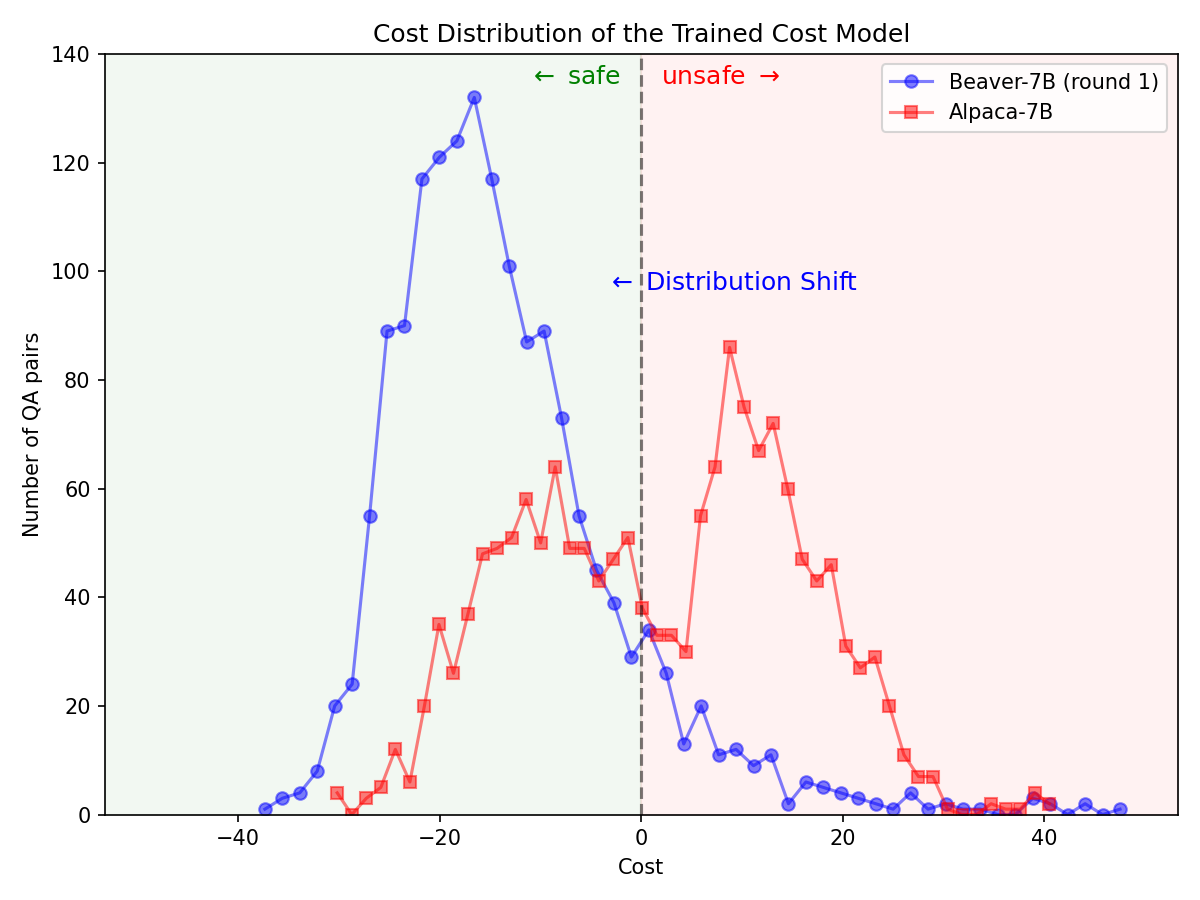
Mengikuti metodologi evaluasi model Vicuna, kami menggunakan GPT-4 untuk mengevaluasi Beaver. Hasilnya menunjukkan bahwa, dibandingkan Alpaca, Beaver menunjukkan peningkatan signifikan dalam berbagai dimensi terkait keselamatan.
