spelltest
v0.0.4
? Jika Anda merasa proyek ini bermanfaat, mohon pertimbangkan untuk memberikannya bintang! Dukungan Anda memotivasi saya untuk terus memperbaikinya! ?
Aplikasi berbasis AI saat ini sangat bergantung pada Model Bahasa Besar (LLM) seperti GPT-4 untuk memberikan solusi inovatif. Namun, memastikan bahwa mereka memberikan respons yang relevan dan akurat dalam setiap situasi merupakan sebuah tantangan. Spelltest mengatasi hal ini dengan mensimulasikan respons LLM menggunakan persona pengguna sintetis dan teknik evaluasi untuk mengevaluasi respons ini secara otomatis (tetapi masih memerlukan pengawasan manusia).
spellforge.yaml : project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

Anda sekarang dapat mencoba proyek ini di lingkungan interaktif berbasis web melalui Google Colab! Tidak diperlukan instalasi.
Cukup klik lencana di atas untuk memulai!
Kualitas Terjamin : Simulasikan interaksi pengguna untuk respons optimal.
Efisiensi & Penghematan : Menghemat biaya pengujian manual.
Integrasi Alur Kerja yang Lancar : Cocok dengan proses pengembangan Anda.
Perlu diketahui bahwa ini adalah versi awal dari Spelltest. Oleh karena itu, ini belum diuji secara ekstensif di berbagai lingkungan dan kasus penggunaan. Dengan memutuskan untuk menggunakan versi ini, Anda menerima bahwa Anda menggunakan kerangka Spelltest dengan risiko Anda sendiri. Kami sangat menganjurkan pengguna untuk melaporkan masalah atau bug apa pun yang mereka temui untuk membantu peningkatan proyek.
Mengenai biaya operasional, penting untuk dicatat bahwa menjalankan simulasi dengan Spelltest dikenakan biaya berdasarkan penggunaan OpenAI API. Tidak ada perkiraan biaya atau batasan anggaran saat ini. Untuk konteksnya, menjalankan 100 simulasi mungkin memerlukan biaya sekitar $0,7 hingga $1,8 (gpt-3,5-turbo), bergantung pada beberapa faktor termasuk LLM spesifik dan kompleksitas simulasi.
Mengingat biaya-biaya ini, kami sangat menyarankan untuk memulai dengan jumlah simulasi yang lebih sedikit untuk menekan biaya awal dan membantu Anda memperkirakan pengeluaran di masa depan dengan lebih baik. Saat Anda semakin memahami kerangka kerja dan implikasi biayanya, Anda dapat menyesuaikan jumlah simulasi sesuai dengan anggaran dan kebutuhan Anda.
Ingat, tujuan Spelltest adalah memastikan respons berkualitas tinggi dari LLM sambil tetap hemat biaya dalam proses pengembangan dan pengujian AI Anda.

Spelltest mengambil pendekatan khusus terhadap jaminan kualitas. Dengan menggunakan persona pengguna sintetis, kami tidak hanya menyimulasikan interaksi tetapi juga menangkap ekspektasi unik pengguna, menyediakan lingkungan yang kaya konteks untuk pengujian. Kedalaman konteks ini memungkinkan kami mengevaluasi kualitas respons LLM dengan cara yang mencerminkan penerapan di dunia nyata.
