paperchat
1.0.0
Selamat datang di arXivchat!
arXivchat adalah perangkat lunak berbasis LLM yang memungkinkan Anda membicarakan makalah yang diterbitkan arXiv dengan cara percakapan. Ia berfungsi sebagai alat cli, penyedia API dan plugin ChatGPT.
Dibuat oleh Operator Forward. Kami bekerja dengan beberapa orang terpintar di proyek terkait LLM dan ML.
Anda dipersilakan untuk berkontribusi!
Ikuti langkah-langkah berikut untuk menyiapkan dan menjalankan plugin arXiv dengan cepat:
Instal Python 3.10, jika belum diinstal.
Kloning repositori: git clone https://github.com/Forward-Operators/arxivchat.git
Arahkan ke direktori repositori yang dikloning: cd /path/to/arxivchat
Instal puisi: pip install poetry
Buat lingkungan virtual baru dengan Python 3.10: poetry env use python3.10
Aktifkan lingkungan virtual: poetry shell
Instal dependensi aplikasi: poetry install
Tetapkan variabel lingkungan yang diperlukan:
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
Jalankan API secara lokal: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
Akses dokumentasi API di http://0.0.0.0:8000/docs dan uji titik akhir API.
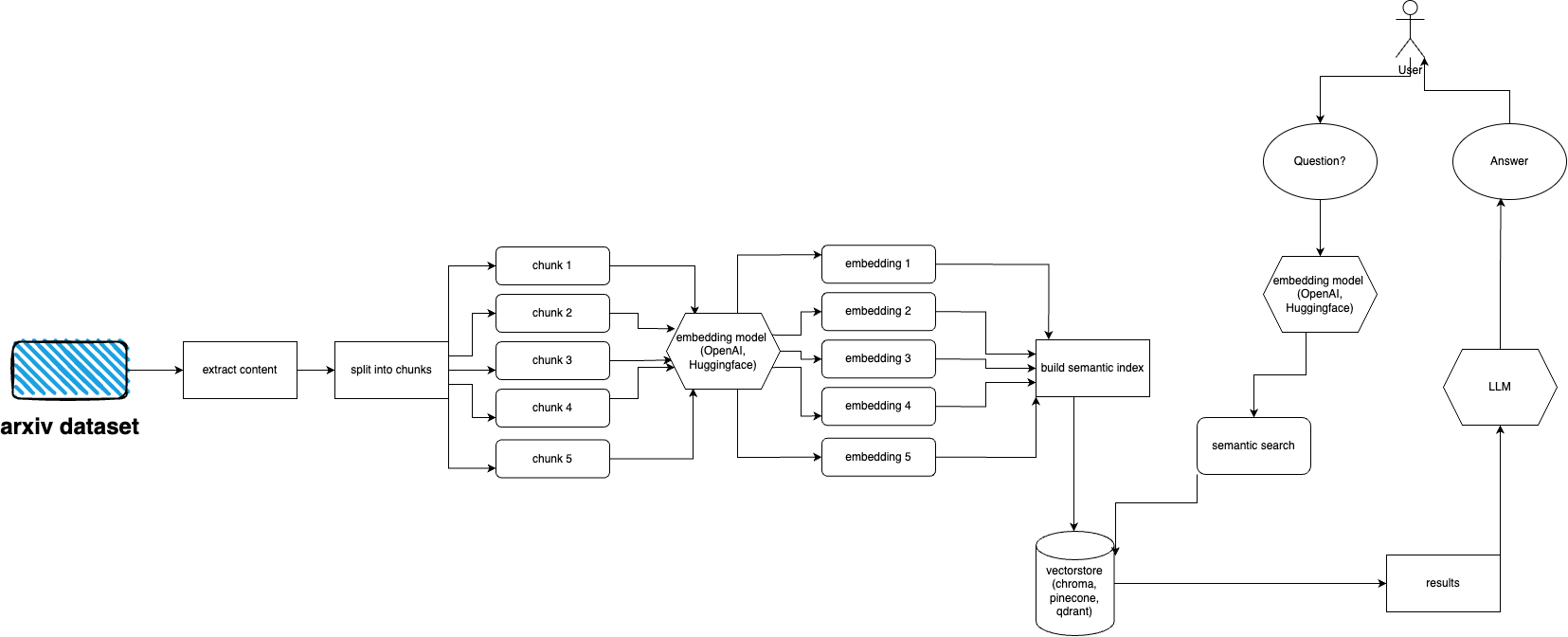
arXiv memiliki kumpulan data hampir 2 juta publikasi. mengambil terlalu banyak data dari situs web mereka bertentangan dengan ToS arXiv (karena menimbulkan beban) Untungnya, orang-orang baik dari kaggle bersama dengan Cornell University membuat kumpulan data yang tersedia untuk umum yang dapat Anda gunakan. Kumpulan data tersedia secara gratis melalui keranjang Google Cloud Storage dan diperbarui setiap minggu.