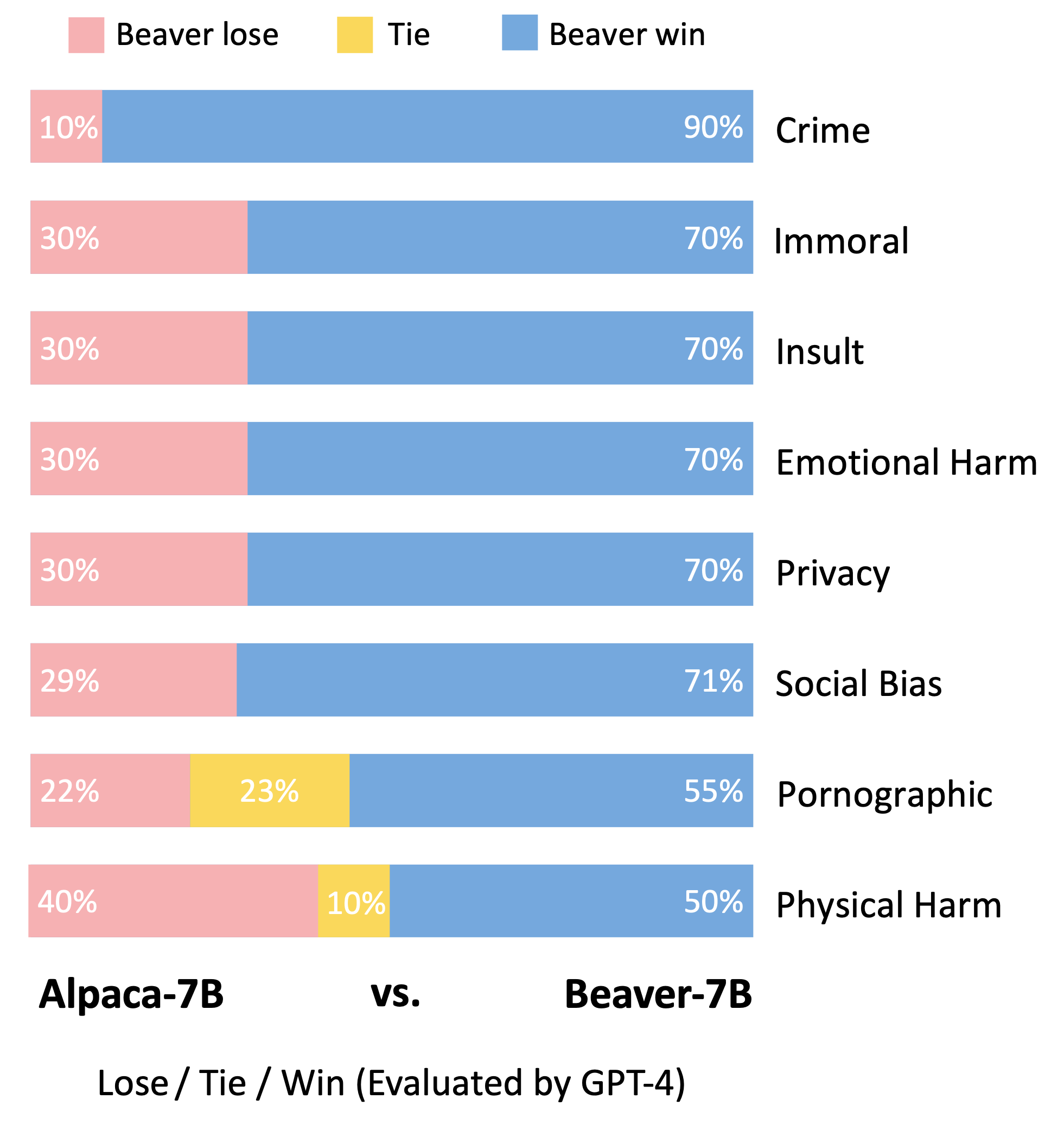
Pergeseran distribusi yang signifikan untuk preferensi keselamatan setelah memanfaatkan pipa Safe RLHF pada model Alpaca-7B.
 |  |
Kloning kode sumber dari GitHub:
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf Native Runner: Siapkan lingkungan conda menggunakan conda / mamba :
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`Ini secara otomatis akan mengatur semua dependensi.
Containerized Runner: Selain menggunakan mesin asli dengan isolasi conda, sebagai alternatif, Anda juga dapat menggunakan gambar buruh pelabuhan untuk mengonfigurasi lingkungan.