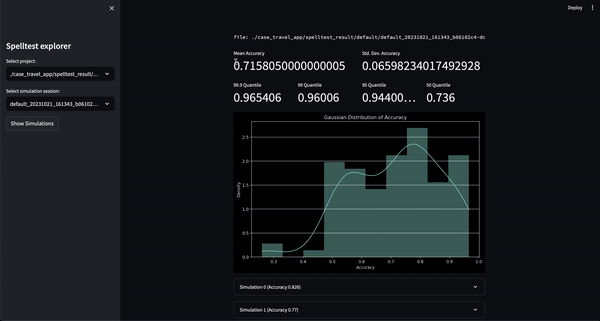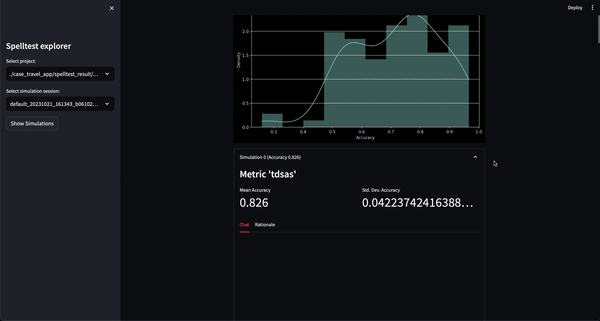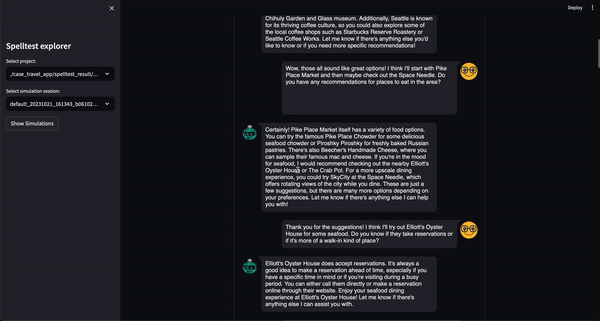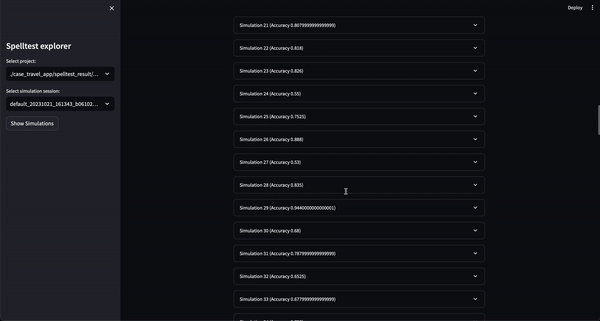
Hasilnya? Skor kualitas berkisar antara 0,0 hingga 1,0, yang berfungsi sebagai latihan menyeluruh sebelum aplikasi Anda bertemu dengan pengguna sebenarnya. Baik dalam mode obrolan atau penyelesaian, Spelltest memastikan bahwa respons LLM selaras dengan harapan pengguna, sehingga meningkatkan kepuasan pengguna secara keseluruhan.
Instal kerangka kerja menggunakan pip:
pip install spelltest .spellforge.yaml adalah inti dari Spelltest, yang berisi profil pengguna sintetis, metrik, perintah, dan simulasi. Di bawah ini adalah rincian strukturnya:
Pengguna sintetis meniru pengguna di dunia nyata, masing-masing memiliki latar belakang, ekspektasi, dan pemahaman unik tentang aplikasi. Konfigurasi untuk pengguna sintetis meliputi:
Sub Perintah : Ini adalah elemen deskriptif yang memberikan konteks pada profil pengguna. Ini termasuk:
description : Penjelasan singkat tentang pengguna sintetis.expectation : Apa yang diharapkan pengguna dari interaksi.user_knowledge_about_app : Tingkat keakraban dengan aplikasi.Setiap pengguna sintetis juga memiliki:
name : Pengidentifikasi untuk pengguna sintetis.llm_name : Model LLM yang akan digunakan (diuji hanya pada model OpenAI).temperature : ...Contoh konfigurasi pengguna sintetis:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
... Metrik digunakan untuk mengevaluasi dan menilai tanggapan LLM. Setiap metrik berisi description sub-perintah yang memberikan konteks tentang apa yang dinilai oleh metrik.
Contoh konfigurasi metrik sederhana:
...
metrics :
accuracy :
description : " Accuracy "
...Contoh konfigurasi metrik kompleks/kustom:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
... Anjuran adalah pertanyaan atau tugas yang diajukan aplikasi. Ini digunakan dalam simulasi untuk menguji kemampuan LLM dalam menghasilkan respons yang sesuai. Setiap prompt ditentukan dengan description dan teks atau tugas prompt yang sebenarnya.
...
prompts :
book_flight :
file : book-flight-prompt.txt
... Simulasi menentukan skenario pengujian. Elemen kuncinya mencakup prompt , users , llm_name , temperature , size , chat_mode , dan quality_threshold .
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
Konfigurasi lengkap dengan file prompt ada di sini.
Biaya OpenAI : Penggunaan kerangka kerja ini dapat menyebabkan sejumlah besar permintaan ke OpenAI, terutama saat menjalankan simulasi ekstensif. Hal ini dapat mengakibatkan biaya besar pada akun OpenAI Anda. Pastikan Anda memperhatikan anggaran OpenAI dan memahami model penetapan harga. Saya tidak bertanggung jawab atas segala biaya yang timbul.
Rilis Awal : Versi Spelltest ini masih dalam tahap awal dan tidak memiliki jaminan stabilitas. Mohon gunakan dengan hati-hati dan jangan ragu untuk memberikan masukan atau melaporkan masalah.