Sekarang masalah utamanya adalah - bagaimana cara mendapatkan hanya sebagian dari keseluruhan kumpulan data tersebut jika kita tidak ingin menyerap lebih dari 5 terabyte file pdf? Kumpulan data dibagi menjadi beberapa direktori per bulan, per tahun, jadi jika Anda ingin mendapatkan semua publikasi mulai September 2021, Anda cukup menjalankan: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
Jika Anda ingin mendapatkan seluruh kumpulan data: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
Tetapi jika Anda hanya ingin mendapatkan sebagian (untuk kategori dan tanggal tertentu) lihat file download.py .
Secara default, ingester mengharapkan file ini berada di /mnt/dataset/arxiv/pdf dengan semua file pdf di sana.
Periksa dan jalankan python scripy.py untuk menyerap data. Anda juga dapat mengaktifkan debugging di sana jika ada yang tidak berfungsi.
TODO: mungkin ubah ini ke pemuat direktori TODO: terapkan penerapan seledri dan gunakan pekerja untuk penyerapan
python cli.py 
Ajukan pertanyaan tentang topik yang Anda masukkan ke database sebelumnya. Mengembalikan informasi tentang sumber juga, berjalan terus menerus. Pilihan lainnya adalah menggunakan REST API (jalankan uvicorn main:app --reload --host 0.0.0.0 --port 8000 dari direktori app ) atau menggunakannya sebagai plugin ChatGPT (setelah penerapan)
Ada file terraform di direktori deployment . Gunakan salah satu yang paling cocok untuk Anda. Ada file README di masing-masingnya dengan instruksi. Anda juga dapat membuat image Docker dan menjalankannya di mana pun Anda mau. File gambarnya cukup besar.
Untuk saat ini dapat diterapkan sebagai Cloud Run menggunakan gambar buruh pelabuhan, jadi ini hanya penerapan API. Penyerapan data harus dijalankan di komputer lain (saya merekomendasikan Mesin Komputasi berkemampuan GPU, terutama jika Anda ingin menggunakan penyematan Hugging Face dan karena Anda dapat memasang data dari Google Storage secara langsung menggunakan gcsfuse ) Solusi potensial untuk menggunakan bucket GCS dengan Cloud Berlari
Untuk saat ini dapat diterapkan sebagai Aplikasi Kontainer (penyebaran API saja, Anda memerlukan penerapan lain untuk penyerapan)
AWS belum didukung. Segera hadir.
arxivchat menggunakan text-embedding-ada-002 untuk OpenAI secara default, Anda dapat mengubahnya di app/tools/factory.py
Untuk saat ini Anda dapat menggunakan model apa pun yang berfungsi dengan sentence_transformers . Anda dapat mengubah model di app/tools/factory.py
Jika Anda memiliki masalah, silakan gunakan masalah GitHub untuk melaporkannya.
Kami akan sangat senang jika Anda membantu membuat arXivchat menjadi lebih baik! Untuk berkontribusi, silakan ikuti langkah-langkah berikut:
arXivchat dirilis di bawah Lisensi MIT.