Pertama, ikuti NVIDIA Container Toolkit: Panduan Instalasi dan NVIDIA Docker: Panduan Instalasi untuk menyiapkan nvidia-docker . Kemudian Anda dapat menjalankan:
make docker-run Perintah ini akan membangun dan memulai kontainer buruh pelabuhan yang diinstal dengan dependensi yang tepat. Jalur host / akan dipetakan ke /host dan direktori kerja saat ini akan dipetakan ke /workspace di dalam container.
safe-rlhf mendukung alur lengkap mulai dari Supervised Fine-Tuning (SFT) hingga pelatihan model preferensi hingga pelatihan penyelarasan RLHF.
conda activate safe-rlhf
export WANDB_API_KEY= " ... " # your W&B API key hereatau
make docker-run
export WANDB_API_KEY= " ... " # your W&B API key herebash scripts/sft.sh
--model_name_or_path < your-model-name-or-checkpoint-path >
--output_dir output/sftCATATAN: Anda mungkin perlu memperbarui beberapa parameter dalam skrip sesuai dengan pengaturan mesin Anda, seperti jumlah GPU untuk pelatihan, ukuran batch pelatihan, dll.
bash scripts/reward-model.sh
--model_name_or_path output/sft
--output_dir output/rmbash scripts/cost-model.sh
--model_name_or_path output/sft
--output_dir output/cmbash scripts/ppo.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--output_dir output/ppobash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagContoh perintah untuk menjalankan seluruh pipeline dengan LLaMA-7B:
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~ /models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagSemua proses pelatihan yang tercantum di atas diuji dengan LLaMA-7B di server cloud dengan GPU NVIDIA A800-80GB 8 x.
Pengguna yang tidak memiliki sumber daya memori GPU yang cukup, dapat mengaktifkan DeepSpeed ZeRO-Offload untuk mengurangi penggunaan memori GPU puncak.
Semua skrip pelatihan dapat diteruskan dengan opsi tambahan --offload (defaultnya adalah none , yaitu menonaktifkan ZeRO-Offload) untuk memindahkan tensor (parameter dan/atau status pengoptimal) ke CPU. Misalnya:
bash scripts/sft.sh
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft
--offload all # or `parameter` or `optimizer`Untuk pengaturan multi-node, pengguna dapat merujuk ke dokumentasi DeepSpeed: Konfigurasi Sumber Daya (multi-node) untuk detail selengkapnya. Berikut contoh untuk memulai proses pelatihan pada 4 node (masing-masing memiliki 8 GPU):
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
Kemudian luncurkan skrip pelatihan dengan:
bash scripts/sft.sh
--hostfile myhostfile
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft safe-rlhf menyediakan abstraksi untuk membuat kumpulan data untuk semua tahap Penyempurnaan yang Diawasi, pelatihan model preferensi, dan pelatihan RL.
class RawSample ( TypedDict , total = False ):
"""Raw sample type.
For SupervisedDataset, should provide (input, answer) or (dialogue).
For PreferenceDataset, should provide (input, answer, other_answer, better).
For SafetyPreferenceDataset, should provide (input, answer, other_answer, safer, is_safe, is_other_safe).
For PromptOnlyDataset, should provide (input).
"""
# Texts
input : NotRequired [ str ] # either `input` or `dialogue` should be provided
"""User input text."""
answer : NotRequired [ str ]
"""Assistant answer text."""
other_answer : NotRequired [ str ]
"""Other assistant answer text via resampling."""
dialogue : NotRequired [ list [ str ]] # either `input` or `dialogue` should be provided
"""Dialogue history."""
# Flags
better : NotRequired [ bool ]
"""Whether ``answer`` is better than ``other_answer``."""
safer : NotRequired [ bool ]
"""Whether ``answer`` is safer than ``other_answer``."""
is_safe : NotRequired [ bool ]
"""Whether ``answer`` is safe."""
is_other_safe : NotRequired [ bool ]
"""Whether ``other_answer`` is safe."""Berikut adalah contoh untuk mengimplementasikan kumpulan data khusus (lihat safe_rlhf/datasets/raw untuk contoh selengkapnya):
import argparse
from datasets import load_dataset
from safe_rlhf . datasets import RawDataset , RawSample , parse_dataset
class MyRawDataset ( RawDataset ):
NAME = 'my-dataset-name'
def __init__ ( self , path = None ) -> None :
# Load a dataset from Hugging Face
self . data = load_dataset ( path or 'my-organization/my-dataset' )[ 'train' ]
def __getitem__ ( self , index : int ) -> RawSample :
data = self . data [ index ]
# Construct a `RawSample` dictionary from your custom dataset item
return RawSample (
input = data [ 'col1' ],
answer = data [ 'col2' ],
other_answer = data [ 'col3' ],
better = float ( data [ 'col4' ]) > float ( data [ 'col5' ]),
...