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yamlPeriksa hasil simulasi.
spelltest --analyzeMengintegrasikan Spelltest ke dalam saluran rilis Anda akan meningkatkan strategi penerapan Anda dengan menggabungkan pengujian otomatis dan konsisten. Langkah penting ini memastikan bahwa aplikasi berbasis LLM Anda mempertahankan standar kualitas yang tinggi dengan secara sistematis melakukan simulasi dan mengevaluasi interaksi pengguna sebelum rilis apa pun. Praktik ini dapat menghemat banyak waktu, mengurangi kesalahan manual, dan memberikan wawasan penting tentang bagaimana perubahan atau fitur baru akan memengaruhi pengalaman pengguna.
Panduan ini akan memandu Anda melalui proses penyiapan dan otomatisasi integrasi berkelanjutan untuk proyek Anda.
Sebelum memulai, pastikan Anda memiliki prasyarat berikut:
Repositori GitHub yang berisi proyek Anda.
Akses ke SpellForge dengan kunci API. Jika Anda belum memilikinya, Anda bisa mendapatkannya dari situs SpellForge.
Kunci API OpenAI untuk menggunakan layanan OpenAI. Jika Anda belum memilikinya, Anda bisa mendapatkannya dari situs OpenAI.
.spellforge.yaml Buat file .spellforge.yaml di direktori root proyek Anda. File ini akan berisi instruksi untuk Spelltest.
Buat file alur kerja GitHub Actions, misalnya, .github/workflows/.spelltest.yaml, untuk mengotomatiskan pengujian SpellForge. Masukkan kode berikut ke dalam file ini:
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATHAlur kerja ini dipicu pada setiap dorongan ke cabang utama dan akan menjalankan pengujian SpellForge Anda.
Buka repositori GitHub Anda dan navigasikan ke tab "Pengaturan".
Di bawah "Rahasia" tambahkan dua rahasia baru:
OPENAI_API_KEY : Tetapkan rahasia ini ke kunci API OpenAI Anda.
Tambahkan variabel lingkungan GitHub:
SPELLTEST_CONFIG_PATH : Setel variabel ini ke path lengkap ke file .spellforge.yaml dalam repositori Anda.
Ini adalah simulasi interaksi pengguna nyata dengan karakteristik dan harapan tertentu.
Latar Belakang Pengguna ( kolom description di .spellforge.yaml ): Sub perintah yang memberikan gambaran umum tentang siapa pengguna sintetis ini dan masalah yang ingin mereka selesaikan menggunakan aplikasi, misalnya, seorang pelancong yang mengatur jadwalnya.
Ekspektasi Pengguna ( bidang expectation ): Sub perintah yang mendefinisikan apa yang diantisipasi pengguna sintetis sebagai interaksi atau solusi yang berhasil dari penggunaan aplikasi.
Kesadaran Lingkungan ( bidang user_knowledge_about_app ): Sub perintah yang memastikan pengguna sintetis memahami konteks aplikasi, memastikan skenario pengujian yang realistis.
Sub prompt yang mewakili standar atau kriteria yang digunakan untuk mengevaluasi dan menilai respons yang dihasilkan oleh LLM dalam simulasi. Metrik dapat berkisar dari pengukuran umum hingga metrik khusus yang lebih spesifik untuk aplikasi.
Contoh Metrik Umum:
Kesamaan Semantik : Mengukur seberapa mirip jawaban yang diberikan dengan jawaban yang diharapkan dalam artian.
Toksisitas : Mengevaluasi respons terhadap bahasa atau konten apa pun yang mungkin dianggap tidak pantas atau berbahaya.
Kesamaan Struktural : Membandingkan struktur dan format respons yang dihasilkan dengan standar yang telah ditentukan atau keluaran yang diharapkan.
Contoh Metrik Khusus Lainnya:
TPAS (Skor Akurasi Rencana Perjalanan) : "Metrik ini mengukur keakuratan respons yang dihasilkan dengan mengevaluasi penyertaan keluaran yang diharapkan dan kualitas rencana perjalanan yang diusulkan. TPAS adalah nilai numerik antara 0 dan 100, dengan 100 mewakili sempurna cocok dengan keluaran yang diharapkan dan 0 menunjukkan hasil yang tidak akurat."
EES (Empathy Engagement Score) : "EES menilai resonansi empati dari respons LLM. Dengan mengevaluasi pemahaman, validasi, dan elemen pendukung dalam pesan, EES menilai tingkat empati yang disampaikan. EES berkisar dari 0 hingga 100, di mana 100 menunjukkan a respons yang sangat berempati, sedangkan 0 menunjukkan kurangnya keterlibatan empati."
Jadikan aplikasi berbasis LLM Anda lebih baik dengan Spelltest!