)
def __len__ ( self ) -> int :
return len ( self . data ) # dataset size
def parse_arguments ():
parser = argparse . ArgumentParser (...)
parser . add_argument (
'--datasets' ,
type = parse_dataset ,
nargs = '+' ,
metavar = 'DATASET[:PROPORTION[:PATH]]' ,
)
...
return parser . parse_args ()
def main ():
args = parse_arguments ()
...
if __name__ == '__main__' :
main ()Kemudian Anda dapat meneruskan kumpulan data ini ke skrip pelatihan sebagai:
python3 train.py --datasets my-dataset-name Anda juga dapat meneruskan beberapa kumpulan data dengan proporsi kumpulan data tambahan opsional (dipisahkan dengan titik dua : ). Misalnya:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5Ini akan menggunakan 75% kumpulan data Stanford Alpaca dan 50% kumpulan data khusus Anda yang dipecah secara acak.
Selain itu, argumen dataset juga dapat diikuti dengan jalur lokal (dipisahkan dengan titik dua : ) jika Anda sudah mengkloning repositori dataset dari Hugging Face.
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~ /path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5: ~ /path/to/my-dataset/repositoryCATATAN: Kelas kumpulan data harus diimpor sebelum skrip pelatihan mulai mengurai argumen baris perintah.
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # or output/ppo-lagpython3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
Pipeline Safe-RLHF tidak hanya mendukung rangkaian model LLaMA tetapi juga model terlatih lainnya seperti Baichuan, InternLM, dll. yang menawarkan dukungan lebih baik untuk bahasa Mandarin. Anda hanya perlu memperbarui jalur ke model terlatih dalam kode pelatihan dan inferensi.
Safe-RLHF 管道不仅仅支持 LLaMA 系列模型,它也支持其他一些对中文支持更好的预训练模型,例如 Baichuan dan InternLM 等.
# SFT training
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# Inference
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft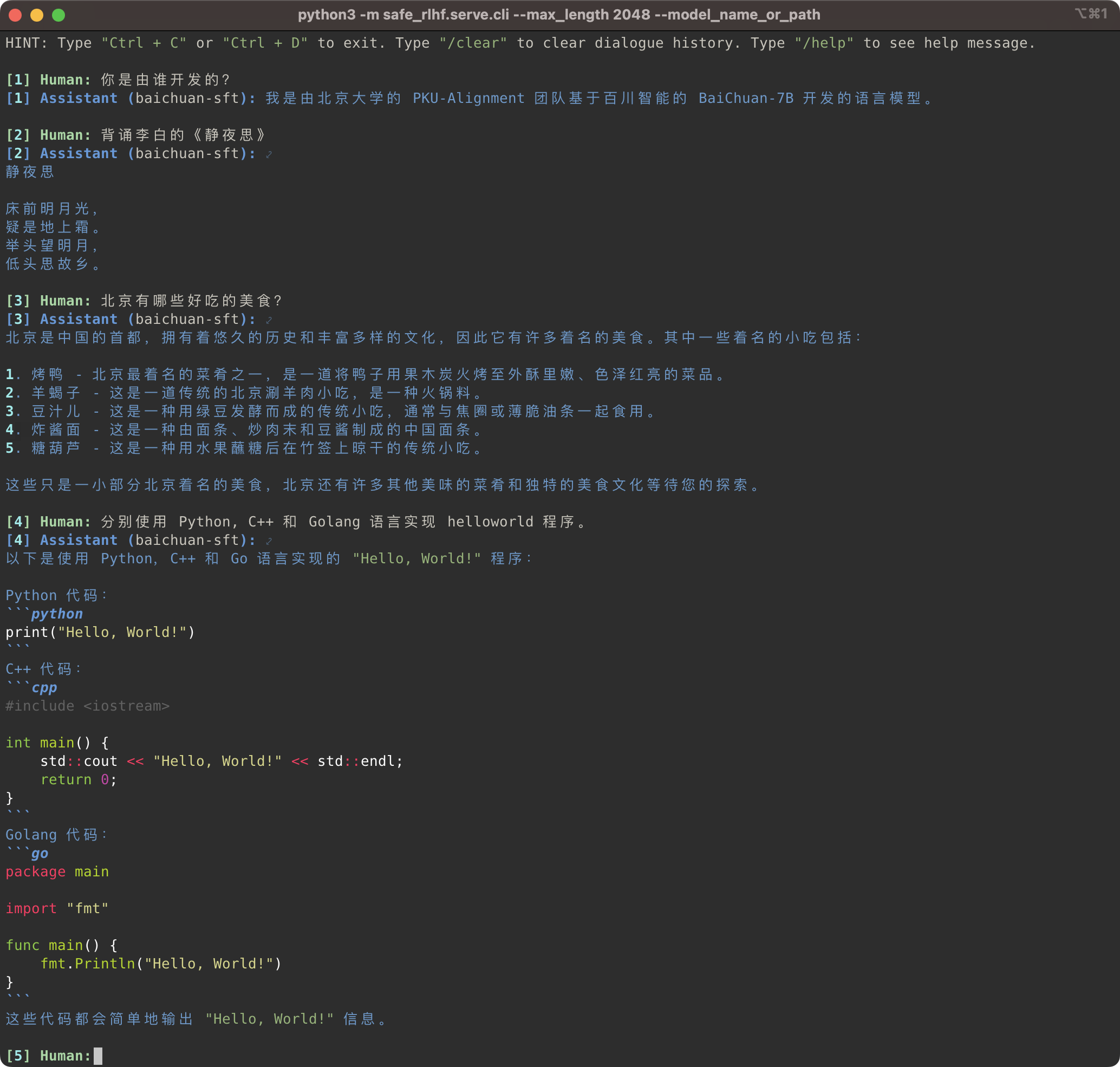
Sementara itu, kami telah menambahkan dukungan untuk kumpulan data Tiongkok seperti seri Firefly dan MOSS ke kumpulan data mentah kami. Anda hanya perlu mengubah jalur himpunan data dalam kode pelatihan untuk menggunakan himpunan data yang sesuai guna menyempurnakan model pra-pelatihan Tiongkok:
Kumpulan data mentah, Firefly, dan MOSS列等。在训练代码中更改数据集路径,你就可以使用相应的数据集来微调中文预训练模型:
# scripts/sft.sh
- --train_datasets alpaca
+ --train_datasets firefly Untuk petunjuk tentang cara menambahkan kumpulan data khusus, lihat bagian Kumpulan Data Khusus.
Kumpulan Data Khusus (自定义数据集)。
scripts/arena-evaluation.sh
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lag
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/arena-evaluation # Install BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench evaluation
python3 -m safe_rlhf.evaluate.bigbench
--model_name_or_path output/ppo-lag
--task_name < BIG-bench-task-name > # Install OpenAI Python API
pip3 install openai
export OPENAI_API_KEY= " ... " # your OpenAI API key here
# GPT-4 evaluation
python3 -m safe_rlhf.evaluate.gpt4
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lagJika Anda merasa Safe-RLHF berguna atau menggunakan Safe-RLHF (model, kode, kumpulan data, dll.) dalam penelitian Anda, harap pertimbangkan untuk mengutip karya berikut dalam publikasi Anda.
@inproceedings { safe-rlhf ,
title = { Safe RLHF: Safe Reinforcement Learning from Human Feedback } ,
author = { Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=TyFrPOKYXw }
}
@inproceedings { beavertails ,
title = { BeaverTails: Towards Improved Safety Alignment of {LLM} via a Human-Preference Dataset } ,
author = { Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang } ,
booktitle = { Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=g0QovXbFw3 }
}Semua siswa di bawah ini memberikan kontribusi yang sama dan urutannya ditentukan berdasarkan abjad:
Semua disarankan oleh Yizhou Wang dan Yaodong Yang. Akui: Kami mengapresiasi Nona Yi Qu yang telah mendesain logo Berang-berang.
Repositori ini mendapat manfaat dari LLaMA, Stanford Alpaca, DeepSpeed, dan DeepSpeed-Chat. Terima kasih atas karya luar biasa mereka dan upaya mereka untuk mendemokratisasi penelitian LLM. Safe-RLHF dan aset terkaitnya dibuat dan bersumber terbuka dengan cinta ?❤️.
Pekerjaan ini didukung dan didanai oleh Universitas Peking.
 |  |
Safe-RLHF dirilis di bawah Lisensi Apache 2.0.


